基于交互注意力引导与修正的跨模态动作定位方法与系统与流程
1.本发明属于视频片段定位技术领域,尤其涉及一种基于交互注意力引导与修正的跨模态动作定位方法与系统。
背景技术:
2.随着多媒体技术的快速发展,网络平台涌现出大规模的视频资源。如何从海量的视频库中快速准确地检索出感兴趣的人体动作片段是目前视频理解领域的热点问题,引起学术界工业界的广泛关注。跨模态动作定位任务旨在根据给定的查询文本描述在长视频中定位出与该描述内容相匹配的动作片段,即确定该动作的开始与结束时间点。这个任务在精彩视频片段检索、智能视频监控、视频字幕生成等领域有着广泛的应用前景,是计算机视觉领域热点研究问题。
3.由于该任务涉及视觉和语言两种模态的信息,为了解决该问题,除了要对视频的时序信息以及文本描述的语义信息进行建模外,还需要对视频和文本模态的特征进行深度融合来挖掘细粒度的交互信息,以实现精准地视频片段定位。目前,已有的方法将注意力放在视频和文本模态的交互特征学习上,采用软注意力或自注意力模型来聚合文本单词与视频图像帧之间的特征,但普遍忽略了不同模态特征在交互过程中产生的误匹配以及文本描述对视频动作定位的关键作用。尽管基于文本描述的跨模态动作定位研究已经取得了一定的进展,但仍然存在以下几方面的问题亟需解决:(1)不同时序片段的持续时间长短往往不同,如何最大化的保留视频的全局上下文信息,以实现精准的时间定位;(2)如何挖掘文本描述的语义信息,进而对时间定位进行精准地指导;(3)如何进行有效的文本和视频特征融合是解决跨模态动作定位的关键。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种基于交互注意力引导与修正的跨模态动作定位方法和系统,该方法是首先利用三维卷积神经网络和词向量模型提取视频和文本描述的特征,并使用长短时间记忆网络学习视频和文本的上下文信息;然后,使用交互注意力引导模块增强跨模态特征间的双向表达,并使用修正门控单元进行跨模态语义信息融合;最后,通过时序定位模块计算匹配得分和时序边界偏移量得到调整后的视频动作片段。
5.本发明是通过以下技术方案来实现的:一种基于交互注意力引导与修正的跨模态动作定位方法,该方法包括如下步骤:s1:对于给定的未分割视频序列,按照固定帧率对视频进行等间隔采样得到视频图像帧序列,并将其分割成长度相等的视频片段单元,然后使用预训练的三维卷积神经网络提取视频片段的视觉特征集合;s2:对于给定的文本描述语句,使用在wikipedia上预训练的glove模型得到每个单词的特征嵌入向量,将所有单词特征拼接得到文本特征集合;s3:在单词特征上使用不同窗口大小的一维卷积挖掘单词间潜在的语义特征;
s4:由于三维卷积神经网络和词向量模型无法捕捉视频和文本描述的上下文语义关联信息,进一步将视频每个帧特征和单词特征按时间和语序送入双向长短时间记忆网络,对视频和文本的序列化特征进行建模,得到视频和文本描述的上下文特征;s5:利用交互注意力引导与修正模块构建跨模态特征交互与融合网络;所述网络包含视觉引导注意力模块、文本引导视觉注意力模块以及修正门控模块,用于增强视频和文本内容的特征表达;s6:将步骤s5融合增强后的特征表示送入到时序定位模块,具体为,在每个时间点预定义一系列多尺度候选时序片段,通过一维时间卷积评估每个候选片段的匹配得分,并计算时序边界偏移量调整候选片段的时序边界,得到精准的片段定位结果;s7:对于任意给定的视频和文本描述,评估候选得分最高的视频片段作为最终定位的输出结果。
6.进一步地,所述步骤s1中,所述视频的等间隔采样的帧率为25帧/秒,每个视频片段单元的长度为16帧,由c3d网络对视频片段进行编码并采用线性变换得到维度为500维的视频单元特征,将视频片段特征在时间维度进行拼接得到长度为200、维度为500的视频特征。
7.进一步地,所述步骤s2中,词向量维度设置为300维,每个文本描述设置固定长度为20个单词。
8.进一步地,所述步骤s3具体过程为:在每个位置计算单词特征向量和三种不同尺度的卷积核的内积,以此捕捉单字母、双字母以及三字母的单词特征;为保持单词总个数不变,当卷积窗口大于1时使用零填充;第个单词位置的输出特征表示为,,其中,为卷积窗口大小;为单词位置;tanh(.)为激活函数,
…
conv1d()为1维卷积。
9.进一步地,所述步骤s4中,双向长短时间记忆网络包含两个方向相反的lstm网络,每层神经元个数为256,最后将前向和反向网络的输出进行拼接得到相应特征的上下文表示。
10.进一步地,所述步骤s5具体过程为:(1.1)文本引导视觉注意力模块:首先,将文本特征和视频特征通过线性变换得到查询特征向量,键向量,值向量;在文本特征上使用时间平均池化操作,并通过两个线性层和非线性激活函数得到文本引导的注意力权重,即:其中,为可学习的权重和偏置参数,代表函数, 为平均池化操作;随后,分别将查询向量和键向量通过条件门与短路连接增强特征内容的表达,即:其中,代表逐元素相乘;为增强后的视频查询向量输出;为增强后的视频键
向量输出;视频查询向量和键向量的通道特征将根据模态信息被上述条件门激活或关闭,以此为视频特征添加文本描述的上下文语义作为指导信息;其次,计算视频模态内的特征自注意力权重,在通道维度上使用函数生成注意力权重:;其中,为视频经过线性变换后的特征维度,表示转置操作;最后,对原视频特征进行更新:;其中,为更新后的视频特征;(1.2)视觉引导文本注意力模块:对于给定的视频和文本模态特征,首先计算视频查询向量和文本键向量之间的跨模态联合注意力权重,即视频和文本模态的相关系数:;并以此更新文本特征:;其中,表示转置操作;为更新后的文本特征;该过程可以增强与视频内容相关的文本描述单词之间的相关性,得到更好的文本特征表示;(1.3)修正门控单元:首先,将步骤(1.2)中增强后的视频和文本特征与原模态特征在通道上拼接,并经过全连接层与非线性激活函数得到遗忘向量如下:;其中,为非线性激活函数;表示可学习的全连接层参数向量;表示偏置向量;为视频模态的遗忘向量;为文本模态的遗忘向量;该遗忘门能有效抑制噪声,减少误匹配;随后,采用逐元素点乘操作更新相应的模态特征,;其中,和为偏置向量;和为可学习的参数向量;最后,使用矩阵加法运算得到修正后的视频和文本特征表示:;其中,、为训练得到的权重矩阵,、为偏置参数。
11.进一步地,所述步骤s6具体过程为:(2.1)将修正后的视频和文本特征经过矩阵点乘运算进行融合,得到融合后的多
模态特征,在每个时间点预定义个不同尺度窗口的候选时序片段,通过conv1d层计算每个候选片段的置信度得分,并使用sigmoid函数将得分映射到区间;第i个候选片段在时间点t的置信度得分表示为:;其中,为sigmoid激活函数;额外通过conv1d层计算时序边界偏移量:;其中,表示预测的时刻第个候选片段的开始时间点的偏移量,则表示相应的结束时间点的偏移量,因此调整后的时序边界表示为:;(2.2)本系统采用多任务联合损失训练和优化网络参数,具体包含匹配损失和回归损失两部分,其中匹配损失采用预测片段和目标真值gt片段的重叠度交并比来表征匹配程度,记作;如果大于预先设定的阈值,则将该候选片段视作正样本,否则视为负样本,因此可以得到个正样本和个负样本,总计个样本片段;采用匹配损失计算每个候选片段的匹配度得分,定义为:;其中,、分别为正、负候选视频片段的个数;对于正样本,进一步采用边界回归损失优化时序边界;边界回归损失定义为:;其中,表示smooth l1损失;联合损失函数表示为匹配损失和边界回归损失的加权和,计算公式为:其中,为调节两项损失的超参数。
12.一种基于交互注意力引导与修正的跨模态动作定位系统,包括一个或多个处理器,用于实现上述任一项所述的基于交互注意力引导与修正的跨模态动作定位方法。
13.本发明的有益效果如下:针对跨模态视频动作定位任务,一方面,以往的方法忽略文本句子描述在跨模态交互过程中更好地关联相关视频内容的重要作用,本发明提出利用句子描述的全局信息,并采用交互注意力机制引导视频和文本跨模态信息交流;另一方面,在多模态特征融合过程中,视频中的冗余帧及句子中的噪声单词会干扰模态间的有效交互,本发明提出修正门控单元抑制模态间的噪声信息,提高多模态特征融合的有效表达,进而提升跨模态视频动
作定位的精度。
附图说明
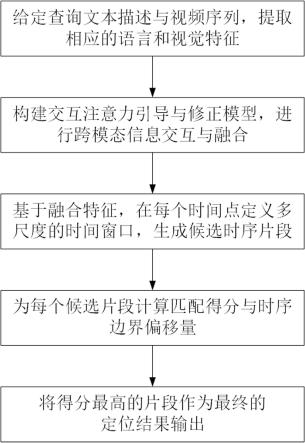
14.图1为本发明的系统流程图;图2为本发明的方法框架示意图。
具体实施方式
15.下面结合附图和具体实例对本发明作进一步的说明。
16.本发明提供一种基于交互注意力引导与修正的跨模态动作定位方法与系统,能基于给定的查询文本描述语句从长视频序列中定位出相应的目标片段,即给出目标片段的开始和结束时间点。如图1所示,该方法首先基于三维卷积神经网络和词向量模型提取视频和文本描述的特征,采用自注意力机制与多尺度时序模型捕捉视频显著化特征和文本上下文语义信息。进一步地,基于视频和文本特征构建交互注意力引导与修正模型,充分挖掘跨模态间的互补信息,使得跨模态特征可以进行有效地交互与融合。最后,基于融合特征在每个时间点生成多尺度的候选时序片段,并使用卷积网络评估候选视频片段的得分和时序边界偏移量,将得分最高的候选片段作为最终的定位结果。
17.下面将结合附图对本发明加以详细说明,图2是本发明提供的一种基于交互注意力引导与修正的跨模动作定位方法与系统。本发明的具体步骤为,s1:对于给定的未分割视频序列,按照固定帧率对视频进行等间隔采样得到视频图像帧序列,并将其分割成长度相等的视频片段单元,然后使用预训练的三维卷积神经网络提取视频片段的视觉特征集合,其中表示视频中的帧数,表示视频中第帧的帧特征,并添加位置编码捕捉视频的时序信息;所述视频采样的帧率fps为25帧/秒,每个视频片段单元的长度为16帧,由c3d网络对视频片段进行编码并采用线性变换得到维度为500维的视频单元特征,将视频片段特征在时间维度进行拼接得到长度为200、维度为的视频特征,对于视频长度不足200的使用0填充,对于长度超出200的进行裁剪。
18.s2:对于给定的文本描述语句,在本实施例中文本描述为“一个人在吃书包里的食物”,使用在wikipedia上预训练的glove模型得到每个单词的特征嵌入向量,将所有单词特征拼接得到文本特征集合,其中为文本描述语句中的单词个数,为文本描述语句中第个单词的语言特征;所述词向量维度设置为300维,每个文本描述设置固定长度为20个单词。当文本单词个数小于20时,使用0填充,当单词个数超出20时,通过裁剪满足固定长度的文本特征输入。
19.s3:为挖掘单词间潜在的语义特征,在单词特征上使用不同窗口大小的一维卷积;具体为,在每个位置计算单词特征向量和三种不同尺度的卷积核的内积,以此捕捉单字母、双字母以及三字母的单词特征。为保持单词总个数不变,当卷积窗口大于1时使用零填充。第个单词位置的输出特征可表示为,其中,为卷积窗口大小。
20.具体为,所述步骤s4中,bi-lstm包含两个方向相反的lstm网络,每个网络包含1个
隐藏层,每层神经元个数为256,最后将前向和反向网络的输出进行拼接得到相应特征的上下文表示。以文本特征为例,该过程表示为:其中,表示前向lstm网络,表示反向lstm网络,为拼接操作。
21.s4:由于三维卷积神经网络和词向量模型无法捕捉视频和文本描述的上下文语义关联信息,进一步将每个帧特征和单词特征按时间和语序送入双向长短时间记忆网络(bi-lstm),对视频和文本的序列化特征进行建模,得到视频和文本描述的整体特征;具体为,双向长短时间记忆网络包含两个方向相反的lstm网络,每层神经元个数为256,最后将前向和反向网络的输出进行拼接,得到相应特征的上下文语义表示。
22.s5:构建基于交互注意力引导与修正的跨模态特征交互与融合网络,包括视觉引导文本注意力模块、文本引导视觉注意力模块以及修正门控单元,以增强视频和文本内容的特征表达;具体过程为:(1.1)文本引导视觉注意力模块:首先,将文本特征和视频特征通过线性变换得到查询特征向量,键向量、值向量,,为充分考虑全局信息,在文本特征上使用时间平均池化操作,并通过两个线性层和非线性激活函数得到文本引导的注意力权重:其中,为可学习的权重和偏置参数,代表函数,为平均池化操作。随后,分别将两个模态的查询向量和键向量通过条件门与短路连接增强特征内容的表达:其中,代表逐元素相乘。视频查询向量和键向量的通道特征将根据模态信息被上述条件门激活或关闭,以此为视频特征添加文本描述的上下文语义作为指导信息。其次,计算视频模态内的特征自注意力权重,在通道维度上使用函数生成注意力权重:其中,为视频经过线性变换后的特征维度,表示转置操作。最后,对原视频特征进行更新:(1.2)视觉引导文本注意力模块:对于给定的视频和文本模态特征,首先计算视频查询向量和文本键向量之间的跨模态联合注意力权重,即视频和文本模态的相关系数:
并以此更新文本特征:该过程可以增强与视频内容相关的文本描述单词之间的相关性,得到更好的文本特征表示。
23.(1.3)修正门控单元:首先,将增强后的视频和文本特征与原模态特征在通道上拼接,并经过全连接层与非线性激活函数得到遗忘向量如下:其中,为非线性激活函数;表示可学习的全连接层参数向量;表示偏置向量;为视频模态的遗忘向量;为文本模态的遗忘向量;该遗忘门能有效抑制噪声,减少误匹配。随后,采用逐元素点乘操作更新相应的模态特征,最后,使用矩阵加法运算得到修正后的视频和文本特征表示:其中,为训练得到的权重矩阵,为偏置参数。
24.s6:将步骤s5融合后的特征表示送入到时序定位模块,在每个时间点预定义个尺度的候选时序片段,总计个候选片段。评估每个候选片段的匹配得分,并计算时序边界偏移量调整候选片段的时序边界,以得到精准的片段定位结果。本实施例中,预定义的候选片段时间尺度为:;当时间尺度为4时,候选片段开始和结束的索引值依次为[0,3],[1,4],[2,5],[3,6]...,以此类推得到多尺度的候选片段集合。具体为:(2.1)将修正后的视频和文本特征经过矩阵点乘运算进行融合,得到融合后的多模态特征,在每个时间点预定义个不同尺度窗口的候选时序片段,这里总计为200个,为上述预定义的候选片段时间尺度,因此共计得到1200个候选片段。
[0025]
通过conv1d层计算每个候选片段的置信度得分,并使用sigmoid函数将得分映射到区间,额外通过conv1d层计算时序边界偏移量,其中,表示预测的时刻第个候选片段的开始时间点的偏移量,则表示相应
的结束时间点的偏移量,因此调整后的时序边界表示为,,(2.2)本系统采用多任务联合损失训练和优化网络参数,具体包含匹配损失和回归损失两部分,其中匹配损失采用预测片段和目标真值(gt, ground truth)片段的时序重叠度交并比(iou, intersection over union)来表征匹配程度,记作。如果大于预先设定的阈值,则将该候选片段视作正样本,否则视为负样本,因此可以得到个正样本和个负样本,总计个样本片段。采用匹配损失计算每个候选片段的匹配度得分,定义为:其中,分别为正、负候选视频片段的个数。对于正样本,进一步采用边界回归损失优化时序边界。边界回归损失定义为:其中,表示smooth l1损失。
[0026]
联合损失函数表示为匹配损失和边界回归损失的加权和,计算公式为:其中,为调节两项损失的超参数。
[0027]
(2.3)在activitynet-captions数据集上利用训练集训练该网络模型,训练集由大量包含(视频,文本描述,视频片段的时序标注)信息的样本组成,并进一步在测试集上验证模型的有效性。activitynet-captions数据集共包含20k个视频和100k个文本描述语句,视频的平均时长为120秒。为了进行公平的比较,本发明遵照该数据集的标准划分,并采用“r@n, iou=m”作为评价标准,其中,n=1,m={0.3,0.5,0.7}。该评价标准表示在前n个预测结果中至少有(召回)一个片段和真实标注的时序交并比(iou)大于m的片段所占的比例。本发明方法与其他现有方法的对比结果如表1所示(单位为:%)。
[0028]
表1由上表分析可得,本发明在不同iou设置下的定位性能都高于所对比的方法,随着iou的增大,即要求预测的片段和真实片段之间有较大的重叠度,因此模型的预测结果会变
差。相比较于cmin的方法,本发明在不同的测试指标下分别取得了5.02%、5.53% 以及3.7% 的提升,显示出本发明能有效提升跨模态动作定位的性能。
[0029]
应当理解的是,本技术并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本技术的范围仅由所附的权利要求来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1