一种面向自监督视频目标分割的黑盒攻击方法
1.本发明涉及一种面向自监督视频目标分割的黑盒攻击方法,属于图像处理技术。
背景技术:
2.通过利用来自数据本身的自我生成的标签,以监督的方式训练模型的自监督学习已成为深度神经网络的学习表示方式。近年来,在视频上进行自监督的学习引起了富有成果的研究。但是深度神经网络非常容易受到攻击,并且可以通过在原始图像中添加视觉上的噪音来轻松地愚弄最新的视频目标分割模型。这种攻击的形式是对人类视觉系统无法察觉的视频帧的小扰动形式。这种攻击会导致模型完全改变其对视频帧的预测。更糟糕的是,受攻击的模型报告了对错误预测的高度信心。此外,相同的对抗性扰动可能会欺骗多个神经网络模型。
3.由于大量的在线数据,已经探索了各种想法以学习通过在视频中利用时空信息来表示对应关系。当前的自监督视频目标分割方法是通过对目标帧和参考帧之间的成对对应关系进行建模来实现的,成对对应保持了时空一致性。基于亲和矩阵的自监督分割模型学习视频序列的特征表示从而实现强大的像素对应关系。因此,黑盒攻击主要针对视频帧序列间的亲和矩阵。基于初始化随机产生的对抗扰动,构建了针对单帧、双帧和多帧的对比损失,进行迭代优化。采用特征损失增强黑盒攻击所生成对抗样本的可转移性。除此之外,为了使生成的对抗样本噪声不可感知,还采用了像素级损失。最终构建多路径聚合模块获得迭代优化后的对抗性扰动。
技术实现要素:
4.发明目的:为了提高自监督视频目标分割方法的鲁棒性,本发明提供一种面向自监督视频目标分割的黑盒攻击方法,通过破坏视频帧间的亲和矩阵找到一个与自监督视频目标分割网络有不可感知差异的对抗样本,使自监督视频目标分割网络失效;通过对对抗性攻击方法的研究,可以帮助理解深度模型的工作机制,方便更好识别分割算法的脆弱性,能够提高自监督视频目标分割算法的鲁棒性。
5.技术方案:为实现上述目的,本发明采用的技术方案为:
6.一种面向自监督视频目标分割的黑盒攻击方法,自监督视频目标分割网络采用基于亲和矩阵的自监督视频目标分割网络,该方法通过破坏视频帧间的亲和矩阵找到一个与自监督视频目标分割网络有不可感知差异的对抗样本,使自监督视频目标分割网络失效。考虑到实施针对视频目标分割的对抗攻击面临两个挑战:
①
与分类的对抗攻击不同,分类只需要分类器错误分类,而成功攻击分割的条件更加模糊;
②
考虑到视频中分割的目标,基于单帧特征生成的对抗性扰动不可能粘贴到每个视频帧中。因此,本发明考虑逐帧产生对抗性扰动,本发明的实现包括如下步骤:
7.(1)针对无注释的原始视频序列x={x1,x2,
…
,xn},首先通过一个自监督训练的噪声生成器随机生成初始化的对抗性扰动δx={δx1,δx2,
…
δxn};xi表示第i帧的原始图
像,δxi表示对应xi的对抗性扰动,i=1,2,
…
,n;
8.(2)将对抗扰动δx添加到原始视频序列x中获得对抗性视频序列x
adv
;
9.(3)考虑视频序列间的一致性问题,分别构建针对单帧、双帧和多帧的对比损失攻击,以获得总的对比损失;
10.(4)设计特征损失函数,使原始图像在语义上更接近特征空间中的对抗帧,进一步增强对抗性视频序列的可转移性;
11.(5)设计像素级损失函数,使对抗性视频序列的噪声不可感知;
12.(6)迭代优化总体损失,构建多路径聚合模块获得迭代优化后的对抗性扰动δx
′
,将对抗性扰动δx
′
添加到原始视频序列x中获得最终的对抗性视频序列x
′
adv
;
13.(7)给定初始帧掩码,将对抗性视频序列x
′
adv
输入自监督视频目标分割网络得到最终预测掩码。
14.优选的,所述步骤(2)中,将对抗扰动δx添加到原始视频序列x中获得对抗性视频序列
[0015][0016]
其中:表示对应xi的对抗样本,ε表示最大允许对抗扰动阈值,||
·
||
∞
表示无穷范数。
[0017]
优选的,所述步骤(3)中,考虑视频序列间的一致性问题,分别构建针对单帧、双帧和多帧的对比损失攻击:
[0018][0019][0020][0021][0022]
其中:和分别表示针对单帧、双帧和多帧的对比损失函数,l
con
表示
总的对比损失函数,xi表示第i帧的原始图像,x
i+1
表示第i+1帧的原始图像,sim(
·
,
·
)表示余弦相似性函数,ν表示温度参数,{x
neg
}是由对抗样本组成的动态队列中元素的集合,{x
pos
}是由原始图像组成的动态队列中元素的集合,m表示每个动态队列中元素的数量。
[0023]
因为黑盒攻击不知道攻击模型的参数与结构,为了进一步增强生成的对抗样本的可转移性,设计特征损失函数使原始图像在语义上更接近特征空间中的对抗帧,即使对抗样本的预测分割掩码应更接近特征空间之间的目标掩模。优选的,所述步骤(4)中,基于特征提取器f
θ
提取的特征设计特征损失函数:
[0024][0025]
其中:表示通过特征提取器f
θ
提取到的的特征图,表示通过特征提取器f
θ
提取到的xi的特征图,h、w和c分别表示特征图的高度、宽度和通道数,||
·
||2表示l2范数。
[0026]
优选的,所述特征提取器f
θ
采用resnet50网络,由resnet50网络的最后一个全连接层的前一层输出输入图像的特征图,θ表示resnet50网络的待学习参数。
[0027]
优选的,所述步骤(5)中,设计像素级损失函数,使对抗性视频序列的噪声不可感知:
[0028][0029]
其中:xi表示第i帧的原始图像,表示对应xi的对抗样本,||
·
||2表示l2范数。
[0030]
具体来说,因为扰动模式类似于噪声,平滑图像有助于缓解对抗效应。因此,为了抑制平滑度,在图像像素空间中应用像素级损失。像素级损失表示对抗示例和原始干净示例之间的l2距离。最小化l2距离的目的是在像素级约束对抗性视频序列和干净视频序列之间的差异,以促进对抗性样本的视觉感知。
[0031]
优选的,所述步骤(6)中,迭代优化总体损失采用的总体损失函数为:
[0032][0033]
其中:δx
′
表示迭代优化后的对抗性扰动,λ、μ和η分别为l
con
、和的权重参数;λ控制噪声和对比损失的相对重要性,μ控制视频中每个目标特征的相对重要性,η控制视频帧像素的相对重要性。
[0034]
优选的,所述步骤(6)中,构建多路径聚合模块获得迭代优化后的对抗性扰动δx
′
,多路径聚合模块旨在整合来自不同路径视频帧的共同特征从而有效地生成对抗性扰动,多路径聚合模块的输入为f
t
、f
t-1
和f
t+1
,多路径聚合模块的输出为迭代优化后的对抗性扰动δx
′
;f
t
、f
t-1
和f
t+1
分别表示原始图像x
t-1
、x
t
和x
t+1
的特征图,f
t
、f
t-1
和f
t+1
的大小均为b
×h×w×
c=b
×h×w×
c,b、h、w和c分别表示特征图的批量大小、高度、宽度和通道数,b、h、w和c分别表示b、h、w和c的取值;多路径聚合模块的处理过程包括:
[0035]
(61)将f
t-1
投影到f
t
的特征空间,具体过程为:先使用1
×
1卷积处理f
t
和f
t-1
,将f
t
的大小调整为b
×h×w×
c=b
×c×w×
h,将f
t-1
的大小调整为b
×h×w×
c=b
×w×c×
h,对
调整大小的f
t
和f
t-1
进行矩阵相乘,再对结果进行归一化,最终形成大小为b
×h×w×
c=b
×c×c×
h的投影p
t-1
:
[0036]
p
t-1
=resize(bn(resize(conv(f
t-1
)))
×
resize(conv(f
t
)))
[0037]
其中:resize(
·
)表示图像缩放函数,bn(
·
)表示归一化操作,conv(
·
)表示卷积函数;
[0038]
(62)将f
t+1
投影到f
t
的特征空间,具体过程为:先使用1
×
1卷积处理f
t
和f
t+1
,将f
t
的大小调整为b
×h×w×
c=b
×c×w×
h,将f
t+1
的大小调整为b
×h×w×
c=b
×w×c×
h,对调整大小的f
t
和f
t+1
进行矩阵相乘,再对结果进行归一化,最终形成大小为b
×h×w×
c=b
×c×c×
h的投影p
t+1
:
[0039]
p
t+1
=resize(bn(resize(conv(f
t+1
)))
×
resize(conv(f
t
)))
[0040]
(63)从f
t
中减去聚合特征,输出迭代优化后的对抗性扰动δx
′
:
[0041][0042]
其中:concat(
·
)表示合并函数;
[0043]
(64)将对抗性扰动δx
′
添加到原始视频序列x中获得最终的对抗性视频序列
[0044][0045]
其中:表示总体损失函数。
[0046]
多路径聚合模块将前一帧和后一帧的特征图通过变换投影到当前帧上,最后再从当前帧中减去聚合的特征,这种图像级的操作可以有效地集成噪声。
[0047]
优选的,所述步骤(7)中,基于亲和矩阵的自监督视频目标分割,给定一对视频帧,基于以下假设:两个连续的视频帧中的内容是连贯的;帧重建(像素复制)操作可以通过使用亲和矩阵的线性转换来表示,该转换描述了从参考帧到目标帧的复制过程。亲和矩阵中相似性测量的一般选择是特征图之间的点积运算。黑盒对抗攻击的目标是通过破坏视频帧间的亲和矩阵找到一个与分割模型有不可感知差异的对抗样本,使分割模型失效。
[0048]
有益效果:本发明提供的面向自监督视频目标分割的黑盒攻击方法,该方法借助对比损失生成对抗性扰动,能够针对自监督视频目标分割任务进行对抗性攻击,实现将目标的所有像素进行错误分割;本发明能够用于特定任务或特定领域的研究,能够帮助了解黑盒攻击是如何影响模型性能的,有助于减少这些影响因素以增强模型安全性和鲁棒性。
附图说明
[0049]
图1为本发明方法的实施流程图;
[0050]
图2为获取的对抗样本和对抗性预测掩码的示意图;
[0051]
图3为多路径聚合模块结构示意图;
[0052]
图4为一种实现本发明方法的装置的结构示意图。
具体实施方式
[0053]
以下结合附图和具体实施例对本发明作具体的介绍。
[0054]
在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0055]
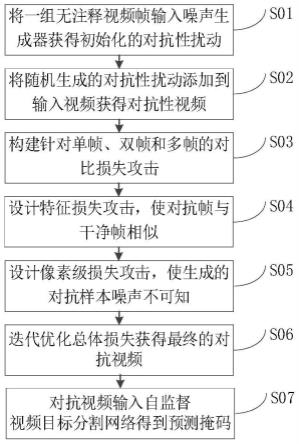
如图1所示为一种面向自监督视频目标分割的黑盒攻击方法的实施流程图,下面就各个步骤加以具体说明。
[0056]
步骤s01:针对无注释的原始视频序列x={x1,x2,
…
,xn},首先通过一个自监督训练的噪声生成器随机生成初始化的对抗性扰动δx={δx1,δx2,
…
δxn};xi表示第i帧的原始图像,δxi表示对应xi的对抗性扰动,i=1,2,
…
,n。
[0057]
步骤s02:将对抗扰动δx添加到原始视频序列x中获得对抗性视频序列x
adv
。
[0058]
对抗性视频序列表示为
[0059][0060]
其中:表示对应xi的对抗样本,ε表示最大允许对抗扰动阈值,||
·
||
∞
表示无穷范数。
[0061]
步骤s03:考虑视频序列间的一致性问题,分别构建针对单帧、双帧和多帧的对比损失攻击,以获得总的对比损失。
[0062]
构建针对单帧、双帧和多帧的对比损失攻击:
[0063][0064][0065]
[0066][0067]
其中:和分别表示针对单帧、双帧和多帧的对比损失函数,l
con
表示总的对比损失函数,xi表示第i帧的原始图像,x
i+1
表示第i+1帧的原始图像,sim(
·
,
·
)表示余弦相似性函数,ν表示温度参数,{x
neg
}是由对抗样本组成的动态队列中元素的集合,{x
pos
}是由原始图像组成的动态队列中元素的集合,m表示每个动态队列中元素的数量。
[0068]
步骤s04:设计特征损失函数,使原始图像在语义上更接近特征空间中的对抗帧,进一步增强对抗性视频序列的可转移性。
[0069]
基于特征提取器f
θ
提取的特征设计特征损失函数;特征提取器f
θ
采用resnet50网络,由resnet50网络的最后一个全连接层的前一层输出输入图像的特征图,θ表示resnet50网络的待学习参数。
[0070][0071]
其中:表示通过特征提取器f
θ
提取到的的特征图,表示通过特征提取器f
θ
提取到的xi的特征图,h、w和c分别表示特征图的高度、宽度和通道数,||
·
||2表示l2范数。
[0072]
步骤s05:设计像素级损失函数,使对抗性视频序列的噪声不可感知。
[0073]
像素级损失函数表示为:
[0074][0075]
其中:xi表示第i帧的原始图像,表示对应xi的对抗样本,||
·
||2表示l2范数。
[0076]
因为扰动模式类似于噪声,平滑图像有助于缓解对抗效应。因此,为了抑制平滑度,在图像像素空间中应用像素级损失。像素级损失表示对抗示例和原始干净示例之间的l2距离。最小化l2距离的目的是在像素级约束对抗性视频序列和干净视频序列之间的差异,以促进对抗性样本的视觉感知。
[0077]
步骤s06:迭代优化总体损失,构建多路径聚合模块获得迭代优化后的对抗性扰动δx
′
,将对抗性扰动δx
′
添加到原始视频序列x中获得最终的对抗性视频序列x
′
adv
。
[0078]
构建多路径聚合模块获得迭代优化后的对抗性扰动δx
′
,如图3所示,多路径聚合模块的输入为f
t
、f
t-1
和f
t+1
,多路径聚合模块的输出为迭代优化后的对抗性扰动δx
′
;f
t
、f
t-1
和f
t+1
分别表示原始图像x
t-1
、x
t
和x
t+1
的特征图,f
t
、f
t-1
和f
t+1
的大小均为b
×h×w×
c=b
×h×w×
c,b、h、w和c分别表示特征图的批量大小、高度、宽度和通道数,b、h、w和c分别表示b、h、w和c的取值;多路径聚合模块的处理过程包括:
[0079]
(61)将f
t-1
投影到f
t
的特征空间,具体过程为:先使用1
×
1卷积处理f
t
和f
t-1
,将f
t
的大小调整为b
×h×w×
c=b
×c×w×
h,将f
t-1
的大小调整为b
×h×w×
c=b
×w×c×
h,对调整大小的f
t
和f
t-1
进行矩阵相乘,再对结果进行归一化,最终形成大小为b
×h×w×
c=b
×c×c×
h的投影p
t-1
:
[0080]
p
t-1
=resize(bn(resize(conv(f
t-1
)))
×
resize(conv(f
t
)))
[0081]
其中:resize(
·
)表示图像缩放函数,bn(
·
)表示归一化操作,conv(
·
)表示卷积
函数;
[0082]
(62)将f
t+1
投影到f
t
的特征空间,具体过程为:先使用1
×
1卷积处理f
t
和f
t+1
,将f
t
的大小调整为b
×h×w×
c=b
×c×w×
h,将f
t+1
的大小调整为b
×h×w×
c=b
×w×c×
h,对调整大小的f
t
和f
t+1
进行矩阵相乘,再对结果进行归一化,最终形成大小为b
×h×w×
c=b
×c×c×
h的投影p
t+1
:
[0083]
p
t+1
=resize(bn(resize(conv(f
t+1
)))
×
resize(conv(f
t
)))
[0084]
(63)从f
t
中减去聚合特征,输出迭代优化后的对抗性扰动δx
′
:
[0085][0086]
其中:concat(
·
)表示合并函数。
[0087]
(64)将对抗性扰动δx
′
添加到原始视频序列x中获得最终的对抗性视频序列
[0088][0089]
其中:表示总体损失函数。
[0090]
(65)计算迭代优化总体损失采用的总体损失函数为:
[0091][0092]
其中:δx
′
表示迭代优化后的对抗性扰动,λ、μ和η分别为l
con
、和的权重参数。
[0093]
(7)给定原始视频序列x的初始帧掩码,将对抗性视频序列x
′
adv
输入自监督视频目标分割网络得到最终预测掩码。
[0094]
如图2所示,为采用本案提供的面向自监督视频目标分割的黑盒攻击方法的结果可视化图,前两行分别是原始视频序列及其正常分割掩码,后两行分别是对抗性扰动添加到原始视频序列中获得的对抗性视频序列及其错误分割的掩码;由附图可以看出,本案提供的方法在原始视频序列中添加人眼很难察觉的对抗性扰动后,自监督视频目标分割模型估计目标边框位置不准确,分割精度显著下降,从而无法正确分割目标对象。
[0095]
如图4所示,为一种实施本发明提供的面向自监督视频目标分割的黑盒攻击方法的装置,该装置包括生成器、resnet网络和多路径聚合模块,生成器是自监督训练的噪声生成器,用于随机生成初始化的对抗性扰动δx,将对抗扰动δx加入原始视频序列x获得对抗性视频序列x
adv
,获得原始视频序列x和对抗性视频序列x
adv
的像素级损失resnet50网络用于构建特征提取器f
θ
,使用特征提取器f
θ
提取原始视频序列x和对抗性视频序列x
adv
的特征图,从而计算特征损失和总的对比损失l
con
;多路径聚合模块用于获得经总体损失迭代优化后的对抗性扰动δx
′
。
[0096]
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本
发明中的具体含义。
[0097]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0098]
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1