一种密集连接模式检测与提取方法
1.本发明涉及一种密集连接模式检测与提取方法,属于异常数据检测技术领域。
背景技术:
2.密集连接模式检测在数据挖掘与机器学习领域得到了广泛的研究,在网络安全、社交网络、合作网络、电信欺诈等领域得到了广泛的应用。例如,在电子商务中,一组账户在一段时间内为一组目标商家提供“刷单好评”,在用户、商家、时间三个维度组成的张量数据中,就会形成密集连接模式。在合作网络中,一组演员与一组导演频繁合作,在演员与导演两个维度组成的张量数据中,也会形成密集连接模式。在张量数据中检测出密集连接模式,对于网络安全监测、社交网络异常检测、电信欺诈检测都是至关重要的。
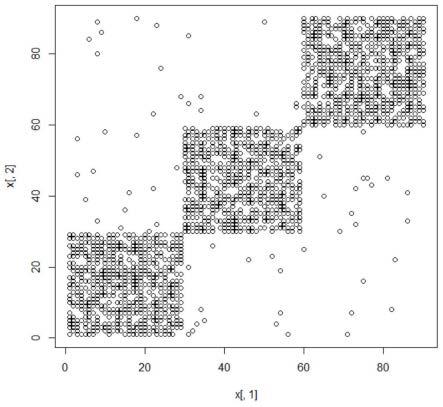
3.现阶段的密集连接模式检测技术及其优缺点如下:1、基于张量分解与密集子图挖掘的密集块检测技术该技术主要包括svd方法,hosvd方法,parafac方法,pagerank/trustrank方法以及其他密集子图挖掘方法,这些方法在早期得到了广泛的研究。基于张量分解与密集子图挖掘的密集快检测技术主要存在两点问题:第一,无法给出可度量的密集程度度量指标;第二,无法实现高维数据跨纬度分析,其中,svd方法与密集子图挖掘方法只能应用于二维张量(矩阵)。
4.2、基于搜索寻优的密集块检测技术基于搜索寻优的方法由于引入度量指标(主要包括基于算术平均数的度量指标、基于几何平均数的度量指标、suspiciousness等),在准确性和灵活性上有了很大提高。这类技术的代表方法有crossspot,m-zoom,d-cube等。基于搜索寻优的方法的主要问题在于:如果存在多个在任意维度不重合、规模相近的密集块,会将多个密集块合并为一个大的密集块,导致搜索结果的准确率很低。例如,在二维张量中,如果存在n个在任意维度互相不重合的、规模相近(例如行数与列数均为k,即k
×
k的密集方阵)的密集块,检测结果会返回一个nk
×
nk的密集块,该检测结果的准确率约为1/n。假设在一个300
×
300的矩阵中,存在3个规模相近的密集块,大小分别为29
×
29,30
×
30,31
×
31,如果三个密集块的位置在任意维度不重合,则利用现有基于搜索寻优的密集块检测算法,最终检测结果如图1所示,可以看出,其中包含大量非密集区域,检测结果的准确率只有1/3左右。
5.3、基于改进的密集程度度量指标的密集块检测方法公开号分别为cn114285601a和cn114218610a的中国发明专利均属于基于改进的密集程度度量指标的密集块检测方法,两者分别提出了 dts与dgcs两种密集程度度量方法。基于dts或dgcs度量方法,利用现有的密集块搜索算法,可以搜索到准确率较高的结果。但是, dts或dgcs结合m-zoom方法时,在搜索过程中会过多删除最终检测到的密集块中的部分属性,导致实际检测到的密集块更小;此外,dts或dgcs结合crossspot方法时,由于crossspot方法对于每个维度的寻优都是寻找该维度下计数最多的前n个列,当张量数据中存在多个小密集块时,前n个计数最多的列会随机分布在不同的小密集块中,因此必然导致
搜索结果是几个小块组成的大密集块,而无法将其中某一个小密集块从中分离出来, 无法有效解决多个规模相近密集块会被合并成一个大密集块的问题。
技术实现要素:
6.针对现有技术中存在的问题,本发明提出了一种密集连接模式检测与提取方法,在改进的度量指标的基础上,进一步改进密集块搜索寻优步骤,从根本上解决密集块合并问题,进一步提高密集块的准确性和可靠性。
7.为解决上述技术问题,本发明采用了如下技术手段:本发明提出了一种密集连接模式检测与提取方法,包括如下步骤:步骤1、获取多维张量数据r;步骤2、利用crossspot方法对多维张量数据r进行收敛,得到密集块b0,并令d= b0;步骤3、利用探针法检测张量数据d,得到更新后的密集块b
γ
;步骤4、根据更新后的密集块b
γ
,对张量数据d进行变宽单维度迭代调整,迭代收敛后得到迭代后的密集块b
δ
;步骤5、根据密集块b
δ
的可疑程度,判断是否满足预设的终止条件,如果满足,输出密集连接模式检测结果,否则,重复步骤3~5。
8.进一步的,设多维张量数据r={r1,r2,
…
,ri,
…
,rk} ,其中,k为多维张量数据r的维数,ri={a
i,1
,a
i,2
,
…
,a
i,j
,
…
,a
i,length(ri)
},a
i,j
表示第i个维度中第j个属性,length(ri)表示ri的长度,即第i个维度中属性的数量。
9.进一步的,在步骤2中,利用crossspot方法对多维张量数据r进行收敛,得到密集块b0的方法为:在多维张量数据r中随机选取一个子张量作为初始随机种子密集块;基于初始随机种子密集块,利用crossspot方法对多维张量数据r进行收敛,得到密集块b0,初始化last_b=b0,last_metric=metric(b0,r),并令d=b0,其中,metric(b0,r)表示密集块b0相对于张量数据r的可疑程度。
10.进一步的,步骤3的具体操作如下:在张量数据d的k个维度中随机选取一个维度di,在di中选取第j列作为探针,di中第j列的属性值为pa(i);利用张量数据d中每个元素在k个维度下对应的属性值组成有序数组,并用该有序数组表示元素的坐标,记为,其中,表示元素在第s个维度下对应的属性值;判断探针所在列上的每个元素是否为零,如果为零,获取该元素的坐标{di=pa
(i),
},其中,g表示该元素在除i之外的k-1个维度的坐标表示;将张量数据d中所有k-1个维度下坐标表示为g的元素去除,得到更新后的密集块b
γ
。
11.进一步的,在步骤4中,令dim_array={i,1,2,
…
,i-1,i+1,
…
,k},其中,i为步骤3中选取的维度,按照dim_array的维度顺序,对张量数据d进行变宽单维度迭代调整,迭代收敛后得到迭代后的密集块b
δ
。
12.进一步的,步骤4的具体操作如下:
初始化迭代次数r=1;在第r次迭代中,按照dim_array的维度顺序依次对k个维度进行变宽单维度调整,得到第k个维度下变宽单维度调整后的密集块bk*,输出第r次迭代的密集块br= bk*;如果r》1,计算第r次迭代与第r-1次迭代的密集块可疑程度之差ε,ε=metric(br,r)
‑ꢀ
metric(b
r-1
,r),如果|ε|《10-6
,则迭代停止,输出迭代后的密集块b
δ
= br,否则r=r+1,进入下一次迭代。
13.进一步的,令m∈dim_array,对第m个维度进行变宽单维度调整的方法为:令bm={},max_metric =
ꢀ‑
∞,max_ b’={};获取密集块b”中除m之外的k-1个维度的映射区域,计算第m个维度下每个属性在该映射区域内的计数,其中,当m=i且r=1时,密集块b”=b
γ
,当m=i且r》1时,密集块b”= b
r-1
,b
r-1
表示第r-1次迭代后的密集块,当m≠i时,密集块b”= bn*,bn*为dim_array中m的前一个维度n下变宽单维度调整后的密集块;根据计数将第m个维度下的属性降序排序,得到第m个维度的降序列表pm={p
m,1
,p
m,2
,
…
,p
m,length(pm)
},其中,count(p
m,1
)≥count(p
m,2
)≥
…
≥count(p
m,length(pm)
),count(p
m,1
)表示属性p
m,1
在映射区域内的计数,length(pm)表示降序列表pm的长度;按照pm中的排序将张量数据d中的属性列依次插入bm中,每插入一个属性列,利用bm结合密集块b”中除m之外的k-1个维度的属性得到一个数据快照b’,如果b’相对于张量数据r的可疑程度metric(b’,r)≥max_metric,则max_metric=metric(b’,r),max_ b’= b’,直至pm为空,输出第m个维度下变宽单维度调整后的密集块bm*= max_ b’。
14.进一步的,步骤5的具体操作为:计算迭代后的密集块b
δ
相对于张量数据r的可疑程度metric(b
δ
,r),如果metric(b
δ
,r) 》last_metric,令d=b
δ
,last_metric= metric(b
δ
,r),last_b=b
δ
,并返回步骤3,如果metric(b
δ
,r) ≤last_metric,输出last_b作为密集连接模式检测结果。
15.进一步的,利用度量指标dts或dgcs度量密集块的可疑程度。
16.采用以上技术手段后可以获得以下优势:本发明提出了一种密集连接模式检测与提取方法,在现有的密集块检测方法crossspot的基础上,对密集块的检测步骤进行改进,先利用crossspot方法收敛一个初始的密集块,基于初始的密集块进行后续检索,能够提高检测准确性;在第一层检测中通过探针法去除张量数据中的部分数据,保留较为密集的数据,在第二层检测中根据第一层的输出进行变宽单维度迭代调整,获取可能的小密集块,然后不断的循环两层检测,直至得到可疑程度最大的密集块。本发明方法每个维度的寻优都是在之前检测结果的约束下进行的,由于探针法会去除部分数据,将密集数据缩小在一定区域内,因此第二层计数靠前的列会集中在该区域内,不会随机分布在不同的小块中,进而能够在张量数据中包含多个小密集块的情况下,提取出某个小密集块,而不是多个小密集块组成的大密集块。本发明方法可以有效避免多个规模相近的密集块合并为一个大的密集块的问题,进一步提高了细粒度密集块检测的准确性,对网络安全监测、社交网络异常检测、电信欺诈检测等密集连接模式检测领域具有重要意义。
附图说明
17.图1为基于搜索寻优的密集块检测技术的检测结果示意图;图2为本发明一种密集连接模式检测与提取方法的步骤流程图;图3为本发明实施例中密集连接模式检测与提取的操作流程图。
具体实施方式
18.下面结合附图对本发明的技术方案作进一步说明:本发明提出了一种密集连接模式检测与提取方法,在传统crossspot搜索方法的基础上进行改进,提出probe-crossspot搜索方法,probe-crossspot包括两层检测操作,第一层检测是随机选取一个维度利用探针法去除张量数据中的部分数据,检测出较为密集的数据,第二层检测是在第一层循环结果的基础上,对张量数据的k个维度迭代进行变宽单维度调整,进一步检索张量数据中的密集数据,完成一次probe-crossspot搜索(即一次循环)后,根据当前循环与上一次循环的结果差判断是否要继续循环,直至得到最优解。
19.如图2、3所示,本发明方法具体包括如下步骤:步骤1、获取多维张量数据r,假设多维张量数据r的维数为k,则r={r1,r2,
…
,ri,
…
,rk} ,其中,ri表示张量数据r的第i个维度的数据,ri={a
i,1
,a
i,2
,
…
,a
i,j
,
…
,a
i,length(ri)
},a
i,j
表示第i个维度中第j个属性,length(ri)表示ri的长度,即第i个维度中属性的数量。
20.假设有一个3
×
3的二维张量数据r如下表所示,其中,张量数据r的两个维度分别是姓名和时间,姓名维度下的属性值分别为张三、李四、王五,实现维度下的属性值分别为10点、14点、18点。
21.表1在本发明实施例中,多维张量数据的获取方法如下:1、数据集成,通过etl技术将待检测数据集成到指定数据中心;2、数据脱敏,在待检测数据中通过脱敏技术对生产环境中的敏感信息(例如身份证号)进行脱敏处理;3、数据清洗,对脱敏后的数据进行清洗操作,确保数据的准确性、一致性;4、数据预处理,对清洗后的数据进行数据建模,将待检测数据转换为多维张量数据。
22.在本发明实施例中,利用公开号为cn114285601a的中国发明专利中的dts值或公开号为cn114218610a1的中国发明专利中的dgcs值作为密集块可疑程度度量指标,进行密集块检测。密集块b相对于张量r的dts或dgcs值,记为metric(b,r),需要强调的是:本发明中所有关于密集块block密集程度度量指标的计算,都是关于r的,即metirc(block,r)。
23.步骤2、利用crossspot方法对多维张量数据r进行收敛,得到密集块b0,具体的:步骤201、在多维张量数据r中随机选取一个子张量作为初始随机种子密集块,这个过程记为b=random_seed(d)。
24.步骤202、基于初始随机种子密集块,利用crossspot方法对多维张量数据r进行收敛,得到密集块b0,令d=b0,用于后续处理,并初始化last_b=b0,last_metric=metric(b0,r),并令d= b0,其中,metric(b0,r)表示密集块b0相对于张量数据r的可疑程度。
25.步骤3、执行probe子流程;利用探针法检测张量数据d,得到更新后的密集块b
γ
。
26.步骤301、在张量数据d的k个维度中随机选取一个维度di,在di中选取第j列作为探针,di中第j列的属性值为pa(i)。
27.步骤302、利用张量数据d中每个元素在k个维度下对应的属性值组成有序数组,并用该有序数组表示元素的坐标,记为,其中,表示元素在第s个维度下对应的属性值。则探针所在列上所有元素的坐标组成一个集合pai_set={:di=pa(i)}。以表1为例,表1中各个元素的坐标可以表示为(张三,10点)、(张三,14点)、(张三,18点)、(李四,10点)、(李四,14点)、(李四,18点),(王五,10点)、(王五,14点)、(王五,18点),假设选取姓名维度的第1列,即张三,作为探针,则探针所在列的坐标集合为pai_set={(张三,10点)、(张三,14点)、(张三,18点)}。
28.步骤303、判断探针所在列上的每个元素是否为零,如果为零,获取该元素的坐标{di=pa
(i),
},其中,g表示该元素在除i之外的k-1个维度的坐标表示,即该元素在除i之外的k-1个维度对应的属性值的集合。
29.步骤304、将张量数据d中所有k-1个维度下坐标表示为g的元素去除,得到更新后的密集块b
γ
,在本发明中,将元素去除是指将该元素的值置零。
30.根据表1可知,张三列上第2个元素(即(张三,14点))的值为0,因此g=(14点)将张量数据d中所有坐标包含14点的元素的值置零,得到更新后的密集块b
γ
:表2步骤4、根据更新后的密集块b
γ
,对张量数据d进行变宽单维度迭代调整,迭代收敛后得到迭代后的密集块b
δ
。
31.步骤401、数据初始化,令ε=+∞,迭代次数r=1,dim_array={i,1,2,
…
,i-1,i+1,
…
,k},其中,i为步骤3中选取的维度,按照dim_array的维度顺序,对张量数据d进行变宽
单维度迭代调整。如果i=k,dim_array={k,1,2,
…
,k-1}。
32.步骤402、在第r次迭代中,按照dim_array的维度顺序依次对k个维度进行变宽单维度调整,得到第k个维度下变宽单维度调整后的密集块bk*,输出第r次迭代的密集块br= bk*,如果i=k,br= b
k-1
*。
33.在步骤402中,变宽单维度调整的具体操作如下:(1)令m∈dim_array, bm={},max_metric =
ꢀ‑
∞,max_ b’={}。
34.(2)获取密集块b”中除m之外的k-1个维度的映射区域,计算第m个维度下每个属性在该映射区域内的计数,其中,当m=i且r=1时,即第一次迭代中排序第一的维度下,密集块b
”ꢀ
=b
γ
,当m=i且r》1时,密集块b”= b
r-1
,b
r-1
表示第r-1次迭代后的密集块,当m≠i时,即不是排序第一的维度下,密集块b”= bn*,bn*为dim_array中m的前一个维度n下变宽单维度调整后的密集块。需要注意的是,当m=1时,n=i,当m=i+1时,n=i-1。
35.(3)根据计数将第m个维度下的属性降序排序,得到第m个维度的降序列表pm={p
m,1
,p
m,2
,
…
,p
m,length(pm)
},其中,count(p
m,1
)≥count(p
m,2
)≥
…
≥count(p
m,length(pm)
),count(p
m,1
)表示属性p
m,1
在映射区域内的计数,length(pm)表示降序列表pm的长度。
36.(3)按照pm中的排序将张量数据d中的属性列插入bm中,每插入一个属性列,利用bm结合密集块b”中除m之外的k-1个维度的属性得到一个数据快照b’。如果b’相对于张量数据r的可疑程度metric(b’,r)≥max_metric,则max_metric=metric(b
m’,r),max_ b’= b’;不断比较可疑程度,直至pm为空,输出第m个维度下变宽单维度调整后的密集块bm*= max_ b’。
37.重复步骤(1)~(3),即可完成k个维度的变宽单维度调整,得到k个变宽单维度调整后的密集块,其中,排序最后的密集块即为当前迭代的密集块。
38.步骤403、当r》1时,每完成一次迭代,进行迭代收敛判断:计算第r次迭代与第r-1次迭代的密集块可疑程度之差ε,ε=metric(br,r)
‑ꢀ
metric(b
r-1
,r),如果|ε|《10-6
,则迭代停止,输出迭代后的密集块b
δ
= br,如果|ε|≥10-6
,令r=r+1,返回步骤402,计算下一次迭代的密集块。
39.步骤5、根据密集块b
δ
的可疑程度,判断是否满足预设的终止条件,如果满足,输出密集连接模式检测结果,否则,重复步骤3~5。具体的:计算迭代后的密集块b
δ
相对于张量数据r的可疑程度metric(b
δ
,r),如果metric(b
δ
,r) 》last_metric,令d=b
δ
,last_metric= metric(b
δ
,r),last_b=b
δ
,并返回步骤3,如果metric(b
δ
,r) ≤last_metric,输出last_b作为密集连接模式检测结果。
40.本发明方法通过循环检测获取张量数据中的密集块,先利用crossspot方法收敛一个初始的密集块,然后利用探针法再去除部分数据,进一步缩小密集数据区域,之后在探针结果的约束下对张量数据的每个属性进行计数,由于探针结果的影响,计数靠前的列会集中在某个小区域内,而不会随机分布在不同的小块中,因此,当张量数据中包含多个小密集块的情况下,本发明方法能够提取出某个小密集块,而不是多个小密集块组成的大密集块。本发明方法可以有效避免多个规模相近的密集块合并为一个大的密集块的问题,进一步提高了细粒度密集块检测的准确性。此外,利用本发明方法进行密集块检测,还能够解决基于dts或dgcs指标时m-zoom方法会过多删除最终检测到的密集块中的部分属性的问题。本发明方法是对现有技术的进一步改进,在现有技术的基础上进一步提高了密集块检测的准确率和效率。
41.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1