一种基于表面监测和遗传算法优化的垃圾填埋场甲烷排放估算方法
1.本发明主要涉及环境岩土和随机搜索算法领域,特别是一种基于表面监测和遗传算法优化的垃圾填埋场甲烷排放估算方法。
背景技术:
2.甲烷作为仅次于二氧化碳的第二大温室气体,其排放量约占全球温室气体排放的20%,且在短期内对全球温室效应影响更加显著。
3.城市固体废弃物填埋场在处理过程中会产生大量甲烷气体,且随着中小型生活垃圾填埋处理量维持增长趋势,其量级尚达不到焚烧的要求,以致垃圾填埋场存在巨大的甲烷治理需求。为助力甲烷减排,有必要将填埋场中有机物分解产生的甲烷逸散排放进行量化。
4.目前我国已有学者提出一些气体污染源扩散溯源方法,但大多针对的是化工园区等建筑群内,利用红外光谱定量分析结合掩日通量法(sof)扩散模型的,结合相应的优化算法进行分析;或是基于无人车搭载传感器结合溯源算法直接获取污染源坐标。这些方法部分需要大量数据进行构建数据库在库内进行搜索,部分方法对于环境场地的要求较高,无法适用于固体废弃物填埋场的复杂地形条件,同时也没有将实测气体浓度与释放通量相结合。因此,非常有必要提出一种适用于固体废弃物填埋场复杂条件下的甲烷排放估算方法,同时可搜索到多个泄露点坐标与相应的释放通量。
技术实现要素:
5.本发明的目的在于提供一种基于表面监测和遗传算法优化的垃圾填埋场甲烷排放估算方法,对于国内固体废弃物填埋场寻找场内甲烷等污染气体泄露点,即表面覆膜破损处具有重要意义。
6.本发明通过以下技术方案实现:
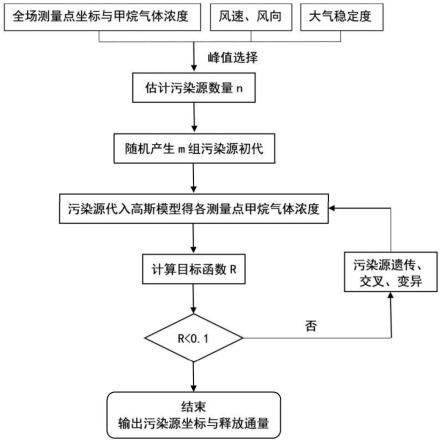
7.一种基于表面监测和遗传算法优化的垃圾填埋场甲烷排放估算方法,具体包括以下步骤:
8.s1:基于垃圾填埋场全场甲烷浓度监测数据,由甲烷浓度峰值数量得到全场泄露点数量估计值n;
9.s2:基于全场泄露点数量估计值n,使用遗传算法,随机生成m组作为初代,各组包含n个假定泄露点坐标与释放通量;
10.s3:基于假定泄露点坐标与释放通量,结合监测到的风速风向与大气稳定度信息,代入高斯模型得到全场甲烷模拟浓度分布情况,并将计算得到的全场甲烷浓度分布情况与监测结果进行对比,计算各组假定泄露点目标函数r;对比不同组假定泄露点目标函数r,若r
min
<0.1,则进入步骤s5,否则进入步骤s4;其中,r
min
表示不同组假定泄露点目标函数r中的最小值;
11.s4:使用遗传算法,对上一代中的m组假定泄露点坐标与释放通量进行遗传、变异、交叉,生成新一代m组假定泄露点坐标与释放通量,返回步骤s3。
12.s5:输出r
min
对应的一组泄露点坐标与甲烷释放通量作为估算结果。
13.进一步地,步骤s1中由垃圾填埋场甲烷浓度监测数据插值得到所述的全场甲烷浓度监测数据,从全场甲烷浓度监测数据中找到所有峰值,取浓度最大值为c
max
;将所有峰值与c
max
的10%进行比较,将峰值大于c
max
的10%的峰值数量作为全场泄露点数量估计值。
14.进一步地,步骤s2中,所述的假定泄露点坐标与释放通量满足:
15.x
min
≤xj≤x
max
;j=1,...,p
16.y
min
≤yj≤y
max
;j=1,...,p
17.q
min
≤qj≤q
max
;j=1,...,p
18.其中,xj,yj分别表示第j个假定泄露点的横坐标和纵坐标,x
min
,x
max
分别表示垃圾填埋场横坐标的最小值和最大值,y
min
,y
max
分别表示垃圾填埋场纵坐标的最小值和最大值,qj表示第j个假定泄露点的甲烷释放通量,q
min
,q
max
表示释放通量估计值的最小值和最大值。
19.进一步地,步骤s3所述的高斯模型为:
[0020][0021]
式中:x是监测点与假定泄露点之间沿风向的顺风距离,y是监测点与假定泄露点之间沿风向的垂直距离,z为地表上的垂直距离,h为监测点处的甲烷监测器高度;c为点(x,y,z)处的稳态甲烷气体浓度;q为排放速率;σy和σz为水平和垂直扩散系数;u为平均风速;;
[0022]
对于地面源和甲烷监测器,z=0,h=0,得到简化后的高斯模型为:
[0023][0024]
将n个假定泄露点坐标与释放通量代入简化后的高斯模型,得到全场甲烷模拟浓度分布情况,各个监测点处的甲烷监测器得到的甲烷浓度值为n个泄露点对该监测点浓度贡献之和,将监测点测得的浓度模拟值表示为:
[0025][0026]
其中,c
i,j
表示第j个泄露点对第i个监测点的模拟浓度贡献量,c
i,模拟
表示第i个监测点的模拟浓度监测值;
[0027]
将监测点测得的模拟浓度监测值与实际浓度监测值进行比较,计算目标函数r,所述的目标函数r为模拟浓度监测值与实际浓度监测值之间的归一化估计误差:
[0028][0029]
其中,c
i,监测
表示第i个监测点测得的实际浓度监测值,p表示监测点数量。
[0030]
进一步地,所述的步骤s4包括:
[0031]
(4-1)遗传:先取上一代m组假定泄露点坐标与释放通量作为本代m组泄露点初始值;
[0032]
(4-2)变异:将本代各组泄露点初始值进行变异操作,组内各值随机赋值0~1,与变异系数进行比较,小于变异系数则将该值进行突变,且在变异过程中确保突变值满足步骤s2中假定泄露点坐标与释放通量的条件;
[0033]
(4-3)交叉:将本代变异后的各组泄露点坐标与释放通量进行交叉操作,每组随机赋值0~1,与交叉系数进行比较,小于交叉系数则将改组随机与其他组值进行交叉。
[0034]
进一步地,所述的步骤s5具体为:经过多次遗传、变异、交叉操作后,直至最小的一组假定泄露点数据的目标函数r减小至小于标准值0.1,则输出该组的n个泄露点坐标与释放通量,将其作为输出结果。
[0035]
本发明相对于现有技术而言,具有以下有益效果:
[0036]
本发明通过使用遗传算法进行随机搜索,简化了寻找甲烷气体泄露点坐标与释放通量的计算,能够在保证计算可靠性的前提下得到最契合全场实际监测浓度分布的结果;本发明提出了将高斯模型与遗传算法相结合的搜索方法,为实际工程应用中寻找泄露点坐标并量化全场污染气体排放情况提供了思路。
附图说明
[0037]
图1是本发明实施例示出的垃圾填埋场甲烷排放估算方法的流程图。
[0038]
图2是高斯模型示意图。
[0039]
图3是实测全场甲烷浓度图与9个峰值点。
[0040]
图4是9个预测泄露点与其产生的全场甲烷浓度图。
具体实施方式
[0041]
下面将以某填埋场全场甲烷监测数据为例,结合附图、表对本发明作进一步阐述和说明,本发明中各个实施方式的技术特征在没有相互冲突的前提下,均可进行相应组合。
[0042]
如图1所示,本发明提出的一种基于表面监测和遗传算法优化的垃圾填埋场甲烷排放估算方法主要包括以下步骤:
[0043]
步骤1):基于垃圾填埋场全场甲烷浓度监测数据情况(表1),可插值得到全场的甲烷浓度分布,再利用matlab中的findpinks函数找到所有峰值,经计算,全场甲烷浓度总共存在67个峰值点,其中甲烷浓度最大值为12844.74ppm。
[0044]
再将67个峰值点浓度与甲烷浓度最大值的10%,即1284.47ppm进行比较,共有9个峰值点的甲烷浓度大于该值,故估计全场存在9个甲烷气体泄露点,即n=9。
[0045]
监测点按照正交网格布置,网格边长约30m。本实施例中,监测点数量为p=311。
[0046]
表1全场甲烷浓度监测坐标与浓度值
[0047]
[0048]
[0049]
[0050][0051]
步骤2):使用遗传算法,随机生成100组作为初代,各组含9个假定泄露点坐标与释放通量。
[0052]
由于每个泄露点包含坐标x,y以及释放通量q共3个特征值,故每组应当包括27个特征值,那么只需建立一个100
×
27的矩阵,并利用rand函数随机生成满足边界条件的初代,边界条件如下:
[0053]
x
min
≤xj≤x
max
;j=1,...,p
[0054]ymin
≤yj≤y
max
;j=1,...,p
[0055]qmin
≤qj≤q
max
;j=1,...,p
[0056]
其中,xj,yj分别表示第j个假定泄露点的横坐标和纵坐标,x
min
,x
max
分别表示垃圾填埋场横坐标的最小值和最大值,y
min
,y
max
分别表示垃圾填埋场纵坐标的最小值和最大值,qj表示第j个假定泄露点的甲烷释放通量,q
min
,q
max
表示释放通量估计值的最小值和最大值。
[0057]
步骤3):计算并保留r最小的一组泄露点
[0058]
结合监测风速风向与大气稳定度,风速为1.0m/s,风向为西北风,大气稳定度为a级,如图2所示,以假定泄漏点(xi,yi)为例,风向与北向的夹角为θ,风吹过假定泄漏点(xi,yi)之后,监测点与假定泄露点(xi,yi)之间沿风向的垂直距离记为y,监测点与假定泄露点(xi,yi)之间沿风向的顺风距离记为x。
[0059]
将假定泄露点坐标与释放通量、风速、风向与大气稳定度信息代入高斯模型:
[0060][0061]
式中:c为点(x,y,z)稳态甲烷气体浓度(μg/m3);q为排放速率(μg/s);σy和σz为水平和垂直扩散系数,是顺风距离x和大气稳定度的函数;u为平均风速(m/s);y为顺风垂直距离(m);z为地表上垂直距离(m);h为监测点处的甲烷监测器堆叠高度(m)。
[0062]
本实施例中,大气稳定度等级根据地表风速、日晒强度、夜间条件等决定,如表2所示。根据不同等级的大气稳定度设计σy和σz扩散系数的计算公式,如表3所示。大气稳定度等级和σy和σz扩散系数的计算公式还可以根据实际需求进行修改。
[0063]
表2定义大气稳定度等级的气象条件
[0064][0065]
表3色散系数的briggs模型
[0066]
大气稳定度等级σy(m)σz(m)a0.22x(1+0.0001x)-0.5
0.20xb0.16x(1+0.0001x)-0.5
0.12xc0.11x(1+0.0001x)-0.5
0.08x(1+0.0002x)-0.5
d0.08x(1+0.0001x)-0.5
0.06x(1+0.0015x)-0.5
e0.06x(1+0.0001x)-0.5
0.03x(1+0.0003x)-1
f0.04x(1+0.0001x)-0.5
0.016x(1+0.0003x)-1
[0067]
对于地面源和甲烷监测器(z=0,h=0),上述方程可简化为:
[0068][0069]
代入初代100组各组的9个泄露点坐标与释放通量,得到全场甲烷模拟浓度分布,各个监测点甲烷浓度值为9个泄露点对该点浓度贡献之和:
[0070][0071]
并与监测结果进行比较,计算目标函数r,r为模拟值与监测值之间的归一化估计误差:
[0072][0073]
经过100代运算,100组中最小的r值为0.796,相应假设的9个泄露点坐标与释放通量如表3所示,保留该组泄露点。
[0074]
表4目标函数r最小的一组假设泄露点
[0075][0076]
步骤4):使用遗传算法进行遗传、交叉、变异
[0077]
(4-1)遗传:先取上一代m组假定泄露点坐标与释放通量作为本代m组泄露点初始值;
[0078]
(4-2)变异:设置变异系数为0.1,将本代各组泄露点初始值进行变异操作,组内各值随机赋值0~1,与变异系数进行比较,小于变异系数则将该值进行突变,且检查确保突变值满足步骤2中的边界条件;
[0079]
(4-3)交叉:设置交叉系数为0.1,将变异后的各组泄露点坐标与释放通量进行交叉操作,每组随机赋值0~1,与交叉系数进行比较,小于交叉系数则将改组随机与其他组值进行交叉。
[0080]
再经过100代运算,100组中最小的r值为0.735,相应假设的9个泄露点坐标与释放通量如表5所示,保留该组泄露点。
[0081]
表5目标函数r最小的一组泄露点
[0082][0083]
步骤5):得到目标函数r满足标准的泄露点
[0084]
进行多代运算后,当目标函数r小于0.1,则输出该组r值对应的泄露点坐标与释放通量。当计算得r=0.092,该值小于0.1,输出对应的9个泄露点坐标与释放通量,如表6所示,最终输出该组泄露点坐标与甲烷释放通量作为估算结果,如图4所示。
[0085]
表6目标函数r=0.092的泄露点坐标与释放通量
[0086][0087]
同时,对比实测全场甲烷浓度图(如图3所示)与预测甲烷浓度图(如图4所示),图3中的圆点为311个监测点位置,星号为筛选出的9个峰值点位置,图3为由311个监测点测得的甲烷浓度插值生成的全场甲烷实际浓度分布图;图4中的星号为算法最终得到的9个预测泄露点位置,并由其位置与通量经高斯模型得到的全场甲烷模拟浓度分布图。可以看出,图3和图4所示的全场甲烷浓度分布接近,本发明能够在保证计算可靠性的前提下得到最契合全场实际监测浓度分布的多个泄露点坐标与通量结果,设计方法可靠,计算方便快捷,结果客观准确。
[0088]
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1