一种连续型栅格数据的存储及读取方法
1.本发明涉及栅格数据处理领域,具体涉及一种连续型栅格数据的存储及读取方法。
背景技术:
2.栅格数据模型将地理空间划分成若干行、列组成的像元阵列,其最小单元称为像元或像素,每个像元的位置由行列号确定,通过像元的值记录这一位置的某类地理属性值。像元值为整数类型的栅格数据通常用来存储各种离散型数据或分类型数据,例如土地利用类型栅格数据,其每个像元存储的是一个整数,代表着该像元对应的地理空间的土地利用类别,如整数1代表耕地,整数2代表林地,整数3代表草地,等等;离散型栅格数据的特点之一是不能对像元值直接进行算术计算,例如对像元值分别为1和2的两个像元进行均值计算得到像元值1.5是没有意义的;连续型栅格数据是每个像元值具有连续性特点,例如dem栅格数据,在最大像元值和最小像元值之间任意数值都可以作为某像元值。
3.假设某连续型栅格数据是由k行l列个栅格像元组成,每个栅格像元对应的数值是double类型的浮点值,按目前栅格数据模型的通常做法,则需要k*l*8个字节,当该栅格数据的覆盖区域较大、分辨率较高(如每个像元对应1米长宽区域)时则栅格的行列数k*l较大,所需要的存储空间非常大,这对系统的存储设备成本、网络传输效率都是很大的挑战。
技术实现要素:
4.本发明所要解决的技术问题是提供一种连续型栅格数据的存储及读取方法,可以有效的减少数据存储量,节约存储设备成本、提高网络传输效率。
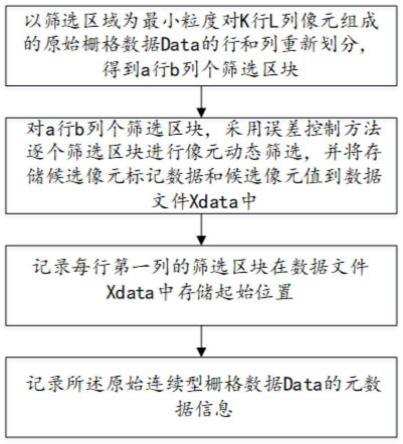
5.一种连续型栅格数据的存储方法,对由k行l列像元组成的原始分类栅格数据data进行存储,包括以下步骤:
6.s1.重新划分原始分类栅格数据data的行和列:
7.以筛选区域为最小粒度对k行l列像元组成的原始栅格数据data的行和列重新划分,得到a行b列个筛选区块;
8.当k/s1为整数时,a=k/s1;
9.当k/s1不为整数时,a=[k/s1]+1;
[0010]
当l/s2为整数时,b=l/s2;
[0011]
当l/s2不为整数时,b=[l/s2]+1;
[0012]
其中,筛选区域为s1行s2列的栅格数据矩阵,s1、s2为常数,s1》=3,s2》=3;
[0013]
s2.对a行b列个筛选区块,采用误差控制方法逐个筛选区块进行像元动态筛选,并将存储候选像元标记数据和候选像元值到数据文件xdata中;
[0014]
s3.记录每行第一列的筛选区块在数据文件xdata中存储起始位置;
[0015]
s4.记录所述原始连续型栅格数据data的元数据信息。
[0016]
进一步地,s2中对a行b列个筛选区块,采用误差控制逐个筛选区块进行像元动态
筛选,具体包括以下步骤:
[0017]
在a行b列个筛选区块中选择多个特征点作为候选像元;
[0018]
确定最大绝对误差阈值e参数值;
[0019]
根据候选像元采用最大绝对误差阈值e参数值逐层插值计算,以此进行像元动态筛选。
[0020]
进一步地,进行像元动态筛选具体包括以下步骤:
[0021]
在两两候选像元选取中间像元,计算中间点像元的计算值,判断中间像元的计算值与其真实值的误差是否在最大误差阈值e内,若是则中间像元不作为筛选候选像元,否则中间像元作为候选像元;逐行逐列进行筛选直至所有像元筛选完毕。
[0022]
进一步地,所述步骤2中将存储候选像元标记数据和候选像元值到数据文件xdata中;以数值ts记录当前筛选区块存储时所需要的字节大小,初始为0;
[0023]
对筛选区块逐行逐列标记每个像素筛选情况,若该像元作为候选像元,则设置标记数据b[i][j]=1,否则设置标记数据b[i][j]=0;
[0024]
若s1*s2是8的倍数ts值为s1*s2/8;若s1*s2不是8的倍数,即标记数据b[][]不能完整的划分为整数个字节,则在末尾补充值为0的bit位至完整的一个字节,ts值为[s1*s2/8]+1;
[0025]
将候选像元标记数据b[][]以字节为单位写入ts个字节到数据文件xdata;将上述筛选的候选像元像素值按顺序写入数据文件xdata。
[0026]
进一步地,所述步骤3记录每行第一列的筛选区块在数据文件xdata中存储起始位置,包括以下步骤:记录下每一行中各个列筛选区块的存储空间大小ts的累计值sumts,并写入数据文件rowsize中。
[0027]
进一步地,所述步骤4中,元数据信息包括:原始连续型栅格数据data的行数k、列数l;筛选区域s1、s2值,最大绝对误差阈值e参数值。
[0028]
还提供了一种连续型栅格数据的读取方法,用于对按照上述的一种连续型栅格数据的存储方法存储的栅格数据进行读取,若要读取原始分类栅格数据data的第r行第c列像元数值的栅格单元数据d(r,c),其中,1《=r《=k,1《=c《=l,包括以下步骤:
[0029]
步骤1.读取数据文件meta,获得原始连续型栅格数据data的元数据信息,得到原始连续型栅格数据data的行数k、列数l;筛选区域s1、s2值,最大绝对误差阈值e参数值,计算出数据文件xdata中共有a行b列个筛选区块;
[0030]
步骤2.计算第r行第c列像元所在的筛选区块编号,假设该请求像元所在的筛选区块的行号为v、列号为z;
[0031]
当r/s1为整数时,v=r/s1;
[0032]
当r/s1不为整数时,v=[r/s1]+1;
[0033]
当c/s2为整数时,z=c/s2;
[0034]
当c/s2不为整数时,z=[c/s2]+1;
[0035]
步骤3.读取数据文件rowsize,获得a个整数值,e1、e2、...、ea;
[0036]
当v=1时,第1行的第一列筛选区块的数据起始于数据文件xdata的0字节处,此时offset=0;
[0037]
当v》1时,第v行的第一列筛选区块的数据起始于数据文件xdata的e(v-1)字节处,
此时offset=e(v-1);
[0038]
从第offset字节处开始读取数据文件xdata,逐个解析筛选区块的信息,以此计算得到请求像元所在筛选区块中的像素值。
[0039]
进一步地,对于步骤3逐个解析筛选区块的信息,所述解析筛选区块的信息包括读取候选像元标记数据、读取候选像元值数据。
[0040]
进一步地,解析筛选区块的信息以此计算得到请求像元所在筛选区块中的像素值,具体包括以下步骤:
[0041]
若当前读取的是第j列个筛选区块,1《=j《=z;
[0042]
读取候选像元标记数据:
[0043]
若s1*s2是8的倍数则从数据文件xdata中读取s1*s2/8个字节为候选像元标记数据;若s1*s2不是8的倍数则从数据文件xdata中读取[s1*s2/8]+1个字节,取前s1*s2个bit位数据为候选像元标记数据;
[0044]
读取候选像元值数据:
[0045]
累计s1*s2个bit位候选像元标记数据中值为1的bit位个数m,从数据文件xdata中读取m个double类型的数值v1、v2、v3、...、vm,分别对应筛选区块中s1*s2个的m个候选像元值;
[0046]
若j==z,则根据这m个候选像元值进行插值计算得到筛选区块中所有像素值;
[0047]
若j!=z,则请求的像元不在该筛选区块中,不需要解析该筛选区块中的像元值,继续处理下一列的筛选区块数据。
[0048]
进一步地,所述插值计算得到筛选区块中所有像素值包括以下步骤:
[0049]
对于两两候选像元的中间像元插值之前,判断该中间像元值是否属于候选像元,若是候选像元则不需要进行插值计算,直接确定该中间像元值为候选像元值,若不是,则将插值计算结果作为中间像元值;逐行多次进行插值处理可得到筛选区块中所有像素值;
[0050]
再根据请求像元的行列号r、c,得到在该筛选区块中的像素位置,进而确定像素值,读取结束。
[0051]
与现有技术相比,本发明具有如下技术效果:
[0052]
本发明根据指定的特征点像元值进行多层次的行、列像素的插值筛选,只要某行、某列中的像元数值有部分接近时就有数据压缩效果,不依赖于最初指定的特征点像元值,具有更优的数据压缩效率。
附图说明
[0053]
图1为本发明的系统整体结构示意图。
具体实施方式
[0054]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0055]
参照图1,一种连续型栅格数据的存储方法,对由k行l列像元组成的原始分类栅格数据data进行存储,为方便叙述,下文中原始分类栅格数据data像元及分块的行列编号都是从1开始计数。在本技术中,符号[x],表示不大于x的最大整数。
[0056]
连续型栅格数据的存储方法包括以下步骤:
[0057]
s1.重新划分原始分类栅格数据data的行和列:
[0058]
以筛选区域为最小粒度对k行l列像元组成的原始栅格数据data的行和列重新划分,得到a行b列个筛选区块;
[0059]
当k/s1为整数时,a=k/s1;
[0060]
当k/s1不为整数时,a=[k/s1]+1;
[0061]
当l/s2为整数时,b=l/s2;
[0062]
当l/s2不为整数时,b=[l/s2]+1;
[0063]
其中,筛选区域为s1行s2列的栅格数据矩阵,s1、s2为常数,s1》=3,s2》=3。
[0064]
在具体实施例中,筛选区域的像元行数s1和列数s2可以不相等,也可以相等。若s1=s2=s,则筛选区域由s行s列像元组成,以筛选区域为最小粒度对原始分类栅格数据data进行从上到下、从左到右分块,得到a行b列个筛选区块。
[0065]
当k/s为整数时,a=k/s;
[0066]
当k/s不为整数时,a=[k/s]+1;此时第a行筛选区块中不足s行个像元,则以像元值为0补充至s行个像元。
[0067]
当l/s为整数时,b=l/s;
[0068]
当l/s不为整数时,b=[l/s]+1;此时第b列筛选区块中不足s列个像元,则以像元值为0补充至s列个像元。
[0069]
s2.对a行b列个筛选区块,采用最大绝对误差阈值e参数值逐个筛选区块进行像元动态筛选,存储候选像元标记数据和候选像元值到数据文件xdata中。
[0070]
第j行q列的筛选区块动态筛选过程,1《=j《=a,1《=q《=b:以数值ts记录当前筛选区块存储时所需要的字节大小,初始为0,具体包括以下步骤:
[0071]
s2-1.在a行b列个筛选区块中选择多个特征点作为候选像元;
[0072]
在具体实施例中,选筛选区块中共有s1*s2个像元,将第1行第1列像元a、第1行第s2列像元b、第s1行第1列像元c、第s1行第s2列像元d的四个像元作为特征点直接入选候选像元点。当然,也可以选择其他像元作为特征点,在计算某些像元值时就需要做外延插值计算。
[0073]
s2-2.确定最大绝对误差阈值e参数值;
[0074]
对于最大绝对误差阈值e参数值可根据经验进行设定。
[0075]
s2-3.根据候选像元采用最大绝对误差阈值e参数值逐层插值计算,以此进行像元动态筛选。
[0076]
在两两候选像元选取中间像元,计算中间点像元的计算值,判断中间像元的计算值与其真实值的误差是否在最大误差阈值e内,若是则中间像元不作为筛选候选像元,否则中间像元作为候选像元;逐行逐列进行筛选直至所有像元筛选完毕。
[0077]
在具体实施例中,对于筛选区块中第1行像元的筛选:
[0078]
第1行像元,先根据候选像元a和像元b插值计算出中间点像元m的计算值vm,比较值vm与像元m的真实值pm的误差是否在最大绝对误差阈值e内,如果是,则中间点像元m不作为筛选候选像元;否则像元m作为候选像元;这里插值计算方法不做具体限制,只要与后续的读取解析时插值计算保持一致即可,优选采用效率高的如线性插值。
[0079]
对于像元a和像元m之间像元,同样插值计算出中间点像元s的计算值vs,比较值vs
与像元s的真实值ps的误差是否在最大绝对误差阈值e内,如果是,则中间点像元s不作为候选像元;否则像元s作为候选像元;
[0080]
对于像元m和像元b之间像元,同样插值计算出中间点像元t的计算值vt,比较值vt与像元t的真实值pt的误差是否在最大绝对误差阈值e内,如果是,则中间点像元t不作为候选像元;否则像元t作为候选像元;
[0081]
继续同样的过程处理像元a和像元s之间像元、像元s和像元m之间像元、像元m和像元t之间像元、像元t和像元b之间像元,直至该行所有像元都筛选完毕。
[0082]
筛选区块中第1列像元的筛选:第1列像元a和像元c之间像元,处理过程类似第1行像元筛选过程,先根据像元a和像元c插值计算出中间点像元m的计算值vm,比较值vm与像元m的真实值pm的误差是否在最大绝对误差阈值e内,如果是,则中间点像元m不作为候选像元;否则像元m作为候选像元;对于像元a和像元m之间像元、像元m和像元c之间像元,按上述类似方法进行筛选直至该列所有像元都筛选完毕。
[0083]
筛选区块中第s列像元的筛选:第s列像元b和像元d之间像元,处理过程类似第1列像元筛选过程直至该列所有像元都筛选完毕。
[0084]
筛选区块中第2行至第s行像元的筛选:此时,第2行至第s行的第1列及s列像元值都是确定的,采用上述a步骤中的方法逐行进行像元筛选。
[0085]
对于存储候选像元标记数据和候选像元值到数据文件xdata中,包括以下步骤:
[0086]
分配s1*s2个bit位存储空间的候选像元标记数据b[][];b[][]是一个二维数组,有s1行s2列,分别对应着筛选区块中各个像元是否为候选像元。
[0087]
对筛选区块按顺序从上到下,从左到右标记每个像素筛选情况,如果该像元作为候选像元,则设置标记数据b[i][j]=1,否则设置标记数据b[i][j]=0;如果s1*s2是8的倍数ts值为s*s/8;如果s1*s2不是8的倍数,即标记数据b[][]不能完整的划分为整数个字节,则在末尾补充值为0的bit位至完整的一个字节,ts值为[s*s/8]+1;
[0088]
将候选像元标记数据b[][]以字节为单位写入ts个字节到数据文件xdata;将上述筛选的候选像元像素值按顺序从上到下,从左到右写入数据文件xdata;假设有m个候选像元,每个像元值为double类型,ts值增加8*m字节。
[0089]
在具体实施例中,连续型栅格数据的某筛选区块s=7,最大绝对误差阈值e=1.0,该筛选区块的像元值如下表1示意:
[0090]
表1
[0091]
562.3563.1568.7564.6564.8565.7566.3
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
662.3663.1663.7664.6674.8655.7666.3
[0092]
在对该筛选区块进行动态筛选时,以p[i][j]表示该筛选区块中第i行第j列的像元,以v[i][j]表示该筛选区块中第i行第j列的像元值;
[0093]
第1行像元,先根据像元p[1][1]和像元p[1][7]插值计算出中间点像元p[1][4]的
计算值vm=(v[1][1]+v[1][7])/2.0=564.3,比较值vm与像元p[1][4]的真实值pm=564.6的误差delt=0.3是否在最大绝对误差阈值e内,由于delt《e则中间点像元p[1][4]不作为筛选候选像元;再根据像元p[1][1]和像元p[1][4]插值计算出中间点像元p[1][2]的计算值vm=v[1][1]+(v[1][4]-v[1][1])/3=563.06,此时像元p[1][2]不是像元p[1][1]和像元p[1][4]的中间位置,比较值vm与像元p[1][2]的真实值pm=563.1的误差delt=0.04,由于delt《e则中间点像元p[1][2]不作为筛选候选像元;再根据像元p[1][2]和像元p[1][4]插值计算出中间点像元p[1][3]的计算值vm=(v[1][2]+v[1][4])/2.0=563.85,比较值vm与像元p[1][3]的真实值pm=568.7的误差delt=4.85,由于delt》e则中间点像元p[1][3]作为筛选候选像元;同理对其余像元进行插值筛选,可知,第一行中有3个像元作为候选像元,分别为p[1][1]、p[1][3]和p[1][7];同理,处理第1列、第7列所有像元的筛选,再进行第2行至第7行所有像元的筛选,得到第7行中有4个像元作为候选像元,分别为p[7][1]、p[7][5]、p[7][6]和p[7][7];分配49个bit位存储空间的候选像元标记数据b[][],其每个标志位的值如下表2示意:
[0094]
表2
[0095]
10100010001000
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
1000111
[0096]
将候选像元标记数据b[][]以字节为单位写入数据文件xdata时,此时49个bit位不是8的倍数则在末尾补充值为0的7个bit位至完整的一个字节,共需要7个字节存储空间,得到如下的标记数据,如表3所示:
[0097]
表3
[0098]
10100010001...1110000000
[0099]
对上表中的7个字节存储空间,从左到右,按字节逐个写入数据文件xdata中;然后将上述筛选的候选像元像素值按顺序从上到下,从左到右写入数据文件xdata,即将像素p[1][1]、p[1][3]和p[1][7];...,p[7][1]、p[7][5]、p[7][6]和p[7][7]的值依次写入数据文件xdata中;假设有m=12个候选像元,ts=7+12*8=103字节;至此,该筛选区块动态筛选过程结束。
[0100]
s3.记录每行第一列的筛选区块在数据文件xdata中存储起始位置,以此提高文件读取解析效率。
[0101]
由上述步骤可以看出,对每个筛选区块动态筛选写入数据文件xdata时所使用的存储空间值可能并不相同,按上述步骤顺序存储所有的筛选区块的数据到数据文件xdata后这就会引发一个问题:例如第2行第1列的筛选区块的数据起始于数据文件xdata中的哪个位置或者说数据文件xdata中从第几个字节开始是属于第2行第1列的筛选区块的数据。如果从第一行第一列逐个筛选区块的读取解析效率较低;如果知道每一行筛选区块的第一列的数据起始点位置,那么就可以快速的读取到任意一个筛选区块的信息了,只需要从该
行的第一列筛选区块逐个解析到某列筛选区块数据即可。
[0102]
因此,还需要记录下每一行中各个列筛选区块的存储空间大小ts的累计值sumts,并写入数据文件rowsize中。对于s1中的a行b列个筛选区块,逐行按s2处理可累计得到a个整数值e1、e2、...、ea,其中e1表示第一行中所有列的筛选区块的存储空间为e1个字节,ea表示最后一行中所有列的筛选区块的存储空间为ea个字节;将这a个整数值e1、e2、...、ea写入数据文件rowsize中。
[0103]
s4.记录所述原始连续型栅格数据data的元数据信息。
[0104]
元数据信息包括:原始连续型栅格数据data的行数k、列数l;筛选区域s1、s2值,最大绝对误差阈值e参数值等;将该元数据信息写入数据文件meta中。
[0105]
本方法中,首先根据指定的四个特征点像元值进行多层次的行、列像素的插值筛选,只要某行、某列中的像元数值有部分接近时就有数据压缩效果,不依赖于最初指定的四个特征点像元值,充分利用“四个特征点像元之外的大部分像素值之间也具有局部的数值相似性”这一规律,可以看出本方法具有更优的数据压缩效率。
[0106]
基于上述一种连续型栅格数据的存储方法,本发明还提供一种连续型栅格数据的读取方法。具体读取过程:
[0107]
假设要读取原始连续型栅格数据data的第r行第c列像元数值;1《=r《=k,1《=c《=l;
[0108]
步骤1.读取数据文件meta,获得原始连续型栅格数据data的元数据信息,得到原始连续型栅格数据data的行数k,列数l;筛选区域s值,最大绝对误差阈值e参数值等,根据s1中计算出数据文件xdata中共有a行b列个筛选区块。
[0109]
步骤2.计算第r行第c列像元所在的筛选区块编号,假设该请求像元所在的筛选区块的行号为v、列号为z。根据s1中的划分方法,可得:
[0110]
当r/s1为整数时,v=r/s1;
[0111]
当r/s1不为整数时,v=[r/s1]+1;
[0112]
当c/s2为整数时,z=c/s2;
[0113]
当c/s2不为整数时,z=[c/s2]+1。
[0114]
在具体实施例中,s1=s2=s;即,
[0115]
当r/s为整数时,v=r/s;
[0116]
当r/s不为整数时,v=[r/s]+1;
[0117]
当c/s为整数时,z=c/s;
[0118]
当c/s不为整数时,z=[c/s]+1;
[0119]
步骤3.读取数据文件rowsize,获得a个整数值,e1、e2、...、ea;
[0120]
当v=1时,第1行的第一列筛选区块的数据起始于数据文件xdata的0字节处,此时offset=0;
[0121]
当v》1时,第v行的第一列筛选区块的数据起始于数据文件xdata的e(v-1)字节处,此时offset=e(v-1);
[0122]
从第offset字节处开始读取数据文件xdata,也就是开始读取解析第v行第1列的筛选区块逐个解析筛选区块的信息。
[0123]
具体的,若当前读取的是第j列个筛选区块,1《=j《=z;
[0124]
步骤3-1.读取候选像元标记数据。
[0125]
若s1*s2是8的倍数则从数据文件xdata中读取s1*s2/8个字节为候选像元标记数据;若s1*s2不是8的倍数则从数据文件xdata中读取[s1*s2/8]+1个字节,取前s1*s2个bit位数据为候选像元标记数据。
[0126]
在具体实施例中,若s1=s2=s,如果s*s是8的倍数则从数据文件xdata中读取s*s/8个字节为候选像元标记数据;如果s*s不是8的倍数则从数据文件xdata中读取[s*s/8]+1个字节;取前s*s个bit位数据为候选像元标记数据。
[0127]
步骤3-2.读取候选像元值数据。
[0128]
累计s1*s2个bit位候选像元标记数据中值为1的bit位个数m,从数据文件xdata中读取m个double类型的数值v1、v2、v3、...、vm,分别对应筛选区块中s1*s2个的m个候选像元值。
[0129]
在具体实施例中,若s1=s2=s,累计s*s个bit位候选像元标记数据中值为1的bit位个数m,从数据文件xdata中读取m个double类型的数值v1、v2、v3、...、vm,分别对应筛选区块中s*s个的m个候选像元值。
[0130]
步骤3-3.计算得到请求像元所在筛选区块中的像素值。
[0131]
如果j==z,则需要根据这m个候选像元值进行插值计算得到筛选区块中所有像素值,具体步骤如下:
[0132]
对于两两候选像元的中间像元插值之前,判断该中间像元值是否属于候选像元,若是候选像元则不需要进行插值计算,直接确定该中间像元值为候选像元值,若不是,则将插值计算结果作为中间像元值;逐行多次进行插值处理可得到筛选区块中所有像素值;再根据请求像元的行列号r、c,得到在该筛选区块中的像素位置,进而确定像素值,读取结束。
[0133]
在具体的实施例中,对像元a和像元b的中间像元c插值之前判断该像元c值是否属于候选像元,如果是候选像元则不需要进行插值计算,直接确定该像元c值为候选像元值,如果不是,则将插值计算结果作为像元c值;逐行多次进行插值处理可得到筛选区块中所有像素值。再根据请求像元的列号r,得到在该筛选区块中的像素位置,进而确定像素值,读取结束。
[0134]
在具体的实施例中,从数据文件xdata中第xx个字节开始读取7个字节存储空间,得到如下的某个筛选区块的候选标记数据,如表4所示:
[0135]
表4
[0136]
10100010001...1110000000
[0137]
取前49个bit位数据为候选像元标记数据,累计候选像元标记数据中值为1的bit位个数为12,再从数据文件xdata中读取12个double类型的数值v1、v2、v3、...、v12,分别对应下表5中筛选区块的12个候选像元值:
[0138]
表5
[0139]
v10v2000v3000v4000
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
ꢀꢀꢀꢀꢀꢀꢀ
v9000v10v11v12
[0140]
根据这12个候选像元值进行插值计算得到筛选区块中所有像素值;对像元p[1][1]和像元p[1][7]的中间像元p[1][3]插值之前判断该像元p[1][3]值是否属于候选像元,由于像元p[1][3]不是候选像元,因此像元p[1][3]值通过插值计算确定;同理,像元p[1][2]值通过插值像元p[1][1]和像元p[1][3]计算确定;像元p[1][3]由于是候选像元,因此不需要进行插值计算,直接确定为v2值;以此类推可确定所有像素值。
[0141]
如果j!=z,则请求的像元不在该筛选区块中,不需要解析该筛选区块中的像元值,继续处理下一列的筛选区块数据。
[0142]
具体案例
[0143]
以全国dem(digital elevation model)数据为例,在30米分辨率情况下,传统存储方式下由行k=134724,列l=161360个栅格像元数据组成,采用8字节的double型数值存储,共需要的存储空间约为161.9gb。
[0144]
应用本方法,使用15x15像元的筛选区域进行划分得到m=8982,n=10758个划分后的筛选区块,然后对这m*n个筛选区块进行上述动态筛选方法,在最大绝对误差阈值e=3.0米的条件下存储候选像元标记数据和候选像元值到数据文件xdata中。经统计,得到的数据文件xdata存储大小约为8.09gb,约为原始数据存储大小的5%;数据文件rowsize存储空间为8982*8字节近似70kb,原始dem数据的元数据信息存储空间可以忽略不计,因此可以看出本方法极大的节省了存储空间,数据压缩效果明显优于现有其他方法。
[0145]
本发明一种连续型栅格数据的存储及读取方法具有如下优点:
[0146]
本方法充分利用“筛选区块中四个特征点像元之外的大部分像素值之间也具有局部的数值相似性”这一规律,不要求筛选区块中大部分像素值与某个固定位置的栅格像元值相同或相近,对于具有空间相似性的连续型栅格数据,如dem、坡度数据等都适用,因而具有更广泛的适用性和更佳的数据压缩效率。
[0147]
本方法筛选区块中动态筛选过程及数据文件读取解析过程中只涉及简单的插值计算,处理简单运行效率高,对海量栅格数据的存储、备份及网络传输都可节约存储空间,降低系统成本,具有明显的经济价值。尤其适合大场景实时仿真中三维地形数据的显示系统(dem数据量大、精度要求不高情况下)中对dem数据可以有很好的数据压缩效率,提高系统的响应性能。
[0148]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1