一种基于级联特征交互的点云图像深度补全方法
1.本发明涉及自动驾驶技术领域,更具体的涉及一种基于级联特征交互的点云图像深度补全方法。
背景技术:
2.深度感知是自动驾驶系统中十分基础且重要的感知技术,它的目的是获取周围场景的精确且稠密的深度信息,基于获得的稠密深度信息,自动驾驶的许多高层感知任务如语义分割、目标检测、三维场景重建等都能获得很大程度上的性能提升。现阶段自动驾驶主要依赖相机和激光雷达两种传感器进行深度感知,相机和激光雷达两种传感器各有优缺点,相机传感器收集的图像数据能获取场景的丰富纹理和色彩信息,但受光照条件影响较大,激光雷达传感器收集的点云数据能获得场景的精确深度信息且不受光照影响,但点云数据十分稀疏,无法提供足够的有效信息。
3.现有技术中存在基于纯图像的深度感知方案和基于图像和激光雷达点云的的深度感知方案。
4.在基于纯图像的深度感知方案中主要有单目深度估计的深度感知方案,单目深度估计,顾名思义,就是利用一张或者唯一视角下的rgb图像,估计图像中每个像素相对拍摄源的距离。基于监督学习的单目深度估计方法直接以二维图像作为输入,以深度图为输出,使用ground truth深度图作为监督信息,训练深度模型;此外,由于深度标签数据获取难度较高,目前有很多算法基于无监督模型,即仅仅使用两个摄像机采集的双目图像数据进行联合训练。其中双目数据可彼此预测对方,从而获取相应的视差数据,再根据视差与深度的关系进行演化,亦或是将双目图像中各个像素点的对应问题看作是立体匹配问题进行训练。
5.在基于图像和激光雷达点云的的深度感知方案中,考虑到相机和激光雷达两种传感器各有优缺点,目前自动驾驶感知系统通常基于多传感器感知融合的方案,通过融合图像和点云两种传感器数据,实现两种传感器数据的优势互补,从而达到提升深度感知能力的目的。按照融合阶段,现有异构多传感器融合感知方案可以划分为前期融合、中期融合和后期融合三种融合方式,其中前期融合又叫数据层融合,是在原始数据层面进行两种感知数据的融合,其主要思路是利用相机和激光雷达的坐标转换关系,将三维点云投影到二维图像平面,再通过通道拼接或者直接相加等方式进行融合,这种融合方案存在的问题主要体现在难以实现两种异构传感器数据在空间上的对齐,导致融合粒度较粗,融合效果不佳;后期融合又叫结果层融合,其主要思路是针对两种传感器数据分别执行感知任务,然后将两种传感器数据各自的感知结果进行融合,这种方案实现起来很简单,但其缺点也很明显,没有实现充分实现两种模态数据间的信息交互和优势互补,融合效果也提升有限,并且有时融合结果甚至会比单一感知模态情况下的感知结果更差。中期融合又叫特征层融合,通过分别对两种感知数据提取特征,然后对提取到的特征进行融合,优势是可以针对单一感知模态数据设计网络充分提取特征,但也存在缺点,同样无法有效实现两种感知数据的充
分交互。
6.目前基于纯图像的深度估计方法可以划分为传统方法、基于机器学习的方法和基于深度学习的方法。传统方法基于双目或者多目图像,采用立体匹配技术,利用三角测量法将两幅图像之间的视差信息转为深度信息,从图像中估计场景深度信息,这种方法缺点在于在弱纹理区域和重复纹理区域匹配困难、计算量大、对光照敏感、应用范围有限。基于机器学习的单目图像深度估计,使用马尔科夫随机场(markov random field,mrf)对深度关系构建概率图模型,通过最小化能量函数实现图像深度估计,这种方法的缺点是算法精度低且耗时长、人为假设多、处理过程繁琐,很难估计出正确的场景深度信息,无法应用于实际场景。基于深度学习的方法也是目前用的比较多的方法,通过输入rgb图像,训练模型学习图像到深度图的映射关系。这种方法的缺点是模型性能严重依赖数据质量,因此在关照条件不佳的场合比如夜间、隧道等环境下模型性能会严重下降。
7.基于图像和激光雷达点云融合的方案是现阶段自动驾驶深度感知的主流方案,克服了基于纯图像方案的缺点。当前点云图像融合深度感知技术中,基于前融合的方案虽然能够最大程度上保留数据的原始信息,但现有技术实现难以实现细粒度的异构感知数据空间对齐和融合,往往导致融合效果不佳;基于后融合的方案在决策层面融合两种传感器数据的感知结果,实现起来简单,但由于两种传感器各有局限,两种模态间缺乏交互,无法实现两种模态间的优势互补,因此融合效果不佳,并且有时会因为两种传感器的感知结果相悖导致感知效果更差。目前使用比较多的融合方案是基于特征层的多模态融合感知,这种方式的优点是无需考虑数据的空间对齐,但当前的各类基于特征层融合的技术实现在融合粒度上依然不够精细,往往将其中一种模态作为另一种模态的辅助补充信息或者仅通过简单相加等方式进行融合,导致两种模态间的交互不足,融合不够充分。
技术实现要素:
8.本发明为了解决上述方案存在的深度感知精度不足、异构感知数据融合效果不佳的问题,实现点云和图像两种传感器数据的细粒度融合和充分交互,提出了一种双分支异构感知数据级联交互网络,在多个尺度上对两种模态的对应特征进行融合,并将融合后的特征输入到各自模态对应的分支网络中,提高了了两个分支网路的信息丰富程度和深度感知能力,此外,引入辅助任务的思想,通过引入一个图像重构任务,引导模型学习图像中的场景结构信息,使输出深度图结构信息更加完整。最后通过置信度图,将两个分支网络的输出深度图中的高可信度深度值作为最终模型输出,得到融合感知结果。
9.本发明实施例提供一种基于级联特征交互的点云图像深度补全方法,包括:
10.获取自动驾驶场景三维点云和场景二维rgb图像;
11.根据多个resnet34的残差模块构建对场景三维点云和场景二维rgb图像进行特征提取的两个编码器;
12.根据多个上采样模块构建对场景三维点云和场景二维rgb图像进行特征还原的两个解码器;
13.将场景三维点云提取和还原分支的编码器与解码器连接,构建场景三维点云分支神经网络;
14.将场景二维rgb图像提取和还原分支的编码器与解码器连接,构建场景二维rgb图
像分支神经网络;
15.将场景三维点云分支神经网络和场景二维rgb图像分支神经网络中两个编码器的残差模块的各层级相互对应设置;
16.构建多个级联特征交互模块,每个级联特征交互模块的输入与两个编码器的残差模块的对应层级输出连接,每个级联特征交互模块的输出与两个编码器的下一对应层级连接,构建特征交互的点云和图像双分支神经网络模型;
17.在特征交互的点云和图像双分支神经网络模型输入场景三维点云和场景二rgb维图像,输出场景深度图;
18.通过使用置信度图加权的方式融合场景深度图,得到新的场景深度图。
19.优选地,对场景三维点云和场景二维rgb图像进行特征提取的两个编码器均包括五个级联的残差模块,对场景三维点云和场景二维rgb图像进行特征还原的两个解码器均包括五个级联的上采样模块,在对场景三维点云进行特征提取的编码器中,残差模块的卷积神经网络采用稀疏卷积神经网络,卷积核为3x3;在对场景二维rgb图像进行特征提取的编码器中,残差模块的卷积神经网络采用标准的卷积神经网络,卷积核为3x3。
20.优选地,三维点云分支神经网络和场景二维rgb图像分支神经网络均包括多个不同的卷积层、池化层、激活层、转置卷积层和跨尺度特征连接层。
21.优选地,每个解码器包括五个级联的上采样模块,每个上采样模块均包括一个转置卷积、一个批归一化层、一个池化层。
22.优选地,级联特征交互模块数量为五个,每个所述级联特征交互模块均包含一个1x1卷积、三个空洞率分别为1、2、4的空洞卷积、和一个1x1卷积;
23.最后一个级联特征交互模块的输出作为特征交互的点云和图像双分支神经网络模型的第一个上采样层的输入。
24.优选地,还包括:
25.将最后一个上采样模块输出的重构图像作为辅助任务,根据l2损失函数计算重构图像和输入场景二维rgb图像的差距,训练模型学习图像的结构信息。
26.优选地,l2损失函数,包括:
[0027][0028]
其中,di表示预测深度图第i个位置的深度值,表示ground truth深度图第i个位置的深度值。
[0029]
优选地,还包括对特征交互的点云和图像双分支神经网络模型的训练,其包括:
[0030]
将点云和图像数据对作为训练的数据集;
[0031]
对数据集中的图像进行增强处理,增强处理包括翻转处理、裁剪处理、明亮度调整,归一化处理,转为张量图处理;
[0032]
将模型参数进行随机高斯分布初始化;
[0033]
设置模型训练的损失函数和重构图像的损失函数,将两个损失函数相加,并设置各自的系数,以最小化损失函数为优化目标,通过梯度更新策略训练模型,得到最优模型参数。
[0034]
优选地,通过使用置信度图加权的方式融合场景图,得到新的场景深度图,包括:
[0035]
分别获取云和图像双分支神经网络输出的两张场景深度图对应位置的两个估计深度值;
[0036]
计算两张场景深度图对应位置的两个估计深度值的置信度;
[0037]
分别计算两张场景深度图对应位置的置信度和深度值的乘积,获得一张待融合图片;
[0038]
将点云和图像双分支神经网络分别输出待融合图片对应位置的深度值相加,融合至场景深度图中,得到新的场景深度图。
[0039]
本发明实施例提供一种基于级联特征交互的点云图像深度补全方法,与现有技术相比,其有益效果如下:
[0040]
发明的基于级联特征交互的点云图像深度补全方法,通过多尺度的点云图像特征细粒度融合,大大提升了两种异构感知数据的交互程度,实现了两种感知数据的优势互补,融合后的特征再次输入到对应分支网络,丰富了两个分支的信息量,提高了两个分支网络的感知能力,最后对两个分支网络的输出进行融合,取两个输出深度图对应位置置信度更高的深度值作为最终的输出深度图的深度值。此外,两种模态的输出相互独立,不以某个分支为主,提高了模型对噪声的鲁棒性。最后,我们的模型相比于其他的基于图像和点云融合的模型,在以图像和低线束激光雷达点云为输入的情况下具有更好的性能,这也证明我们的模型可以应用在仅有相机和低线束低成本激光雷达的资源受限的设备上。
附图说明
[0041]
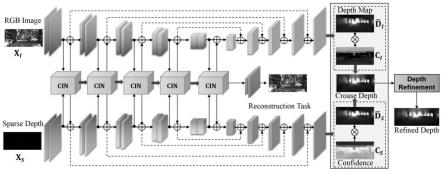
图1为本发明实施一种基于级联特征交互的点云图像深度补全方法的模型结构图;
[0042]
图2为本发明提出的级联特征交互模块结构图。
具体实施方式
[0043]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0044]
实施例:
[0045]
参见图1~2,本实例提供了一种基于级联特征交互的点云图像深度补全方法,利用图像具备色彩和纹理信息,但受光照影响,点云不受光照影响信息稀疏的特点,构建了一个多尺度细粒度融合模型,实现了图像和点云数据的充分融合和优势互补,大大提升了小物体的感知能力。本实例中通过引入图像重构辅助任务,引导模型学习图像中的结构信息,使输出深度图的物体轮廓更加完整。通过使用置信度图加权的方式,融合两个分支的输出深度图,得到可信度更高的深度图。
[0046]
step1:利用resnet34的残差模块搭建多尺度的双分支神经网络模型;
[0047]
step101:两个分支网络的编码器部分均由五个残差块构成,解码器部分均由五个上采样模块构成;
[0048]
step102:两个分支网络包括多个不同的卷积层、池化层、激活层、转置卷积层、跨
尺度特征连接,其中点云分支的编码器部分,五个残差块的卷积网络采用的是稀疏卷积,图像分支的编码器部分,五个残差块的卷积网络采用的是标准的卷积网络,所有卷积神经网络的卷积核大小均为3x3;
[0049]
step103:解码器的每一个上采样模块均由转置卷积、批归一化层、池化层构成;
[0050]
step104:在两个分支网络之间,是五个级联特征交互模块,级联特征交互模块按照从上到下的搭建顺序由一个1x1卷积、空洞率分别为1、2、4的空洞卷积、一个1x1卷积构成,输入是两个分支网络对应层级的特征图;
[0051]
step105:在最后一个级联特征交互模块的后面连接了五个上采样模块,每个上采样模块由一个卷积网络层、一个归一化层、一个激活层构成,最后一个上采样模块的输出是重构出的输入图像,重构图像作为辅助任务,利用l2损失函数计算重构出的图像和输入rgb图像的差距,训练模型学习图像的结构信息;
[0052]
工作过程:双分支网络的每一个网络都有一个输出深度图,通过计算两个深度图对应位置的两个估计深度值的置信度,分别用置信度乘以对应深度图的深度值,相加得到最后输出深度图对应位置的深度值。
[0053]
step2:对数据集中的图像进行增强处理,增强操作包括翻转、裁剪、明亮度等,并进行归一化处理,最后转为张量形式,得到便于深度学习卷积神经网络处理的训练数据集:
[0054]
step3:本实例中所使用的的真实场景自动驾驶数据集是kitti 2015深度估计和深度补全数据集,包括双目摄像头的左图和右图,激光雷达点云,以及ground truth深度图。输入到模型中的图像裁剪为hxw为325x1216分辨率。为了加快模型的训练速度,本实例中将输入图像进行零均值归一化。在开始训练前对模型参数进行随机高斯分布初始化,足够的随机性可以增强模型的性能。本实例在训练时的具体参数设置如下:
[0055]
参数名参数值批大小(batch size)16输入图像分辨率(h x w)352x1216训练轮数(epochs)30学习率(learning rate)1e-4有效深度值范围(单位:m)0-80
[0056]
step:4:根据我们搭建的双分支网络模型,设置模型训练的损失函数和图像重构的损失函数,将两个损失函数相加,并设置各自的系数,以最小化损失函数为优化目标,通过梯度更新策略训练模型,得到最优的模型参数。
[0057]
本实例中所使用的的损失函数为l2损失函数:,其中di表示预测深度图低i个位置的深度值,表示ground truth深度图第i个位置的深度值。本实例中使用adam优化器优化模型参数,达到最小化损失函数的目的。adam算法优化过程可以归纳为:每迭代一次,利用梯度的样本均值估计和样本平方均值估计动态调整每个参数的学习率,使得训练时参数更新比较平稳,模型梯度能够稳定下降。
[0058]
step5:将点云和图像数据对数据输入到双分支网络模型中,得到最终输出的深度图。
[0059]
本实例中的基于级联特征融合的点云图像融合深度补全方法,基于卷积神经网
络,利用针对两种感知数据特定设计的网络,分别提取两种模态的特征,并使用级联特征网络实现多尺度的点云图像特征细粒度融合,充分提高了两种模态的交互程度,增强了两个分支网络的深度感知能力,并提高了模型对噪声的鲁棒性。在引入图像重构任务后,通过图像重构任务引导模型学习图像中的场景结构信息,我们的模型的输出深度图在物体轮廓上具有更好的完整性。通过在kitti2015深度补全和深度估计任务上的比较,我们的模型在深度估计任务上达到了最好的性能,在深度补全任务上也取得了具有竞争力的性能,在引入高斯噪声的鲁棒性实验中,我们的模型也取得了具有较强竞争力的结果,证明了本发明的实用性。
[0060]
以上公开的仅为本发明的几个具体实施例,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明的精神和范围,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1