一种基于深度学习的停车位定位方法与流程
1.本发明涉及自动泊车技术领域,尤其涉及一种基于深度学习的停车位定位方法。
背景技术:
2.随着智能汽车的不断发展,自动泊车技术作为智能汽车领域不可或缺的组成部分也逐渐受到重视。近年来,深度学习技术已经广泛的应用在计算机视觉的诸多领域中,与传统方法相比,深度学习可以在更为复杂的场景解决目标的检索和识别等问题。在自动泊车领域中,基于深度学习的停车位检测方法逐渐体现出优越的性能,利用深度学习方法鲁棒的感知自动泊车过程中每帧图像的停车位位置是一项重要的研究课题。
3.现有的基于深度学习的停车位检测方法是利用卷积神经网络模型对自动泊车过程中的视频逐帧提取关键特征,识别出每帧图像中的停车位位置。
4.目前的基于深度学习的停车位检测方法的主要问题有:首先,卷积神经网络模型对视频中每帧图像做独立的停车位识别,没有利用到视频序列中上下文语义信息,忽略了视频序列中的每帧图像之间的强关联性;其次,车辆在泊入目标停车位时,车辆与目标停车位的相对距离与方向都会发生变化,容易造成框定的停车位区域发生偏移,影响目标停车位的准确定位。
技术实现要素:
5.本发明提供一种基于深度学习的停车位定位方法,旨在解决现有技术中的缺陷,解决自动泊车过程中车辆运动导致识别的停车位偏移的问题,提高停车位识别准确性和鲁棒性。
6.为达到上述目的,本发明所采取的技术方案为:
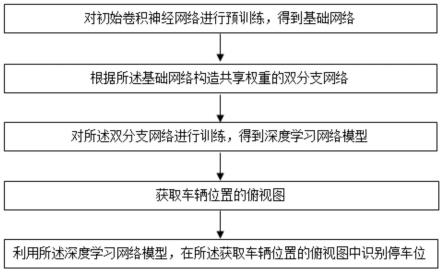
7.本发明提供一种基于深度学习的停车位定位方法,包括:
8.步骤1、对初始卷积神经网络进行预训练,得到基础网络;
9.步骤2、根据所述基础网络构造共享权重的双分支网络;
10.步骤3、对所述双分支网络进行训练,得到深度学习网络模型;
11.步骤4、获取车辆位置的俯视图;
12.步骤5、利用所述深度学习网络模型,在所述获取车辆位置的俯视图中识别停车位。
13.具体地,所述步骤1包括:采用alexnet作为所述初始卷积神经网络的骨干网络,使用停车位图像数据及其对应的标签对所述骨干网络进行预训练。
14.具体地,所述步骤2包括:利用两个不同深度的所述基础网络构成一组双分支网络模型,将深层基础网络分支作为模板分支,浅层基础网络分支作为搜索分支,所述深层基础网络、浅层基础网络在浅层权重共享。
15.具体地,所述步骤3包括:将小尺寸特征图作为模板,在大尺寸特征图中搜索对应的模板区域,利用上下文信息逐帧搜索与前一帧输入图像的响应值图,直至在搜索区域中
匹配到与该模板具有高相似度的特征图。
16.具体地,所述步骤3包括:
17.步骤301、在所述模板分支中输入第i帧图像,进行卷积提取特征,得到对应的第一特征图,并将其作为模板;
18.步骤302、同时在所述搜索分支中输入第i+1帧图像,进行卷积提取特征,得到对应的第二特征图;
19.步骤303、在所述第二特征图上以所述第一特征图为卷积核按照预设规则进行卷积,得到响应值图。
20.具体地,所述预设规则为:
21.f(xi,x
i+1
)=η(xi)*η(x
i+1
)+b
22.其中,f(xi,x
i+1
)表示图像xi和图像x
i+1
的响应值图,η(xi)表示第一特征图,η(x
i+1
)表示第二特征图,b代表偏置值,*表示卷积运算。
23.具体地,所述步骤5包括:根据所述响应值图,通过插值方式还原为原始图像,确定停车位的位置。
24.进一步地,在所述步骤5之后还包括:
25.步骤6、利用损失函数对所述深度学习网络模型更新。
26.具体地,所述步骤6包括:
27.步骤601、根据第一公式确定每个样本的损失;
28.步骤602、根据全部样本点的损失的均值计算所有样本点的总损失;
29.步骤603、根据第二公式确定所述深度学习网络模型训练的总损失。
30.具体地,所述第一公式为:
31.l(y,s)=log(1+e-ys
)
32.其中,l(y,s)表示每个样本的损失,e为自然常数,s表示响应值图中对应样本点的分数,数值大小与预测值为正样本的概率成正比;y表示所述样本点的标签,表示响应图表中真值区域的标记;
33.所述样本点的标签y根据如下公式计算:
[0034][0035]
其中,k是输入图像经过卷积之后得到响应图表缩小的倍数,c表示所述响应值表的中心,u表示所述响应值表中的任意一点,||u-c||2表示l2范数,r表示距离阈值。
[0036]
具体地,所述第二公式为:
[0037]
l=l
id
+l(y,s)
[0038]
其中,l表示深度学习网络模型训练的总损失,l
id
表示分类损失,l(y,s)表示所有样本点的总损失。
[0039]
本发明的有益效果在于:本发明通过构造双分支网络模型,将车辆位置的俯视图按帧输入,每一帧以上一帧卷积得到的特征图为模板进行模板相似性度量和匹配,利用视频序列的上下文信息定位到准确的停车位位置,提高停车位识别的准确性,并利用损失约束和更新网络模型,有效解决了自动泊车过程中车辆运动导致识别的停车位偏移的问题,提高了停车位识别准确性和鲁棒性。
附图说明
[0040]
图1是本发明的基于深度学习的停车位定位方法的流程示意图;
[0041]
图2是本发明的双分支网络示意图。
具体实施方式
[0042]
下面结合附图具体阐明本发明的实施方式,附图仅供参考和说明使用,不构成对本发明专利保护范围的限制。
[0043]
在本发明的说明书、权利要求书或附图中描述的流程中,包含各个步骤的序号(如步骤10、20等),所述序号仅用于区分开各个步骤,所述序号本身不代表任何的执行顺序。需要说明的是,本文中的“第一”、“第二”等描述,仅用于区分描述对象等,不代表先后顺序,也不表示“第一”、“第二”等是不同的类型。
[0044]
如图1所示,本实施例提供一种基于深度学习的车位识别方法,包括:
[0045]
步骤1、对初始卷积神经网络进行预训练,得到基础网络。
[0046]
在本实施例中,所述步骤1包括:采用alexnet作为所述初始卷积神经网络的骨干网络,使用停车位图像数据及其对应的标签对所述骨干网络进行预训练。
[0047]
为进一步提高网络的判别能力和自适应能力,使用分类损失对所述骨干网络进行预训练。
[0048]
在本实施例中,所述分类损失为:
[0049][0050]
其中,p(xi|yi)表示输入的图像xi属于真实标签yi的概率。
[0051]
通过本步骤得到了经过预训练的alexnet,将其称为基础网络。
[0052]
步骤2、根据所述基础网络构造共享权重的双分支网络。
[0053]
如图2所示,在本实施例中,所述步骤2包括:利用两个不同深度的所述基础网络构成一组双分支网络模型,将深层基础网络分支作为模板分支,浅层基础网络分支作为搜索分支,并且深层基础网络、浅层基础网络在浅层权重共享。
[0054]
由深层基础网络卷积得到的特征图,由于其具有更多的卷积和池化层数,会得到更小尺寸的特征图,而浅层基础网络则会得到更大尺寸的特征图。
[0055]
步骤3、对所述双分支网络进行训练,得到深度学习网络模型。
[0056]
在本实施例中,所述步骤3包括:将小尺寸特征图作为模板,在大尺寸特征图中搜索对应的模板区域,利用上下文信息逐帧搜索与前一帧输入图像的响应值图,直至在搜索区域中匹配到与该模板具有高相似度的特征图。
[0057]
在本实施例中,上述方法通过如下步骤实现:
[0058]
步骤301、在所述模板分支中输入第i帧图像,进行卷积提取特征,得到对应的第一特征图η(xi),并将其作为模板;
[0059]
步骤302、同时在所述搜索分支中输入第i+1帧图像,进行卷积提取特征,得到对应的第二特征图η(x
i+1
);
[0060]
步骤303、在所述第二特征图η(x
i+1
)上以所述第一特征图η(xi)为卷积核按照预设
规则进行卷积,得到响应值图f(xi,x
i+1
)。
[0061]
在本实施例中,所述预设规则为:
[0062]
f(xi,x
i+1
)=η(xi)*η(x
i+1
)+b
[0063]
其中,f(xi,x
i+1
)表示图像xi和图像x
i+1
的响应值图,η(xi)表示第一特征图,η(x
i+1
)表示第二特征图,b代表偏置值,*表示卷积运算。
[0064]
步骤4、获取车辆位置的俯视图。
[0065]
在具体实施时,可以通过车辆周围环视摄像头拍摄车辆所处位置的视频,并经过畸变校正和拼接融合得到车辆所在位置的俯视角视频,然后将所述俯视角视频按帧裁剪为车辆位置的俯视图。
[0066]
步骤5、利用所述深度学习网络模型,在所述获取车辆位置的俯视图中识别停车位。
[0067]
在本实施例中,所述步骤5包括:根据所述响应值图,通过插值方式还原为原始图像,确定停车位的位置。
[0068]
本步骤利用视频序列的上下文信息定位到准确的停车位位置,克服了现有技术中没有利用视频序列中上下文语义信息来进行车位识别,从而提高了停车位识别的准确性。
[0069]
在本发明的另一个实施例中,在所述步骤5之后还包括:
[0070]
步骤6、利用损失函数对所述深度学习网络模型更新。
[0071]
在具体实施时,选取目标区域一定范围内的点作为正样本,所述范围外的点为负样本,使用logistic损失对停车位定位区域进行约束。
[0072]
在本实施例中,所述步骤6包括:
[0073]
步骤601、根据第一公式确定每个样本的损失。
[0074]
在本实施例中,所述第一公式为:
[0075]
l(y,s)=log(1+e-ys
)
[0076]
其中,e为自然常数,s表示响应值图中对应样本点的分数,数值大小与预测值为正样本的概率成正比;y表示所述样本点的标签,表示响应图表中真值区域的标记。
[0077]
在本实施例中,所述样本点的标签y根据如下公式计算:
[0078][0079]
其中,k是输入图像经过卷积之后得到响应图表缩小的倍数,c表示所述响应值表的中心,u表示所述响应值表中的任意一点,||u-c||2表示l2范数,r表示距离阈值。
[0080]
y值为1时,表示样本点在目标的附近;y值为-1时,表示样本点定位到了错误位置,此时返回的损失函数值会很大,需要重新到下一帧的搜索区域中检索。
[0081]
步骤602、根据全部样本点的损失的均值计算所有样本点的总损失l(y,s)。
[0082]
即:总损失l(y,s)表示为:
[0083][0084]
步骤603、根据第二公式确定所述深度学习网络模型训练的总损失l。
[0085]
在本实施例中,所述第二公式为:
[0086]
l=l
id
+l(y,s)
[0087]
其中,l表示深度学习网络模型训练的总损失,l
id
表示分类损失,l(y,s)表示所有样本点的总损失。
[0088]
利用总损失约束,不断的优化卷积神经网络模型,使得在自动泊车过程中,随着摄像机的移动,双分支网络模型能够鲁棒的定位停车位位置。
[0089]
以上所揭露的仅为本发明的较佳实施例,不能以此来限定本发明的权利保护范围,因此依本发明申请专利范围所作的等同变化,仍属本发明所涵盖的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1