一种基于3D头部姿态估计的青少年专注度评价方法与流程
一种基于3d头部姿态估计的青少年专注度评价方法
技术领域
1.本发明涉及专注度识别技术领域,具体为一种基于3d头部姿态估计的青少年专注度评价方法。
背景技术:
2.人工智能技术进入校园,带来的重要变化之一是:用数据丈量课堂,课堂关注度在衡量课堂质量、优化教学设计方面的价值受到教育工作者的认可,课堂上学生的专注力如此重要,传统课堂缺少工具帮助老师了解学生是否进入学习状态。在这种情况下,课堂专注度应用而生,以时间反应了课堂上学生专注力变化的趋势,以及在哪个时间专注度最高,哪个时间度最低。学生是否集中注意力,会透过他们的头部行为体现出来。例如,老师在讲课时,学生抬头听讲被看作是注意的集中表现,所以,判断学生在课堂上头部姿态是计算课堂专注度的重要依据。
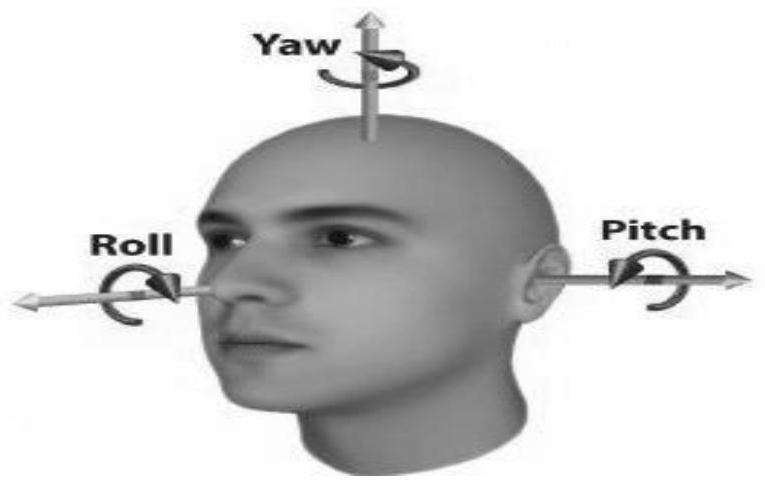
3.目前基于计算机视觉的方法是通过人脸关键点去估计头部姿态,由于在教室场景中人脸小/遮挡/光照/等因素影响,很难检测出人脸关键点,而在3d空间中,表示物体的旋转可以由三个欧拉角来表示:分别计算pitch(围绕x轴旋转),yaw(围绕y轴旋转)和roll(围绕z轴旋转),如图1,通过计算三个自由度,很容易估计出头部各个姿态,从而适应与不同的场景。基本都是基于计算机视觉人脸关键点计算头部姿态或对头部几个姿态打标签训练一个多分类模型,通过人脸关键点对遮挡人脸和侧脸人脸效果特别差,通过头部几分类打标签,使用性差,估计的姿态有限,应用范围比较小。
技术实现要素:
4.针对现有技术的不足,本发明提供了一种基于3d头部姿态估计的青少年专注度评价方法,具备模型轻量化,在高分辨率的视频数据可以达到实时效果,从而实时关注学生的专注度,使用3d头部姿态估计技术可以实现任意角度的姿态估计,以适应不同的场景的优点。
5.为实现上述目的,本发明提供如下技术方案:一种基于3d头部姿态估计的青少年专注度评价方法,包括以下步骤:
6.s1、在教室多方位安装摄像头,用于采集教室中学生上课视频数据;
7.s2、对采集的视频数据进行预处理,将采集视频数据保存为图片;
8.s3、通过labeling对人脸数据进行boxes标注;
9.s4、搭建yolov5模型,训练头部检测模型;
10.s5、对保存的模型yolov5进行剪枝,量化,并保存模型;
11.s6、构建卷积神经网络simple-net;
12.s7、下载数据300w-lp对模型进行初始训练,对采集的数据进行头部姿态估计,并保存标签,建立人工矫正标签,重新训练模型,得到头部姿态估计模型并保存。
13.优选的,所述采集视频数据对应实时人脸图像,图像处理包括:
14.确定实时对应的人脸图像视频;
15.视频采集时间与人脸图像视频时间同步;
16.依据预设的截取频率及时间间隔,对采集的实时人脸图像视频进行跟踪截取,提取人脸图像视频中人脸图像。
17.优选的,提取每幅人脸图像的特征点,并对提取的所述特征点进行处理,通过labeling对人脸数据进行boxes标注。
18.优选的,所述通过labeling对人脸数据进行boxes标注的具体过程为:
19.读取摄像头视频数据,确定图像数据特征点;
20.对实时人脸图像进行yolov5人脸检测,搭建yolov5模型;
21.根据simple-net对人脸进行姿态估计,获得统计学上上课头部姿态;
22.依据预设的人脸图像专注程度类别与专注度值区间之间的映射关系,将所述采集人脸图像对应的专注程度类别设为所述实时人脸图像所属的预设专注度值区间所映射的专注程度类别;
23.得到学生上课专注度。
24.优选的,所述步骤5的具体过程为:
25.对采集视频数据进行数据保存,将数据进行标注分流;
26.包括进行yolov5模型训练,对训练模型保存,根据保存模型进行剪枝量化,并对剪枝量化模型进行保存;
27.还包括根据人脸头部姿态估计打标签,确定人工矫正有误标签,根据simple-net对人脸进行姿态模型训练,进行模型保存。
28.优选的,所述卷积神经网络simple-net网络结构设置为9层。
29.优选的,所述卷积神经网络simple-net网络结构全部使用卷积。
30.有益效果:
31.1、该基于3d头部姿态估计的青少年专注度评价方法,通过使用模型剪枝量化技术,使模型更轻量,在高分辨率的视频数据可以达到实时效果,从而实时关注学生的专注度。使用3d头部姿态估计技术可以实现任意角度的姿态估计,以适应不同的场景,在训练中使用了单独标注的学生数据,模型精度更高。根据教室高密度场景设计了非常轻量的slimpe-net网络,在满足精度的同时减少识别时间。
32.2、该基于3d头部姿态估计的青少年专注度评价方法,通过头部姿态估计网络,更容易学习到头部整体信息,不会像关键点检测因为遮挡等原因缺少关键点信息而无法估计,相对分类模型可以识别头部任意姿态,调高使用效果。
33.3、该基于3d头部姿态估计的青少年专注度评价方法,通过3d头部姿态估计的轻量级网络simple-net,可以实时识别头部的任意姿态;
34.4、该基于3d头部姿态估计的青少年专注度评价方法,通过该算法可以使用在教室高密度,小人脸侧脸的头部姿态估计,simple-net轻量级网络,满足准确率的前提下,推理耗时在毫秒级别。
附图说明
35.图1为本发明在3d空间中的yolov5模型示意图;
net网络结构全部使用卷积,没有权连接层,极大的减少了参数量,模型大小仅5m;
61.s7、下载数据300w-lp对模型进行初始训练,对采集的数据进行头部姿态估计,并保存标签,建立人工矫正标签,重新训练模型,得到头部姿态估计模型并保存,参考图4。
62.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
技术特征:
1.一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于,包括以下步骤:s1、在教室多方位安装摄像头,用于采集教室中学生上课视频数据;s2、对采集的视频数据进行预处理,将采集视频数据保存为图片;s3、通过labeling对人脸数据进行boxes标注;s4、搭建yolov5模型,训练头部检测模型;s5、对保存的模型yolov5进行剪枝,量化,并保存模型;s6、构建卷积神经网络simple-net;s7、下载数据300w-lp对模型进行初始训练,对采集的数据进行头部姿态估计,并保存标签,建立人工矫正标签,重新训练模型,得到头部姿态估计模型并保存。2.根据权利要求1所述的一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于:所述采集视频数据对应实时人脸图像,图像处理包括:确定实时对应的人脸图像视频;视频采集时间与人脸图像视频时间同步;依据预设的截取频率及时间间隔,对采集的实时人脸图像视频进行跟踪截取,提取人脸图像视频中人脸图像。3.根据权利要求2所述的一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于:提取每幅人脸图像的特征点,并对提取的所述特征点进行处理,通过labeling对人脸数据进行boxes标注。4.根据权利要求3所述的一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于:所述通过labeling对人脸数据进行boxes标注的具体过程为:读取摄像头视频数据,确定图像数据特征点;对实时人脸图像进行yolov5人脸检测,搭建yolov5模型;根据simple-net对人脸进行姿态估计,获得统计学上上课头部姿态;依据预设的人脸图像专注程度类别与专注度值区间之间的映射关系,将所述采集人脸图像对应的专注程度类别设为所述实时人脸图像所属的预设专注度值区间所映射的专注程度类别;得到学生上课专注度。5.根据权利要求1所述的一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于:所述步骤5的具体过程为:对采集视频数据进行数据保存,将数据进行标注分流;包括进行yolov5模型训练,对训练模型保存,根据保存模型进行剪枝量化,并对剪枝量化模型进行保存;还包括根据人脸头部姿态估计打标签,确定人工矫正有误标签,根据simple-net对人脸进行姿态模型训练,进行模型保存。6.根据权利要求1所述的一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于:所述卷积神经网络simple-net网络结构设置为9层。7.根据权利要求6所述的一种基于3d头部姿态估计的青少年专注度评价方法,其特征在于:所述卷积神经网络simple-net网络结构全部使用卷积。
技术总结
本发明涉及专注度识别技术领域,且公开了一种基于3D头部姿态估计的青少年专注度评价方法,包括以下步骤:S1、在教室多方位安装摄像头,用于采集教室中学生上课视频数据;S2、对采集的视频数据进行预处理,将采集视频数据保存为图片;S3、通过labeling对人脸数据进行boxes标注;S4、搭建yolov5模型,训练头部检测模型。通过使用模型剪枝量化技术,使模型更轻量,在高分辨率的视频数据可以达到实时效果,从而实时关注学生的专注度。使用3D头部姿态估计技术可以实现任意角度的姿态估计,以适应不同的场景,在训练中使用了单独标注的学生数据,模型精度更高。根据教室高密度场景设计了非常轻量的slimpe-net网络,在满足精度的同时减少识别时间。时间。时间。
技术研发人员:刘文华 刘冰 徐超立
受保护的技术使用者:浙江柔灵科技有限公司
技术研发日:2022.09.26
技术公布日:2022/12/19
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1