一种基于两阶段数据预处理和残差网络的房颤分类方法
1.本发明属于心电监测技术领域,具体涉及一种基于两阶段数据预处理和残差网络的房颤分类方法。
背景技术:
2.心房颤动(atrial fibrillation,af)是一种常见的室上性心律失常。研究表明,房颤会大大增加卒中和系统性血栓栓塞的风险。具有很高的发病率和死亡率,会对社会经济和卫生健康造成了巨大的负担。通过对房颤的诱发条件进行早期的干预和有效控制可以减少房颤的发生概率。房颤患者可能会有各种症状,但是50-87%的患者在最初是无症状的。因此心电图成为房颤诊断的一种金标准。
3.典型的窦性心率的心电波形主要由p波,qrs复合波和t波组成,但在房颤信号中,会出现rr间期不规则,p波被干扰或缺失等现象。传统的多导联心电采集设备大多都很昂贵,且复杂度高,不易携带。因此使用可穿戴设备收集到的单导联信号实现准确的房颤检测,成为了当前的热门研究问题。目前为止,大多数研究已经实现了在单个数据集上的准确分类,但在其他数据集上的分类效果普遍较差。本发明的目的是能够在多个数据集上实现更稳定的房颤分类。
4.当前深度学习模型在心电领域取得了非常好的分类效果,但是这种分类效果对于数据集具有一定的依赖性,模型只能够在单个训练过的数据集上表现出良好的性能,在其他数据集上分类性能会出现严重下降的情况。同其他领域不同,心电数据由于采集环境和个体差异等因素,存在高度的异构性。使用单个数据集进行验证很难确保模型的可靠性。也就是说,模型的实际应用情况无法确定。因此,降低模型的过拟合程度以及模型对于单个数据集的依赖性,提高模型的鲁棒性和泛化性是一个非常重要的问题。
技术实现要素:
5.本发明针对现有技术的不足,提出一种基于两阶段数据预处理和残差网络的房颤分类方法。具体方案如下:
6.步骤1:对原始心电信号进行所提出的两阶段数据预处理策略,过程如下:
7.第一阶段数据预处理包括数据的降采样,降噪,标准化和30s切片等操作。最终获得数据集其中xk和分别表示第k个数据集以及数据集切片后的第i条心电信号,nk指第k个数据集中心电信号切片的数量。表示第i条心电信号的类别标签:当表示第i条心电切片为非房颤节律;当表示第i条心电切片为房颤节律。
8.第二阶段数据预处理主要包括对cinc2017数据集使用l-ros算法以及数据集分割。我们获得最终的训练集为d={(x
*(1)
,y
*(1)
),(x
*(i)
,y
*(i)
),
…
,(x
*(m)
,y
*(m)
)},其中x
*(i)
表示第二阶段后的心电信号,y
*(i)
表示第二阶段后的类别标签,m表示第二阶段后训练集的样
本个数。
9.步骤2:将处理后的数据和标签输入到md-net中,对于每一个输入值x
*(i)
,经过模型后的输出为e(i),在最后一层我们使用了softmax函数,具体等式如下所示:
[0010][0011][0012]
其中g(
·
)为模型函数,θ是模型md-net中的相关参数,c=2表示心率类别数,表示最终模型输出心电信号x
*(i)
的类别概率,最终我们将获得训练好的md-net模型。
[0013]
步骤3:我们使用训练好的模型对三个测试集进行测试,验证模型的鲁棒性和泛化性。
附图说明
[0014]
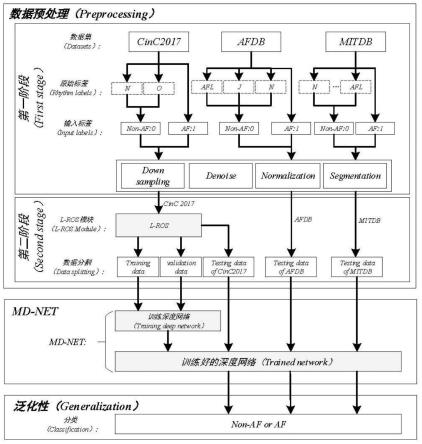
图1为本发明一种基于两阶段数据预处理和残差网络的房颤分类方法的整体架构。
[0015]
图2为l-ros算法流程。
[0016]
图3为md-net模型架构。
[0017]
图4为md-block的三种变体以及md-block,(a):ma-block,(b):mb-block,(c):mc-block,(d):md-block。
[0018]
图5中(a)(b)(c)分别表示cinc2017,afdb和mitdb数据集使用十折交叉验证后的roc曲线和auc面积。
[0019]
图6中(a)(b)(c)分别表示三个数据集特征可视化后的结果,(d)是将三个数据集放在一起进行特征可视化的结果。
具体实施方式
[0020]
下面通过具体实施方式,对本发明的技术方案做进一步的详细描述。
[0021]
如图1所示,一种基于两阶段数据预处理和残差网络的房颤分类方法,该包括:
[0022]
步骤1:对原始心电信号进行所提出的两阶段数据预处理策略,过程如下:
[0023]
第一阶段数据预处理包括数据的降采样,降噪,标准化和30s切片等操作。其中采样频率设置为250hz。我们使用daubechies 6(db6)对心电信号进行9级小波变换去除d1,d2,a9分量,然后将剩下的分量重构,最终得到滤波后的信号。采用的标准化方法是最大最小归一化方法。最大最小归一化公式如下所示:
[0024][0025]
其中,x代表一个ecg样本,x
min
表示样本中的最小值,x
max
表示样本中的最大值,x
norm
表示标准化后的ecg样本。
[0026]
我们将切片长度设置为30s。最终获得数据集我们将切片长度设置为30s。最终获得数据集其中xk和分别表示第k个数据集以及数据集切片后的第i条心电信号,nk指第k个数据集中心电信号切片的数量。表示第i条心电信号的类别标签:当表示第i条心电
切片为非房颤节律;当表示第i条心电切片为房颤节律。
[0027]
第二阶段数据预处理主要包括对cinc2017数据集使用l-ros算法以及数据集分割,l-ros算法流程如图2所示。其中ros算法我们设置不平衡处理后的样本比例为1:1。然后设置lof算法的第k距离邻域为20,局部离散因子为0.6,当大于设定值时,样本被识别为离群值。局部离散因子的计算过程如下所示:
[0028]dk
(p)=d(p,o)
ꢀꢀꢀ
(4)
[0029]dreach
(p,o)=max(dk(p),d(p,o))
ꢀꢀꢀ
(5)
[0030][0031][0032]
其中k表示样本距离数,p和o分别代表两个心电信号,dk(p)表示第k邻域距离,d
reach
(p,o)第k可达距离,lrdk(p)表示局部可达密度,lofk(p)表示局部离散因子。
[0033]
我们获得最终的训练集为d={(x
*(1)
,y
*(1)
),(x
*(i)
,y
*(i)
),
…
,(x
*(m)
,y
*(m)
)},其中x
*(i)
表示第二阶段后的心电信号,y
*(i)
表示第二阶段后的类别标签,m表示第二阶段后训练集的样本个数。
[0034]
步骤2:将处理后的数据和标签输入到md-net中,md-net模型结构如图3所示。对于每一个输入值x
*(i)
,经过模型后的输出为e(i),在最后一层我们使用了softmax函数,具体等式如下所示:
[0035][0036][0037]
其中g(
·
)为模型函数,θ是模型md-net中的相关参数,c=2表示心率类别数,表示最终模型输出心电信号x
*(i)
的类别概率,最终我们将获得训练好的md-net模型。md-net模型的详细参数内容如表1所示:
[0038]
表1md-net模型详细参数
[0039]
[0040][0041]
步骤3:我们使用训练好的模型对三个测试集进行测试,验证模型的鲁棒性和泛化性。
[0042]
本发明提出的一种基于两阶段数据预处理和残差网络的房颤分类方法主要包括三个步骤:基于两阶段的数据预处理策略,md-net和测试模块。md-net主要由md-block,平均池化层,blstm层,dropout层和dense层组成。其中md-block是在残差网络的基础上结合特征金字塔的思想,提取心电信号的浅层和深层特征,同时与dropout层结合,对浅层和深层特征进行平衡,提取更稳定的特征信息。每一个md-block的过滤器个数从开始到结束分别为4,8,16,32,64,128。md-block中的dropout我们设置为0.4。在每个md-block后我们使用平均池化层对特征图进行降维,池化层步幅为2。最后使用softmax层实现分类。模型使用adam作为优化器,初始学习率为0.0001,分类交叉熵作为损失函数。在md-net中,模型设置最大迭代数为100,batch size为64。在回调函数中,同时调用tensorflow中的modelcheckpoint,reducelronplateau和earlystopping来协助模型达到最优的性能。为了降低模型的过拟合程度,我们将l2regularization与损失函数结合使用。在本发明中,我们在cinc2017、afdb和mitdb三个数据集上均使用十折交叉验证方法对实验结果进行验证,这样能够更加可靠的对模型的泛化能力进行评估。
[0043]
验证实验
[0044]
实验的原始心电数据分别取自physionet/cinc challenge 2017(cinc2017),mit-bih atrial fibrillation(afdb)和mit-bih arrhythmia(mitdb)。cinc2017数据集中所有的心电信号都是由alivecor设备收集的ⅰ导联信号。其中训练集包含8528条记录,每条记录的持续时间在9s到61s之间,采样率为300hz。数据集包含四种不同类型的心率,分别为:“af”(心房颤动),“normal”(正常心率),“other”(其他心率),“noise”(噪音)。在本实验中,我们将使用其中的房颤,正常和其他三类数据,并将其中的正常和其他归类为非房颤数据。afdb数据集包含25名心房颤动患者(大多数为阵发性房颤)的长期心电图记录。其中有23条记录包含两条心电信号可以被使用。每条记录的持续时间在10小时左右,采样频率为250hz,这些记录包含四种心率类型,分别为:“afib”(心房颤动),“afl”(心房扑动),“j”(交界性节律),“n”(其他节律)。在本实验中,我们仅使用afdb的ⅱ导联数据,将以上四种心率分为房颤和非房颤(心房扑动,交界性节律,其他节律)。mitdb数据集为心率失常数据集,主要包含48条双通道的心率失常记录,每一条的持续时间在半小时左右,采样频率为360hz。在本实验中,将mitdb数据集分为两类,其中一类为房颤,将除房颤以外的类都归类为非房颤。
[0045]
本发明的目的是降低模型的过拟合程度以及模型对于单个数据集的依赖性,提高
模型的鲁棒性和泛化性。为了解决以上问题,本发明提出一种基于两阶段数据预处理和残差网络的房颤分类方法。其中md-net结合残差网络和特征金字塔的思想,平衡模型对于浅层特征和深层特征的学习能力,利用md-block提高模型对于房颤的分类稳定性。同时本发明提出两阶段的数据预处理策略,其中第二阶段中的l-ros算法,对训练集中的异常值进行分析研究。
[0046]
为了证明所提md-block的有效性,我们设计了以下三种md-block的变体进行消融实验,分别为ma-block:该模块与原始残差网络模块相似,其中shortcut connections使用卷积的形式进行尺寸匹配。不同的是卷积核这里未采用1
×
1的方式,而是表1所示的卷积核大小。mb-block:该模块在ma-block的基础上,在原identity mapping处的卷积结束后添加dropout层。mc-block:该模块在ma-block的基础上,在residual mapping处每一个卷积层结束后添加dropout层。md-block的三种变体如图4所示。
[0047]
对以上md-block的三种变体以及md-block进行实验分析,实验结果如表2所示。从表2中我们可以看出,模型在使用使用ma-block进行训练,模型在cinc2017数据集上的表现较好,但是在其他数据集上的泛化性和房颤的检出率上表现非常差,这表明此时模型已经出现了很严重的过拟合现象。当分别使用mb-block和mc-block进行训练时,模型最后在其他数据集以及房颤的检出率上均有不同程度的提升,这表明mb-block和mc-block能够有效的提升模型的鲁棒性和泛化性。当使用md-block进行训练时,模型的鲁棒性和泛化性达到了最优。
[0048]
在确定md-block的优越性后,我们同时对md-block中dropout层的参数进行了分析,并将dropout层的参数分别设置为0.3,0.4,0.5。通过结果对比我们发现,随着dropout层系数的增大,模型的泛化性会经历一个从弱到强的过程,并在参数为0.4的时候,达到最好。此时模型在afdb和mitdb数据集上的泛化性有了很大的提升。与ma-block相比,使用md-block后,cinc2017数据集的sp指标从85.62%增长到89.93%,但是acc有微弱的下降。afdb数据集的sp指标从68.83%增长到93.63%,acc从87.17%增长到96.95%。mitdb数据集的sp指标从82.16%增长到96.77%,acc从94.98%增长到95.46%。
[0049]
表2md-block消融实验结果对比
[0050][0051]
在不断的实验中我们发现,训练集的数据成分对模型最终的泛化性有很大的影响。因此我们提出使用l-ros算法对训练集进行第二次数据预处理,这里我们设置l-ros算法中lof算法的第k距离邻域为20,离群因子使用表示,当大于设定值时,样本被识别为离群值。
[0052]
从表3的实验结果中我们可以看出,当我们使用l-ros算法对cinc2017数据集进行处理后,模型在cinc2017测试集以及afdb和mitdb数据集上的泛化性都有所提升,并且在离群因子时达到最好。其中cinc2017测试集的各项指标都有所提升,最为重要的是,三个数据集中sp指标均有明显的提高,同未使用l-ros模块时相比,模型在cinc2017数据集的sp指标提高了6.54%,afdb数据集的sp指标提高了1.13%,mitdb数据集的sp指标提高了1.41%。
[0053]
表3l-ros模块消融实验结果对比
[0054]
[0055]
在本实验中我们将vgg-16、resnet-18和googlenet作为基线模型进行了对比实验。我们从泛化性和模型参数量两个角度对模型性能进行比较。实验结果如表4所示。从模型参数量的角度来看,vgg-16的参数量最多,resnet-18和googlenet的参数量接近。但是与我们所提出的模型md-net相比,md-net的参数量更少。从泛化能力的角度来看,三种基线模型均能够在cinc2017数据集上取得较好的分类能力,其中googlenet的准确率最高,为97.77%。但是三种基线模型在afdb数据集和mitdb数据集上的分类能力普遍较差。与md-net相比,md-net不仅能够在cinc2017数据集上取得较好的分类结果,同时在afdb和mitdb数据集上也能够取得出众的分类结果。
[0056]
表4vgg-16、res-net和md-net实验结果展示
[0057][0058][0059]
接下来我们将通过roc曲线、auc面积和特征可视化的角度去更加准确的了解md-net的鲁棒性和泛化性。由于我们的实验均使用十折交叉验证的形式,因此我们将模型的roc曲线和auc面积按照十折交叉验证的形式进行了如图5所示的展示。从图5中我们可以看出,模型在cinc2017数据集进行训练后,在cinc2017的测试集、afdb和mitdb数据集均能够取得稳定的分类性能,达到了较好的鲁棒性和泛化性。
[0060]
图6我们对模型学习到的特征进行了可视化分析,首先我们将三个测试集输入模型并获得模型的全局平均池化层输出值,在全局平均池化层总共有18个特征,我们使用pca降维并选取前三个最重要的特征,将这三个特征作为三个维度。如图6所示,a、b、c展示的是cinc2017、afdb和mitdb三个数据集的可视化结果。cinc2017和afdb数据集中的非房颤类只包含两类心电信号且数据量较多,所以非房颤分布的区域比较大。mitdb的非房颤数据包含类别较多,所以在图像c中,非房颤的心电信号成几块聚集在一起,从图像d中我们可以看出,模型即使使用不同的数据集进行验证,同样能够取得较好的分类效果。
[0061]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1