具有旋转不变性的无人机目标重识别方法、系统及设备
augmentation.ieee tpami 40,2(2017),392
–
408.
8.[文献2]mang ye,jianbing shen,gaojie lin,tao xiang,ling shao,and steven c.h.hoi.2021.deep learning for person re-identification:a survey and outlook.ieee tpami(2021),1
–
1.
[0009]
[文献3]liang zheng,yi yang,and alexander g hauptmann.2016.person reidentification:past present and future.arxiv preprint arxiv:1610.02984(2016).
[0010]
[文献4]shizhou zhang,qi zhang,yifei yang,xing wei,peng wang,bingliang jiao,and yanning zhang.2020.person re-identification in aerial imagery.ieee tmm 23(2020),281
–
291.
[0011]
[文献5]sv kumar,ehsan yaghoubi,abhijit das,bs harish,and hugo2020.the p-destre:a fully annotated dataset for pedestrian detection,tracking,reidentification and search from aerial devices.arxiv preprint arxiv:2004.02782(2020).
[0012]
[文献6]tianjiao li,jun liu,wei zhang,yun ni,wenqian wang,and zhiheng li.2021.uav-human:a large benchmark for human behavior understanding with unmanned aerial vehicles.in cvpr.16266
–
16275.
[0013]
[文献7]yifan sun,liang zheng,yi yang,qi tian,and shengjin wang.2018.beyond part models:person retrieval with refined part pooling(and a strong convolutional baseline).in eccv.480
–
496.
[0014]
[文献8]guanshuo wang,yufeng yuan,xiong chen,jiwei li,and xi zhou.2018.learning discriminative features with multiple granularities for person re-identification.in acm mm.274
–
282.
[0015]
[文献9]hao luo,wei jiang,youzhi gu,fuxu liu,xingyu liao,shenqi lai,and jianyanggu.2019.a strong baseline and batch normalization neck for deep person re-identification.ieee tmm 22,10(2019),2597
–
2609.
[0016]
[文献10]kaiyang zhou,yongxin yang,andrea cavallaro,and tao xiang.2019.omni-scale feature learning for person re-identification.in iccv.3702
–
3712.
[0017]
[文献11]xiaolong wang,ross girshick,abhinav gupta,and kaiming he.2018.non-local neural networks.in cvpr.7794
–
7803.
[0018]
[文献12]alexey dosovitskiy,lucas beyer,alexander kolesnikov,dirk weissenborn,xiaohuazhai,thomas unterthiner,mostafa dehghani,matthias minderer,georg heigold,sylvain gelly,et al.2020.an image is worth 16x16 words:transformers for image recognition at scale.arxiv preprint arxiv:2010.11929(2020).
[0019]
[文献13]aharon azulay and yair weiss.2018.why do deep convolutional networks gen eralize so poorly to small image transformations?arxiv preprint arxiv:1805.12177(2018).
[0020]
[文献14]gong cheng,peicheng zhou,and junwei han.2016.rifd-cnn:rotation-invariant and fisher discriminative convolutional neural networks for object detection.in cvpr.2884
–
2893.
[0021]
[文献15]max jaderberg,karen simonyan,andrew zisserman,et al.2015.spatial transformer networks.advances in neural information processing systems 28(2015),2017
–
2025.
技术实现要素:
[0022]
为了解决上述技术问题,本发明提供了一种基于vision transformer(vit)的具有旋转不变性的无人机目标重识别方法、系统及设备,实现了无人机场景目标重识别准确率的提升。
[0023]
本发明的方法所采用的技术方案是:一种具有旋转不变性的无人机目标重识别方法,采用旋转不变目标识别网络进行无人机目标重识别;所述旋转不变目标识别网络,包括块生成模块和若干transformer层;
[0024]
具体包括以下步骤:
[0025]
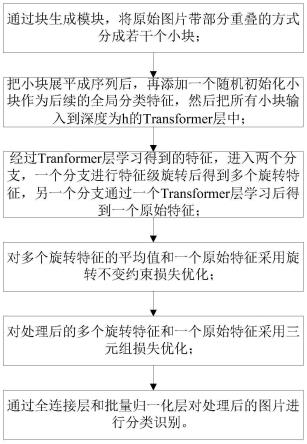
步骤1:通过块生成模块,将原始图片带部分重叠的方式分成若干个小块;
[0026]
步骤2:把小块展平成序列后,再添加一个随机初始化小块作为后续的全局分类特征,然后把所有小块输入到深度为h的transformer层中;
[0027]
步骤3:经过步骤2中的tranformer层学习得到的特征,进入两个分支,一个分支进行特征级旋转后得到多个旋转特征,另一个分支通过一个transformer层学习后得到一个原始特征;
[0028]
步骤4:对多个旋转特征的平均值和一个原始特征采用旋转不变约束损失优化;
[0029]
步骤5:对步骤4处理后的多个旋转特征和一个原始特征采用三元组损失优化;
[0030]
步骤6:通过全连接层和批量归一化层对步骤5处理后的图片进行分类识别。
[0031]
本发明的系统所采用的技术方案是:一种具有旋转不变性的无人机目标重识别系统,采用旋转不变目标识别网络进行无人机目标重识别;所述旋转不变目标识别网络,包括块生成模块和若干transformer层;
[0032]
具体包括以下模块:
[0033]
模块1,用于通过块生成模块,将原始图片带部分重叠的方式分成若干个小块;
[0034]
模块2,用于把小块展平成序列后,再添加一个随机初始化小块作为后续的全局分类特征,然后把所有小块输入到深度为h的transformer层中;
[0035]
模块3,用于经过模块2中的tranformer层学习得到的特征,进入两个分支,一个分支进行特征级旋转后得到多个旋转特征,另一个分支通过一个transformer层学习后得到一个原始特征;
[0036]
模块4,用于对多个旋转特征的平均值和一个原始特征采用旋转不变约束损失优化;
[0037]
模块5,用于对模块4处理后的多个旋转特征和一个原始特征采用三元组损失优化;
[0038]
模块6,用于通过全连接层和批量归一化层对模块5处理后的图片进行分类识别。
[0039]
本发明的设备所采用的技术方案是:一种具有旋转不变性的无人机目标重识别设备,包括:
[0040]
一个或多个处理器;
[0041]
存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现所述的具有旋转不变性的无人机目标重识别方法。
[0042]
本发明具有以下优点:
[0043]
(1)本发明设计了一种新的特征级的旋转策略来增强应对无人机旋转变化的泛化能力。
[0044]
(2)本发明将旋转不变性约束集合到特征学习过程中,增强了对空间变化的鲁棒性,减少了因旋转变化导致的错误分类。
[0045]
(3)本发明提出的方法在无人机和城市摄像头上进行评估,取得了比目前最先进技术更好的表现。在具有挑战性的prai-1581数据集上,rank-1/map从63.3%/55.1%提升到70.8%/63.7%.
附图说明
[0046]
图1为本发明实施例的方法流程图;
[0047]
图2为本发明实施例的旋转不变目标识别网络架构图;
[0048]
图3为本发明实施例的特征级旋转原理图。
具体实施方式
[0049]
为了便于本领域普通技术人员理解和实施本发明,下面结合附图及实施案例对本发明做进一步的详细描述,应当理解,此处所描述的实施示例仅用于说明和解释本发明,并不用于限定本发明。
[0050]
考虑到vit有很强的建模能力和泛化能力,在常见的目标识别任务上表现很出色。本发明的核心思想是基于vit设计一种新的特征级的旋转策略来增强应对旋转变化的泛化性,并将旋转不变性约束集成到特征学习过程中,增强对空间变化的鲁棒性,以减少因旋转变化导致的错误分类。具体地,本发明提出了一种在特征级上模拟块特征旋转来产生旋转特征的方法。最后,本发明在多个旋转特征和原始特征之间建立强约束,与原始目标一起优化,从而提高了检索率。
[0051]
请见图1,本发明提供的一种具有旋转不变性的无人机目标重识别方法,采用旋转不变目标识别网络进行无人机目标重识别;旋转不变目标识别网络,包括块生成模块和若干transformer层;
[0052]
请见图2,本实施例的块生成模块包含一个卷积层,采用重叠方式以16*16为单位分割源图像。使用卷积核大小为16*16,步长为12。transformer层由msa(多头自注意力)和mlp(两层使用gelu激活函数的全连接网络)组成,在msa和mlp之前均加上了layernorm和残差连接。
[0053]
本实施例的方法具体包括以下步骤:
[0054]
步骤1:通过块生成模块,将原始图片带部分重叠的方式分成若干个小块;
[0055]
步骤2:把小块展平成序列后,再添加一个随机初始化小块作为后续的全局分类特征,然后把所有小块输入到深度为h的transformer层中;
[0056]
步骤3:经过步骤2中的tranformer层学习得到的特征,进入两个分支,一个分支进行特征级旋转后得到多个旋转特征,另一个分支通过一个transformer层学习后得到一个原始特征;
[0057]
由框架网络学习的全局特征表示成n+1在这里由长为n的块序列(表示为f
p
)和一个全局分类特征组成(表示为co,包括n个原特征)。为了模拟二维空间的旋转操作,本实施例将重构为x和y在此表示通过重叠块嵌入产生的步长为s的空间大小。x和y的计算公式是:
[0058][0059]
其中,w、h是图像的长和宽,p是一个块的大小,d是维度;
[0060]
请见图3,本实施例把每个块都看作一个像素,f
res
在视觉上可被看作一个二维矩阵。通过这种方法,本实施例可以将类似于旋转矩阵的操作应用到块特征级别。由于无人机的持续移动,捕捉到的矩阵角度是随机变化的。本实施例通过随机产生一系列角度a={θi|i=1,2,
…
,n}。二维矩阵里每个块向量的坐标表示为(x,y),旋转角度公式是:
[0061][0062][0063]
与基于像素的图片旋转不同,特征级旋转是在更大块上进行的,所以旋转一个数值看起来很小的角度实际上模拟了一个相对较大的旋转。因此,本实施例定义一个参数α来限制产生的角度的大小,θ∈[-α,α]。通过实施上述旋转操作得到一系列多角度旋转图片fr={f
r1
,f
r2
,
…
,f
rn
}。在这一步,无人机场景的多角度特点被提前引入模型来模拟多样化旋转,全局分类特征从原来图片学习所有信息。
[0064]
步骤4:对多个旋转特征的平均值和一个原始特征采用旋转不变约束损失优化;
[0065]
步骤3中的特征级旋转从多样性角度提升了网络对角度变化的泛化能力。此外,旋转特征和原始特征都表示同一个目标。本实施例人为地将旋转特征和原始特征的不变性约束加入损失函数中,以建立它们之间的关系。通过这种方法,缩短了类内的距离(mang ye,jianbing shen,xu zhang,pong c yuen,and shih-fu chang.2020.augmentation invariant and instance spreading feature for softmaxembedding.ieee tpami(2020)),更有利于正确分类。旋转特征的一组全局分类特征cr与原始特征的全局分类特征co之间存在多对一的关系.如果为每对原始特征和每个旋转特征建立约束,将花费巨大的计算成本。为了避免冗余计算,使用旋转特征的平均值来建立不变性,表示为:
[0066][0067]
其中,c
r1
、c
r2
、
…
、c
rn
分别表示为每个旋转特征的添加的用于分类的全局特征。
[0068]
本实施例的目标是限制平均旋转特征和原始特征之间的差异。有必要确保旋转特
征表现出来的类别区分不会被削弱。mean square error(mse)是最常用的损失函数,它表示预测值与目标值之差的平方和。本实施例选择smooth l1 loss来计算差值,这可以有效防止梯度爆炸问题。该部分的旋转不变性约束表示为:
[0069][0070]
在训练阶段,整体损失函数由三个部分组成。当旋转特征更新时,原始特征也被输入到一个transformer层以进一步更新代表全局的全局分类特征。本实施例将通过多个transformer层学习得到的原始特征表示为co。在批标准化后,同样采用三元组损失和交叉熵损失:
[0071][0072]
此外,平均旋转特征是一种适应角度多样性的辅助特征表示。不变性约束控制着原始特征和旋转特征之间的差异。总体学习目标函数是:
[0073][0074]
其中,λ和1-λ分别表示原始特征和旋转特征的比重。
[0075]
步骤5:对步骤4处理后的多个旋转特征和一个原始特征采用三元组损失优化;
[0076]
步骤6:通过全连接层和批量归一化层(bn层)对步骤5处理后的图片进行分类识别。
[0077]
本实施例的旋转不变目标识别网络,为训练好的旋转不变目标识别网络;由于旋转的随机性,每一个含有不同信息的旋转特征可以被看作一个新的特征。为了学习多样的特征,二维应该被展平成如此transformer就可以收到以为块序列。每一个旋转的特征有和原特征一样的相同的大小为n的块,并且分类时很难涵盖所有块的信息。经过多个transformer层学习后的全局分类特征融入了全局特征表现。本实施例通过向每一个旋转特征加入n个原特征的全局分类特征co的复制,得到这个操作的目的是每个旋转特征可以通过一个可学习的全局分类特征来分类,作为n个旋转块的样本c
r1
、c
r2
、
…
、c
rn
。然后,本实施例分别为每个样本建立一个transformer层来保证学习到多样性。训练时表示旋转特征的cr的全局分类特征的更新是基于已经包含丰富特征信息的原始全局分类特征co,这有效避免了旋转特征带来的损失。本实施例为transformer层更新的旋转特征的全局分类特征设立了n个分类器。在批标准化(hao luo,wei jiang,youzhi gu,fuxu liu,xingyu liao,shenqi lai,and jianyanggu.2019.a strong baseline and batch normalization neck for deep person re-identification.ieee tmm 22,10(2019),2597
–
2609)后使用最常用的交叉熵损失函数。此外,为了进行细粒度识别,在每个全局分类特征使用三元组损失函数(alexander hermans,lucas beyer,and bastian leibe.2017.in defense of the triplet loss for person re-identification.arxiv preprint arxiv:1703.07737(2017))。旋转特征的最后损失函数是:
[0078][0079]
每一个代表旋转特征的全局分类特征对整个模型的更新发挥着等同作用。
[0080]
下面结合具体实验进一步阐述本实施例的原理。
[0081]
本实施示例采用的深度学习框架为pytorch。实验的硬件环境是nvidia geforce rtx3090*8显卡,处理器为intel(r)xeon(r)gold 6240。实验流程如下:
[0082]
第一步:旋转特征生成网络搭建
[0083]
实验中采用vision transformer(vit)网络作为特征提取器,在特征级上模拟块特征旋转来产生旋转特征,最后建立原始特征和旋转后的特征之间的约束。并采用身份分类损失、三元组损失、smooth l1损失、交叉熵损失联合端到端特征提取器、旋转特征生成网络和旋转不变约束。
[0084]
第二步:网络训练
[0085]
划分目标对象照片和无人机拍摄照片为训练集和测试集。目标对象照片被送入特征旋转网络进行训练。利用前向传播和反向传播对网络参数进行优化和更新。
[0086]
第三步:网络测试
[0087]
测试集中目标对象的图像作为待查询集,无人机拍摄样本集作为图库集。采用训练过程中效果最好模型进行推理,得到测试集上最终检索结果。评价指标采用rank-1、rank5、map、minp匹配精度,该精度反应了正确的重识别图像的检索概率。
[0088]
本发明在prai-1581,uavhuman,vrai三个由无人机拍摄的数据集和market1501、msmt7是两个常用的使用地面监控摄像头收集的行人重识别数据集。prai-1581是为无人机任务提出的数据集。它由两架在20米至60米高度飞行的无人机拍摄的1581名行人的39461张图像组成。uavhuman主要用于无人机行人行为研究,也可以被用到例如行人重识别、动作识别和高度估测等多种任务中。这个数据集包含1444个行人和41290张图像。vrai是由13033辆车的137613张照片组成的车辆重识别数据集。车辆图片由在不同地方飞行的高度在15米到80米的无人机收集。同时也有丰富的注释,包含颜色、车种类、属性、图片和有区别的地方。
[0089]
本发明将图像统一调整为256*256。此外,在训练数据中采用10个像素的填充、随机裁剪和概率为0.5的随机擦除。用imagenet-1k预先训练的参数进行网络参数初始化。在重叠块嵌入阶段,patch大小设置为16,步幅大小设置为12。在特征级旋转中,旋转的特征数n为4,随机旋转角度的范围在-15度到15度之间。由于是基于块旋转,所以角度不宜设置过大。对于主干提取的原始特征和旋转特征,使用无边距的三元组损失,并在特征通过批泛化层后使用交叉熵损失。原始特征λ的权重为0.5,旋转特征1-λ的权重为0.5。在平均旋转特征和原始特征之间应用smooth l1损失。在训练期间,使用随机梯度下降(sgd)优化器。初始学习率为0.008,采用余弦学习率衰减。训练次数为200。批大小设置为64,包括16个身份,每个身份有4张图像。在测试阶段,仅使用原始特征来计算距离矩阵。整个实验的实现基于pytorch。
[0090]
为了验证本发明的有效性,本节将本发明的检索结果与现有的无人机重识别方法进行了对比,现有的目标重识别方法主要有:
[0091]
(1)pcb:jianlou si,honggang zhang,chun-guang li,jason kuen,xiangfei kong,alex c kot,and gang wang.2018.dual attention matching network forcontext-aware feature sequence based person re-identification.in cvpr.5363
–
5372.
[0092]
(2)sp:shizhou zhang,qi zhang,yifei yang,xing wei,peng wang,bingliang jiao,and yanning zhang.2020.person re-identification in aerial imagery.ieee tmm 23(2020),281
–
291.
[0093]
(3)agw:mang ye,jianbing shen,gaojie lin,tao xiang,ling shao,and steven c.h.hoi.2021.deep learning for person re-identification:a survey and outlook.ieee tpami(2021),1
–
1.
[0094]
(4)multi-task:peng wang,bingliang jiao,lu yang,yifei yang,shizhou zhang,wei wei,and yanning zhang.2019.vehicle re-identification in aerial imagery:dataset and approach.in iccv.460
–
469.
[0095]
(5)baseline(vit):shuting he,hao luo,pichao wang,fan wang,hao li,and wei jiang.2021.transreid:transformer-based object re-identification.in iccv.15013
–
15022.
[0096]
(6)transreid:shuting he,hao luo,pichao wang,fan wang,hao li,and wei jiang.2021.transreid:transformer-based object re-identification.in iccv.15013
–
15022.
[0097]
在prai-1581,uavhuman,vrai数据集上进行测试,结果见表1
[0098]
表1
[0099][0100]
在market-1501和msmt17数据集上进行测试,结果见表2
[0101]
表2
[0102][0103]
从表1和表2可以看出:与近些年re-id相比,本发明所提方法不管在无人机目标重识别和城市摄像头目标重识别上均实现了检索率的提升。在prai-1581数据集上,所提方法性能明显优于表中所有方法,所提方法在rank1和map上分别优于当前最优方法transre-id 4.8%和5.9%。在uavhuman数据集上,map优于当前最优方法transre-id 2%。在vrai数据集上,本发明提出的方法在不使用任何辅助信息的情况下实现了83.5%的rank1准确率和84.8%的map,超过了所有其他方法。在market-1501和msmt17数据集上,提出的方法在普通城市摄像头场景下实验也显示本发明的方法具有强大的泛化能力,map和rank1比目前最优分别提高了5.4%和3.2%。在三个无人机采集数据集和两个地面摄像头采集数据集上的实验结果,证明了本发明所提方法的有效性和泛化性。
[0104]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1