一种基于注意力图的视觉Transformer模型剪枝方法
一种基于注意力图的视觉transformer模型剪枝方法
技术领域
1.本发明属于神经网络轻量化技术领域,具体涉及一种基于注意力图的视觉transformer模型剪枝方法。
背景技术:
2.transformer是一种主要基于自注意机制的深度神经网络,应用于自然语言处理领域,视觉transformer模型简称vit模型,transformer具有强大的长程依赖关系的建模能力,已经在各种视觉任务中取得了令人瞩目的成功,然而,transformer模型的巨大计算量和内存消耗是其固有问题,使其无法在资源有限的边缘端计算设备上成功部署并投入使用,剪枝是一种有效降低神经网络推理成本的常用方法,已广泛应用于计算机视觉和自然语言处理应用中。
3.基于注意力图的模型剪枝方法可用于将神经网络模型部署在低功耗、计算资源受限的嵌入式机器视觉推理系统中,包括基于图形处理器加速的嵌入式计算板和基于神经网络处理器,该类系统一般只能提供相当于高性能gpu不到20%的计算资源。
4.剪枝操作一般可以分为非结构化剪枝和结构化剪枝两大类,具体来说,非结构化剪枝在特定标准下删除单个不重要的权重,非结构化剪枝属于精细范式,对精度有少许损害,实际加速需要特殊的硬件设计,结构化剪枝移除了模型的整个子结构,例如通道和注意力头,已经有一些工作通过减少计算图像编码块的数量修剪vit,tang等人开发了一种自上而下的图像块剪枝方法,该方法基于预训练模型的重建误差去除冗余图像块,xu等人基于结构维持的图像编码块选择和慢-快结合的更新策略以完全利用整个空间结构;上述方法虽然可以节省计算成本,但不能降低推理复杂性和减小模型大小,为此我们提出一种基于注意力图的视觉transformer模型剪枝方法。
技术实现要素:
5.本发明的目的在于提供一种基于注意力图的视觉transformer模型剪枝方法,以解决上述背景技术中提出的问题。
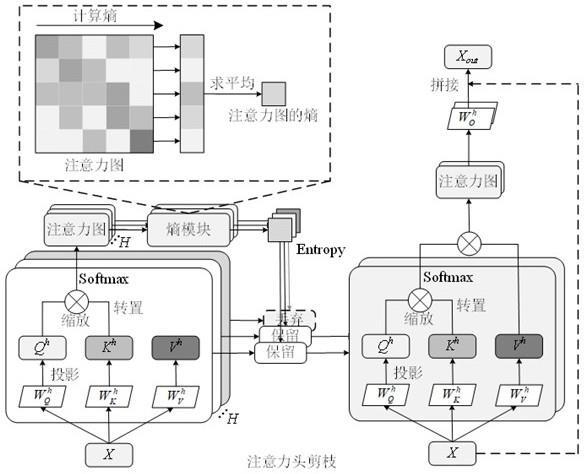
6.为实现上述目的,本发明提供如下技术方案:一种基于注意力图的视觉transformer模型剪枝方法,应用于机器视觉推理系统,包括如下步骤:步骤a、在机器视觉推理系统中,通过数据训练网络对vit模型执行若干轮初始训练,以生成完整的注意力图;步骤b、计算注意力图的信息熵,根据计算的信息熵大小对注意力头进行剪枝操作,度量注意力图的不确定性;步骤c、移除被剪枝注意力头关联的各权重参数,以获得新vit模型;步骤d、重新微调新vit模型的参数。
7.优选的,在所述的步骤a中,vit模型将输入图像拆分为n个图像块,并对每个图像块附加一个类编码,然后将附加类编码的n个图像块馈送到与普通transformer类似的编码
器中,形成n个图像编码块。
8.优选的,所述的步骤a,包括如下步骤:a1、在vit模型训练的初始阶段,vit模型没有学习到有用的信息,此时注意力图是无序的,且注意力图具有大的信息熵;a2、在vit模型经过若干轮的初始训练,vit模型学习到基本信息,并开始呈现出一定的模式;a3、在vit模型训练的最终阶段,当vit模型收敛时,每个注意力头都获得了注意力图,此时重要的图像编码块会受到注意力头的高度关注,信息熵会降低,所有注意力图都是一个训练轮次的平均结果。
9.优选的,在所述的步骤b中,在vit模型执行若干轮初始训练后,当注意力头学习到的有用信息增加,注意力头会关注图像编码块,使得信息熵降低,注意力图具有确定性;当注意力头学习到的有用信息少时,注意力头对全局有统一的关注,使得信息熵增加,从而产生大的不确定性,此过程中信息熵用于衡量注意力图的不确定性。
10.优选的,在所述的步骤b中,对于transformer块而言,多头自注意力msa和多层感知机mlp是花费计算资源的主要部分;表示第l层的输入,且,则注意力头h的注意力计算如公式(1)所示:
ꢀꢀꢀ
(1);其中,;q、k、v分别表示多头注意力机制中的“查询”、“键”和“值”;对于第l层中的第h个注意力头模块而言,参与生成注意力图,计算的“查询”、“键”和“值”分别表示为;d表示注意力头嵌入维度;n表示输入进vit模型的图像块的数量;t表示注意力头为h的视觉transformer网络;则多头自注意力msa的计算如公式(2)所示:
ꢀꢀꢀ
(2);表示4个投影矩阵的总和;h表示注意力头的数量。
11.优选的,通过公式(1)和公式(2)包含的参数计算复杂度如公式(3)所示:
ꢀꢀꢀꢀ
(3);c表示参数计算复杂度;4ndhd表示投影计算的计算量总和;
同时参数量如公式(4)所示: (4);p表示参数量;表示使用公式(1)计算注意力图的计算量;d表示嵌入维度,当vit模型还没有被剪枝时,d=hd。
12.优选的,视觉transformer的输入序列是长序列场景时,自注意力的计算复杂度表示为;当视觉transformer的序列长度不能支配全部多头注意力模块的复杂度时,自注意力的计算复杂度表示为。
13.优选的,在vit模型被剪枝后,注意力头的数量被剪枝为,则剪枝后的复杂度如公式(5)所示:
ꢀꢀ
(5);同时参数量如公式(6)所示:
ꢀꢀ
(6)。
14.优选的,在所述的步骤b中,注意力图表示第l层和注意力头h的注意力图,则注意力图的信息熵如公式(7)所示:
ꢀꢀ
(7);表示第i个查询编码块第j个键编码块的相似度;对于第i个查询图像块,在注意力计算中进行softmax操作,则表示键图像块到第i个查询编码块的概率分布。
15.与现有技术相比,本发明的有益效果是:1、通过对视觉transformer模型结构的分析发现模型中的多头注意力模块占据了大量的计算资源,而对多头注意力模块进行剪枝,删除具有高不确定性的特征图和相应的注意力头,以减少vit模型的参数和复杂性,降低vit模型的计算复杂度和参数量,能够在不大规模影响vit模型精度的情况下,缩减vit模型大小,最终达到在vit模型性能有限损失的情况下实现vit模型的轻量化;2、相比传统剪枝方法,本发明利用注意力图引导了注意力头的剪枝操作,而非传统的泰勒准则,为剪枝决策提供了新的思路;3、通过信息熵度量了各个注意力头的重要性,指导剪枝决策。
附图说明
16.图1为本发明的注意力头剪枝流程示意图;图2为本发明的方法流程示意图。
具体实施方式
17.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
18.请参阅图1-图2,本发明提供的基于注意力图的视觉transformer模型剪枝方法,应用于机器视觉推理系统,包括如下步骤:步骤a、在机器视觉推理系统中,通过数据训练网络对vit模型执行若干轮初始训练,以生成完整的注意力图;在步骤a中,vit模型将输入图像拆分为n个图像块,并对每个图像块附加一个类编码,然后将附加类编码的n个图像块馈送到编码器中,形成n个图像编码块;步骤a包括如下步骤:a1、在vit模型训练的初始阶段,vit模型没有学习到有用的信息,此时注意力图是无序的,且注意力图具有大的信息熵;a2、在vit模型经过若干轮的初始训练,vit模型学习到基本信息,并开始呈现出一定的模式;a3、在vit模型训练的最终阶段,当vit模型收敛时,每个注意力头都获得了注意力图,此时重要的图像编码块受到注意力头的高度关注,使得信息熵降低,所有注意力图都是一个训练轮次的平均结果;步骤b、计算注意力图的信息熵,根据计算的信息熵大小对注意力头进行剪枝操作,度量注意力图的不确定性;在步骤b中,在vit模型执行若干轮初始训练后,当注意力头学习到的有用信息增加,注意力头会关注图像编码块,使得信息熵降低,使得注意力图更具确定性;当注意力头学习到的有用信息少时,注意力头对全局有统一的关注,使得信息熵增加,从而产生大的不确定性,此过程中信息熵用于衡量注意力图的不确定性;在步骤b中,对于transformer块而言,多头自注意力msa和多层感知机mlp是花费计算资源的主要部分;表示第l层的输入,且,则注意力头h的注意力计算如公式(1)所示:
ꢀꢀꢀ
(1);其中,;q、k、v分别表示多头注意力机制中的“查询”、“键”和“值”;对于第l层中的第h个注意力头模块而言,参与生成注意力图,计算的“查询”、“键”和“值”分别表示为;
d表示注意力头嵌入维度;n表示输入进vit模型的图像块的数量;t表示注意力头为h的视觉transformer网络;则多头自注意力msa的计算如公式(2)所示:
ꢀꢀꢀ
(2);表示4个投影矩阵的总和;h表示注意力头的数量;通过公式(1)和公式(2)包含的参数计算复杂度如公式(3)所示:
ꢀꢀꢀꢀ
(3);c表示参数计算复杂度;4ndhd表示投影计算的计算量总和;同时参数量如公式(4)所示: (4);p表示参数量;表示使用公式(1)计算注意力图的计算量;d表示嵌入维度,当vit模型还没有被剪枝时,d=hd。
19.视觉transformer的输入序列是长序列场景时,自注意力的计算复杂度表示为;当视觉transformer的序列长度不能支配全部多头注意力模块的复杂度时,自注意力的计算复杂度表示为。
20.在本实施例中,如图1所示,在vit模型被剪枝后,注意力头的数量被剪枝为,则剪枝后的复杂度如公式(5)所示:
ꢀꢀ
(5);同时参数量如公式(6)所示:
ꢀꢀ
(6)。
21.在步骤b中,注意力图表示第l层和注意力头h的注意力图,则注意力图的信息熵如公式(7)所示:
ꢀꢀ
(7);表示第i个查询编码块第j个键编码块的相似度;对于第i个查询图像块,在注意力计算中进行softmax操作,则表示键图像块到第i个查询编码块的概率分布;
步骤c、移除被剪枝注意力头关联的各权重参数,以获得新vit模型;步骤d、重新微调新vit模型的参数;vit模型剪枝方法如下表1所示:表1:该基于注意力图的vit模型剪枝方法可用于将神经网络模型部署在低功耗、计算资源受限的嵌入式机器视觉推理系统中,包括基于图形处理器加速的嵌入式计算板和基于神经网络处理器,该机器视觉推理系统一般只能提供相当于高性能gpu不到20%的计算资源,由于存储和计算资源限制视觉transformer模型部署非常困难,本专利在完成剪枝任务后,对存储、数据带宽和计算资源的需求可降低到嵌入式机器视觉推理系统的计算能力范围内,顺利实现视觉transformer模型的边缘端部署;本发明将视觉transformer模型多头自注意力模块中的键维度上的特征视为概率分布,并进一步计算信息熵以呈现注意力的不确定性,然后通过删除具有高不确定性的特征图和相应的注意力头,以减少vit模型的参数和复杂性,降低vit模型的计算复杂度和参数量,最终达到在vit模型性能有限损失的情况下实现vit模型的轻量化。
22.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1