一种用于行人重识别的基于样本孤立机制的身份隐私保护方法和系统
1.本发明属于信息技术领域,具体涉及一种用于行人重识别的基于样本孤立机制的身份隐私保护方法和系统。
背景技术:
2.随着数字时代的到来,人们对行人重识别越来越感兴趣,它从不同摄像机的数据库中返回相同的身份。现有的工作已经取得了显著的检索性能。然而,他们忽略了身份信息的泄露,这在行人重识别领域中非常重要。我们将目标人物表示为对私人保护有很高要求的重要人物,如名人或政治领袖。但是,恶意用户(入侵者)一旦获得非法访问,就可以入侵行人重识别模型。同时,入侵者可以通过社交媒体轻松获取目标人物的图像,例如从网络新闻和在线搜索引擎中下载。然后,目标人物将在密集查询(攻击)下被检索(暴露),泄露个人身份信息,例如他是谁、他的行程轨迹等。这可能进一步导致恶意攻击等不良情况,甚至是一些安全问题,例如跟踪和绑架。
3.从平台的角度来看,如何主动保护目标人物不被潜在入侵者恶意检索成为本方法的重点。现有方法中,对抗攻击主要通过干扰像素的方式稍微修改干净图像,生成人类难以察觉的对抗扰动图像,以高置信度输出不一致结果误导模型输出错误的预测。近期工作还为行人重识别模型的对抗攻击提供了新的视角,他们根据训练数据生成扰动,并将它们添加到干净的图像中,作为误导排名的恶意查询。这种“从对抗到干净”的攻击范式(扰动查询和干净的结果)是对抗性攻击领域中突出的学习策略。受此启发,通过对抗扰动来保护身份信息是目前的一种解决方法。
4.在图像检索机制中,两个开创性的工作cwdm和ppl对类似问题进行了早期探索,他们训练对抗性扰动并将它们直接添加到数据库中的私有图像中,以逃避干净但恶意的查询。这可以称为“从干净到对抗”的保护范式,即查询数据库中的干净图像(具有恶意目的)和对抗图像(受保护的目标人物)。然而,将这些基于对抗的方法简单地应用于抢先保护行人重识别将导致退化的结果。本发明将此归功于“重叠身份”问题。具体来说,以前的方法只关注将对抗性图像推离其原始身份,这可能会使对抗性图像移动到其他身份附近。然后,如果攻击者使用其他身份发起查询,仍然可以检索到目标人物的图像,因此极大地阻碍了保护能力。
技术实现要素:
5.本发明的目的在于研究数据库图像之间保护范式的最佳关系是什么,因此,本发明深入研究了保护的主要目的,即最大限度地保护目标人物不被检索(暴露)。或者等效地,使目标人物与密集查询隔离(无论查询属于什么身份)。受此启发,本发明从如何找到最佳关系的角度重新思考“从干净到对抗”的保护范式。
6.本发明采用的技术方案如下:
7.一种用于行人重识别的基于样本孤立机制的身份隐私保护方法,包括以下步骤:
8.给定干净图像,通过生成器学习扰动以生成相应的对抗图像;
9.将对抗图像和干净图像输入目标模型中,分别获得对抗特征和干净特征;
10.针对目标模型,利用对抗特征和干净特征,采用身份隔离损失、错误分类损失和错误排序损失对生成器进行训练,以生成最佳扰动;
11.将生成的最佳扰动添加到目标人物的图像中,得到目标人物的对抗图像;
12.通过对抗图像保护目标人物以防御恶意查询。
13.进一步地,所述身份隔离损失最大化目标人物的对抗图像与数据库中所有干净图像的总体距离,将目标人物的对抗图像明确限制在一个孤立的位置,使目标人物既远离原始身份也远离任何其他身份,从而保护目标人物不会被非法查询检索到。
14.进一步地,所述身份隔离损失为:
[0015][0016]
其中b表示批量大小,f(x
′i)表示对抗样本输出的特征,fc是每个身份质心的特征,c是所有训练图像的总身份数量。
[0017]
进一步地,所述错误排序损失最小化对抗图像的负对的距离并最大化对抗图像的正对的距离;所述错误排序损失为:
[0018][0019]
其中m是平衡边际,x
′j和x
′k分别表示图像x
′i的正例和负例,f(x
′j)表示正例样本输出的特征,f(x
′k)表示负例样本输出的特征。
[0020]
进一步地,所述错误分类损失为:
[0021][0022]
其中yi是x
′i的真实标签,yi是属于真实标签的概率的预测值,由全连接分类器输出。
[0023]
进一步地,通过两种攻击方式和成功保护率指标评估和量化保护能力,所述两种攻击方式为随机攻击和顺序攻击。
[0024]
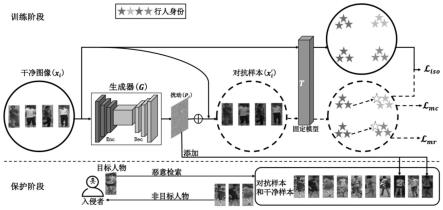
进一步地,所述成功保护率定义为:
[0025][0026]
其中,sprr表示随机攻击的成功保护率,spro表示顺序攻击的成功保护率,n
ta
是总攻击次数;检索结果返回的所有图像会与查询图像形成相似到不相似的排序列表,r
p
是目标人物图像在排序列表中第一次出现的位置;n
gallery
是数据库中图像的数量;对于顺序攻击,表示前n
ta
个图像;对于随机攻击,表示随机选择的n
ta
个图像。
[0027]
一种用于行人重识别的基于样本孤立机制的身份隐私保护系统,其包括:
[0028]
训练模块,用于给定干净图像,通过生成器学习扰动以生成相应的对抗图像;将对
抗图像和干净图像输入目标模型中,分别获得对抗特征和干净特征;利用对抗特征和干净特征,采用身份隔离损失、错误分类损失和错误排序损失对生成器进行训练,以生成最佳扰动;
[0029]
保护模块,用于将生成的最佳扰动添加到目标人物的图像中,得到目标人物的对抗图像,通过对抗图像保护目标人物以防御恶意查询。
[0030]
与现有方法相比,本发明提出了一种新颖的主动保护行人重新识别方法,该方法(pride)通过给定一个目标人物(需要主动的保护),生成最佳扰动并将它们添加到数据库中目标人物的图像中。因此,对抗性(受保护的)图像不会被非法查询检索到。为此,本发明首先介绍了“重叠身份”问题,它显示了在详尽查询所有其他身份时被检索到的潜在风险。为了解决这个问题,本发明提出了一种身份隔离机制,以最大化对抗性图像(受保护的目标人物)与数据库中所有干净图像的总体距离。通过将对抗性图像明确限制在一个孤立的位置,目标人物既远离原始身份,也远离任何其他身份,从而保护他不会被非法查询检索到。本发明进一步提出了一种新的成功保护率指标和两种关键攻击(随机攻击和顺序攻击)来全面评估和量化本发明方法的保护能力。
附图说明
[0031]
图1是主动保护行人重新识别(pride)方法示意图。
[0032]
图2是样本孤立机制示意图。
[0033]
图3是对比面对两种攻击方式的不同保护效果图。
[0034]
图4是可视化效果图。
具体实施方式
[0035]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面通过具体实施例和附图,对本发明做进一步详细说明。
[0036]
一、本发明的技术方案
[0037]
如图1所示,本发明提出的一种新颖的主动保护行人重新识别方法(pride)主要分为两个阶段:
[0038]
在第一阶段,给定一张干净的图像(干净图像是指未添加对抗扰动的原始图像),生成器旨在学习扰动以生成相应的对抗图像,然后将对抗图像和干净图像输入固定目标模型中,分别获得对抗特征和干净特征,利用对抗特征和干净特征,采用身份隔离损失、错误分类损失和错误排序损失的联合学习可以生成最佳扰动。
[0039]
在第二阶段,这些扰动将添加到数据库中目标人物的图像中,形成目标人物的对抗图像,在保护阶段,数据库中目标人物的对抗图像将保护目标人物不被恶意查询检索出。
[0040]
其中,如图1所示,给定一张干净的图像xi,生成器旨在学习扰动pi以生成相应的对抗图像xi′
,其中,enc和dec分别用于图像的降维和重建。然后将对抗图像xi′
和干净图像xi输入固定目标模型t,分别获得对抗特征和干净特征。
[0041]
其中,固定目标模型是指保持目标模型不被更新,目标模型则是实现reid检索系统的算法模型,例如现有的alignedreid、fastreid等。
[0042]
(一)身份孤立机制:
[0043]
本发明提出了一种身份隔离机制,它明确地限制了对抗图像和所有干净图像之间的整体关系。图2说明了本发明提出的身份隔离机制。具体来说,可以看出,以前的方法(即直接将dmr和ssae应用到主动保护行人重识别中)只关注将对抗性图像推离其原始标签。然而,这通常会使对抗性图像移动到其他身份附近。然后,如果攻击者使用其他身份发起查询,仍然可以检索到目标人物的图像。确切地说,目标人物的对抗性图像只有在隐藏在“最佳”位置时才能防御密集攻击。本发明的理解的“最佳”意思是对抗图像远离任何身份,使他成为一个孤立的人,这可以被认为是一种强有力的保护。
[0044]
为此,给定对抗性图像x
′i,本发明限制x
′i和所有其他图像的总距离最大化。具体来说,通过对相同身份的干净图像进行简单的平均操作,可以获得每个身份质心的特征其中c是所有训练图像的总身份数量。身份隔离损失因此可以表述为公式(1):
[0045][0046]
其中b表示批量(即batch,每一轮训练参与的训练图片的数量)大小,f(x
′i)表示对抗样本输出的特征。身份隔离损失明确地将目标人物的对抗性图像限制在一个孤立的位置,从而使其与任何其他身份之间的总体距离最大化。因此,可以有效地减少目标人物被恶意用户检索到的机会。
[0047]
(二)错误分类与错误排序:
[0048]
受dmr的启发,本发明还引入了错误排序损失以同时最小化对抗图像的负对的距离并最大化对抗图像的正对的距离。形式上,它可以定义为公式(2):
[0049][0050]
其中m是平衡边际,x
′j和x
′k分别表示图像x
′i的正例和负例,f(x
′j)表示正例样本输出的特征,f(x
′k)表示负例样本输出的特征。
[0051]
同样,本发明进一步引入了错误分类损失,以使对抗性图像远离其正确预测结果。形式上,错误分类损失可以定义为公式(3):
[0052][0053]
其中yi是x
′i的ground truth(真实标签),yi是属于真实标签的概率的预测值,由全连接分类器输出。
[0054]
(三)顺序攻击与随机攻击:
[0055]
为了模拟真实场景中的关键攻击,本发明提出了两种攻击方式,即顺序攻击和随机攻击。请注意,以前的方法提出了一种类似的顺序防御方法来提高排序系统的鲁棒性。与它们不同的是,本发明在保护机制中定义了两种攻击方式,以便更好地量化保护能力。直观地说,本发明假设恶意用户可以访问测试数据(查询图像),可以构建攻击集合其中qi表示不同的查询图像,m表示不同的目标人物。
[0056]
给定一个身份为i
p
的目标人物,攻击者随机选择一张图像q(属于i
p
)作为第一个恶意查询。一方面,当攻击预算(攻击总数)n
ta
有限时,攻击者可能会以“相似到不同”的顺序入
侵行人重识别模型,称为顺序攻击oa。为此,攻击者可以计算图像和中的所有其他图像的余弦相似度,并按降序重新排列它们,得到的排列结果为(从相似到不同)。然后,他可以通过有序地查询中最靠前的n
ta
张图像来发起攻击。这很直观,攻击者总是会尝试最相似的查询(这可能会检索到目标人物),尤其是当他的查询预算有限时。
[0057]
另一方面,当攻击预算充足时,他可能通过随机查询中的n
ta
张图像来发起攻击,称为随机攻击ra。如果目标人物的图像不可用,攻击者将随机查询(如遍历或枚举所有身份)是合理的。显然,如果攻击者可以密集地访问行人重识别模型,随机攻击ra会增加攻击成功的机会。简而言之,oa和ra都可以对行人重识别模型进行猛烈攻击,这彻底评估了本发明方法的保护能力。
[0058]
与此同时,本发明提出了一种新的评估指标,称为成功保护率(spr),以进一步描述和量化保护能力。具体来说,给定一个目标人物p,spr度量可以表述为公式(4):
[0059][0060]
其中m
p
是中目标人物图像的总数;检索结果返回的所有图像会与查询图像形成相似到不相似的一个排序列表,r
p
是目标人物图像在该排序列表中第一次出现的位置;n
gallery
是数据库中图像的数量。此外,本发明还将提议的oa和ra的spr定义为公式(5):
[0061][0062]
其中,sprr表示ra的spr,spro表示oa的spr,n
ta
是总攻击次数(攻击预算)。对于顺序攻击,表示前n
ta
个图像而对于随机攻击,表示随机选择的n
ta
个图像与平均精度(map)相比,spr显然更适合评估保护能力,它首先量化目标人物的排名被暴露。直觉上,攻击的主要目标是尽快暴露目标人物,而本发明的目标则是提高spr。
[0063]
二、本发明的关键点:
[0064]
1.本发明提出了主动保护行人重新识别(pride)方法,它可以保护目标人物不被恶意查询检索到。据本发明所知,这是第一次尝试使用对抗性示例深入研究行人重识别的身份保护,这项工作扩展了身份保护的范围,并有望在行人重识别领域中激发更多的想法。
[0065]
2.本发明发现,由于“重叠身份”问题,将对抗数据简单地引入数据库是次优的。为了解决这个问题,本发明提出了一种身份隔离机制,将对抗性图像限制在一个孤立的位置,以防御非法查询。
[0066]
3.为了评估和量化保护能力,本发明引入了一种新的成功保护率指标和两种关键攻击(随机攻击和顺序攻击)。跨不同模型、数据集和攻击场景进行的实验表明了优越性和可转移性。
[0067]
三、本发明的效果
[0068]
数据集:本发明在两个基础数据集market1501和cuhk03上进行了实验。market1501包含来自6个摄像头的1,501个人和32,668张图像,其中用于训练的751个身份
的12,936张图像和用于测试的750个身份的19,732张图像。cuhk03包含来自5对相机的1,467个身份和28,192张图像,其中767个身份的7,365个图像用于训练,700个身份的1,400个图像用于测试。
[0069]
目标模型:本发明选择alignedreid和fastreid作为目标模型。alignedreid是一种基于部件的行人重识别方法,它通过考虑部件对齐来学习局部和全局相似性。它在文献中被广泛用于评估先前行人重识别攻击方法的性能。fastreid是一个pytorch工具箱,用于真实世界的行人重识别。它提供了强大的baseline,能够在实际应用中的多个任务上实现最先进的性能。
[0070]
评价指标:本发明采用提出的成功保护率(spr)作为评估指标,sprr和spro分别评估面临随机攻击和顺序攻击下的保护能力,其数值越大越好;同时本发明采用ssim的大小来表示图像质量的高低,其数值同样越大越好。
[0071]
实验结果:为了全面验证本发明的方法,比较了三个类别的sota baseline,即保护前、两种行人重识别攻击方法(dmr和ssae)和两种用于图像检索的目标图像检索保护方法(cwdm和ppl)。
[0072]
(1)作为下界,本发明在表1中包括了保护前结果,其中恶意用户直接攻击(查询)目标模型,而没有保留目标人物的身份。(2)攻击方法dmr和ssae在行人重识别任务中取得了很好的攻击性能,也可以用于目标人物的身份保护。因此,本发明从头开始训练这两种方法,并在目标人物图像中添加学习到的扰动作为保护。(3)cwdm和ppl是深度哈希检索中保护目标图像(私有数据)的两项开创性工作。本发明还根据原论文中的设置重新实现了cwdm和ppl。
[0073]
如表1所示,可以得出以下结论:(1)作为下界,保护之前的性能最差,表明行人重识别系统中存在身份泄漏。(2)行人重识别攻击方法dmr和ssae不如本发明的方法,经验表明,将对抗性数据简单地引入数据库是抢占式保护行人重识别的次优解决方案。(3)本发明的方法始终优于cwdm和ppl,验证了身份隔离机制的有效性。(4)与关注最小化扰动的ssae相比,本发明仍然可以生成具有相对较高ssim结果的最优对抗样本。
[0074]
迁移性分析:为了验证本发明的方法在跨数据集、跨模型上的迁移性,本发明做了以下实验分析。
[0075]
(1)跨数据集的可迁移性:如表2所示,与无迁移设置相比,迁移设置有明显的性能下降,由于数据集的多样性,这是可以接受的。与保护前相比,迁移设置仍然可以实现良好的身份保护性能,即使不访问原始数据也可以进行对抗训练。
[0076]
(2)跨目标模型的可迁移性:如表3所示,迁移设置不如无迁移设置,这表明对抗性扰动与训练模型高度相关。此外,传输设置比保护前设置实现了更好的性能。这揭示了真实场景,如果目标模型是黑盒,用户可以使用代理模型训练对抗数据。
[0077]
(3)跨数据集和模型的可迁移性:如表4所示,跨数据集和模型进行迁移是一项相当具有挑战性的任务。与保护前相比,本发明的方法并没有非常注重提高迁移性能。
[0078]
两种重要攻击的影响:为了验证随机攻击ra和顺序攻击oa之间的差异,本发明在图3中显示了spr结果的性能比较。可以找到几个观察结果。
[0079]
(1)显然,与ssae相比,本发明的方法始终获得更高的spr结果,表明pride在目标人物身份保护方面的功效。
[0080]
(2)当攻击预算有限时(n
ta
=10),oa的spr低于ra,说明oa比ra攻击力更强。这与本发明的分析一致,即如果预算有限,攻击可能会发起顺序攻击。
[0081]
(3)当market1501中的攻击预算充足(n
ta
=3368)和cuhk03中的(n
ta
=1400)时,ra的spr结果等于oa的spr结果。这恰好证明了攻击场景ra和oa的差异。
[0082]
消融实验:本发明进行消融研究以评估和的贡献。表5中的spr结果表明,所有三种变体均不如完整方法,验证了所提出组件的有效性。此外,与其他两个变体相比,的性能最差,进一步表明是最重要的组件。同样,如表6所示,ra和oa下的spr结果也证明了所有三个组件在保护行人重识别中目标人物员身份方面的功效。
[0083]
可视化分析:为了直观地展示本发明方法的有效性,本发明在图4中说明了一些定性结果。具体来说,给定一个干净但恶意的查询,本发明展示了第一个返回图像的排名如何随着不同的方法变化,即alignedreid和fastreid,在market1501数据集上。作为比较,本发明还包括了保护前的结果(即图4中的before),以显示恶意用户在没有保护的情况下直接查询目标人物时第一个返回图像的排名。图4显示:(1)总的来说,本发明的方法(即图4中的ours)在两个主干网络上始终优于其他baseline,表明本发明在身份保护方面的功效。(2)与保护前相比,所有基线都表现出显着的保护性能,这清楚地验证了行人重识别中身份泄漏的存在。(3)对于dmr和ssae(都是行人重识别攻击方式),防护性能相对较差。这是合理的,因为抢先保护行人重识别中存在重叠身份问题。(4)cwdm和ppl是针对深度哈希检索的两种保护方法。与它们相比,它表明深度散列机制中的私有图像保护不适用于行人重识别。(5)与其他baseline相比,本发明的图像质量具有竞争力。在视觉损失很小的情况下,本发明的方法排名最高,表明目标人物的曝光最少。
[0084]
本发明的另一实施例提供一种用于行人重识别的基于样本孤立机制的身份隐私保护系统,其包括:
[0085]
训练模块,用于给定干净图像,通过生成器学习扰动以生成相应的对抗图像;将对抗图像和干净图像输入目标模型中,分别获得对抗特征和干净特征;利用对抗特征和干净特征,采用身份隔离损失、错误分类损失和错误排序损失对生成器进行训练,以生成最佳扰动;
[0086]
保护模块,用于将生成的最佳扰动添加到目标人物的图像中,得到目标人物的对抗图像,通过对抗图像保护目标人物以防御恶意查询。
[0087]
其中各模块的具体实施过程参见前文对本发明方法的描述。
[0088]
本发明的另一实施例提供一种计算机设备(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0089]
本发明的另一实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
[0090]
表1不同方法在不同模型上的保护效果
[0091][0092]
表2跨数据集迁移性比较
[0093][0094]
表3跨模型迁移性比较
[0095][0096]
表4跨数据集跨模型迁移性比较
[0097][0098]
表5对不同损失项的spr结果的消融研究
[0099][0100]
表6 sprr和spro的消融研究在不同的损失条件下效果
[0101][0102]
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1