一种基于目标检测和知识增强的图像描述生成方法
1.本发明涉及图像处理技术领域,具体涉及一种基于目标检测和知识增强的图像描述生成方法。
背景技术:
2.自然图像生成描述是一项具有挑战性的研究。该任务对于人类来说非常容易,但是对于机器却非常具有挑战性,它不仅需要利用模型去理解图片的内容并且还需要用自然语言去表达它们之间的关系。图像描述解决了在给定图像后自动得到相应的描述性文本的难题,是结合计算机视觉、自然语言处理和机器学习的一个交叉领域,也是一个极具挑战性的人工智能研究问题。由于人类的大部分交流都依赖于自然语言,无论是书面还是口语,因此使计算机能够描述视觉世界将提供大量的应用。例如,对互联网中图像信息检索,儿童的早期教育与视障人士的生活辅助等方面有重要的意义。
3.近年来,人们对描述视觉场景的兴趣日益浓厚,过去的image captioning基本是直来直去的,给一副图像,提取图像特征,送进翻译模型,生成一个caption,至于生成的这个caption是关注图像当中哪个物体,是什么风格的caption,是由训练数据的样式来决定的,无法自由的控制。我们希望我们能够控制生成的caption,比如被描述的重点物体与区域,比如我们可以决定生成的caption是描述图像背景还是描述前景中某个物体的,也可以决定其描述的详细程度。
4.传统的文本生成任务只依靠输入图像进行生成,缺乏更加丰富的“知识”信息,因此生成的文本往往非常乏味,缺少有意思的内容。在文本生成任务中,“知识”是对输入文本和上下文的一种“补充”,可以由不同方法和信息源获得,包括但不限于关键词,主题,语言学特征,知识库,知识图谱等。
5.当下流行的引入知识图谱进行图像描述生成的方法,只能简单的通过目标检测工具得到出一些物体的粗类别标签,同时检测的类别有限。在生成的图像描述方面,语句缺乏连贯性,描述不能完全概括图像表达的含义。比如引入知识图谱的图像描述生成模型cnet-nic,是将知识图谱实体的embedding融入模型,未学习到细粒度实体间的关系,只对图像中的粗粒度类别标签进行描述。cnet-nic没有生成聚焦于图像显著区域的细粒度描述,且生成的描述语言缺乏连贯性。
技术实现要素:
6.针对现有技术中的不足,本发明提供了一种基于目标检测和知识增强的图像描述生成方法,以解决现有技术中图像标题描述语言可读性低、只拥有粗粒度表层信息、缺乏细粒度实体间关系的问题。
7.本发明提供了一种基于目标检测和知识增强的图像描述生成方法,包括如下步骤:
8.步骤1:获取已有描述标注的图像描述数据集,对数据集中标题文本中的每个词进
行识别,获取固定长度的词向量并组成相对应的词汇表;通过抽取图像感兴趣区域特征向量,识别图像实体区域框及图像实体类别,来获取固定长度的类别特征词向量;对图像进行识别,获取固定长度的图像实体特征向量;检测图像,获得图像中所含的目标区域框和目标标签;
9.步骤2:将目标标签、目标区域框作为分类检测方法的输入,分类检测方法先根据目标标签,使用人脸识别方法及通用商品识别方法将目标标签与目标区域框进行匹配,获得区域内的目标特征标签集;分类检测方法再在匹配完成的基础上根据目标区域框,使用人脸识别方法及通用商品识别方法获得目标具体的信息,即人脸特征标签,物体特征标签;
10.步骤3:将目标标签、人脸特征标签、物体特征标签,通过知识图谱术语检索方法,获得图像中目标的背景信息标签集;
11.步骤4:将目标特征标签集和背景信息标签集分别作为深度学习rnn网络的输入,获取目标特征向量、背景信息特征向量;
12.或将目标特征标签集和背景信息标签集分别作为深度学习rnn网络的输入,得到深度学习rnn网络中产生图像特征,根据图像实体特征向量、背景信息特征向量、深度学习rnn网络中产生图像特征,得到图像的融合特征向量;
13.步骤5:将目标特征向量、背景信息特征向量作为长短期记忆网络的输入量,类别特征词向量作为长短期记忆网络的输出量,实现长短期记忆网络的训练;
14.或将融合特征向量作为长短期记忆网络的输入量类别特征词向量作为长短期记忆网络的输出量,实现长短期记忆网络的训练;
15.步骤6:用训练好的长短期记忆网络生成图像描述内容。
16.进一步地,所述步骤4中得到图像的融合特征向量的具体方法为,依次将目标特征向量、背景信息特征向量、深度学习rnn网络中产生图像特征进行向量拼接,得到图像的融合特征向量。
17.进一步地,深度学习rnn网络中产生图像特征为:
18.r=f-rcnn(i)
19.其中,r是图像实体特征向量,f-rcnn()为faster-rcnn工具函数,i是训练集中的图像。
20.进一步地,图像的融合特征向量为:
21.v=concatenate(i,d,r)
22.其中,v为图像的融合特征向量,i为图像实体特征向量,d为背景信息特征向量。
23.进一步地,图像实体特征向量为:
24.i=rnn(r0)
25.背景信息特征向量为:
26.d=rnn(e0)
27.其中,r0为目标特征的标签集,e0为背景信息标签集。
28.本发明的有益效果:
29.1.本发明使用全局图像特征、图像中的目标知识特征和描述的文本特征来生成图像描述,并采用基于目标检测和知识增强的方法来增强模型在生成文本时语言的丰富性和多样性。相较于未融入知识图谱的模型,本文所述方法生成的描述更加符合日常表达的形
式,含有图像中事物的背景信息,语义信息更加丰富;在侧重语义的评价指标spice、meteor上分别提升了1%、0.6%;
30.2.本发明将目标检测阶段的区域框和类别标签联合起来,利用先进的人脸识别、商品识别等工具做更深层次的信息发掘;采用resnet的模型来提取图像中的全局特征,并编码为特征向量,而对于文本则采用长短期记忆网络来提取文本中的特征;在解码阶段引入lbpf注意力机制,增强了词与词之间的联系,从而生成连贯的、富含细粒度背景知识的描述。
附图说明
31.通过参考附图会更加清楚的理解本发明的特征和优点,附图是示意性的而不应理解为对本发明进行任何限制,在附图中:
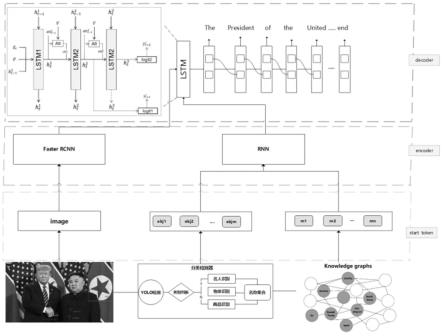
32.图1为本发明实施例中图像描述生成方法的总体框架图;
33.图2为本发明实施例中未融入知识图谱的模型生成效果示例图;
34.图3为本发明实施例中融入知识图谱的模型生成效果示例图。
具体实施方式
35.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
36.下面结合具体实施例,进一步阐明本发明。本领域的技术人员应该了解这些实施例仅用于说明本发明而不用于限制本发明的范围,对本发明的各种等价形式的修改均落于本技术所附权利要求书所限定的范围。
37.本发明提供了步骤1:获取已有描述标注的图像描述数据集,对数据集中标题文本中的每个词进行识别,获取固定长度的词向量并组成相对应的词汇表;通过抽取图像感兴趣区域特征向量,识别图像实体区域框及图像实体类别,来获取固定长度的类别特征词向量;对图像进行识别,获取固定长度的图像实体特征向量;检测图像,获得图像中所含的目标区域框和目标标签;
38.步骤2:将目标标签、目标区域框作为分类检测方法的输入,分类检测方法先根据目标标签,使用人脸识别方法及通用商品识别方法将目标标签与目标区域框进行匹配,获得区域内的目标特征标签集;分类检测方法再在匹配完成的基础上根据目标区域框,使用人脸识别方法及通用商品识别方法获得目标具体的信息,即人脸特征标签,物体特征标签;
39.步骤3:将目标标签、人脸特征标签、物体特征标签,通过知识图谱术语检索方法,获得图像中目标的背景信息标签集;
40.步骤4:将目标特征标签集和背景信息标签集分别作为深度学习rnn网络的输入,获取目标特征向量、背景信息特征向量;
41.或将目标特征标签集和背景信息标签集分别作为深度学习rnn网络的输入,得到深度学习rnn网络中产生图像特征,依次将图像实体特征向量、背景信息特征向量、深度学习rnn网络中产生图像特征进行向量拼接,得到图像的融合特征向量;
42.其中,深度学习rnn网络中产生图像特征为:
43.r=f-rcnn(i)
44.式中,r是图像实体特征向量,f-rcnn()为faster-rcnn工具函数,i是训练集中的图像;
45.图像的融合特征向量为:
46.v=concatenate(i,d,r)
47.式中,v为图像的融合特征向量,i为图像实体特征向量,d为背景信息特征向量,
48.i=rnn(r0)
49.d=rnn(e0)
50.式中,r0为目标特征的标签集,e0为背景信息标签集;
51.步骤5:将目标特征向量、背景信息特征向量作为长短期记忆网络的输入量,类别特征词向量作为长短期记忆网络的输出量,实现长短期记忆网络的训练;
52.或将融合特征向量作为长短期记忆网络的输入量类别特征词向量作为长短期记忆网络的输出量,实现长短期记忆网络的训练;
53.步骤6:用训练好的长短期记忆网络生成图像描述内容。
54.以下对本发明实施例做进一步地的描述:。
55.步骤1:找到开源的并且标注好描述的图像描述数据集,将数据集切分为训练集、验证集和测试集,所述图像描述数据集为mscoco2014数据集,所述数据集切分为训练集图片113,287张,验证集图片5000张,测试集图片5000张。
56.步骤11:获取每个图像对应的描述文本,对图像的描述中的每个词进行识别,获取固定长度的词向量并组成相应的词汇表,具体为:
57.步骤12:将图像描述的文本数据集中的所有描述文本转换为以单词为单位的词汇表;
58.步骤13:对句子描述中的每个词进行识别,得到的词向量每一维代表了词语特征,维度为1024;
59.步骤14:对图像,使用faster-rcnn工具抽取图像感兴趣区域特征向量并识别图像实体区域框以及图像实体类别,得到的图像感兴趣区域特征向量,每一维都代表了图像特征,维度为2048;
60.步骤15:对步骤14中的图像实体类别,对实体类别名称进行识别,获取固定长度的类别特征词向量;
61.步骤16:对步骤14中的图像实体区域框,使用resnet工具对实体区域中的图片进行识别,获取固定长度的图像实体特征向量;
62.进一步地,所述步骤14-16抽取图像感兴趣区域特征向量步骤如下,由预训练faster-rcnn产生图像i的图像特征r,输入图片i,每张图片使用resnet-101提取的feature map和faster r-cnn提取的区域r,
63.r=f-rcnn(i)
64.步骤17:通过yolo目标检测工具检测出图像中的目标,获得图像中所含的目标的区域框和目标标签;
65.其中,获得目标标签步骤如下:对于数据集中图像i,使用yolo目标检测器来识别
图像中的对象即o=yolo(i);
66.步骤2:将步骤17得到的目标标签送入分类检测器,分类检测器根据对象标签的信息,选择使用人脸识别模块或通用商品识别模块,识别步骤17得到的区域框;
67.步骤21,如果目标检测的结果是person,就将这部分区域图送入人脸和名人检测工具识别出具体人的信息;若目标检测的结果是物体,进一步送入京东云通用商品检测,识别出商品名;若无商品名称,则使用目标检测的物体名称。
68.步骤3:根据步骤21的目标区域框,使用人脸识别模块和通用商品识别模块获得对象具体的信息,即人脸特征标签,物体特征标签;所属步骤3获得人脸特征标签,物体特征标签步骤如下:
69.步骤31,通过o=yolo(i)得到图像中的对象名称,对对象集合判断是否是person,如果是person,送入人脸、名人检测模块得到人物及人脸信息标签;如果是物体,送入商品识别模块;如果通过名人识别和商品识别模块均没有输出,即输出原先的对象名,即最后得到分类检测器的输出名称集;
70.步骤4:将步骤17,3所得的特征标签列表,送入conceptnet知识图谱相关术语检索模块,获得图像中对象的背景信息标签集;
71.其中,获得图像中对象的背景信息标签集步骤如下:
72.步骤41,通过查询相关术语api查询conceptnet常识知识图谱中的相关实体术语,获得与m相关的术语集合e0=conceptnet(m)和图中对象整个集合m相关的术语集合r0=conceptnet(m);
73.步骤5:通过深度学习rnn预训练步骤4得到的背景信息标签集,映射成相应的向量空间嵌入,获取背景信息特征向量;
74.其中,获取背景信息特征向量步骤如下:
75.步骤51,通过预训练rnn产生e0和r0的向量空间嵌入,
76.i=rnn(r0)
77.d=rnn(e0)
78.步骤6:创建look back and predict forward method长短期记忆网络的解码器模块,在编码器模块的卷积神经网络输入端和解码器模块的循环神经网络输入端之间添加一层全连接层;
79.步骤61,创建的look back and predict forward method长短期记忆网络lstm的方法包括:给定k维空间的图像特征向量和当前隐藏状态预测y
t+1
和y
t+2
,记attention function为f
att
,lstm2为f2,则
[0080][0081][0082][0083]
预测下一个词,于是,继续通过att
t
和lstm2得到
[0084][0085]
[0086][0087]
通过以上公式,最后利用两者的和来计算最终预测的词:
[0088][0089]
步骤8:将所述步骤2中所获得的图像描述文本的词向量、所述步骤5中所提取的图像特征和所述步骤5中所获得的背景信息特征向量输入到长短期记忆网络中,将图像特征和所对应的图像描述文本在长短期记忆网络中进行训练;
[0090]
其中,将图像特征和所对应的图像描述文本在长短期记忆网络中进行训练步骤如下:
[0091]
步骤81,将步骤5得到的背景信息特征与步骤16得到的faster r-cnn获得的图像特征进行拼接:
[0092]
input:v=concatenate(i,d,r)
[0093]
通过步骤81得到的拼接特征,将其作为描述生成模型的输入。其中描述生成模型使用look back and predict forward method长短期记忆网络lstm。
[0094]
soft vector:w=softmax(lstm(v))
[0095]
步骤82:在长短期记忆网络的解码器模块中,从预设起始标志开始对每个语句进行预测生成单词,从预设起标志开始对每个语句进行预测生成单词;
[0096]
步骤83:利用beam search算法,我们使用线形层将解码器的输出转换为词汇表中每个单词的得分,在最佳候选单词集中选择最大概率分布的单词构成句子,得到最优的标题序列。
[0097]
以下以具体的实例作说明:
[0098]
本实例对比了图像标题生成模型与基于目标检测和知识增强的图像描述模型ftcd+kg,实例图片从mscoco2014数据集的测试集中随机抽取图片,如图2所示,没有使用目标检测和知识图谱的描述为“a woman is holding a frisbee in a room”,较为准确地描述了图片中的内容,包括人物、动作场景等信息;如图3所示,使用基于目标检测和融入知识图谱的描述为“a young girl with long hair was holding a hunt mice cat with a bicycle behind her”;相比较于未融入知识图谱的模型,该句的描述更加符合日常表达的形式,含有图像中更多的事物信息,语义信息更加丰富。为了比较这两种模型的性能,则本实例用了bleu、meteor、cider、spice自动评价指标来进行对比,如表1所示为评价结果对比:
[0099][0100]
表1
[0101]
通过实验可以得出如下结论:本发明对融入知识图谱的图像描述具有较好的效果,bleu、meteor等指标均有提升,适用范围广,可以很好弥补引入知识图谱的图像描述以往方法的缺陷。
[0102]
虽然结合附图描述了本发明的实施例,但是本领域技术人员可以在不脱离本发明的精神和范围的情况下作出各种修改和变型,这样的修改和变型均落入由所附权利要求所限定的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1