一种基于多平面图像型参数编码的虚拟视点合成方法
1.本发明涉及视点合成技术领域,尤其涉及一种基于多平面图像型参数编码的虚拟视点合成方法。
背景技术:
2.视点合成问题首先使用不同视角的一个或多个相机拍摄同一个场景,然后利用获得的一个或者多个视角的图像合成新的虚拟视角的图像。视点合成在计算机视觉领域是一个经典的问题,多年来一直被各国研究人员关注。对于它的研究也推动了许多以它为基础的研究和应用的发展,比如虚拟漫游,汽车导航和远程手术等。随着深度学习技术的发展,神经渲染方法在视点合成问题中展示了其优势并越来越受到关注。mildenhall b,srinivasan p p,tancik m等.nerf:representing scenes as neural radiance fields for view synthesis[j].lecture notes in computer science(including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics),2020:405
–
421.doi:10.1007/978-3-030-58452-8_24.中提出一种热门的神经渲染方法,它首先沿光线采样点,并得到点的坐标和观察方向。之后使用频率编码方法编码点的坐标和观察方向并将编码后的结果输入多层感知器(muti-layer perception,mlp)来预测点的颜色和体积密度。最后使用体积渲染方法将预测的颜色和体积密度合成目标图像。虽然nerf取得了优秀的合成新视图的质量,但是它的训练时间需要一到两天。wizadwongsa s,phongthawee p,yenphraphai j等.nex:real-time view synthesis with neural basis expansion[j/ol].proceedings of the ieee computer society conference on computer vision and pattern recognition,2021:8530
–
8539.http://arxiv.org/abs/2103.05606.doi:10.1109/cvpr46437.2021.00843.中使用多平面图像(multi-plane image,mpi)来建模三维场景。mpi由一组位于参考摄像机坐标系前的固定深度处的半透明平行平面组成,其中每个平面存储点的rgb值和透明度值,以描述相应深度处的场景外观。nex没有使用原始mpi在平面上存储静态rgb值的方法,而是使用每个点与视点有关的基函数和其rgb系数的线性组合来建模与视点有关的光照效果。它同样首先将点的坐标和观察方向进行频率编码。之后将点坐标的编码结果输入一个mlp来预测点的透明度值和rgb系数并且将点的观察方向的频率编码结果输入另一个mlp来预测视点有关的基函数。虽然nex可以获得优秀的合成结果,但是其在单个场景上的训练时间仍然高达十多个小时。
[0003]
造成训练时间过长的一部分原因是两者使用的频率编码方式给网络学习提供的场景信息不够全面。为了解决上述问题,本发明提出了一种基于多平面图像型参数编码的虚拟视点合成方法。
[0004]
本发明采用mpi型参数编码和频率编码的混合编码方式。加入的mpi型参数编码为网络增加了额外的可学习的编码参数,即增加了更为全面的场景信息。因此,本发明可以在几小时内完成整个训练过程并依旧获得相似的优秀合成结果。
技术实现要素:
[0005]
本发明的目的在于解决现有的虚拟视点合成方法无法将更全面的信息提供给网络且所需训练时间过长的问题而提出了一种基于多平面图像型参数编码的虚拟视点合成方法,采用mpi型参数编码方法为网络增加了额外的可学习的编码参数,显著减少了网络的训练时间,提升了网络的时间效率。
[0006]
为了实现上述目的,本发明采用了如下技术方案:
[0007]
一种基于多平面图像型参数编码的虚拟视点合成方法,采用mpi型参数编码方法为网络增加了额外的可学习的编码参数,减少网络的训练时间,提升网络的时间效率,具体包括以下内容:
[0008]
s1、基于多层感知器构建颜色预测网络和视点效果预测网络;
[0009]
s2、利用颜色预测网络预测点的透明度值和rgb参数:
[0010]
s3、利用视点效果预测网络预测点的与视点相关的基函数;
[0011]
s4、基于s2中预测得到的点的透明度值和rgb参数以及s3中预测得到的基函数,将其经过合并操作得到最终合成结果图像。
[0012]
优选地,所述颜色预测网络记作gc,其输入由参数编码p(
·
)的特征和频率编码f(
·
)的值组成;所述颜色预测网络使用mpi建模场景;假设参考图像的宽为w,高为h,则mpi的宽为wm=w+2o,高为hm=h+2o,层数为lm;其中,o表示额外增加的长度。
[0013]
优选地,所述参数编码p(
·
)使用与mpi形状相同的结构m
p
来存储可学习的编码参数,即m
p
的每一层不像mlp一样存储rgb值和透明度值,而是存储维度为d的可学习的编码参数。使用与mpi形状相同的结构m
p
存储可学习的编码参数,相当于为场景建模中每个点都设置了一个可学习的参数,从而能够进一步学习场景的信息。mpi型参数编码p(
·
)以点坐标(x,y,z)为索引,通过插值的方法得到与点对应的存储在m
p
中的可学习编码参数特征f
p
:
[0014]fp
=p((x,y,z),m
p
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0015]
优选地,所述频率编码f(
·
)使用不同频率的正弦和余弦函数编码点坐标(x,y,z):
[0016][0017][0018][0019]
其中,n
x
,ny和nz用于产生不同的频率。
[0020]
优选地,将参数编码得到的可学习编码参数特征f
p
和频率编码得到的值f(x,y,z)一同输入颜色预测网络gc来预测点的透明度值α和rgb系数km:
[0021]
gc:f
p
+f(x,y,z)
→
(α,k1,k2,...,k
m-1
,km)
ꢀꢀꢀꢀꢀꢀ
(3)
[0022]
其中,“+”表示连接的意思。
[0023]
优选地,所述视点效果预测网络记作gv,其输入为点的观察方向(v
x
,vy)经过频率编码f(
·
)之后的值;其输出为点的与视点相关的基函数hm,进而模拟与视角相关的光照效果:
[0024]gv
:f(v
x
,vy)
→
(h1,h2,...,h
m-1
,hm)
ꢀꢀꢀꢀꢀꢀꢀ
(4)
[0025]
与现有技术相比,本发明提供了一种基于多平面图像型参数编码的虚拟视点合成方法,具备以下有益效果:
[0026]
本发明提出的一种基于多平面图像型参数编码的虚拟视点合成方法,显著减少了训练网络所需要的时间,改善了现有虚拟视点合成方法训练时间过长的缺点,并且能够获得与其相当的合成结果;在需要对一个场景进行虚拟视点合成时,本发明可以在几个小时之内训练完成,而不需要等待十几个小时甚至一两天,有效增强了网络的时间效率。
附图说明
[0027]
图1为本发明提出的一种基于多平面图像型参数编码的虚拟视点合成方法的网络结构图;
[0028]
图2为本发明实施例1中网络训练时间的比较结果示意图;
[0029]
图3为本发明实施例1中网络的定性与定量实验结果示意图。
具体实施方式
[0030]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0031]
实施例1:
[0032]
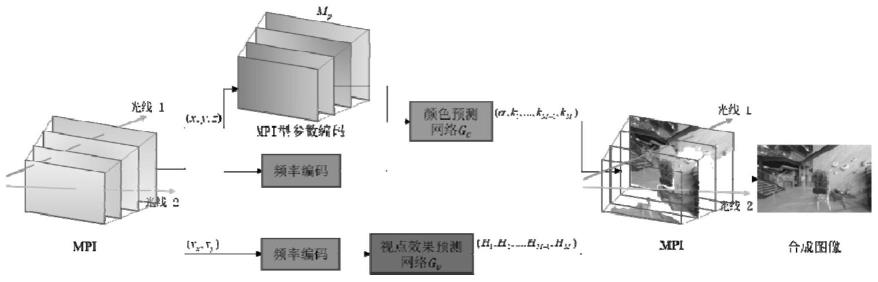
请参阅图1-3,本发明的目的是利用输入的多个视角的图像,网络能够得到新的虚拟视角的图像。本发明基于mpi型参数编码的虚拟视点合成方法如图1所示。其由两个子网络组成,分别是颜色预测网络gc和视点效果预测网络gv。下面结合图1对本发明进行详细说明。
[0033]
首先,本发明沿着每条光线采样lm个空间中的点,并且获得点的坐标(x,y,z)和观察方向(v
x
,vy)。点的坐标(x,y,z)需要进行mpi型参数编码p(
·
)和频率编码f(
·
),得到的结果是颜色预测网络gc的输入。网络使用mpi建模场景。假设参考图像的宽为w,高为h,则mpi的宽为wm=w+2o,高为hm=h+2o,层数为lm;其中,o表示额外增加的长度。mpi型参数编码p(
·
)则使用与mpi形状相同的结构m
p
来存储可学习的编码参数,即m
p
的每一层不像mlp一样存储rgb值和透明度值,而是存储维度为d的可学习的编码参数。使用与mpi形状相同的结构m
p
存储可学习的编码参数,相当于为场景建模中每个点都设置了一个可学习的参数,从而能够进一步学习场景的信息。mpi型参数编码p(
·
)使用点坐标(x,y,z)索引网格中存储的可学习编码参数的位置,然后用插值方法得到可学习编码参数特征f
p
,如公式1所示。本发明通过增加额外的可学习编码参数特征,为网络提供了更多可以学习的信息,从而能够有效减少网络的学习时间。频率编码f(
·
)使用不同频率的正弦和余弦函数编码点坐标(x,y,z),如公式2所示。之后,本发明将参数编码得到的特征f
p
和频率编码得到的值f(x,y,z)连接起来,输入颜色预测网络gc。颜色预测网络gc由6个完全连接的层组成。其输出为点的透明度值α和rgb系数km,如公式3所示。
[0034]
本发明同样使用频率编码f(
·
)编码点的观察方向(v
x
,vy),之后将编码后的值输入视点效果预测网络gv。视点效果预测网络gv由3个完全连接的层组成。其输出是点的与视点相关的基函数hm,如公式4所示。
[0035]
基础颜色k0不使用神经网络来学习,其是显式学习的。之后,本发明使用获得的基
础颜色k0,rgb系数km和基函数hm来计算每个点的颜色值c
p
:
[0036][0037]
令为一条光线上不同采样点的透明度。为一条光线上不同采样点的颜色。则合成结果图像上每一个像素点可以通过合成操作得到:
[0038][0039][0040]
在训练过程中,本发明使用如下重建损失l:
[0041][0042]
其中,l由l2损失,梯度差损失和总变差正则化tv(
·
)组成。是合成结果图像,i是真实图像。是梯度算子。η和是加权系数。
[0043]
在训练阶段,采用adam优化器,初始学习率为0.001,每训练1333个轮次,将学习率减少为原来的0.1倍,一共训练3800个轮次。
[0044]
图2展示了随着训练时间增加,本发明与nex在相同场景下合成图像的psnr的比较。从图中可以看出,本发明显著的减少了训练时间,并且在该场景取得了更好的合成图片质量。图3展示了本发明的合成图像与真实图像的对比。从图中可以看出本发明的合成图像与真实图像十分近似。
[0045]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1