对象推荐方法、装置、电子设备和存储介质与流程
本技术涉及数据处理领域,尤其涉及一种对象推荐方法、装置、电子设备和存储介质。
背景技术:
1、目前,双塔模型在推荐领域的召回环节中的应用越来越广泛,较为普遍的做法如下:首先,离线训练一个双塔模型,双塔模型包括用户侧模型和物品侧模型,利用训练好的物品侧模型提前将所有候选物品转换成对应的物品语义向量,并存储于数据库中以供查询;之后,对于新的用户访问,利用训练好的用户侧模型实时将其转换成对应的用户语义向量,并根据用户语义向量与物品语义向量的相似度,从所有候选物品中召回用户可能感兴趣的物品,用于后续排序和推荐。
2、然而,上述方法对新用户或冷启动阶段的适用性不强,模型训练时依赖的海量数据存在样本偏差,例如不同类别的用户在数量以及行为数据上的偏差,这容易导致最终模型主要记忆了占比较大的类别用户(记为大类别用户)的行为特征,而忽略了占比较小的类别用户(记为小类别用户)的行为特征,使得最终推荐给小类别用户的商品可能并不适用,从而影响推荐效果以及小类别用户的消费体验。
技术实现思路
1、本技术提供一种对象推荐方法、装置、电子设备和存储介质,可以提高对于小类别用户的推荐效果以及小类别用户的消费体验。
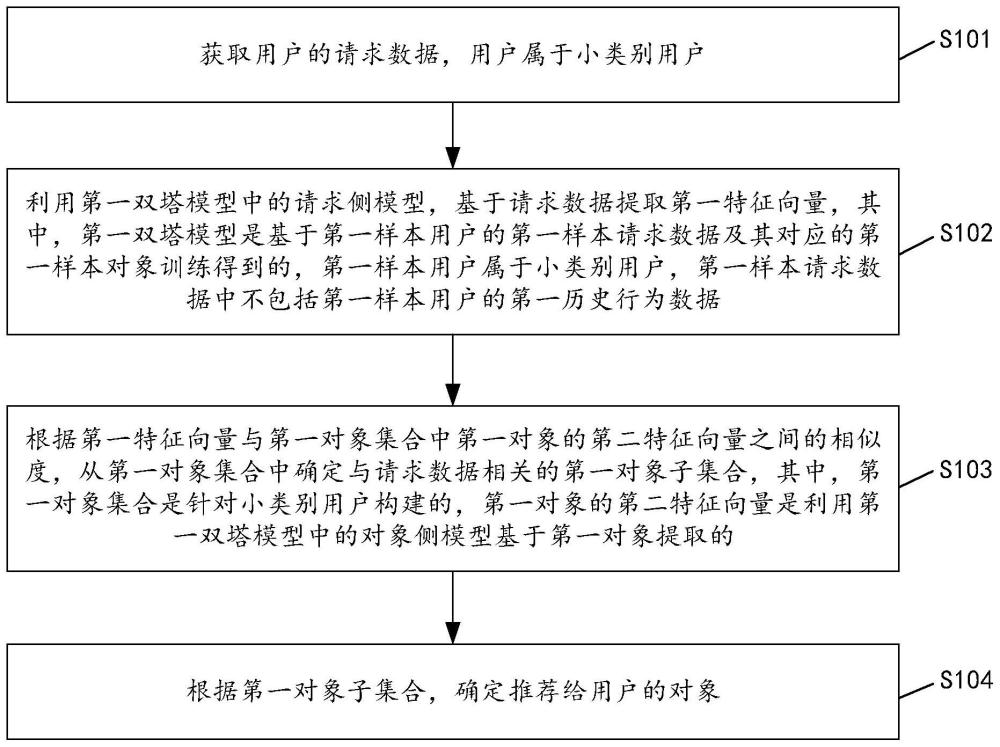
2、第一方面,本技术实施例提供了一种对象推荐方法,所述方法包括:
3、获取用户的请求数据,所述用户属于小类别用户;
4、利用第一双塔模型中的请求侧模型,基于所述请求数据提取第一特征向量,其中,所述第一双塔模型是基于第一样本用户的第一样本请求数据及其对应的第一样本对象训练得到的,所述第一样本用户属于所述小类别用户,所述第一样本请求数据中不包括所述第一样本用户的第一历史行为数据;
5、根据所述第一特征向量与第一对象集合中第一对象的第二特征向量之间的相似度,从所述第一对象集合中确定与所述请求数据相关的第一对象子集合,其中,所述第一对象集合是针对所述小类别用户构建的,所述第一对象的第二特征向量是利用所述第一双塔模型中的对象侧模型基于所述第一对象提取的;
6、根据所述第一对象子集合,确定推荐给所述用户的对象。
7、上述实施例中,利用第一双塔模型基于用户的请求数据提取第一特征向量,根据第一特征向量与第一对象集合中第一对象的第二特征向量之间的相似度,从第一对象集合中确定与请求数据相关的第一对象子集合,根据第一对象子集合确定推荐给用户的对象。其中,用户属于小类别用户,第一对象集合是针对小类别用户构建的,这使得第一对象作为推荐对象的合适概率较大,并且第一双塔模型的训练中不考虑第一样本用户的第一历史行为数据,这有利于消除行为偏差,提高模型性能。据此,可以提高对于小类别用户的推荐效果,有助于快速完成小类别用户的冷启动,减小分发和供给偏差带来的影响,提高小类别用户的消费体验。
8、在一些可能的实施方式中,所述方法还包括:
9、确定种子对象和扩充对象,根据所述种子对象和所述扩充对象构建所述第一对象集合,其中,所述种子对象包括所述小类别用户交互过的对象,所述扩充对象是基于所述种子对象挖掘的。
10、上述实施方式中,先确定种子对象再挖掘扩充对象,据此构建的第一对象集合可以兼顾准确性和全面性。
11、在一些可能的实施方式中,所述方法还包括:训练获得所述第一双塔模型,所述训练获得所述第一双塔模型包括:
12、获取第一训练数据,所述第一训练数据包括:第一样本用户的第一样本请求数据及其对应的第一样本对象;
13、利用第一待训练双塔模型中的请求侧模型,基于所述第一样本请求数据提取第一样本特征向量;
14、利用所述第一待训练双塔模型中的对象侧模型,基于所述第一样本对象提取第二样本特征向量;
15、根据所述第一样本特征向量与所述第二样本特征向量之间的相似度,调整所述第一待训练双塔模型的参数,获得所述第一双塔模型。
16、上述实施方式中,针对小类别用户训练第一双塔模型,可以更为准确的识别小类别用户的请求数据与待召回对象之间的相关性,有利于召回更适合小类别用户的对象。
17、在一些可能的实施方式中,所述第一样本请求数据对应的第一样本对象包括:第一正例对象和第一负例对象;所述第一负例对象包括:与所述第一正例对象的区分难度依次减小的第一极难负例对象、第一较难负例对象和第一简单负例对象;
18、所述根据所述第一样本特征向量与所述第二样本特征向量之间的相似度,调整所述第一待训练模型的参数,获得所述第一双塔模型,包括:
19、对于所述第一极难负例对象,使用铰链损失函数根据所述第一样本特征向量与所述第二样本特征向量之间的相似度计算第一损失值;
20、对于所述第一正例对象、所述第一较难负例对象和所述第一简单负例对象,使用交叉熵损失函数根据所述第一样本特征向量与所述第二样本特征向量之间的相似度计算第二损失值;
21、基于所述第一损失值和所述第二损失值,调整所述第一待训练双塔模型的参数,获得所述第一双塔模型。
22、上述实施方式中,在第一双塔模型的训练中,将负例对象划分为不同难度,并结合使用铰链损失函数和交叉熵损失函数,据此训练获得的第一双塔模型能够更好地识别请求数据与对象之间的相关性,并且能够更好地区分正例对象和负例对象。
23、在一些可能的实施方式中,所述第一极难负例对象、所述第一较难负例对象、所述第一简单负例对象的数量比为1:3:30。
24、上述实施方式中,在第一双塔模型的训练中,按照1:3:30的比例配置第一极难负例对象、第一较难负例对象、第一简单负例对象,有利于获得更好的模型性能。
25、在一些可能的实施方式中,所述第一正例对象包括:在响应所述第一样本请求数据的第一曝光对象中,被所述第一样本用户点击过的对象;
26、所述第一极难负例对象包括:在所述第一曝光对象中,排序在前第一预设数量位、但未被所述第一样本用户点击过的对象;
27、所述第一较难负例对象包括:在响应所述第一样本请求数据的第一召回对象中,排序不在前第二预设数量位的对象;
28、所述第一简单负例对象包括:在根据所述小类别用户点击过的对象组成的第一正例对象集中,未被所述第一样本用户点击过的对象。
29、上述实施方式中,通过多种方式选取第一双塔模型训练用的负例对象,有利于模型充分学习到真实样本数据的分布,从而提高模型性能。
30、在一些可能的实施方式中,所述用户的请求数据中包括所述用户的历史行为数据;所述方法还包括:
31、利用第二双塔模型中的请求侧模型,基于所述请求数据提取第三特征向量,其中,所述第二双塔模型是基于第二样本用户的第二样本请求数据及其对应的第二样本对象训练得到的,所述第二样本用户属于所述小类别用户,所述第二样本请求数据中包括所述第二样本用户的第二历史行为数据;
32、根据所述第三特征向量与第二对象集合中第二对象的第四特征向量之间的相似度,从所述第二对象集合中确定与所述请求数据相关的第二对象子集合,其中,所述第二对象集合是针对所述小类别用户构建的,所述第二对象的第四特征向量是利用所述第二双塔模型中的对象侧模型基于所述第二对象提取的;
33、所述根据所述第一对象子集合,确定推荐给所述用户的对象,包括:
34、根据所述第一对象子集合和所述第二对象子集合,确定推荐给所述用户的对象。
35、上述实施方式中,利用第二双塔模型基于用户的请求数据提取第三特征向量,根据第三特征向量与第二对象集合中第二对象的第四特征向量之间的相似度,从第二对象集合中确定与请求数据相关的第二对象子集合,根据第一对象子集合和第二对象子集合确定推荐给用户的对象。其中,用户属于小类别用户,第二对象集合是针对小类别用户构建的,这使得第二对象作为推荐对象的合适概率较大,并且第二双塔模型的训练中引入了第二样本用户的第二历史行为数据,使模型能够学习到小类别用户的行为特征,有利于进一步提高对于小类别用户的推荐效果。
36、在一些可能的实施方式中,所述方法还包括:训练获得所述第二双塔模型,所述训练获得所述第二双塔模型包括:
37、获取第二训练数据,所述第二训练数据包括:第二样本用户的第二样本请求数据及其对应的第二样本对象;
38、利用第二待训练双塔模型中的请求侧模型,计算所述第二历史行为数据的注意力权重,基于所述第二历史行为数据的注意力权重以及所述第二样本请求数据提取第三样本特征向量;
39、利用所述第二待训练双塔模型中的对象侧模型,基于所述第二样本对象提取第四样本特征向量;
40、根据所述第三样本特征向量与所述第四样本特征向量之间的相似度,调整所述第二待训练双塔模型的参数,获得所述第二双塔模型。
41、上述实施方式中,针对小类别用户训练第二双塔模型,训练过程中引入了用户历史行为数据的注意力权重,使得用户行为利用上更能体现个体本身的偏好,有利于获得更好的模型性能。
42、在一些可能的实施方式中,所述第二样本请求数据包括:第三样本请求数据或其关联的第四样本请求数据;
43、所述第三样本请求数据中的第二历史行为数据包括:由所述第二样本用户最近点击过的第三预设数量的对象组成的对象序列,所述第四样本请求数据中的第二历史行为数据包括:对所述对象序列进行随机遮蔽获得的对象子序列;
44、所述第三样本请求数据对应的第二样本对象包括:第二正例对象和第二负例对象,所述第四样本请求数据对应的第二样本对象包括:辅助负例对象;
45、所述第二正例对象包括:在响应所述第三样本请求数据的第二曝光对象中,被所述第二样本用户点击过的对象;
46、所述第二负例对象包括:第二极难负例对象、第二较难负例对象和第二简单负例对象;
47、所述第二极难负例对象包括:在所述第二曝光对象中,排序在前第四预设数量位、但未被所述第二样本用户点击过的对象;
48、所述第二较难负例对象包括:在响应所述第三样本请求数据的第二召回对象中,排序不在前第五预设数量位的对象;
49、所述第二简单负例对象包括:在根据所述小类别用户点击过的对象组成的第二正例对象集中,未被所述第二样本用户点击过的对象;
50、所述辅助负例对象包括:所述第四样本请求数据关联的第三样本请求数据所对应的第二正例对象。
51、上述实施方式中,通过多种方式选取第二双塔模型训练用的负例对象,有利于模型充分学习到真实样本数据的分布以及小类别用户的行为特征,从而提高模型性能。
52、第二方面,本技术实施例提供了一种对象推荐装置,所述装置包括:
53、获取单元,用于获取用户的请求数据,所述用户属于小类别用户;
54、处理单元,用于利用第一双塔模型中的请求侧模型,基于所述请求数据提取第一特征向量,其中,所述第一双塔模型是基于第一样本用户的第一样本请求数据及其对应的第一样本对象训练得到的,所述第一样本用户属于所述小类别用户,所述第一样本请求数据中不包括所述第一样本用户的第一历史行为数据;
55、确定单元,用于根据所述第一特征向量与第一对象集合中第一对象的第二特征向量之间的相似度,从所述第一对象集合中确定与所述请求数据相关的第一对象子集合,其中,所述第一对象集合是针对所述小类别用户构建的,所述第一对象的第二特征向量是利用所述第一双塔模型中的对象侧模型基于所述第一对象提取的;
56、推荐单元,用于根据所述第一对象子集合,确定推荐给所述用户的对象。
57、在一些可能的实施方式中,所述装置还包括:
58、构建单元,用于确定种子对象和扩充对象,根据所述种子对象和所述扩充对象构建所述第一对象集合,其中,所述种子对象包括所述小类别用户交互过的对象,所述扩充对象是基于所述种子对象挖掘的。
59、在一些可能的实施方式中,所述处理单元还用于:训练获得所述第一双塔模型,所述处理单元在训练获得所述第一双塔模型时,具体用于:
60、获取第一训练数据,所述第一训练数据包括:第一样本用户的第一样本请求数据及其对应的第一样本对象;
61、利用第一待训练双塔模型中的请求侧模型,基于所述第一样本请求数据提取第一样本特征向量;
62、利用所述第一待训练双塔模型中的对象侧模型,基于所述第一样本对象提取第二样本特征向量;
63、根据所述第一样本特征向量与所述第二样本特征向量之间的相似度,调整所述第一待训练双塔模型的参数,获得所述第一双塔模型。
64、在一些可能的实施方式中,所述第一样本请求数据对应的第一样本对象包括:第一正例对象和第一负例对象;所述第一负例对象包括:与所述第一正例对象的区分难度依次减小的第一极难负例对象、第一较难负例对象和第一简单负例对象;
65、所述处理单元在根据所述第一样本特征向量与所述第二样本特征向量之间的相似度,调整所述第一待训练模型的参数,获得所述第一双塔模型时,具体用于:
66、对于所述第一极难负例对象,使用铰链损失函数根据所述第一样本特征向量与所述第二样本特征向量之间的相似度计算第一损失值;
67、对于所述第一正例对象、所述第一较难负例对象和所述第一简单负例对象,使用交叉熵损失函数根据所述第一样本特征向量与所述第二样本特征向量之间的相似度计算第二损失值;
68、基于所述第一损失值和所述第二损失值,调整所述第一待训练双塔模型的参数,获得所述第一双塔模型。
69、在一些可能的实施方式中,所述第一极难负例对象、所述第一较难负例对象、所述第一简单负例对象的数量比为1:3:30。
70、在一些可能的实施方式中,所述第一正例对象包括:在响应所述第一样本请求数据的第一曝光对象中,被所述第一样本用户点击过的对象;
71、所述第一极难负例对象包括:在所述第一曝光对象中,排序在前第一预设数量位、但未被所述第一样本用户点击过的对象;
72、所述第一较难负例对象包括:在响应所述第一样本请求数据的第一召回对象中,排序不在前第二预设数量位的对象;
73、所述第一简单负例对象包括:在根据所述小类别用户点击过的对象组成的第一正例对象集中,未被所述第一样本用户点击过的对象。
74、在一些可能的实施方式中,所述用户的请求数据中包括所述用户的历史行为数据;
75、所述处理单元还用于:利用第二双塔模型中的请求侧模型,基于所述请求数据提取第三特征向量,其中,所述第二双塔模型是基于第二样本用户的第二样本请求数据及其对应的第二样本对象训练得到的,所述第二样本用户属于所述小类别用户,所述第二样本请求数据中包括所述第二样本用户的第二历史行为数据;
76、所述确定单元还用于:根据所述第三特征向量与第二对象集合中第二对象的第四特征向量之间的相似度,从所述第二对象集合中确定与所述请求数据相关的第二对象子集合,其中,所述第二对象集合是针对所述小类别用户构建的,所述第二对象的第四特征向量是利用所述第二双塔模型中的对象侧模型基于所述第二对象提取的;
77、所述推荐单元还用于:根据所述第一对象子集合和所述第二对象子集合,确定推荐给所述用户的对象。
78、在一些可能的实施方式中,所述处理单元还用于:训练获得所述第二双塔模型,所述处理单元在训练获得所述第二双塔模型时,具体用于:
79、获取第二训练数据,所述第二训练数据包括:第二样本用户的第二样本请求数据及其对应的第二样本对象;
80、利用第二待训练双塔模型中的请求侧模型,计算所述第二历史行为数据的注意力权重,基于所述第二历史行为数据的注意力权重以及所述第二样本请求数据提取第三样本特征向量;
81、利用所述第二待训练双塔模型中的对象侧模型,基于所述第二样本对象提取第四样本特征向量;
82、根据所述第三样本特征向量与所述第四样本特征向量之间的相似度,调整所述第二待训练双塔模型的参数,获得所述第二双塔模型。
83、在一些可能的实施方式中,所述第二样本请求数据包括:第三样本请求数据或其关联的第四样本请求数据;
84、所述第三样本请求数据中的第二历史行为数据包括:由所述第二样本用户最近点击过的第三预设数量的对象组成的对象序列,所述第四样本请求数据中的第二历史行为数据包括:对所述对象序列进行随机遮蔽获得的对象子序列;
85、所述第三样本请求数据对应的第二样本对象包括:第二正例对象和第二负例对象,所述第四样本请求数据对应的第二样本对象包括:辅助负例对象;
86、所述第二正例对象包括:在响应所述第三样本请求数据的第二曝光对象中,被所述第二样本用户点击过的对象;
87、所述第二负例对象包括:第二极难负例对象、第二较难负例对象和第二简单负例对象;
88、所述第二极难负例对象包括:在所述第二曝光对象中,排序在前第四预设数量位、但未被所述第二样本用户点击过的对象;
89、所述第二较难负例对象包括:在响应所述第三样本请求数据的第二召回对象中,排序不在前第五预设数量位的对象;
90、所述第二简单负例对象包括:在根据所述小类别用户点击过的对象组成的第二正例对象集中,未被所述第二样本用户点击过的对象;
91、所述辅助负例对象包括:所述第四样本请求数据关联的第三样本请求数据所对应的第二正例对象。
92、第三方面,本技术实施例提供了一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面及其任意一种可能的实施方式中的方法。
93、第四方面,本技术实施例提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面及其任意一种可能的实施方式中的方法。
94、第五方面,本技术实施例提供了一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现上述第一方面及其任意一种可能的实施方式中的方法。
95、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本技术的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!