基于自适应加权TV正则化的盲图像反卷积工作方法
基于自适应加权tv正则化的盲图像反卷积工作方法
技术领域
1.本发明涉及图像处理领域,尤其涉及一种基于自适应加权tv正则化的盲图像反卷积工作方法。
背景技术:
2.图像反卷积是图像处理中的一个基本问题,近年来引起了越来越多的关注。其目的是将带有噪声的模糊图像重建成清晰的图像;模糊图像通常被建模为图像和模糊核(也被称为点扩散函数(psf))的线性卷积。在数学上,图像退化过程被描述如下:
3.f=k*u+η,
4.其中u和f分别代表清晰图像和退化图像,k是模糊核,*表示卷积算子,η是加性高斯白噪声。图像反卷积包括非盲反卷积和盲反卷积两种类型。当模糊核k已知时,通过f和k获得清晰图像u的问题称为非盲反卷积。但在许多实际应用中,模糊核通常是未知。在这种情况下需要从f中估计u和k。这个问题被称为盲反卷积。盲反卷积作为图像处理和计算机视觉领域的研究热点,与非盲反卷积不同的是,盲反卷积不仅对噪声敏感,而且可能产生许多解。由于这些原因,盲图像反卷积比非盲图像反卷积更具挑战性。
5.为了解决盲反卷积问题,现有技术提出了一种盲反卷积方法,利用h1范数最小化图像u和模糊核k。u和k的h1范数最小化问题可以表示为
[0006][0007]
其中第一项为数据拟合项,其余两项分别为u和k的h1范数。α和β是两个正则化参数。然而,h1范数具有非常强的各向同性平滑特性,这使得该方法在保留图像边缘方面不令人满意。现有技术存在用于高斯图像去噪的全变分(tv)正则化模型。该模型在去除噪声的同时能够更好地保留图像的边缘。此后便有了使用tv正则化代替h1范数提出的一种新的盲反卷积方法:
[0008][0009]
tv正则化能够在保留边缘的同时去除噪声和模糊,特别是对于分段常数图像。然而,由于tv模型的非线性和不可微性,在计算中很难求解。现有技术使用冲击滤波器对退化图像进行预处理,然后将预处理后的图像用作tv最小化盲反卷积的初始条件,与现有技术相比,该方法可以节省计算时间。虽然tv正则化在保留边缘方面表现良好,但在保持图像纹理方面表现不佳。因此,现有技术提出了一种用于盲图像复原的自适应非局部tv正则化方法。该方法可以通过非局部tv算子充分利用分布在不同图像区域的空间信息,从而保留图像的更多细节。由于卡通和纹理分量在图像中的表现形式不同,现有技术在盲图像反卷积中使用卡通纹理分解技术来保存纹理。此外,tv范数还容易将平滑信号转换为分段常数,从而导致阶梯效应。为了消除阶梯效应,现有技术提出了一种用于盲图像反卷积的非凸高阶tv模型。然而,高阶tv正则化对于保留图像边缘并不理想。
[0010]
现有技术中的基于传统tv正则化的盲反卷积算法在处理图像的局部结构时并不理想,全变分(tv)正则化能够保留图像边缘,但是缺乏自适应性,在复原具有复杂结构的图像时表现不佳。这就亟需本领域技术人员解决相应的技术问题。
技术实现要素:
[0011]
本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于自适应加权tv正则化的盲图像反卷积工作方法。
[0012]
为了实现本发明的上述目的,本发明提供了一种基于自适应加权tv正则化的盲图像反卷积工作方法,包括如下步骤:
[0013]
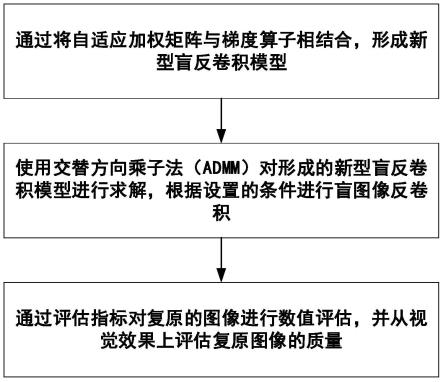
s1,通过将自适应加权矩阵与梯度算子相结合,形成新型盲反卷积模型;
[0014]
s2,使用交替方向乘子法(admm)对形成的新型盲反卷积模型进行求解,根据设置的条件进行盲图像反卷积;
[0015]
s3,通过评估指标对复原的图像进行数值评估,并从视觉效果上评估复原图像的质量。
[0016]
根据上述技术方案优选的,所述s1包括:
[0017]
提出了以下用于盲图像反卷积的自适应加权tv模型:
[0018][0019]
其中α和β是用于平衡数据拟合项和正则项的两个正则化参数,t为自适应加权矩阵,为梯度算子。经过实验研究,本发明发现使用的性能优于使用||k||1,所以使用l1范数用于约束
[0020]
根据上述技术方案优选的,t的定义如下:
[0021][0022]
其中g
δ
(
·
)表示二维高斯卷积核,δ和ι是两个参数,和表示f在水平和垂直方向上的差分,i和j分别表示图像像素点的横轴和纵轴坐标。
[0023]
根据上述技术方案优选的,所述s2包括:
[0024]
引入三个辅助变量p、q、w,将模型重写为约束优化问题:
[0025][0026]
为求解上式,引入了三个拉格朗日乘子λ1、λ2、λ3,将其转化为鞍点问题,其增广拉格朗日泛函为:
[0027][0028]
其中k表示未知模糊矩阵,是由点扩散函数k形成的块循环矩阵;r1、r2和r3是三个罚参数。
[0029]
根据上述技术方案优选的,应用admm时,需要最小化k,u,p,q,w五个子问题,在每次迭代时固定其它变量,并更新三个拉格朗日乘子λ1、λ2、λ3。得到以下公式:
[0030][0031]
其中,上标n为迭代次数的递增符号,n≥0。
[0032]
根据上述技术方案优选的,k子问题表示为
[0033][0034]
其中,u是由图像u形成的块循环矩阵。根据最优性条件,得出上式的欧拉-拉格朗日方程,本发明假设为周期边界条件,因此可通过快速傅立叶变换(fft)求解该方程,得到
[0035][0036]
其中,f表示fft,f-1
表示其逆变换,表示梯度算子的共轭转置。
[0037]
根据上述技术方案优选的,u子问题表示为
[0038][0039]
根据其最优性条件,然后使用fft,得到公式:
[0040][0041]
根据上述技术方案优选的,对于p子问题,表示为
[0042][0043]
根据上述公式最优性条件,其中p=[p1,p2],q=[q1,q2],λm=[λ
m1
,λ
m2
](m=1,2);则相应的线性方程组表示为
[0044][0045]
通过简单的计算从上式线性方程组中获得p
n+1
的显式解:
[0046][0047]
根据上述技术方案优选的,q子问题表示为
[0048][0049]
其具有闭形式解,可由快速收缩公式给出
[0050][0051]
w子问题表示为
[0052][0053]
类似于q子问题,w子问题的解也可由快速收缩公式给出
[0054][0055]
根据上述技术方案优选的,所述s3包括:
[0056]
定义:
[0057][0058][0059][0060]
其中f、i和u分别表示退化图像、原始图像和复原图像;m和n是图像的长度和宽度;
μ和σ分别表示图像的局部均值和标准偏差;σ
iu
是i和u之间的协方差值;c1和c2是两个常数,用于避免分母值接近零;psnr、isnr和ssim的值越高,图像复原的质量越好;un的相对误差定义为:
[0061][0062]
综上所述,由于采用了上述技术方案,本发明的有益效果是:
[0063]
本发明提出了一种新的使用自适应加权tv正则化的盲图像反卷积模型。该模型能够更好地处理图像的局部结构。在数值上,设计了一种有效的交替方向乘子法(admm)来求解该非光滑模型。实验结果表明,与其它相关的盲反卷积方法相比,该方法具有优越性。
[0064]
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
[0065]
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
[0066]
图1是本发明总体流程图;
[0067]
图2是本发明数据实验的清晰图;
[0068]
图3(a)至3(d)是本发明设置线性运动模糊、高斯模糊、离焦模糊和自定义模糊效果图;
[0069]
图4(a)至4(d)是本发明satellite线性运动模糊状态下的四种效果图;
[0070]
图5(a)至5(d)是本发明satellite高斯模糊状态下的四种效果图;
[0071]
图6(a)至6(d)是本发明satellite离焦模糊状态下的四种效果图;
[0072]
图7(a)至7(d)是本发明satellite自定义模糊状态下的四种效果图;
[0073]
图8(a)至8(d)是本发明lena线性运动模糊状态下的四种效果图;
[0074]
图9(a)至9(d)是本发明lena高斯模糊状态下的四种效果图;
[0075]
图10(a)至10(d)是本发明lena离焦模糊状态下的四种效果图;
[0076]
图11(a)至11(d)是本发明lena自定义模糊状态下的四种效果图;
[0077]
图12(a)至12(d)是本发明peppers线性运动模糊状态下的四种效果图;
[0078]
图13(a)至13(d)是本发明peppers高斯模糊状态下的四种效果图;
[0079]
图14(a)至14(d)是本发明peppers离焦模糊状态下的四种效果图;
[0080]
图15(a)至15(d)是本发明peppers自定义模糊状态下的四种效果图;
[0081]
图16(a)至16(d)是本发明house线性运动模糊状态下的四种效果图;
[0082]
图17(a)至17(d)是本发明house高斯模糊状态下的四种效果图;
[0083]
图18(a)至18(d)是本发明house离焦模糊状态下的四种效果图;
[0084]
图19(a)至19(d)是本发明house自定义模糊状态下的四种效果图;
[0085]
图20是本发明的peppers复原图;
[0086]
图21是本发明的lena复原图。
具体实施方式
[0087]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
[0088]
如图1所示,本发明公开一种基于自适应加权tv正则化的盲图像反卷积工作方法,包括如下步骤:
[0089]
s1,通过将自适应加权矩阵与梯度算子相结合,形成新型盲反卷积模型;
[0090]
s2,使用交替方向乘子法(admm)对形成的新型盲反卷积模型进行求解,根据设置的条件进行盲图像反卷积;
[0091]
s3,通过评估指标对复原的图像进行数值评估,并从视觉效果上评估复原图像的质量。
[0092]
由于图像的不同区域具有不同的结构。对于所提出的模型,保持局部结构至关重要。由于梯度的有限差分方式仅依赖于水平和垂直方向,传统的基于tv的模型不能有效地与图像的局部结构耦合。为了克服这一缺点,现有技术提出了一种用于高斯图像去噪的各向异性tv(atv)模型,该模型能够更好地沿局部特征的切线方向扩散。为了更有效地与局部结构耦合,通过添加自适应加权矩阵t来构造不同的权重。t的定义如下:
[0093][0094]
其中g
δ
(
·
)表示二维高斯卷积核,δ和ι是两个参数,和表示f在水平和垂直方向上的差分,i和j分别表示图像像素点的横轴和纵轴坐标。
[0095]
对于盲图像反卷积,将自适应加权矩阵t与梯度算子相结合。此外,使用l1范数用于约束因此,提出了以下用于盲图像反卷积的自适应加权tv模型:
[0096][0097]
其中α和β是用于平衡数据拟合项和正则项的两个正则化参数。经过实验研究,本发明发现在多数情况下使用的性能优于使用||k||1。
[0098]
本发明使用admm来求解模型,将初始问题的解转化为几个简单子问题交替计算。admm广泛应用于凸优化和非凸优化,在盲图像反卷积领域也有许多应用。
[0099]
为了应用admm,引入三个辅助变量p、q、w,将模型重写为约束优化问题:
[0100][0101]
为求解上式,引入三个拉格朗日乘子λ1、λ2、λ3,将其转化为鞍点问题。其增广拉格朗日泛函为:
[0102][0103]
其中k表示未知模糊矩阵,是由点扩散函数k形成的块循环矩阵。r1、r2和r3是三个罚参数。
[0104]
在应用admm时,需要最小化五个子问题,在每次迭代时固定其它变量,并更新三个拉格朗日乘子。也就是说,有
[0105][0106]
下面给出了上述子问题的显式解。其中,上标n为迭代次数的递增符号,n≥0;
[0107]
k子问题表示为
[0108][0109]
其中,u是由图像u形成的块循环矩阵。根据最优性条件,得出上式的欧拉-拉格朗日方程,本发明假设为周期边界条件,因此可通过快速傅立叶变换(fft)有效地求解该方程,得到
[0110][0111]
其中,f表示fft,f-1
表示其逆变换。表示梯度算子的共轭转置。
[0112]
u子问题表示为
[0113]
[0114]
根据其最优性条件,然后使用fft,得到公式:
[0115][0116]
对于p子问题,表示为
[0117][0118]
根据上述公式最优性条件,其中p=[p1,p2],q=[q1,q2],λm=[λ
m1
,λ
m2
](m=1,2)。则相应的线性方程组表示为
[0119][0120]
显然,p子问题是光滑优化问题。因此通过简单的计算从上式线性方程组中获得p
n+1
的显式解:
[0121][0122]
对于q子问题表示为
[0123][0124]
其具有闭形式解,可由快速收缩公式给出
[0125][0126]
w子问题表示为
[0127][0128]
类似于q子问题,w子问题的解也可由快速收缩公式给出
[0129][0130]
由于模型的解(k,u)不是唯一的。因此,需要对k和u施加一些约束,以获得唯一的合理解。本发明对估计的psf进行归一化,并在迭代过程中考虑图像强度的非负性。因此,计算∫kn(x,y)dxdy=1和
[0131]
[0132]
为了减少估计的点扩散函数psf中所存在噪声的影响,使用动态阈值约束来进一步优化psf;使用如下公式:
[0133][0134]
其中max(kn)表示第n次估计的psf的最大值,ξ是一个小的正常数。在实验中设定ξ=0.05。
[0135]
为了体现本发明中盲图像反卷积方法相对于其它盲反卷积方法的有效性和优越性:tv-bdsb和ep-l0rg。为了简化表示,将新提出的方法表示为awtv-bd。所有的数值实验都是在matlab环境下使用峰值信噪比(psnr)、改善信噪比(isnr)和结构相似性(ssim)作为定量指标来评估复原结果的质量,有如下定义:
[0136][0137][0138][0139]
其中f、i和u分别表示退化图像、原始图像和复原图像。m和n是图像的长度和宽度。μ和σ分别表示图像的局部均值和标准偏差。σ
iu
是i和u之间的协方差值。c1和c2是两个常数,用于避免分母值接近零。psnr、isnr和ssim的值越高,图像复原的质量越好。un的相对误差定义为:
[0140][0141]
在所有实验中,当r(un)<10-4
或迭代次数达到500步时,迭代将终止。
[0142]
在图2中,有四张测试图像,包括a:satellite(256
×
256)、b:peppers(256
×
256)、c:lena(256
×
256)和d:house(256
×
256),这些图像的强度均被缩放至0到1之间。为了获得退化图像,使用matlab命令“fspecial”生成三种不同的模糊核,如图3所示,包括a:线性运动模糊(长度为8像素,方向为45度),b:高斯模糊(大小为7
×
7像素,方差为25)和c:离焦模糊(半径为3像素)。最后一种自定义模糊图3(d)是模拟的不规则运动模糊,本发明手动设置为([0 1 1 1 1 0 0;1 1 0 0 0 1 0;0 0 0 0 1 1 0;0 0 1 1 0 0 0;0 1 1 0 0 1 1;0 1 0 0 1 1 0;0 1 1 1 1 0 0]/22)。使用的模糊内核如图3所示。
[0143]
在执行所提出的算法之前,需要设置7个参数,即α、β、ι、δ、r1、r2和r3。α控制图像正则项的权重。如果α太大,会导致复原的图像过于平滑,丢失图像的一些细节。相反,如果α太
小,则无法很好地去除噪声。总之,α的选择通常与图像受噪声污染的程度有关。当原始清晰图像被高噪声污染时,应选择较大的α。在实验中,设置α∈[0.000001,0.01]。β是模糊核k的正则项参数,影响psf的扩散。如果β过大,估计的psf将更加扩散。相反,β过小则会使估计psf的支持域不会被充分展开。实验中设置β∈[0.0001,10]。为了获得令人满意的盲反卷积结果,这两个参数选择合适的值至关重要。
[0144]
ι是用于控制局部自适应性的参数,δ是标准偏差。在参数调整的过程中,ι的选择会受到测试图像和模糊类型的影响。因此,需要根据具体实验进行调整。此外,δ对复原图像的psnr值影响不大。
[0145]
r1、r2和r3三个罚参数控制p、q和w的更新。设置r1∈[0.00001,10],r2∈[0.000001,1]。为了获得最高的psnr值,将r3的值设置为5的倍数。
[0146]
本发明针对盲反卷积,首先测试了awtv-bd在低噪声水平下的盲反卷积性能。通过将图3中的四个不同模糊核添加到测试图像中生成模糊图像,且模糊图像均受到标准方差为0.001的加性高斯白噪声的污染。对于盲图像反卷积,需要设置psf的支持域。由于psf的真实支持域大小未知,因此psf初始支持域的大小设置为大于真实支持域的大小,但小于图像的大小。在实验中,将psf支持域的大小设置为101
×
101像素。从表1和表2的结果可以看出,在大多数情况下,本发明提出的awtv-bd与其它方法相比能得到最高的psnr、isnr和ssim值。特别是对于线性运动模糊、高斯模糊和离焦模糊,awtv-bd的psnr和isnr值始终最高。
[0147]
为了直观地评估不同方法的结果,在图4至图7和图8至图11分别展示了satellite图像和lena图像的复原结果,并将选择的局部放大图像放置在左下角。此外,复原的模糊核被放置在图像的右下角。
[0148]
从图4至图7的satellite图像的复原结果可以观察到,ep-l0rg恢复的图像丢失了很多细节,无法获得令人满意的视觉效果,恢复的模糊核与原始模糊核也有很大的不同。幸运的是,本发明提出的awtv-bd与其它两种方法相比,恢复的模糊核最接近原始模糊核。
[0149]
图4a为线性运动模糊试验状态下原始图,图4b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图4c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图4d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0150]
图5a为高斯模糊试验状态下原始图,图5b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图5c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图5d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0151]
图6a为离焦模糊试验状态下原始图,图6b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图6c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图6d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0152]
图7a为自定义模糊试验状态下原始图,图7b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图7c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图7d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0153]
从图8至图11可以看出,ep-l0rg恢复的图像同样过于平滑,导致原始图像的一些细节丢失。另外,tv-bdsb得到的一些图像在平坦区域有明显的阶梯效应。本发明提出的awtv-bd由于使用了自适应加权矩阵,可以更好地保留图像的局部结构,尤其是面部和嘴
角。从恢复的模糊核可以看出,本发明提出的awtv-bd恢复的模糊核最接近于原始模糊核。
[0154]
图8a为线性运动模糊试验状态下原始图,图8b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图8c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图8d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0155]
图9a为高斯模糊试验状态下原始图,图9b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图9c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图9d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0156]
图10a为离焦模糊试验状态下原始图,图10b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图10c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图10d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0157]
图11a为自定义模糊试验状态下原始图,图11b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图11c为边缘保持l0正则化梯度先验(ep-l0rg)复原图像,图11d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图像。
[0158][0159]
表1在标准方差为0.001的高斯噪声下盲反卷积的数值结果。
[0160][0161]
表2在标准方差为0.001的高斯噪声下盲反卷积的数值结果。
[0162]
此外,在更高噪声水平的情况,例如peppers图像和house图像,添加标准差为0.01的加性高斯白噪声。用于图像模糊的模糊核与之前的实验相同。在表3可以看出,在大多数情况下,自适应加权tv正则化盲图像反卷积方法(awtv-bd)仍然达到最高的psnr、isnr和ssim值。为了在视觉效果上评估复原的图像,在图12至图15展示了复原后的peppers图像,其中复原的模糊核放置在图像的右下角。从图12至图15看出,在高噪声水平下,通过边缘保持l0正则化梯度先验(ep-l0rg)得到的复原图像也过于平滑,尽管对于图15中的自定义模糊,其复原的模糊核更接近原始模糊核。
[0163]
其中,图12a为线性运动模糊试验状态下原始图,图12b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图12c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图12d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0164]
图13a为高斯模糊试验状态下原始图,图13b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图13c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图13d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0165]
图14a为离焦模糊试验状态下原始图,图14b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图14c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图14d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0166]
图15a为自定义模糊试验状态下原始图,图15b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图15c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图15d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0167]
从图16至图19展示复原后的house图像看出,ep-l0rg产生的过度平滑效果非常明显,而本发明提出的awtv-bd克服了这个问题。另外,从这几组图看出,与其它两种方法相比,awtv-bd复原的图像更为自然。
[0168]
其中,图16a为线性运动模糊试验状态下原始图,图16b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图16c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图16d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0169]
图17a为高斯模糊试验状态下原始图,图17b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图17c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图17d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0170]
图18a为离焦模糊试验状态下原始图,图18b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图18c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图18d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0171]
图19a为自定义模糊试验状态下原始图,图19b为tv正则化盲反卷积方法(tv-bdsb)的复原图,图19c为边缘保持l0正则化梯度先验(ep-l0rg)复原图,图19d为自适应加权tv正则化盲图像反卷积方法(awtv-bd)复原图。
[0172][0173][0174]
表3在标准方差为0.01的高斯噪声下盲反卷积的数值结果。
[0175]
本发明针对非盲反卷积展示了非盲图像反卷积的结果,此时psf是完全已知的。模型对应的非盲反卷积问题表示为
[0176]
[0177]
同样,tv-bdsb非盲反卷积的模型如下:
[0178][0179]
其中,k为未知模糊矩阵,这两个模型分别使用admm和split bregman方法求解。将它们分别表示为自适应加权tv正则化非盲反卷积模型(awtv-nbd)和tv正则化非盲反卷积模型(tv-nbd)。在实验中,使用自定义模糊核对原始图像进行模糊处理。在模糊图像中加入标准差为0.01的加性高斯白噪声。图20和图21展示了复原的peppers图像和lena图像,同时也给出了局部放大图像,其中第一列表示退化图像,第二列表示tv正则化非盲反卷积模型(tv-nbd)复原图像和第三列为自适应加权tv正则化非盲反卷积模型(awtv-nbd)复原图像。由表4可知,与tv-nbd相比,awtv-nbd具有更高的psnr和ssim值。从图20和图21中看出,由于使用了自适应加权矩阵,awtv-nbd复原的图像更加自然。
[0180][0181]
表4标准差为0.01的高斯噪声下非盲反卷积方法比较。
[0182]
本发明提出一种用于盲图像反卷积的自适应加权全变分正则化方法。为了更好地描述图像的局部结构,将自适应加权矩阵与梯度算子相结合。此外,采用了一种有效的admm对模型进行求解。本发明提出的方法可以复原多种类型的模糊。实验结果表明,该方法对线性运动模糊、高斯模糊和离焦模糊退化的图像具有较好的复原性能。
[0183]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1