一种融合后见之明思想的群体智能学习方法与流程
1.本发明属于多智能体深度强化学习领域,特别涉及该领域中的一种融合后见之明思想的通用有效群体智能学习方法。
背景技术:
2.随着科学技术的不断进步,强化学习和深度学习相结合,形成了深度强化学习领域,其在游戏、无人机编队、自动驾驶和物流调配等场景下表现出超越人类的水准。尽管深度强化学习在多智能体系统的应用方面已经取得了一些成果,但是仍然存在一些挑战,其中一点是经验回放区中大多为失败经验。多智能体场景的状态动作空间随着智能体数量的增长呈指数型增长,在如此大的空间中进行试错,智能体很难得到成功的经验。这就导致智能体只能使用失败经验进行学习,几乎不能得到效果好的策略。另一个问题是经验只能通过与环境交互得到,导致采样效率较低。因此,强化学习研究的一个重要方向是采用更有效率的采样方法并得到质量更高的经验。
3.目前已有通过经验回放技术提高采样效率并提升经验质量的做法,dqn(deep q-network)首次将经验回放的概念引入深度强化学习中,利用它存储每一步产生的经验以便后续更新使用,一定程度上解决了采样效率低的问题。per(prioritized experience replay)对经验回放进行了改进,开发出一个优先考虑经验的框架,以便更频繁地回放重要的经验,进行更有效地学习。der(dynamic experience replay)使强化学习算法不仅可以使用人类演示中的经验回放样本,还可以使用智能体在训练过程中成功进行的状态转换经验,从而提高训练效率。
技术实现要素:
4.本发明所要解决的技术问题就是提供一种融合后见之明思想的群体智能学习方法,将后见之明思想引入流行的多智能体强化学习算法maddpg(multi-agent deep deterministic policy gradient)中,令智能体拥有在已有经验的基础上反思的能力,从而得到新的更倾向于成功的伪经验,以此扩充经验回放区,改善算法的效果。
5.本发明采用如下技术方案:
6.一种融合后见之明思想的群体智能学习方法,其改进之处在于,包括如下步骤:
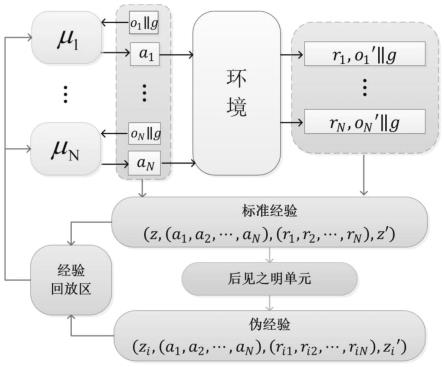
7.步骤1,使用多智能体强化学习算法生成标准经验:
8.环境中的每个智能体都有自己的策略一评判网络,策略网络输入智能体自身的状态s=o||g,其中,o是智能体的局部观测值,g是本回合的目标,o和g采用直接连接的方式构成状态,策略网络的输出是动作a;
9.智能体依据策略网络选择出的动作与环境交互,得到一条标准经验(z,(a1,
…
,an),(r1,
…
,rn),z
′
),其中,n表示环境中的智能体数量,z=(o1||g,o2||g,
…
,on||g),代表所有智能体的状态,z
′
代表所有智能体转移到的下一状态,an是第n个智能体选择执行的动作,rn是第n个智能体动作后得到的即时奖励,1≤n≤n,计算方法为:
10.rn=r(on′
,g,an)
11.其中,r为奖励函数,on′
为第n个智能体转移到的下一局部观测值,得到的标准经验存入经验回放区d;
12.步骤2,从标准经验中采样伪目标,构造伪目标集合:
13.将z
′
作为新的状态输入策略网络,策略网络选择新的动作,重复t步完成一回合的交互,t为正整数,得到一条状态转移轨迹(z1,z2,
…
,z
t
),对于第t步得到的标准经验(z
t
,(a
t1
,a
t2
,
…
,a
tn
),(r
t1
,r
t2
,
…
,r
tn
),z
t+1
),1≤t≤t,从状态转移轨迹(z
t+1
,z
t+2
,
…
,z
t
)中随机选择k个状态,k为正整数,将所选状态中的观测值(o1,o2,
…
,ok)作为伪目标(g1,g2,
…
,gk),构成伪目标集合g;
14.步骤3,依据伪目标,使用后见之明单元生成伪经验:
15.用每个gk∈g替换标准经验中z
t
和z
t+1
的目标部分,1≤k≤k,得到新的当前状态z
tk
=(o
t1
||gk,o
t2
||gk,
…
,o
tn
||gk)和新的下一状态z
(t+1)k
=(o
(t+1)1
||gk,o
(t+1)2
||gk,
…
,o
(t+1)n
||gk),使用与标准经验相同的奖励函数,依据伪目标重新计算奖励,具体计算方法是:
16.r
tn
=r(o
(t+1)n
,gk,a
tn
)
17.用计算得到的新的当前状态、新的下一状态和奖励组成伪经验(zk,(a1,a2,
…
,an),(r
k1
,r
k2
,
…
,r
kn
),zk′
),其中zk=(o1||gk,o2||gk,
…
,on||gk),伪经验也存入经验回放区d,供智能体网络更新使用;
18.步骤4,智能体结合标准经验和伪经验更新智能体策略-评判网络:
19.对于策略网络,智能体i的收益期望的梯度是:
[0020][0021]
其中,e是求期望,θi表示智能体i的网络的参数,是智能体i的动作值函数,通过所有智能体的状态和动作得到智能体i的奖励值,μ是所有智能体策略的集合;
[0022]
对于评判网络,更新方法为:
[0023][0024]
其中,是损失函数,μ
′
是目标网络所有智能体策略的集合,是目标网络的动作值函数,j是智能体索引,1≤j≤n,γ是折扣系数。
[0025]
本发明的有益效果是:
[0026]
本发明所公开的方法,通过引入后见之明单元生成高质量伪经验,改善了经验回放区的质量,解决了在多智能体系统中智能体只能使用低质量经验进行学习的问题。本发明方法将标准经验和伪经验都存入经验回放区,有效地丰富了经验回放区,隐式地提高了采样效率。本发明方法可以指导智能体学到更好的策略,并且在合作、竞争和合作竞争共存的多智能体系统中都适用。
[0027]
本发明通过引入后见之明思想改进多智能体系统中的智能体学习方法,该方法结构简单清晰,易于实现,对不同场景下智能体的学习都有帮助。对于生活中常见的无人机编
队、自动驾驶、交通路口规划、智能体群体协同等实际问题有参考意义。
[0028]
本发明针对复杂环境下智能体探索时存在大量失败经验的问题进行了定制化设计,较好的解决了智能体仅能依据失败经验进行学习的问题,能有效提升算法的采样效率和学习效果。
[0029]
本发明具有先进性、稳定性和实用性,其应用范围广泛,经过后见之明单元扩充经验回放区后训练的智能体能收敛到获得超过基线算法45%奖励的成功策略。
附图说明
[0030]
图1是本发明方法的流程示意图;
[0031]
图2是本发明方法的模型结构图。
具体实施方式
[0032]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图和实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0033]
目前有很多工作都引入了后见之明的思想。her(hindsight experience replay)方法被用在机器人臂的训练中:训练过程中,her将访问过的状态标记为目标状态,然后用新构建的目标状态替换真实的目标,并重新计算奖励值。接着将原经验和计算后的经验一起作为历史经验指导智能体学习有效策略。cher(curriculum-guided hindsight experience replay)利用逐渐变化比例的好奇心自适应地选择失败的经验进行复盘,同时具有课程指导和事后经验回放的优点,精心设计的课程可以提高强化学习的质量和效率,从失败的经历中得到教训和经验修正自己的行为。cer(competitive experience replay)方法把学习放在一个有一对智能体探索竞争的环境下,通过引入自动探索性课程来补充her,有效地改善了算法性能。本发明利用后见之明的思想,在经验回放的基础上对每一条经验进行计算,将计算所得的结果也存入经验回放区,进一步提高样本利用率。
[0034]
本发明提出的融合后见之明思想的群体智能学习方法,主要包含两个部分,智能体网络和后见之明单元。首先介绍智能体网络:每个智能体都有自己的策略一评判网络,策略网络输入智能体自身的状态并输出动作,评判网络的输入是环境中所有智能体的状态-动作对,输出一个反应当前状态-动作好坏的q值,以此指导策略网络的更新。智能体依据策略网络给出的动作与环境交互,得到标准经验。后见之明单元对每条标准经验进行重新计算。选择新目标生成伪经验。经验回放区中的经验数量成倍增长,达到了提高经验利用率,扩充经验回放区的目的。
[0035]
接下来详细介绍本发明的具体原理。本发明在训练过程中通过后见之明单元有效利用失败和成功的探索经验,在依据原有经验生成新的伪经验后,成功增加了经验数量,提高采样效率。
[0036]
实施例1,如图1,2所示,本实施例公开了一种融合后见之明思想的群体智能学习方法,包括如下步骤:
[0037]
步骤1,使用多智能体强化学习算法(多智能体深度确定性策略梯度算法)生成标准经验:
[0038]
多智能体强化学习算法采用集中式训练分散式执行的框架,智能体仅根据自身局部观测值进行决策,但在训练阶段使用所有智能体的局部观测值和动作,保证智能体在学习过程中受环境不稳定性影响较小。
[0039]
多智能体环境中的每个智能体都有自己的策略-评判网络,策略网络输入智能体自身的状态s=o||g,其中,o是智能体的局部观测值,g是本回合的目标,o和g采用直接连接的方式构成状态,策略网络的输出是动作a;
[0040]
智能体依据策略网络选择出的动作与环境交互,得到一条标准经验(z,(a1,
…
,an),(r1,
…
,rn),z
′
),其中,n表示环境中的智能体数量,z=(o1||g,o2||g,
…
,on|g),代表所有智能体的状态,z
′
代表所有智能体转移到的下一状态,an是第n个智能体选择执行的动作,rn是第n个智能体动作后得到的即时奖励,1≤n≤n,计算方法为:
[0041]rn
=r(on′
,g,an)
[0042]
其中,r为奖励函数,on′
为第n个智能体转移到的下一局部观测值,得到的标准经验存入经验回放区d;
[0043]
步骤2,从标准经验中采样伪目标,构造伪目标集合:
[0044]
将z
′
作为新的状态输入策略网络,策略网络选择新的动作,重复t步完成一回合的交互,t为正整数,得到一条状态转移轨迹(z1,z2,
…
,z
t
),对于第t步得到的标准经验(z
t
,(a
t1
,a
t2
,
…
,a
tn
),(rt1,rt2,
…
,r
tn
),z
t+1
),1≤t≤t,从状态转移轨迹(z
t+1
,z
t+2
,
…
,z
t
)中随机选择k个状态,k为正整数,将所选状态中的观测值(o1,o2,
…
,ok)作为伪目标(g1,g2,
…
,gk),构成伪目标集合g;
[0045]
步骤3,依据伪目标,使用后见之明单元生成伪经验:
[0046]
后见之明单元为智能体赋予反思的能力,使用与生成标准经验相同的奖励函数,以标准经验为依据产生更倾向于成功的高质量伪经验。
[0047]
用每个gk∈g替换标准经验中z
t
和z
t+1
的目标部分,1≤k≤k,得到新的当前状态z
tk
=(o
t1
||gk,o
t2
||gk,
…
,o
tn
||gk)和新的下一状态z
(t+1)k
=(o
(t+1)1
||gk,o
(t+1)2
||gk,
…
,o
(t+1)n
||gk),使用与标准经验相同的奖励函数,依据伪目标重新计算奖励,具体计算方法是:
[0048]rtn
=r(o
(t+1)n
,gk,a
tn
)
[0049]
用计算得到的新的当前状态、新的下一状态和奖励组成伪经验(zk,(a1,a2,
…
,an),(r
k1
,r
k2
,
…
,r
kn
),zk′
),其中zk=(o1||gk,o2||gk,
…
,on||gk),伪经验也存入经验回放区d,供智能体网络更新使用;
[0050]
步骤4,智能体结合标准经验和伪经验更新智能体策略-评判网络:
[0051]
对于策略网络,智能体i的收益期望的梯度是:
[0052][0053]
其中,e是求期望,θi表示智能体i的网络的参数,是智能体i的动作值函数,通过所有智能体的状态和动作得到智能体i的奖励值,μ是所有智能体策略的集合;
[0054]
对于评判网络,更新方法为:
[0055]
[0056]
其中,是损失函数,μ
′
是目标网络所有智能体策略的集合,是目标网络的动作值函数,j是智能体索引,1≤j≤n,γ是折扣系数。
[0057]
本发明利用伪经验丰富经验回放区以提高采样效率,经过后见之明单元改善经验回放区之后的强化学习方法能得到更好的学习效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1