一种基于提示学习的文本分类方法
1.本发明提供一种基于提示学习的文本分类方法,具体涉及一种根据输入数据对文本分类提示进行修正的方法,属于自然语言处理中的文本分类领域。
背景技术:
2.神经文本分类模型(英语:neural document classification)是一种引入人工神经网络进行文本分类的分类方式。以图1中展示的文本分类任务来举例子。当给定的输入文本是:“根据统计数据,2013年全国刺参养殖面积达到36万亩,年产鲜参16万吨,实现产值380多亿元.然而伴随着养殖快速发展和规模的日益扩大,技术条件低下、盲目养殖带来的危害也日趋严重,例如2013年度山东地区连续阴雨且连续高温,浒苔暴发面积大幅超越历史同期,对海参生长环境形成致命性破坏,导致山东地区海参尤其是虾池参大幅减产,山东地区海参减产幅度达到50%,全国减产30%.刺参养殖由于各种疾病的侵袭造成的直接经济损失达90亿元以上。”传统的文本分类的做法是在使用的预训练语言模型的输出层的embedding的cls位置后面接上分类器,并映射到这个文本分类任务的具体的多分类目标上分类上。这种分类器的方法需要从头开始训练一个新的mlp分类器,在低资源场景下,这个mlp分类器不一定能学到最好的参数,比较难获得好的效果。提示学习(英语:prompt learning)是使用预训练语言模型进行下游任务时常用的技术,是一种减小语言模型预训练任务和下游任务之间差异的手段,其通过将下游任务重塑为语言模型预训练任务中的完形填空任务来加强语言模型预训练阶段和下游任务阶段的参数共享,然后通过模板函数将模板与输入文本进行拼接,接着在训练时通过预训练语言模型预测[mask]位置的词,再通过标签词映射函数将[mask]位置的输出词汇映射到对应的文本分类输出类别上,例如这个例子的输出词是“水产”,具体对应水产养殖文本。
[0003]
目前,使用人工编写的自然语言提示进行语义理解任务,在小样本场景下表现提升。(timo schick,hinrich schutze,2021,it’s not just size that matters:small language models are also few-shot learners.)使用神经网络调优后得到的提示进行语义理解任务。(xiao liu,yanan zheng,zhengxiao du,ming ding,yujie qian,zhilin yang and jie tang.2021.gpt understands too.)在锁定语言模型参数的设定下通过调优前缀来进行语义理解任务(xiao liu,kaixuan ji,yicheng fu,weng lam tam,zhengxiao du,zhilin yang and jie tang.2021.p-tuning-v2:prompt tuning can be comparable to fine-tuning universally across scales and tasks.)。现有技术存在的问题:
[0004]
1、在文本翻译问题中,往往将文本输入到语言模型后,在语言模型的输出层外接分类器来完成文本分类任务。现有的文本分类方法需要使用新的分类损失函数来训练模型,无法很好地利用模型在预训练阶段学习到的一套参数。
[0005]
2、使用提示学习替代分类器学习可以提升模型在性能,并且仅需要少量的样本就可以达到与分类器接近的效果。但是目前的提示学习研究仅为整个数据集调优提示,没有
考虑到集中数据的差异,没有考虑为不同数据相应地调整提示。
技术实现要素:
[0006]
本发明的目的是提供一种基于提示学习的文本分类方法,其目标是解决用提示学习解决文本分类任务的过程中,提示与输入文本不匹配的问题,进一步提高文本分类模型的性能。
[0007]
本发明提供的技术方案如下;
[0008]
一种基于提示学习的文本分类方法,其步骤包括:
[0009]
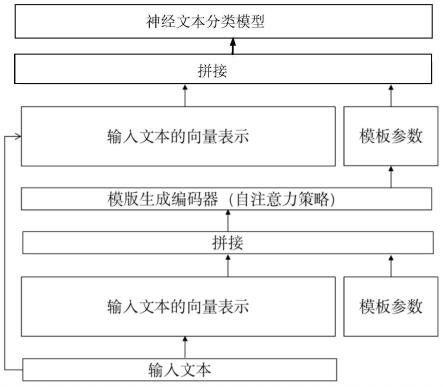
1)对于给定的文本包含一token的文本序列t,即t=t1,
…
,t
l
,获取输入文本序列t的向量表示e=e1,
…
,e
l
;
[0010]
2)使用可学习的提示参数p=p1,
…
,pm作为模板参数其中m是模板参数序列的长度,de是词向量的维度,把序列e和模板参数p拼接得到序列z=e1,
…
,e
l
,p1,
…
,pm,输入模板生成编码器;序列z按照如下公式更新:
[0011]
multihead(z,z,z)=concat(head1,
…
,headn)wo[0012][0013][0014]
其中softmax指的是softmax函数,z
t
指的是z的转置,dz指的是序列z的维度,attention(z,z,z)指的是针对z的自注意力更新,指用来对序列z进行线性变换的矩阵,headi指多头自注意力更新中的单个头的输出,concat指的是对n个head的输出矩阵进行拼接,wo指用来对n个head的输出的拼接结果进行线性转换的矩阵,multihead(z,z,z)指对z进行多头自注意力更新的输出,所述模板参数p会被更新;
[0015]
3)将序列z中更新后的模板参数p提取出来和未经过更新的输入文本的序列e重新拼接得到新的序列z
′
,输入神经文本分类模型,进行文本分类。
[0016]
使用bert-base、bert-large、roberta-base、roberta-large、gpt2-base和alberta-xxlarge-v2模型作为神经文本分类模型。
[0017]
模板生成编码器是一层attention结构,由位置编码和多头自注意力机制组成。
[0018]
本发明提出的基于提示学习的文本分类方法的有益效果在于:
[0019]
1、将文本分类任务重塑为语言模型预训练任务中的填空任务,减小了下游任务和预训练任务之间的差异,可以更好地利用语言模型预训练得到的参数;
[0020]
2、根据输入文本调优提示参数,为每条数据生成专属提示,使得提示生成过程能共享输入信息,提升模型效果。
附图说明
[0021]
图1为现有文本分类任务的示意图;
[0022]
图2为本发明流程图。
具体实施方式
[0023]
下面参照本发明的附图2,详细的描述出本发明的实施过程。
[0024]
1)使用bert-base、bert-large、roberta-base、roberta-large、gpt2-base和alberta-xxlarge-v2模型作为神经文本分类模型的基础模型。对于给定的文本序列t,输入是文本t的向量表示,即e=e1,
…
,e
l
。使用可学习的参数p=p1,
…
,pm,即作为提示的模板参数其中m是模板参数序列的长度,是超参数,而de是词向量的维度。
[0025]
2)训练时,把文本t的向量表示e和模板参数p拼接,得到序列z=e1,
…
,e
l
,p1,
…
,pm,输入到模板生成编码器。
[0026]
3)序列z在模板生成编码器中按照如下公式更新:
[0027]
multihead(z,z,z)=concat(head1,
…
,headn)wo[0028][0029][0030]
其中softmax指的是softmax函数,z
t
指的是z的转置,dz指的是序列z的维度,attention(z,z,z)指的是针对z的自注意力更新,w
iz
指用来对序列z进行线性变换的矩阵,headi指多头自注意力更新中的单个头的输出,concat指的是对n个head的输出矩阵进行拼接,wo指用来对n个head的输出的拼接结果进行线性转换的矩阵,multihead(z,z,z)指对z进行多头自注意力更新的输出。训练时模板参数p会被更新。
[0031]
使用单层attention结构作为提示生成模块。用adam作为优化器进行优化,学习率统一设置为5e-5。初始学习率为1e-7,在5000个warm-up更新布内线性增加到5e-5。权重衰减参数设置为1e-4,dropout设置为0.1
[0032]
4)预测时,将序列z中的更新后的参数p提取出来,再和未经过更新的输入文本t的向量表示e重新拼接,得到新的输入序列z
′
输入神经文本分类模型进行文本分类。
[0033]
模型共训练30epoch,选取在开发集上表现最好的checkpoint在测试集上进行测试,batch-size设置为16。
[0034]
实验结果:
[0035]
模型方法boolqcbrtewicwscmultircbert-base提示学习方法74.2891.0769.668.1565.5862.37bert-base本发明75.0292.8671.2669.7566.1563.51bert-large提示学习方法73.3887.1470.470.1967.8864.62bert-large本发明78.1892.1474.8770.2566.5463.77roberta-base提示学习方法78.5394.2977.9169.0669.6266.16roberta-base本发明79.4296.7981.370.2868.4666.18roberta-large提示学习方法83.9499.2984.8472.7671.9269.66roberta-large本发明83.8399.6487.8772.8870.9269.72
[0036]
评价指标:multirc为f1,其他任务为acc。
[0037]
模型方法boolqcbrtewicwscmultircalbert-xxlarge-v2提示学习方法61.7586.965,159.2565.0661.75
albert-xxlarge-v2本发明62.2294.0572.5658.166.0362.22
[0038]
上面描述的实施例并非用于限定本发明,任何本领域的技术人员,在不脱离本发明的精神和范围内,可做各种的变换和修改,因此本发明的保护范围视权利要求范围所界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1