一种基于个性扩展的对话生成方法
本发明涉及自然语言处理技术,尤其涉及一种基于个性扩展的对话生成方法。
背景技术:
1、传统的个性对话方法通常基于特定个性集合完成对话生成,但固定的预定义个性集合无法表示机器人的完整个性,在对话响应的生成过程中容易触发个性缺失问题。当前大多数研究工作基于深度循环神经网络和transformer等技术对预定义个性进行编码,尽管这些模型能够对预定义个性进行充分的语义理解,但固定的预定义个性无法覆盖所有类型的用户提问,具有明显的缺点。同时当前的工作只关注于以同等权重混合所有个性信息,忽略了实际个性对话生成过程中不同个性的作用存在差异,因此具有很大的局限性。
技术实现思路
1、本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种基于个性扩展的对话生成方法,该方法能有效提高对话生成结果的个性一致性。
2、本发明解决其技术问题所采用的技术方案是:一种基于个性扩展的对话生成方法,包括以下步骤:
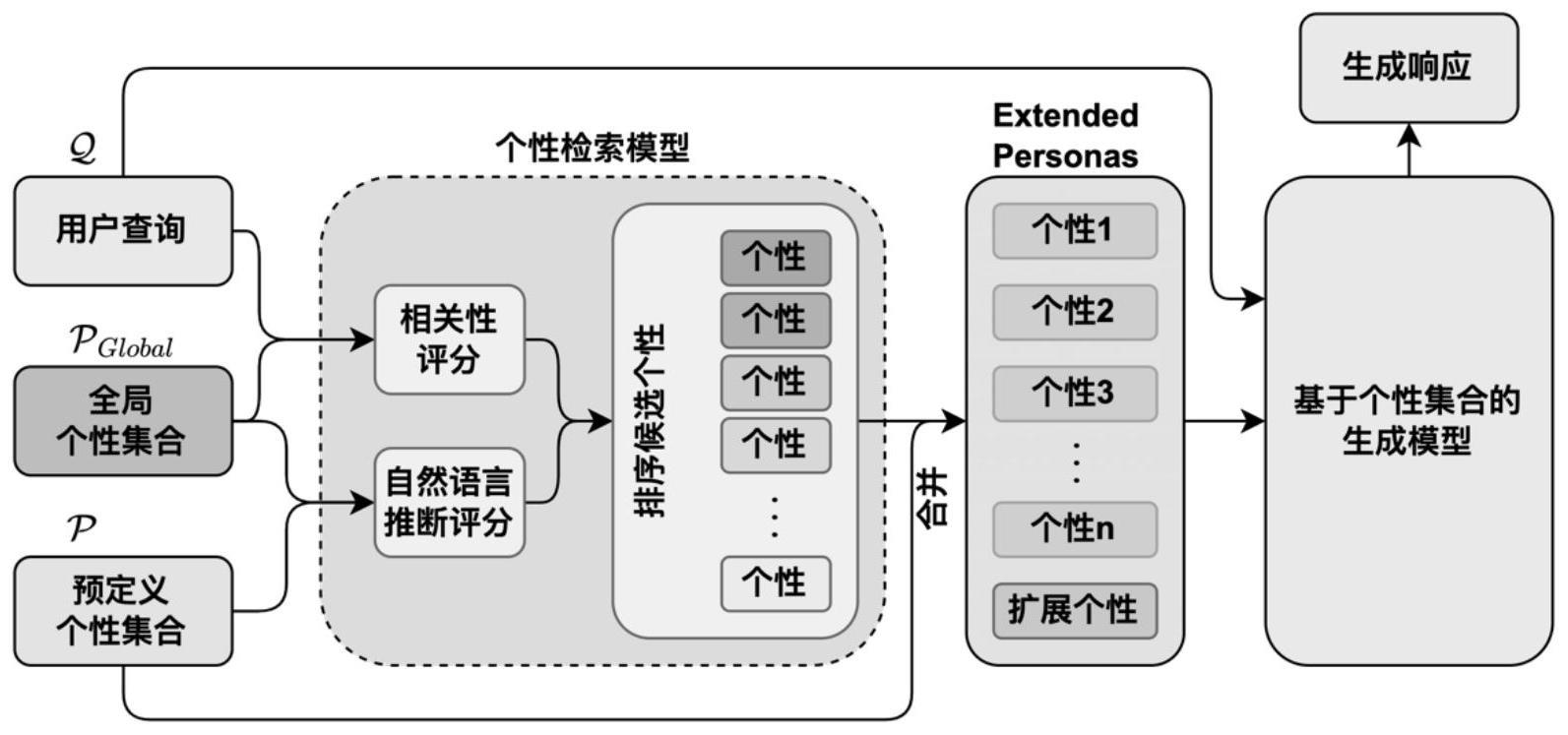
3、1)根据用户查询和预定义个性信息进行对话个性扩展;
4、给定一个查询和一组预定义个性其中每条个性可表示为一个句子
5、假设为一个全局角色集合,采用角色检索模型(persona retrievalmodel)对其中候选个性进行排序;
6、采用句对匹配模型来预测查询和候选个性之间的相关性,该二分类模型的置信度即所求相关性得分;
7、采用自然语言推断模型来评估候选个性与预定义个性集合的逻辑关联;
8、采用自然语言推断模型来评估候选与预定义个性集合的蕴含得分和冲突得分:
9、
10、
11、其中对于预定义个性集合中的不同个性,将候选个性与其依次比对,取最大值作为最终蕴含得分和冲突得分;
12、对于所有候选个性,依据联合得分s=α·r+β·(1-c)+γ·e对其进行排序,得分最高者即为扩展个性,其中α,β,γ均为可调节的超参数;
13、2)基于先后验网络构建个性集合的重要性分布模型,获得个性重要性分布;
14、先后验网络中,后验网络以用户查询、个性集合、目标响应作为输入,训练目标即判别每个个性信息是否在目标响应中被采用;先验网络以用户查询、个性集合作为输入,训练目标即对个性的判别结果与后验网络趋于一致;
15、采用gpt将用户查询、预定义个性、目标响应分别编码为句向量表征
16、其中,先后验网络中用于编码个性重要性的注意力网络定义如下:
17、
18、
19、其中,表示先验(pri)或后验(post)网络中每个个性的重要性;
20、采用前馈神经网络配合sigmoid激活函数,将它们转换为先验(pri)或后验(post)网络中每个个性的权重:
21、
22、其中,后验网络中损失函数通过交叉熵定义:
23、
24、由于最终所得个性分布可视为一个维度为个性数目的向量,定义先后验网络逼近时的损失函数如下:
25、
26、其中,cos表示先后验网络输出向量之间的cosine距离;
27、3)根据基于后验网络预测的个性重要性分布,使用加权后的个性信息进行响应解码;
28、采用加权方法对所有个性表征进行融合,在训练过程中,基于后验网络的预测结果进行个性融合:
29、
30、其中,np代表个性集合中的个性总数,代表t时刻下与已生成部分进行注意力交互后的第i条个性的表征;
31、采用mean pooling对于解码所需的用户查询、个性信息、已解码部分进行融合,然后利用gpt解码该时刻的响应单词rt:
32、
33、
34、从本质上讲,生成模型基于个性集和用户查询预测目标响应,因此,我们在训练期间应用了负对数逻辑损失:
35、
36、4)响应推断,生成查询的对话文本;
37、采用先验网络的个性重要性分布预测结果对后验网络进行替换,得到个性的整体加权编码为:
38、
39、以自回归的形式迭代生成响应单词,该过程可表示为:
40、
41、
42、其中,代表t时刻下已自回归生成部分响应的编码表征。
43、本发明产生的有益效果是:
44、1、通过评估个性候选与预定义个性在自然语言推断维度上的关联性,引入与预定义个性具有逻辑联系的新个性信息,通过先后验网络预测对话生成阶段中个性信息的重要性分布,通过结合加权后的个性信息,提高对话生成结果的个性一致性。
45、2、个性集合中不同个性对生成任务的贡献程度不同,通过先后验网络预测对话生成阶段中个性信息的重要性分布,并结合加权后的个性信息完成响应解码。
技术特征:
1.一种基于个性扩展的对话生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于个性扩展的对话生成方法,其特征在于,所述步骤1)中根据用户查询和预定义个性信息进行对话个性扩展,具体如下:
3.根据权利要求1所述的基于个性扩展的对话生成方法,其特征在于,所述步骤2)中,后验网络中损失函数通过交叉熵定义:
4.根据权利要求1所述的基于个性扩展的对话生成方法,其特征在于,所述步骤2)中,在训练期间采用负对数逻辑损失函数:
技术总结
本发明公开了一种基于个性扩展的对话生成方法,该方法包括以下步骤:1)根据用户查询和预定义个性信息进行对话个性扩展;2)基于先后验网络构建个性集合的重要性分布模型,获得个性重要性分布;3)根据基于后验网络预测的个性重要性分布,使用加权后的个性信息进行响应解码;4)响应推断,生成查询的对话文本。本发明提出的方法基于自然语言推断和先后验网络,能够更加准确地扩展出符合预定义个性的新个性信息,并且更加有效地学习到响应生成过程中个性集合的利用方式,从而提高对话生成的个性一致性。
技术研发人员:魏巍,刘逸帆,刘家邑,汤鑫,郑文俊
受保护的技术使用者:华中科技大学
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!