基于麻雀搜索算法和分解误差校正的短期空气质量预测方法
1.本发明涉及空气污染预测技术领域,特别是涉及一种基于麻雀搜索算法和分解误差校正的短期空气质量预测方法。
背景技术:
2.人类长期暴露在污染的空气中会导致健康受到影响。根据世界卫生组织(who)的研究,与空气污染接触相关的全球疾病负担对全世界的人类健康造成了巨大损失。据估计,空气污染造成的疾病负担与不健康饮食和吸烟等其他主要全球健康风险相当,空气污染现在被认为是对人类健康最大的环境威胁。因此,根据过去的空气质量数据预测未来的空气质量有着重大的研究意义。不仅体现在对空气污染情况的预警上,还体现在更好的规划和决策城市的发展方向,更好的保护人类的身体健康上。
3.目前关于空气质量预测的方法主要集中在对未来空气质量数据的预测准确度上,而忽略了预测误差和参数的简化,这会导致预测精度不高和运算时间长。
技术实现要素:
4.本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于麻雀搜索算法和分解误差校正的短期空气质量预测方法。
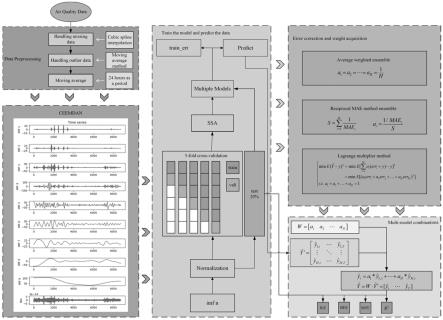
5.为了实现本发明的上述目的,本发明提供了一种基于麻雀搜索算法和分解误差校正的短期空气质量预测方法,包括以下步骤:
6.s1,使用ceemdan分解算法对数据进行分解,得到若干imf;
7.s2,使用深度学习模型对所述若干imf进行预测,对多个深度学习模型的预测误差进行处理,得到每个深度学习模型的权重;所述深度学习模型的数量至少两个;
8.s3,根据权重将每个深度学习模型的预测结果相结合,得到综合预测结果即多模型组合预测的结果。
9.进一步地,所述深度学习模型包括:lstm、bi-lstm、gru和bi-gru。
10.进一步地,s2包括以下步骤:
11.s2-1,使用不同的深度学习模型对所述若干imf进行预测,获得多个预测结果;同时,获得预测的数据和统计评价指标的值。
12.s2-2,采用简单平均法、mae倒数法和拉格朗日乘数法中的任一算法对各模型的预测误差进行处理,得到每个深度学习模型的权重;
13.当采用所述简单平均法时,每个模型的权重相等;
14.当采用所述mae倒数法时,每个模型的权重表示如下:
[0015][0016]
其中s表示h个模型的预测结果的mae的倒数之和,h为模型的总数量;
[0017]ai
表示第i个模型的权重;
[0018]
maei表示第i个模型的平均绝对误差;
[0019]
当采用拉格朗日乘数法时,每个模型的权重通过如下公式求解获得:
[0020][0021]
其中ai表示第i个模型的权重,i=(1,2,...,n);
[0022]
n为模型的总数量;
[0023]
表示对拉格朗日函数l(a,λ)中的a求偏导。
[0024]
s2-3,最后将各个深度学习模型的预测结果与权重相结合,产生多模型组合预测的结果。
[0025]
进一步地,在步骤s1前,对所述数据进行预处理,包括以下步骤:
[0026]
s0-1,使用三次样条插值来填补缺失的数值;
[0027]
s0-2,采用移动平均法来处理三次样条插值后的数据。
[0028]
对数据进行预处理不仅可以处理原始数据中的异常和缺失数据,还可以消除原始数据中的周期性和季节性因素的影响,从而提高预测的准确性。
[0029]
进一步地,所述深度学习模型是通过麻雀搜索算法训练获得,包括以下步骤:
[0030]
sa,将经过ceemdan分解的数据进行归一化,然后分级成以0到1之间的统计概率均匀分布;归一化操作不仅加快了神经网络的收敛速度,还消除了奇数样本数据造成的不良影响。
[0031]
sb,将经过分级的数据分为训练数据集和测试数据集;
[0032]
sc,使用麻雀搜索算法ssa优化深度学习模型的超参数,所述超参数包括神经网络每层的神经元数量、迭代次数和学习率;
[0033]
sd,采用深度学习模型对测试数据集进行预测,并根据评估指标进行评估,若模型的超参数没有发生过拟合且预测结果的误差最小则得到最优超参数,由此最优深度学习模型。若模型的超参数发生过拟合或不满足预测结果的误差最小则跳转步骤sc。
[0034]
通过麻雀搜索算法使模型能够自适应地确定深度学习模型的参数,从而不需要人工设置,从而实现了参数的简化。
[0035]
进一步地,所述评估指标包括:平均绝对误差、均方根误差、相关系数和平均绝对百分比误差中的任意组合。
[0036]
进一步地,在步骤s1之前包括s0,获取数据,该数据为气象数据。
[0037]
进一步地,所述数据为短期气象数据,采集时间为连续的24~72小时。
[0038]
综上所述,由于采用了上述技术方案,本发明通过将空气质量预测与时间序列分解相结合,且采用组合预测的方法,使用权重将各个模型的预测结果结合起来,由此可以得到精度更高的空气质量预测结果。
[0039]
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变
得明显,或通过本发明的实践了解到。
附图说明
[0040]
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
[0041]
图1是本发明的整体结构示意图。
[0042]
图2是lstm、bi-lstm、gru和bi-gru的网络结构示意图,图2(a)是lstm网络结构图,图2(b)是bilstm网络结构图,图2(c)是gru网络结构图,图2(d)是bi-gru网络结构。
[0043]
图3是具体实施例北京的空气质量指数数据和北京的监测站位置示意图,图3(a)是北京的空气质量指数数据;图3(b)是北京的监测站的位置。
[0044]
图4是本发明数据预处理的结果和处理时间序列的多步骤深度学习模型示意图,图4(a)是三次样条插值的部分结果图,4(b)是移动平均线法的结果图,图4(c)是用于处理时间序列的多步骤深度学习模型图,4(d)是使用移动平均法后在day 0到day 120的局部图。
[0045]
图5是具体实施例ceemdan的分解结果和归一化结果,图5(a)是ceemdan的分解结果,图5(b)是ceemdan分解结果进行归一化后的结果。
[0046]
图6是本发明不同深度神经模型上是否使用分解算法的结果示意图,图6(a)、图6(b)是使用分解算法前后模型的预测结果示意图,图6(c)是预测结果的误差示意图。
[0047]
图7是各个模型的统计指标和预测结果的变化示意图。
[0048]
图8是不同方法组合的预测结果示意图,图8(a)、图8(b)是不同方法组合的预测结果图,图8(c)是不同方法组合的预测误差的统计图。
[0049]
图9是采用不同组合方法的模型统计指标的变化示意图,图9(a)是合并“bg-g-bl-l”的模型的统计指标变化示意图,图9(b)是合并为“imf”的模型的统计指标变化示意图,图9(c)是合并为“ceemdan”的模型的统计指标变化示意图。
具体实施方式
[0050]
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
[0051]
本发明提出了一种基于麻雀搜索算法和分解误差校正的短期空气质量预测方法,如图1所示,包括以下步骤:
[0052]
s100:数据处理。
[0053]
s100-1,对数据进行预处理不仅可以处理原始数据中的异常和缺失数据,还可以消除原始数据中的周期性和季节性因素的影响,从而提高预测的准确性。所述预处理包括使用三次样条插值来填补缺失的数值;采用移动平均法来处理三次样条插值后的数据。
[0054]
s100-2,使用分解算法将预处理后的数据分解为有限数量的本征模函数imf。分解后的分量分别作为后续部分的数据使用。所述分解算法为带有自适应噪声的ceemdan。
[0055]
s200:训练模型并预测数据。
[0056]
s200-1,将imf归一化。使用归一化后,imf在0到1之间分布。归一化操作不仅加快
了神经网络的收敛速度,还消除了奇数样本数据造成的不良影响。
[0057]
s200-2,归一化后的imf被分为训练数据集和测试数据集。训练数据占了80%的数据。在训练集上使用五倍交叉验证进而得到一个可靠和稳定的模型。
[0058]
s200-3,使用麻雀搜索算法ssa和训练数据集训练深度学习模型(即神经网络lstm、bi-lstm、 gru和bi-gru)。使用麻雀搜索算法ssa优化神经网络的超参数,包括每层的神经元数量、迭代次数和学习率。这些超参数被用来获得当前的最优神经网络。之后,这个神经网络被用来对测试数据集进行预测,并根据评估指标进行评估。没有发生过拟合且预测结果的误差最小的模型的超参数就是最优超参数。
[0059]
s200-4,用最优超参数构建各个神经网络,用神经网络来预测数据集。同时,获得预测的数据和统计评价指标的值。
[0060]
s200-5,采用简单平均法、mae倒数法和拉格朗日乘数法对多模型进行纠错即误差校正,并获得各个深度学习模型的权值。
[0061]
s300,根据权重计算出多模型组合预测结果。将组合预测结果与未进行组合的预测结果进行比较和分析。
[0062]
所述四种深度学习模型为即lstm、bi-lstm、gru和bi-gru。
[0063]
长短时记忆网络(long short term memory network,lstm)是一种经过改进的循环神经网络(rnn),它是一种递进的rnn,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题,可用于时间序列的建模和预测。lstm单元的结构如下图2(a)所示。lstm由一个状态存储单元c
t
和三个逻辑门(输入门i
t
、输出门o
t
、遗忘门f
t
)组成,此外x
t
是lstm的输入,h
t
是lstm的输出。其中,表示矩阵元素相乘,表示矩阵相加。
[0064]ft
=σ(wf[h
t-1
,x
t
]+bf)
ꢀꢀꢀ
(1)
[0065]it
=σ(wi[h
t-1
,x
t
]+bi)
ꢀꢀꢀ
(2)
[0066]ct
′
=tanh(wc[h
t-1
,x
t
]+bc)
ꢀꢀꢀ
(3)
[0067]ct
=f
t
*c
t-1
+i
t
*c
t
′ꢀꢀꢀ
(4)
[0068]ot
=σ(wo[h
t-1
,x
t
]+bo)
ꢀꢀꢀ
(5)
[0069]ht
=o
t
*tanh(c
t
)(6)在公式(1)-(6)中,w为各个模块对应的权值矩阵,wf为遗忘门的权值矩阵,wi为输入门的权值矩阵,wo为输出门的权值矩阵,wc为tanh模块的权值矩阵。b表示各个模块对应偏误差,bf为遗忘门的偏误差,bi为输入门的偏误差,bo为输出门的偏误差,bc为tanh 模块的偏误差。[h
t-1
,x
t
]表示对h
t-1
,x
t
进行拼接,h
t-1
表示t-1时刻lstm的输出,x
t
表示t时刻lstm 的输入。σ为sigmoid激活函数,tanh为双曲正切函数。
[0070][0071][0072]
lstm中使用了状态存储单元c
t
使得可以更加有效地预测时间序列。当t时刻,lstm获取到上一单元的输出h
t-1
和新的输入x
t
时,首先遗忘控制门f
t
控制是否保留上一单元状态信息c
t-1
;输入门i
t
确定h
t-1
和x
t
中哪些内容能够用于这个单元状态的计算,减少无关内容;tanh模块通过h
t-1
和 x
t
生成新状态c
t
′
;然后更新状态信息,将这些结果组合得到当前的状态信息c
t
;最后输出门o
t
和当前的状态信息c
t
生成输出h
t
。
[0073]
双向的长短时记忆模型(bidirectional long short-term memory,bi-lstm)是一种特殊的lstm,包含一个前向lstm和一个后向lstm的双层网络。bi-lstm可以同时考虑数据的过去和未来信息。图2(b)显示了bi-lstm网络的结构。bi-lstm可以反向获得两个隐藏状态,并将这两个状态连接起来,获得相同的输出。前向lstm和后向lstm层可以重新获得输入序列的过去信息和未来信息。bi-lstm可以取得比lstm更好的预测结果。
[0074]
门控循环单元(gate recurrent unit,gru)是一种类似于lstm的循环神经网络(rnn),它使用门控机制来控制输入、记忆和其他信息,从而在当前时间步长进行预测,这解决了反向传播中长期记忆和梯度等问题。同时,gru比lstm相比最大的区别在于结构简单,只有两个门(用于更新状态的更新门和用于复位状态的复位门),而且gru中没有lstm的单元状态c
t
。一般来说, gru中的更新门控制过去的信息是否可以向后传递,而复位门控制过去信息被遗忘的程度。图2 (c)显示了gru网络的结构。
[0075]
公式(9)至公式(12)表示t时刻的gru单元的状态。
[0076]rt
=σ(wr[h
t-1
,x
t
]+br)
ꢀꢀꢀ
(9)
[0077]zt
=σ(wz[h
t-1
,x
t
]+bz)
ꢀꢀꢀ
(10)
[0078][0079][0080]
其中,r
t
表示重置门,z
t
表示更新门,x
t
表示t时刻的输入,h
t
表示t时刻的隐藏状态,表示 t时刻的部分状态信息,h
t
表示t时刻的状态信息,w代表权重,wr表示重置门权重、wz表示更新门权重、wh表示tanh模块中用于计算当前状态信息的权重;b代表输入门的偏置项,br表示重置门的偏置项、bz表示更新门的偏置项、bh表示tanh模块中的偏置项;σ(
·
)表示广泛用于神经网络工作的sigmoid激活函数;tanh(
·
)表示tanh激活函数。sigmoid和tanh函数都可以将数据值转换到一定的范围内,σ(x)和tanh(x)可以表示为公式(7)和公式(8)。
[0081]
双向门控循环单元(bidirectional gate recurrent unit,bi-gru)是一种特殊类型的gru,其结构与bi-lstm相似,由前向和后向传播的gru网络组成。图2(d)显示了bi-gru网络的结构。
[0082]
所述分解算法优选为带有自适应噪声的完全集合经验模式分解法(complete ensemble empiricalmode decomposition with adaptive noise,ceemdan),还可以采用emd算法、eemd算法,所述 emd算法即经验模态分解算法是将一个非平稳信号逐步分解为若干个本征模函数(imfs)和一个残差(res)。emd在处理非平稳和非线性数据方面有明显的优势,适合于分析非线性和非平稳信号序列。然而,emd受到末端效应和模态混叠的影响。因此,提出了eemd,eemd是在原始序列中加入白高斯噪声,使信号极点的分布更加均匀,有效地抑制了模态混叠。然而,eemd算法的计算量很大,在eemd中加入白噪声的振幅和迭代次数需要根据经验设定。因此,torres等人提出了带有自适应噪声的完全集合经验模式分解ceemdan。ceemdan不仅解决了emd中的模态混叠问题,而且通过自适应添加白噪声和设置迭代次数来降低计算成本,提高执行效率。
[0083]
ceemdan算法包括:假设y(t)是原始信号;vj(t)是满足标准正态分布的高斯白噪声信号;j 是加入白噪声的次数,j=1,2,...,n;ei(
·
)用emd分解第i个imf的函数;ii(t)是
emd分解得到的第i个成分;是ceemdan分解得到的第i个成分;ε是白噪声的振幅。ceemdan分解的步骤如下:
[0084]
第一步:在原始信号y(t)中加入高斯白噪声,得到一个新的信号之后,用emd对新信号进行分解,得到一阶分量i1(t)。其中res是表示残差;j是分解的数量。
[0085][0086][0087]
其中表示加入了j次白噪声得到的新信号;
[0088]
表示用emd算法分解加入j次白噪声后的信号表示用emd算法分解加入j次白噪声后的信号表示对加入了j次白噪声后使用emd分解得到的一阶分量;
[0089]
resj表示对加入了j次白噪声后使用emd分解得到的残差;
[0090]
第二步:n个分量的总体平均值产生了ceemdan分解的一阶分量去除分解的一阶分量后得到残差信号r1(t)。
[0091][0092][0093]
其中j是加入白噪声的次数,j=1,2,...,n;
[0094]
第三步:在残差信号r1(t)中加入高斯白噪声,得到一个新的残差信号之后,用emd对新残差信号进行分解,得到二阶分量i2(t)。
[0095][0096][0097]
其中ε是白噪声的振幅;
[0098]
e1[vj(t)]表示用emd分解加入j次的高斯白噪声信号vj(t);
[0099]
第四步:重复第二步,得到ceemdan的二阶分量和分解后的残差r2(t)。
[0100]
第五步:重复上述步骤,直到得到的残差信号rk(t)是一个无法进一步分解的单调函数,则算法结束。这时,ceemdan的分解结果中的第k阶分量可以用下面的式子表示。
[0101][0102][0103]
其中j是加入白噪声的次数,j=1,2,...,n;
[0104]
此时,ceemdan的残余信号可以表示为:
[0105]
[0106]
ceemdan分解的结果可以表示为:
[0107][0108]
所述麻雀搜索算法(sparrow search algorithm,ssa)是一个受麻雀的蜂群智能、觅食和反捕食行为启发的蜂群智能优化模型,由xue j和shen b在2020年提出。ssa描述了麻雀种群中两种类型的麻雀行为。一种麻雀被称为生产者(producer),它的主要任务是寻找食物,所以它倾向于飞往食物丰富的地方。另一种麻雀被称为蹭食者(scrounger),它不断选择并跟随最好的生产者寻找食物。
[0109]
生产者(scrounger)如果在觅食时发现捕食者,就会发出报警信号。当报警信号超过某个阈值时,生产者的位置就会被更新,具体如下:
[0110][0111]
其中,表示第i只(i=1,2,
…
,n,n表示麻雀的数量)麻雀在第j个(j=1,2,
…
,m,m表示待优化的参数数量)待优化参数的第t次(t=1,2,
…
,p,p表示最大迭代次数)迭代时的位置值。α和q是随机数,区别在于q遵循正态分布,而α的值在0和1之间。w和s分别代表报警值和安全阈值。c代表一个有m行的列矩阵,每行的值为1。
[0112]
蹭饭者(scrounger)的位置与生产者有关,其位置的计算方法如下所示:
[0113][0114]
其中,表示生产者在第t+1次迭代时在麻雀中的最佳位置;表示生产者在第t次迭代时在麻雀中的最差位置,|
·
|为绝对值符号。a
′
=a
t
(aa
t
)-1
,a代表一个有m行的列矩阵,每一行的值为1或-1。
[0115]
处于边缘的麻雀即位于所有麻雀外围,身份不定的麻雀在遇到危险时向中间移动,此时的位置更新如下:
[0116][0117]
其中表示第t次迭代时麻雀中生产者的全局最优位置;β和k是随机数,区别在于β是正态分布,平均值为0,标准差为1,而k控制麻雀具体运动的方向和步长,其取值范围在-1到1之间;λ是一个非常小的数字,以保证分母不为零;fi,fg和fw分别表示第i个麻雀、最佳麻雀和最差麻雀的值。算法结束迭代时麻雀的最佳位置表示需要搜索查询的参数的最佳值。
[0118]
所述s200-5包括:使用不同的神经网络对分解后若干imf行单独预测,并按单个imf输入网络;以获得多个预测结果。之后,对多个神经网络的预测误差进行处理,得到每个
预测模型的权重。最后将各个神经网络的预测结果与权重相结合,产生多模型组合预测的结果。
[0119]
在公式(26)和(27)中,y
t
表示t时刻多模型的组合预测结果;代表在t时刻时,第h个模型的预测结果;ai表示第i个模型的权重,ξ表示多模型组合的误差。
[0120][0121][0122]
其中f(
·
)表示通过某种方式对多模型的预测结果进行组合。
[0123]
若预测结果的时间范围为t
′
~t
′
+t,则多模型的组合预测结果y
t
与真实值y
t
之间的均方误差(mean-square error,mse)可以表示为:
[0124][0125]yt
表示t时刻的真实值;表示多模型的组合预测结果;y表示真实值;
[0126]
在本文中,考虑了以下三种组合预测方法:
[0127]
(1)简单平均组合法
[0128]
最终的多模型组合预测是多个模型预测的平均值,其中ξ表示多模型组合的误差。
[0129][0130]
表示第i个模型t时刻的预测值;
[0131]
ξ表示多模型组合的误差;
[0132]
(2)mae倒数组合法
[0133]
多模型组合预测中每个模型的权重可以通过平均绝对误差(mae)的倒数来确定。计算权重的公式如下:
[0134][0135][0136]
其中s表示h个模型的预测结果的平均绝对误差(mae)的倒数之和;
[0137]ai
表示第i个模型的权重,
[0138]
第i个模型的平均绝对误差用maei表示,公式(27)显示了最终多模型综合预测结果的计算方法。
[0139]
(3)基于拉格朗日乘数法的组合法
[0140]
拉格朗日乘数法是一种在一组约束条件下寻找多变量函数极值的方法。在这一部分中,第i个模型的权重ai被重新视为待解的变量,约束条件为如公式(32)所示。
[0141][0142]
随着误差的引入,这可以表示为:
[0143][0144][0145]
其中,表示多模型的组合预测结果与真实值均方误差(mse)的最小值,见式(28);
[0146]
是第i个模型的预测值;y表示真实值;erri表示第i个模型的误差。
[0147]
之后,在引入拉格朗日乘数后,有约束的优化问题被转化为无约束的优化问题。
[0148]
l(a,λ)=e[(a1err1+a2err2+...+anerrn)2]+λ(a1+a2+
…
+a
n-1)
ꢀꢀꢀ
(35)
[0149]
其中l(a,λ)表示拉格朗日函数;a为待求的量,λ为拉格朗日乘子;
[0150]
e[]表示期望;
[0151]
引入karush-kuhn-tucker(ktt)条件:
[0152][0153]
组合权重可通过公式(36)求解。
[0154]
具体实施例如下:
[0155]
首先采集数据:采用了北京地区2021年1月1日至2021年12月31日共8695个小时的空气质量指数(aqi)数据(图3(a)为北京地区的aqi数据;表1列出了aqi数据的统计特征),这些数据由北京24个空气监测站测得(图3(b)显示了定陵、东四、天坛、海淀万柳、怀柔镇、昌平镇等监测站的位置),并由中国环境监测总站(gems)在国家城市空气质量实时发布平台 (https://air.cnemc.cn:18007/)上发布。
[0156]
北京市总面积为16,410.54平方公里,位于华北平原北部,背靠燕山山脉。北京及其周边地区有大量高能耗、高污染的重工业企业,如电力、冶金、化工等行业。就北京本地的污染源而言,过去的主要污染源是机动车和燃煤。事实上,随着近年来的环境治理和产业结构调整,机动车尾气污染已经成为主要的污染物来源,而燃煤等工业污染源的比例逐渐下降。
[0157]
在表1显示,北京地区的aqi数据中共有65个缺失值,数据中的最大值为500,达到了aqi 定义中的极限。为了减少数据中的缺失值和异常值对后续预测的影响,有必要对数
据进行预处理,从而提高预测精度。
[0158]
空气质量指数(aqi)是对空气质量的定量描述,它可以说明空气的清洁或污染程度以及空气污染对健康的影响,其计算公式如下:
[0159]
aqi=max{iaqi1,iaqi2,
…
,iaqin}
ꢀꢀꢀ
(37)
[0160][0161]
其中,n为污染物项目;iaqi
p
为污染物项目p的iaqi。单项污染物的空气质量指数(iaqi) 代表污染物的空气质量指数。在公式(38)中,c
p
代表污染物项目p的质量浓度值;bph和bp
l
分别代表污染物项目p的质量浓度的最高限值和最低限值;iaqih和iaqi
l
分别代表对应于bph和bp
l
的空气质量分指数。
[0162]
然后对数据进行预处理:使用三次样条插值来填补缺失的数值。图4(a)是立方样条插值的部分结果(2021-01-01 00:00至2021-01-02 23:00)。
[0163]
之后采用移动平均法来处理三次样条插值后的数据。它不仅可以消除时间序列中的不规则变化和其他变化,而且可以揭示时间序列的长期趋势,提高预测精度。时间序列y=(y1,y2,
…
,y
t
)的移动平均数的计算公式为:
[0164][0165]
其中g代表移动平均数项的数量,且g《t,设y1为day 0的aqi值,则最后一天的值为 day 8736。
[0166]
图4(b)和4(d)显示了当g=24时使用移动平均法的结果。表1显示了原始数据经过上述操作后的结果的统计特征。
[0167]
表1数据的统计描述
[0168]
datacountmeanstdmin25%50%75%maxmissingoriginal869563.2053.91731517050065preprocessed873763.0646.599.8234.2949.1771.17366.080
[0169]
另外,在训练模型之前要对数据进行划分。训练集占80%,测试集占20%。在图4(c)中,x
t
表示t时刻的aqi值,是输入值;y
t+1
表示t+1时刻(下一时刻)的aqi值,是输出值;t表示周期, t=24表示用连续24小时的aqi值预测未来的aqi值。让训练数据集的第一天为day 0,测试数据集的最后一天为day 8712。
[0170]
再对模型的预测结果进行评价:为了确定哪个模型的预测效果更好,对所提出的模型的预测效果使用以下几个评估指标进行评定:平均绝对误差(mean absolute error,mae)、均方根误差(root
ꢀꢀ
mean squared error,rmse)、相关系数(coefficient of determination,r2)和平均绝对百分比误差 (mean absolute percentage error,mape).它们的定义如下:
[0171][0172]
[0173][0174][0175]
其中,是预测值;y=(y1,y2,
…
,yn)是真实值。
[0176]
平均绝对误差(mae)表示预测值和观测值之间绝对误差的平均值,其范围为[0,+∞),mae 越小表示模型的预测效果越好
[0177]
均方根误差(rmse)是回归模型的典型指标,用于表明实际数据与模型的预测数据之间的差异,其范围为[0,+∞),rmse越小表示模型的预测效果越好。
[0178]
r2指相关系数,可用来衡量回归问题的拟合程度。r2越接近1表示模型的预测效果越好
[0179]
平均绝对百分比误差(mape)是一个相对指标。如果mape=0%,建议的模型是完美的,如果mape》100%,则意味着模型的预测效果很差。
[0180]
与此同时,若模型的预测效果更好,则模型的参数也更优秀。
[0181]
最后对实验结果进行了分析和比较:实验由两部分组成,第一部分实验首先使用lstm、 bi-lstm、gru和bi-gru模型预测aqi值,之后使用ceemdan分解算法分解的数据作为训练数据,依次使用上述模型进行预测。最后,对它们的预测结果进行了比较。在第二部分的实验中,组合权重分别由简单平均法、mae倒数法和拉格朗日乘数法获得。其次,根据权重对四个深度学习模型的预测结果进行组合。最后,分别比较三个组合的预测结果,并将这些预测结果与第一部分的结果进行比较。
[0182]
(1)ceemdan的分解结果
[0183]
图5(a)是ceemdan的分解结果,图5(b)是ceemdan分解成分的归一化结果。在下文中,归一化的ceemdan分解成分(imf)被作为数据使用。
[0184]
随后的实验过程与不使用ceemdan分解算法时类似,使用训练数据集结合ssa优化算法,分别训练上述四个深度学习模型,得到最优的深度学习网络模型。结合ceemdan分解算法、ssa 优化算法和深度学习模型的预测结果见表2和图6。
[0185]
表2不同评价指标上gru、bi-gru、lstm和bi-lstm的预测结果
[0186][0187][0188]
图6(a)显示了四个最好的深度学习模型在使用和不使用ceemdan分解算法的情况下的预测结果,图6(b)中显示了重新结果的散点图。图6(c)中的误差符号表示预测的数据相对于原始数据的大小。当误差为正时,表示预测结果大于原始数据,反之,表示预测结果
小于原始数据。
[0189]
从图6可以看出,ssa-gru和ssa-bi-gru的预测结果分布在原始数据的两边。同时, ssa-bi-gru的预测误差比ssa-gru的小。ssa-lstm和ssa-bi-lstm的预测结果大多比原始数据小。ceemdan分解算法也大大减少了预测值。它使大部分的预测值小于原始数据。然而, ssa-bi-gru-ceemdan的结果都集中在原始数据周围。可以推断出,ssa-bi-gru-ceemdan 有更好的预测结果。图6(c)证明了这一推断。ssa-bi-gru-ceemdan的绝大部分误差都分布在0 左右。
[0190]
图7显示了上述模型的预测结果的统计评价指标的演变。结合表2和图7可以得出结论:使用 ceemdan分解算法对数据进行分解后,模型的预测结果有所改善,rmse平均降低11.245%, r2平均增加0.866%,mae平均降低8.165%。特别是,使用ceemdan分解模型后,ssa-bi-gru 模型取得了最佳预测结果。它的rmse和mae最小,r2在所有模型中最大,而其rmse和mae 分别为4.810319和3.657710,减少了14.356206%和12.123751%。其r2从0.978011增加到0.983518,其maep保持在0.06%左右。
[0191]
(2)误差纠错与权值获取
[0192]
在实验中,多模型的组合权重是通过简单平均法、mae倒数法和拉格朗日乘数法的整合重新得到的。
[0193]
图8显示了多模型组合的预测结果。每张图从左到右显示了"bg-g-bl-l"方法、"imf"方法和 "ceemdan"方法的结果。图例中的"bg-g-bl-l"表示在没有ceemdan分解的情况下组合四个深度学习模型的结果,如公式(47)所示。图例中的"imf"表示四个深度学习网络预测的imf成分首先被合并,然后合并到最终的预测中,如公式(48)和(49)所示。图例中的"ceemdan"表示每个深度学习网络预测的imf成分首先被合并,然后合并到最终的预测中,如公式(50)所示。
[0194]wbg_g_bl_l
=[w
bg
,wg,w
bl
,w
l
]
ꢀꢀꢀ
(44)
[0195][0196]wceemdan
=[w
bg
,wg,w
bl
,w
l
]
ꢀꢀꢀ
(46)
[0197][0198]
[0199][0200][0201]
式中y表示多模型的组合预测结果;yi表示第i个(i=1,2,
…
,n)imf分量的组合预测结果; y
i,j
表示第i个imf分量通过模型j(j=bi_gru,gru,bi_lstm,lstm)预测的结果;yj表示第j个模型的预测结果;w
bg_g_bl_l
、w
imf
、和w
ceemdan
表示权重。通过这些方法得到的组合预测模型如下所示:
[0202]
a.简单平均法
[0203]
由"bg-g-bl-l"、"imf"和"ceemdan"代表的组合模型的权重分别见公式(51)、公式(52)、公式(53)。
[0204][0205][0206][0207]
b.mae倒数法
[0208]
由"bg-g-bl-l"、"imf"和"ceemdan"代表的组合模型的权重分别见公式(54)、公式(55)、公式(56)。
[0209]wbg_g_bl_l
=[0.3266 0.2752 0.2153 0.1829]
ꢀꢀꢀ
(54)
[0210][0211]wceemdan
=[0.3077 0.2662 0.2464 0.1797]
ꢀꢀꢀ
(56)
[0212]
c.拉格朗日乘数法
[0213]
由"bg-g-bl-l"、"imf"和"ceemdan"代表的组合模型的权重分别见公式(57)、公式(58)、公式(59)。
[0214]wbg_g_bl_l
=[4.2063
ꢀ‑
2.7239
ꢀ‑
0.9561 0.4737]
ꢀꢀꢀ
(57)
[0215][0216]wceemdan
=[0.9193 0.0673
ꢀ‑
0.0035 0.0169]
ꢀꢀꢀ
(59)
[0217]
图8显示,使用拉格朗日乘数法的组合预测结果优于mae倒数法和简单平均法的组合预测结果。图8(b)清楚地显示,在最右边的使用拉格朗日乘数法的多模型组合预测结果与紧密分布在原始数据两边。图8(c)显示,使用多模型组合后的预测误差都集中在0左右,只有很低比例的误差绝对值大于10。这个比例也比图6(c)中的比例小得多。这表明多模型组合的预测结果要比单一模型的预测结果高得多。从表3中的数值来看,当模型以同样的方式组合时,在获得权重后,使用拉格朗日乘数法对多模型组合进行预测,可以获得最佳预测结果。这样的结论也可以从图9 中得出。
[0218]
表3组合模型预测的评价指标
[0219][0220][0221]
在表3中,以模型组合方法"imf"(见上文对模型组合方法的解释)的预测结果的统计指标为例。使用简单的平均法获得权重,得到组合模型的最终预测结果,其内在指标rmse、r2、mae 和mape的值分别为6.256345、0.972717、5.499121和0.102130。同时,采用mae反演法得到的组合模型的指标rmse、r2、mae和mape的值分别为5.880983、0.975893、5.294846和0.104462,反之,使用拉格朗日乘法获得权重的组合模型的指标rmse、r2、mae和mape的值分别为rmse、 r2、mae和mape为4.784601、0.984043、3.674884和0.079240。对于rmse来说,它改变了-5.999701%和-18.642836%;r2改变了1.183331%和0.835132%;mae改变了-3.714685%和-30.595073%;mape 改变了2.283364%和-24.144665%。同时,在使
用拉格朗日乘数法获得权重后,使用其他模型组合得到的预测结果也有明显改善。
[0222]
在表2中,使用ceemdan去分解算法对数据进行分解,然后使用深度学习模型进行预测的最佳结果是ssa-bi-gru-ceemdan,rmse和r2分别为4.810319和0.983518。直接使用深度学习模型进行预测的最佳结果是ssa-bi-gru,rmse和r2分别为5.616658和0.978011。然而,结合表3的结果,通过使用ceemdan去组合算法,利用拉格朗日乘法的整合,将多个深度学习模型组合起来,得到的最佳预测的rmse为4.764355,减少了0.955529%,r2为0.984178,增加了 0.067106%。使用该方法结合多个直接使用的深度学习模型得到的预测的rmse为3.858319,减少了31.305787%,r2为0.989624,增加了1.187410%。
[0223]
综上所述:(1)用gru、bi-gru、lstm和bi-lstm来预测未分解的数据和ceemadn分解的数据。结果表明,ceemdan分解算法可以提高预测效果,具体来说,平均rmse降低11.245%,平均r2增加0.866%,平均mae降低8.165%。
[0224]
(2)设计了一种基于拉格朗日乘数法的多模型组合方法,该方法可以获得各个深度学习模型的权重,并且该权重可以组合多个模型。多模型组合的结果比单一模型的结果要好。
[0225]
(3)拉格朗日乘法与简单平均组合模型和mae逆向组合模型进行比较。实验结果表明,使用拉格朗日乘数法得到的结果要比其他两种方法好。
[0226]
本文提出的一个采用麻雀搜索算法和分解误差修正的多模型简化组合的短期空气质量预报模型,用这种解析型组合模型来预示空气质量。一方面,使用ceemdan分解算法对数据进行分解,然后使用深度学习模型进行预测,可以得到更好的结果。另一方面,这种组合模型比使用单一模型的预测结果有明显的改善。同时,它的预测结果也比其他传统的组合方法要好。
[0227]
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1