一种自顶向下和自底向上相结合的复杂表结构识别方法
本发明涉及文档分析和计算机视觉。特别是涉及一种自顶向下和自底向上相结合的复杂表结构识别方法。
背景技术:
1、由于风格和结构的多样性,表结构识别是一项具有挑战性的任务。近年来,在表格识别相关竞赛的推动下,表结构识别已经取得了出色的性能,但仍有一些方面需要改进,如更好地处理跨越关系复杂的表格。
2、根据问题处理之初选择的粒度元素不同,将基于深度学习的表结构识别方法归纳为三类:自顶向下的方法、自底向上的方法以及自然语言处理的方法。自顶向下的方法试图预测表格的行列区域或行列分隔符,然后通过启发式规则或序列模型合并行列跨度大于一的过度分割区域。尽管利用序列模型进行合并的效果很好,但当表格单元数量非常多时,会带来较大的计算成本且无法并行计算。自底向上的方法是指从检测文本块或单元格的位置开始,再通过启发式规则或图模型恢复边框的关系。这种方法大多忽略了空单元格,并且容易受到局部噪声的干扰。自然语言处理的方法则是将表结构识别定义为标记序列识别问题,它们尝试通过循环神经网络或transformer作为语言模型,将表格图像直接翻译成html或latex代码。由于自回归模型本身的误差积累,这类方法通常会出现回归边框漂移的问题,需要依赖复杂的后处理进行边框匹配。而且受网络中线性层的限制,模型只能接收固定大小的输入,过度的下采样导致对大表的识别效果差。
3、综上所述,现有的表结构识别方法仍然有以下几个方面需要改进:1、单元格定位不准确;2、无法平衡速度和性能。简单的启发式规则无法处理复杂的合并关系,而序列模型虽然能很好地识别合并关系,但是计算复杂度较高;3、大表格识别效果差。
技术实现思路
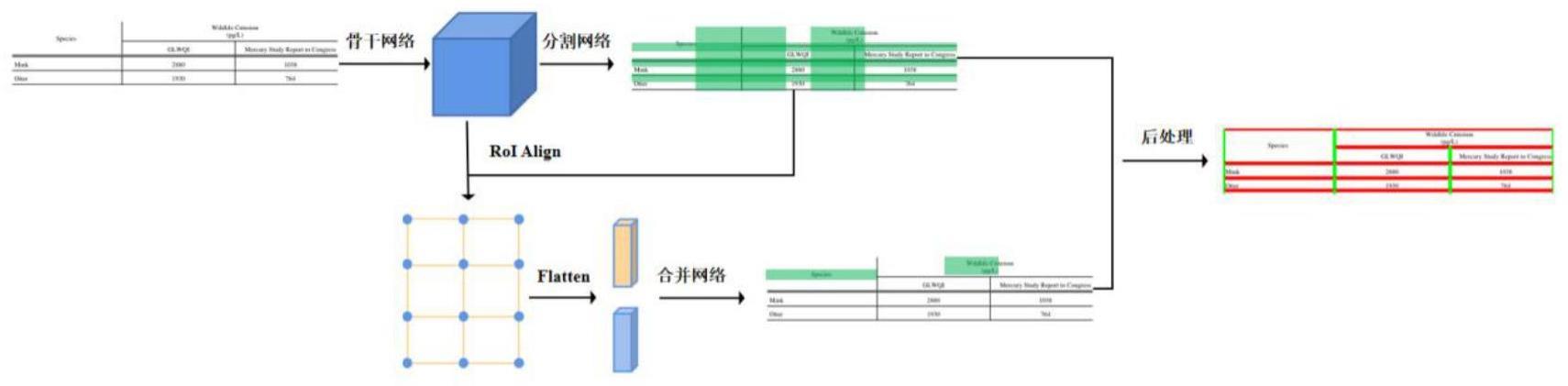
1、本发明针对现有的表结构识别方法存在的单元格定位不准确、单元合并方法计算成本高、大表识别性能差等缺点,设计了一种有效的方法来识别具有复杂跨越关系的表格结构。该发明主要包括两个部分:1、自顶向下:将表格图像分解成基本的网格单元,这些网格单元由拆分模型预测的行列分隔符进行划分;2、自底向上:图合并模型预测在水平和垂直方向上相邻的网格单元间的合并关系。具体步骤如下:
2、(1)图像尺寸处理。本发明中,输入表格图像的最长边限制为842像素,即分辨率为72像素/英寸的a4纸像素的长度。
3、(2)获得图像的特征表示。将尺寸为3×h×w的表格图像送入全卷积网络中进行特征提取,得到形状为c×h×w的三维张量,作为表格图像的特征表示。
4、(3)自顶向下的网格检测。本发明将多分支感受野块和空间注意力机制引入网格检测中,多分支感受野块通过模拟人类视觉的感受野来加强网络的特征提取能力,空间注意力机制用于学习特征的空间相关性,从而提升网格检测的精度。具体可进一步划分为以下三个步骤:
5、(3.1)行分隔符检测。首先将步骤(2)中得到的三维张量送入多分支感受野块。然后为输出的特征图计算空间注意力系数矩阵,并用注意力矩阵对输出特征图进行加权。最后,为了将二维问题转为一维问题,对加权后的特征图进行投影池化和激活,得到行分隔符预测向量,记作h×1。
6、(3.2)列分隔符检测。除投影池化在列的维度外,其余均与(3.1)相同。这里将列分隔符预测向量记作1×w。
7、(3.3)后处理。对行和列的分隔符预测向量分别进行二值化,并进行一些轻量级后处理,得到m个行分隔符段和n个列分隔符段,从而将表格图像划分成m×n的网格。
8、(4)自底向上的网格合并关系预测。本发明提出了一种基于图注意力网络的网格合并关系预测方法。该方法以网格单元为顶点,在水平和垂直方向上对相邻网格单元间采样边,并通过若干个图注意力块使得顶点和顶点、顶点和边、边和边之间进行信息交互,显著提升了合并关系预测的精度。它可以进一步划分为以下五个步骤:
9、(4.1)初始图的构建。在拆分模型输出的网格上构建一个无向图g=(v,e),其中v中的每个顶点表示一个基本网格单元,e是顶点之间的边的集合。除边界顶点外,每个顶点在水平和垂直方向上都有4个相邻的顶点。若两个相邻网格单元间需要合并,对应边的值为1,否则为0。
10、(4.2)获取顶点和边的特征。对每个顶点和边,采用roi align从步骤(2)中得到的表格图像的特征表示中提取r×r固定大小的特征图作为顶点和边的视觉特征,形状为c×3×3。
11、(4.3)线性变换。将c×3×3的三维特征图展平为一维特征向量,并对其进行线性变换,以降低特征向量的维度。
12、(4.4)关系预测。将步骤(4.3)中得到的节点的边的特征向量送入图注意力网络中进行边的分类,得到边的预测向量,记作|e|×1。
13、(4.5)后处理。将边预测向量二值化,并结合网格预测结果以恢复完整的表结构。
14、(5)表结构识别测试。计算ground truth和预测表结构之间的准确率、召回率和f1分数。
15、与现有的表结构识别方法相比,本发明的优点在于:
16、(1)本发明将表结构识别划分成了自顶向下的网格检测和自底向上的网格合并两个子任务,首次将网格合并问题视为图的边预测问题。与在文本块或单元格上运用图模型相比,本方法边的总数可以由o(kmn)减少到o(2mn-m-n),显著降低了计算复杂度,并且可以精准定位空单元格。而相比序列模型,本发明不限制输入表格图像的尺寸,对于大表也具备较好的识别精度,更具灵活性。
17、(2)本发明将多分支感受野块和空间注意力机制引入网格检测,引导网络关注表格图像中的关键辨识区域,有效提升了网格检测的精度。
18、(3)本发明在分隔符检测阶段同时考虑了表格与外界的边界分隔符和行或列之间的内容分隔符。由于边界分隔符和内容分隔符具有相似的特征,边界分隔符的加入可降低模型的学习难度。
技术特征:
1.一种复杂表结构识别方法,包括自顶向下的网格检测和自底向上的网格合并。
2.如权利要求1所述的表结构识别方法,其特征在于多分支感受野和注意力机制。
3.如权利要求1所述的表结构识别方法,其特征在于所述的分隔符包含内容分隔符和边界分隔符。
4.如权利要求1所述的表结构识别方法,其特征在于所述的网格合并方法是由图神经网络建模。
技术总结
本发明公开了一种复杂表结构识别方法,包括自顶向下的网格检测和自底向上的网格合并。方法由骨干网络、分割网络、RoIAlign和图注意力网络四个部分组成。表结构识别是文档自动化的核心问题,现有的表结构识别方法普遍存在对大表识别效果差、推理速度慢等问题。本发明通过卷积神经网络提取任意尺寸表格图像的特征;图注意力网络使得网格的合并变得高效简单;边界分隔符的引入有效降低了模型学习的难度。
技术研发人员:林红利,陈佩佩
受保护的技术使用者:湖南大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!