模型训练方法、装置及设备与流程
1.本技术涉及计算机视觉技术领域,尤其涉及一种模型训练方法、装置及设备。
背景技术:
2.在一些场景中,可以通过模型对输入的文本短语进行处理,以在多个图像中识别出文本短语指定的目标对象。
3.在相关技术中,可以通过样本图像和样本文本对模型进行训练,以得到模型。然而,在上述训练过程中,通常是通过模型分别对样本图像和样本文本进行处理,导致模型确定目标对象的准确性低。
技术实现要素:
4.本技术的多个方面提供一种模型训练方法、装置及设备,用以提高模型确定目标对象的准确性。
5.第一方面,本技术实施例提供一种模型训练方法,包括:
6.获取样本数据,所述样本数据中包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象,所述标注对象为所述样本图像中与所述样本文本相似度最高的对象;
7.确定初始模型,所述初始模型中包括n个融合层和映射层,所述融合层包括图像编码器、图像注意力层、文本编码器和文本注意力层,所述图像注意力层和所述文本注意力层分别用于融合所述图像编码器和所述文本编码器输出的特征,所述n为正整数;
8.通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,所述预测对象与所述样本文本相似度最高;
9.根据所述预测对象和所述标注对象,更新所述初始模型的模型参数。
10.在一种可能的实施方式中,通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,包括:
11.通过所述n个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征;
12.通过所述映射层对所述融合图像特征和所述融合文本特征进行处理,以确定所述预测对象。
13.在一种可能的实施方式中,所述n为大于1的整数;通过至少一个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征,包括:
14.通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;
15.通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,所述i依次取2、3、
……
、n,并将第n个中间图像特征确定为所述融合图像特征,以及将所述第n个中间文本特征确定为所述融
合文本特征。
16.在一种可能的实施方式中,通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征,包括:
17.通过所述第1个融合层中的图像编码器对所述样本图像特征进行处理,得到第一编码图像特征;
18.通过所述第1个融合层中的文本编码器对所述样本文本特征进行处理,得到第一编码文本特征;
19.通过所述第1个融合层中图像注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间图像特征;
20.通过所述第1个融合层中文本注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间文本特征。
21.在一种可能的实施方式中,通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征之前,还包括:
22.在所述样本图像特征中去除部分图像特征;和/或,
23.在所述样本文本特征中去除部分文本特征。
24.在一种可能的实施方式中,通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征,包括:
25.通过所述第i个融合层中的图像编码器对所述第i-1个中间图像特征进行处理,得到第i编码图像特征;
26.通过所述第i个融合层中的文本编码器对所述第i-1个中间文本特征进行处理,得到第i编码文本特征;
27.通过所述第i个融合层中的图像注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间图像特征;
28.通过所述第i个融合层中的文本注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间文本特征。
29.在一种可能的实施方式中,获取样本数据,包括:
30.获取所述样本图像和所述样本文本;
31.通过第一模型对所述样本图像进行处理,得到所述样本图像特征;
32.通过第二模型对所述样本文本进行处理,得到所述样本文本特征
33.根据所述样本文本对所述样本图像中的对象进行标注处理,以确定所述标注对象。
34.在一种可能的实施方式中,通过第一模型对所述样本图像进行处理,得到所述样本图像特征,包括:
35.通过所述第一模型在所述样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;
36.根据所述样本图像中的多个对象、以及各对象的对象类别,生成所述样本图像特征。
37.在一种可能的实施方式中,根据所述预测对象和所述标注对象,更新所述初始模型的模型参数,包括:
38.根据所述预测对象和所述标注对象,确定损失函数;
39.根据所述损失函数,更新所述初始模型的模型参数。
40.第二方面,本技术实施例提供一种模型训练方法,包括:
41.获取样本数据,所述样本数据中包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象,所述标注对象与所述样本文本的相似度在预设范围内;
42.确定初始模型,所述初始模型中包括n个融合层和映射层,所述融合层包括图像编码器、图像注意力层、文本编码器和文本注意力层,所述图像注意力层和所述文本注意力层分别用于融合所述图像编码器和所述文本编码器输出的特征,所述n为正整数;
43.通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,所述预测对象与所述样本文本的相似度在所述预设范围内;
44.根据所述预测对象和所述标注对象,更新所述初始模型的模型参数。
45.在一种可能的实施方式中,通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,包括:
46.通过所述n个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征;
47.通过所述映射层对所述融合图像特征和所述融合文本特征进行处理,以确定所述预测对象。
48.在一种可能的实施方式中,所述n为大于1的整数;通过至少一个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征,包括:
49.通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;
50.通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,所述i依次取2、3、
……
、n,并将第n个中间图像特征确定为所述融合图像特征,以及将所述第n个中间文本特征确定为所述融合文本特征。
51.在一种可能的实施方式中,通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征,包括:
52.通过所述第1个融合层中的图像编码器对所述样本图像特征进行处理,得到第一编码图像特征;
53.通过所述第1个融合层中的文本编码器对所述样本文本特征进行处理,得到第一编码文本特征;
54.通过所述第1个融合层中图像注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间图像特征;
55.通过所述第1个融合层中文本注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间文本特征。
56.在一种可能的实施方式中,通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征之前,还包括:
57.在所述样本图像特征中去除部分图像特征;和/或,
58.在所述样本文本特征中去除部分文本特征。
59.在一种可能的实施方式中,通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征,包括:
60.通过所述第i个融合层中的图像编码器对所述第i-1个中间图像特征进行处理,得到第i编码图像特征;
61.通过所述第i个融合层中的文本编码器对所述第i-1个中间文本特征进行处理,得到第i编码文本特征;
62.通过所述第i个融合层中的图像注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间图像特征;
63.通过所述第i个融合层中的文本注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间文本特征。
64.在一种可能的实施方式中,获取样本数据,包括:
65.获取所述样本图像和所述样本文本;
66.通过第一模型对所述样本图像进行处理,得到所述样本图像特征;
67.通过第二模型对所述样本文本进行处理,得到所述样本文本特征
68.根据所述样本文本对所述样本图像中的对象进行标注处理,以确定所述标注对象。
69.在一种可能的实施方式中,通过第一模型对所述样本图像进行处理,得到所述样本图像特征,包括:
70.通过所述第一模型在所述样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;
71.根据所述样本图像中的多个对象、以及各对象的对象类别,生成所述样本图像特征。
72.在一种可能的实施方式中,根据所述预测对象和所述标注对象,更新所述初始模型的模型参数,包括:
73.根据所述预测对象和所述标注对象,确定损失函数;
74.根据所述损失函数,更新所述初始模型的模型参数。
75.第三方面,本技术实施例提供一种图像处理方法,包括:
76.获取待处理图像和目标文本;
77.通过目标模型对所述待处理图像和所述目标文本进行处理,以在所述待处理图像中确定目标对象;其中,所述目标模型为通过第一方面任一项所述的方法训练得到的,或者,所述目标模型为通过第二方面任一项所述的方法训练得到的。
78.第四方面,本技术实施例提供一种模型训练装置,包括:获取模块、确定模块、处理模块和更新模块,其中,
79.所述获取模块用于,获取样本数据,所述样本数据中包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象,所述标注对象为所述样本图像中与所述样本文本相似度最高的对象;
80.所述确定模块用于,确定初始模型,所述初始模型中包括n个融合层和映射层,所述融合层包括图像编码器、图像注意力层、文本编码器和文本注意力层,所述图像注意力层
和所述文本注意力层分别用于融合所述图像编码器和所述文本编码器输出的特征,所述n为正整数;
81.所述处理模块用于,通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,所述预测对象与所述样本文本相似度最高;
82.所述更新模块用于,根据所述预测对象和所述标注对象,更新所述初始模型的模型参数。
83.在一种可能的实施方式中,所述处理模块具体用于:
84.通过所述n个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征;
85.通过所述映射层对所述融合图像特征和所述融合文本特征进行处理,以确定所述预测对象。
86.在一种可能的实施方式中,所述n为大于1的整数;所述处理模块具体用于:
87.通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;
88.通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,所述i依次取2、3、
……
、n,并将第n个中间图像特征确定为所述融合图像特征,以及将所述第n个中间文本特征确定为所述融合文本特征。
89.在一种可能的实施方式中,所述处理模块具体用于:
90.通过所述第1个融合层中的图像编码器对所述样本图像特征进行处理,得到第一编码图像特征;
91.通过所述第1个融合层中的文本编码器对所述样本文本特征进行处理,得到第一编码文本特征;
92.通过所述第1个融合层中图像注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间图像特征;
93.通过所述第1个融合层中文本注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间文本特征。
94.在一种可能的实施方式中,所述处理模块还用于:
95.在所述样本图像特征中去除部分图像特征;和/或,
96.在所述样本文本特征中去除部分文本特征。
97.在一种可能的实施方式中,所述处理模块具体用于:
98.通过所述第i个融合层中的图像编码器对所述第i-1个中间图像特征进行处理,得到第i编码图像特征;
99.通过所述第i个融合层中的文本编码器对所述第i-1个中间文本特征进行处理,得到第i编码文本特征;
100.通过所述第i个融合层中的图像注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间图像特征;
101.通过所述第i个融合层中的文本注意力层对所述第i编码图像特征和所述第i编码
文本特征进行融合处理,得到所述第i个中间文本特征。
102.在一种可能的实施方式中,所述获取模块具体用于:
103.获取所述样本图像和所述样本文本;
104.通过第一模型对所述样本图像进行处理,得到所述样本图像特征;
105.通过第二模型对所述样本文本进行处理,得到所述样本文本特征
106.根据所述样本文本对所述样本图像中的对象进行标注处理,以确定所述标注对象。
107.在一种可能的实施方式中,所述获取模块具体用于:
108.通过所述第一模型在所述样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;
109.根据所述样本图像中的多个对象、以及各对象的对象类别,生成所述样本图像特征。
110.在一种可能的实施方式中,所述更新模块具体用于:
111.根据所述预测对象和所述标注对象,确定损失函数;
112.根据所述损失函数,更新所述初始模型的模型参数。
113.第五方面,本技术实施例提供一种模型训练装置,包括:获取模块、确定模块、处理模块和更新模块,其中,
114.所述获取模块用于,获取样本数据,所述样本数据中包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象,所述标注对象与所述样本文本的相似度在预设范围内;
115.所述确定模块用于,确定初始模型,所述初始模型中包括n个融合层和映射层,所述融合层包括图像编码器、图像注意力层、文本编码器和文本注意力层,所述图像注意力层和所述文本注意力层分别用于融合所述图像编码器和所述文本编码器输出的特征,所述n为正整数;
116.所述处理模块用于,通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,所述预测对象与所述样本文本的相似度在所述预设范围内;
117.所述更新模块用于,根据所述预测对象和所述标注对象,更新所述初始模型的模型参数。
118.在一种可能的实施方式中,所述处理模块具体用于:
119.通过所述n个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征;
120.通过所述映射层对所述融合图像特征和所述融合文本特征进行处理,以确定所述预测对象。
121.在一种可能的实施方式中,所述n为大于1的整数;所述处理模块具体用于:
122.通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;
123.通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,所述i依次取2、3、
……
、n,并将第
n个中间图像特征确定为所述融合图像特征,以及将所述第n个中间文本特征确定为所述融合文本特征。
124.在一种可能的实施方式中,所述处理模块具体用于:
125.通过所述第1个融合层中的图像编码器对所述样本图像特征进行处理,得到第一编码图像特征;
126.通过所述第1个融合层中的文本编码器对所述样本文本特征进行处理,得到第一编码文本特征;
127.通过所述第1个融合层中图像注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间图像特征;
128.通过所述第1个融合层中文本注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间文本特征。
129.在一种可能的实施方式中,所述处理模块还用于:
130.在所述样本图像特征中去除部分图像特征;和/或,
131.在所述样本文本特征中去除部分文本特征。
132.在一种可能的实施方式中,所述处理模块具体用于:
133.通过所述第i个融合层中的图像编码器对所述第i-1个中间图像特征进行处理,得到第i编码图像特征;
134.通过所述第i个融合层中的文本编码器对所述第i-1个中间文本特征进行处理,得到第i编码文本特征;
135.通过所述第i个融合层中的图像注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间图像特征;
136.通过所述第i个融合层中的文本注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间文本特征。
137.在一种可能的实施方式中,所述获取模块具体用于:
138.获取所述样本图像和所述样本文本;
139.通过第一模型对所述样本图像进行处理,得到所述样本图像特征;
140.通过第二模型对所述样本文本进行处理,得到所述样本文本特征
141.根据所述样本文本对所述样本图像中的对象进行标注处理,以确定所述标注对象。
142.在一种可能的实施方式中,所述获取模块具体用于:
143.通过所述第一模型在所述样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;
144.根据所述样本图像中的多个对象、以及各对象的对象类别,生成所述样本图像特征。
145.在一种可能的实施方式中,所述更新模块具体用于:
146.根据所述预测对象和所述标注对象,确定损失函数;
147.根据所述损失函数,更新所述初始模型的模型参数。
148.第六方面,本技术实施例提供一种图像处理装置,包括:获取模块和处理模块,其中,
149.所述获取模块用于,获取待处理图像和目标文本;
150.所述处理模块用于,通过目标模型对所述待处理图像和所述目标文本进行处理,以在所述待处理图像中确定目标对象;其中,所述目标模型为通过第一方面任一项所述的方法训练得到的,或者所述目标模型为通过第二方面任一项所述的方法训练得到的。
151.第七方面,本技术实施例提供一种电子设备,包括:存储器和处理器;
152.所述存储器存储计算机执行指令;
153.所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行第一方面任一项所述的模型训练方法,或第二方面任一项所述的模型训练方法。
154.第八方面,本技术实施例提供一种电子设备,包括:存储器和处理器;
155.所述存储器存储计算机执行指令;
156.所述处理器执行所述存储器存储的计算机执行指令,使得所述处理器执行第三方面任一项所述的图像处理方法。
157.第九方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述计算机执行指令被处理器执行时用于实现第一方面任一项所述的模型训练方法,或第二方面任一项所述的模型训练方法。
158.第十方面,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述计算机执行指令被处理器执行时用于实现第三方面任一项所述的图像处理方法。
159.第十一方面,本技术实施例提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第一方面任一项所示的模型训练方法,或第二方面任一项所述的模型训练方法。
160.第十二方面,本技术实施例提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现第三方面任一项所示的图像处理方法。
161.本技术实施例提供一种模型训练方法、装置及设备,电子设备可以获取样本数据,并确定初始模型。可以通过初始模型中的n个融合层和映射层对样本图像特征和样本文本特征进行处理,以在样本图像中确定预测对象,并根据预测对象和标注对象,更新初始模型的模型参数。由于初始模型中包括n个融合层,每个融合层中可以包括图像注意力层和文本注意力层,可以通过图像注意力层和文本注意力层,对样本图像特征和样本文本特征进行融合处理,以将样本图像特征和样本文本特征关联起来,相比通过模型分别对样本图像和样本文本进行处理,提高了模型确定目标对象的准确性。
附图说明
162.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
163.图1为本技术示例性实施例提供的一种应用场景的示意图;
164.图2为本技术示例性实施例提供的一种模型训练方法的流程示意图;
165.图3为本技术示例性实施例提供的数据库的示意图;
166.图4为本技术示例性实施例提供的样本图像的示意图;
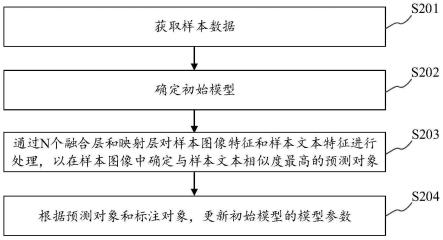
167.图5为本技术示例性实施例提供的初始模型的结构示意图;
168.图6为本技术示例性实施例提供的另一种模型训练方法的流程示意图;
169.图7为本技术示例性实施例提供的又一种模型训练方法的流程示意图;
170.图8为本技术实施例提供的一种模型训练方法的过程示意图;
171.图9为申请示例性实施例提供的一种图像处理方法的过程示意图;
172.图10为本技术示例性实施例提供的一种模型训练装置的结构示意图;
173.图11为本技术示例性实施例提供的另一种模型训练装置的结构示意图;
174.图12为本技术示例性实施例提供的一种图像处理装置的结构示意图;
175.图13为本技术示例性实施例提供的一种电子设备的结构示意图。
具体实施方式
176.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术具体实施例及相应的附图对本技术技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
177.图1为本技术示例性实施例提供的一种应用场景的示意图。请参见图1,可以将待处理图像和目标文本输入模型,模型可以根据目标文本,在待处理图像中确定目标文本指定的目标对象。例如,若目标文本为“左边第一个人”,则模型可以根据该目标文本,在待处理图像中确定目标对象为左边第一个人,并输出该目标对象,如图1所示。
178.在相关技术中,可以通过样本图像和样本文本对模型进行训练,以得到模型。然而,在上述训练过程中,通常是通过模型分别对样本图像和样本文本进行处理,导致模型确定目标对象的准确性低。
179.在本技术实施例中,可以通过模型对样本图像和样本文本进行处理,得到样本图像特征和样本文本特征,并且可以通过模型对样本图像特征和样本文本特征进行融合处理,以将样本图像特征和样本文本特征关联起来,相比通过模型分别对样本图像和样本文本进行处理,提高了模型确定目标对象的准确性。
180.下面,通过具体实施例对本技术所示的技术方案进行详细说明。需要说明的是,下面几个实施例可以单独存在,也可以相互结合,对于相同或相似的内容,在不同的实施例中不再重复说明。
181.在本技术的技术方案中,主要涉及2个过程,分别为模型训练的过程、使用模型的过程。下面,结合图2,首先对模型训练的过程进行说明。
182.图2为本技术示例性实施例提供的一种模型训练方法的流程示意图。请参见图2,该方法可以包括:
183.s201、获取样本数据。
184.本技术实施例的执行主体可以为电子设备,也可以为设置在电子设备中的模型训练装置。模型训练装置可以通过软件实现,也可以通过软件和硬件的结合实现。模型训练装置可以为电子设备中的处理器。为了便于理解,在下文中,以执行主体为电子设备为例进行说明。
185.样本数据中可以包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象。标注对象可以为样本图像中与样本文本相似度最高的对象。
186.在一可选实施例中,可以通过如下方式,获取样本数据:获取样本图像和样本文本;通过第一模型对样本图像进行处理,得到样本图像特征;通过第二模型对样本文本进行处理,得到样本文本特征;根据样本文本对样本图像中的对象进行标注处理,以确定标注对象。
187.样本图像中可以包括多个对象。例如,样本图像中可以包括5个对象,该5个对象分别具有不同的对象特征。
188.可选地,样本图像的尺寸可以表示为c
×h×
w。其中,c表示该图像的通道数,h为图像的高度,可以用该图像在垂直维度的像素数表示;w为图像的宽度,可以用该图像在水平维度的像素数表示。例如,样本图像的尺寸可以为3
×
128
×
128,表示该样本图像有红色(red,r)、绿色(green,g)、蓝色(blue,b)3个通道,高为128像素(pixel,px),宽为128px。
189.样本文本可以为短句。例如,样本文本可以为“左边第一个人”。
190.第一模型可以为基于掩模区域的卷积神经网络(mask region-based convolutional neural networks,mask-r cnn)模型。可以通过第一模型对图像进行处理。
191.第二模型可以为基于编码器的双向编码表征(bidirectional encoder representations from transformer,bert)模型。可以通过第二模型对文本进行处理。
192.在一可选实施例中,可以通过如下方式,得到样本图像特征:通过第一模型在样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;根据样本图像中的多个对象、以及各对象的对象类别,生成样本图像特征。
193.可选地,第一模型可以在样本图像中进行对象识别,确定样本图像中的多个对象。针对任意一个对象,第一模型可以生成对象的初始特征,该初始特征可以通过一维向量q表示。例如,一维向量q可以为:q=[q1,q2,
…
,qn]。
[0194]
例如,若样本图像中包括3个对象,则第一模型可以在该样本图像中确定该3个对象,并生成该3个对象的初始特征。例如,对象1的初始特征1可以为q1=[0.10,0.09,
…
,0.02]、对象2的初始特征2可以为q2=[0.18,0.11,
…
,0.05]、对象3的初始特征3可以为q3=[0.10,0.09,
…
,0.02]。
[0195]
可选地,针对样本图像中的任意一个对象,第一模型可以在样本图像中识别出对象的对象类别,并根据该对象类别在数据库中确定该对象类别对应的类别特征。
[0196]
在一可选实施例中,可以通过bert模型预先生成对象类别对应的类别特征。类别特征可以通过一维向量p表示。例如,一维向量p可以为p=[p1,p2,
…
,pm]。
[0197]
例如,若对象类别为“电脑”,则可以将“电脑”输入到bert模型中,通过bert模型对“电脑”进行处理,得到对象类别“电脑”对应的类别特征1,假设该类别特征1可以表示为p1=[0.12,0.07,
…
,0.09]。
[0198]
可选地,确定对象类别对应的类别特征之后,可以将对象类别和对应的类别特征,一一对应保存在数据库中,以便后续使用。
[0199]
下面,结合图3,对数据库进行说明。
[0200]
图3为本技术示例性实施例提供的数据库的示意图。请参见图3,数据库中可以对应保存有多个对象类别和对应的类别特征。例如,数据库中可以保存有对象类别1和对应的类别特征1、对象类别2和对应的类别特征2、
……
、对象类别j和对应的类别特征j。例如,若对象类别1为电脑,对应保存的类别特征1可以为p1=[0.12,0.07,
…
,0.09]。
[0201]
针对任意一个对象,第一模型可以对对象的初始特征即一维向量q、以及对象类别对应的类别特征即一维向量p进行拼接,以生成该对象的对象特征。对象特征可以表示为一维向量s。例如,一维向量s可以表示为s=[q1,q2,
…
,qn,p1,p2,
…
,pm]。
[0202]
例如,若通过第一模型确定对象1的初始特征1为q1=[0.10,0.09,
…
,0.02],对象1的对象类别为电脑,对应的类别特征1为p1=[0.12,0.07,
…
,0.09],则可以将q1和p1进行拼接,以生成对象特征s1。例如,对象特征s1可以表示为:
[0203]
s1=[0.10,0.09,
…
,0.02,0.12,0.07,
…
,0.09]
[0204]
可选地,通过第一模型确定样本图像中各对象的对象特征之后,则可以根据多个对象的对象特征,生成样本图像特征。样本图像特征中可以包括多个对象的对象特征,可以通过矩阵t表示。例如,矩阵t可以表示为:
[0205][0206]
例如,若样本图像中包括3个对象,若对象1的对象特征1为s1=[0.17,0.09,
…
,0.02,0.12,0.07,
…
,0.09],对象2的对象特征2为s2=[0.52,0.27,
…
,0.46,0.09,0.07,
…
,0.26],对象3的对象特征3为s3=[0.06,0.01,
…
,0.73,0.91,0.42,
…
,0.33],则可以根据该3个对象特征,得到样本图像特征为:
[0207][0208]
在一可选实施例中,可以通过第二模型对样本文本进行处理,得到样本文本特征。可选地,样本文本特征可以通过一维向量z表示。例如,一维向量z可以为:z=[z1,z2,
…
,za]。
[0209]
例如,若第二模型为bert模型,样本文本1为“左边第一个人”,则可以将“左边第一个人”输入到bert模型中,通过bert模型对“左边第一个人”进行处理,以得到该样本文本1对应的样本文本特征1。假设,该样本文本特征1可以表示为z1=[0.05,0.14,
…
,0.35]。
[0210]
在一可选实施例中,可以根据样本文本对样本图像中的对象进行标注处理,以确定标注对象。例如,若样本图像如图4所示,若样本文本1为“左边第一个人”,则可以根据该样本文本1,对样本图像中的人物1进行标注处理,以确定该样本文本1对应的标注对象为人物1;若样本文本2为“右下角的电脑”,则可以根据该样本文本2,对样本图像中的电脑2进行标注处理,以确定该样本文本2对应的标注对象为电脑2。
[0211]
可选地,电子设备可以将样本图像特征、样本文本特征、以及标注对象,确定为样本数据。
[0212]
可选地,针对样本图像中的任意一个对象,还可以通过第一模型确定对象在样本图像中的对象坐标、以及对象所在的目标框。
[0213]
对象坐标可以通过像素值表示。例如,若样本图像的尺寸为3
×
128
×
128,若样本图像中包括对象1,则可以以样本图像的左上角顶点为原点,建立直角坐标系,以水平方向为横轴,以垂直方向为纵轴,例如,对象1在样本图像中的对象坐标可以表示为(65px,
92px)。
[0214]
可选地,第一模型可以识别出对象的尺寸大小,即对象的高和宽;进而可以通过对象的尺寸、以及对象坐标确定对象所在的目标框。
[0215]
可选地,目标框可以通过[x,y,w,h]表示。其中,x表示对象坐标中的横坐标;y表示对象坐标中的纵坐标;w表示目标框的宽度;h表示目标框的高度。
[0216]
下面,结合图4,对对象所在的目标框进行说明。
[0217]
图4为本技术示例性实施例提供的样本图像的示意图。请参见图4,若样本图像中包括5个对象,分别为人物1、人物2、人物3、电脑1、电脑2,若样本图像的尺寸为3
×
128
×
128,则第一模型可以在样本图像中分别识别出该5个对象在样本图像中的对象坐标,以及对象的长和宽。假设第一模型可以在该样本图像中,确定电脑1的对象坐标为(20px,98px),电脑1的宽为40px,高为23px,则第一模型可以确定电脑1所在的目标框1,目标框1可以表示为[20,98,40,23]。
[0218]
s202、确定初始模型。
[0219]
初始模型可以为视觉语言多模态(vision-and-language bert,vilbert)模型,可以通过vilbert模型同时对样本图像和样本文本进行处理。
[0220]
下面,结合图5,以初始模型为vilbert模型为例,对初始模型的结构进行说明。
[0221]
图5为本技术示例性实施例提供的初始模型的结构示意图。请参见图5,初始模型中可以包括n个融合层和映射层,n为正整数。
[0222]
针对任意一个融合层,融合层中可以包括图像编码器(transformer,trm)、图像注意力层(co-attentional transformer,co-trm)、文本编码器和文本注意力层。如图5所示,在第1个融合层中,可以包括图像编码器trm-11,图像注意力层co-trm-11,文本编码器trm-12,文本注意力层co-trm-12。同样的,在第n个融合层中,可以包括图像编码器trm-n1、图像注意力层co-trm-n1、文本编码器trm-n2、以及文本注意力层co-trm-n2。
[0223]
其中,任意一个图像注意力层和文本注意力层可以分别用于融合图像编码器和文本编码器输出的特征。例如,在第1个融合层中,图像注意层co-trm-11可以融合图像编码器trm-11和文本编码器trm-12输出的特征,以生成与文本关联的图像特征;文本注意力层co-trm-12可以融合文本编码器trm-12和图像编码器trm-11输出的特征,以生成与图像关联的文本特征。
[0224]
需要说明的是,图像编码器trm-11、图像注意力层co-trm-11、
……
、图像编码器trm-n1、图像注意力层co-trm-n1,可以组成图像流,即图5中vilbert模型的左侧一列;文本编码器trm-12,文本注意力层co-trm-12、
……
、文本编码器trm-n2、文本注意力层co-trm-n2,可以组成文本流,即图5中vilbert模型的右侧一列。
[0225]
可选地,初始模块中可以包括映射层。可以通过映射层将图像注意力层co-trm-n1、文本注意力层co-trm-n2输出的特征,映射到相同的维度,以便进行后续计算。
[0226]
s203、通过n个融合层和映射层对样本图像特征和样本文本特征进行处理,以在样本图像中确定与样本文本相似度最高的预测对象。
[0227]
可选地,预测对象可以为样本图像中与样本文本的相似度最高的对象。
[0228]
在一可选实施例中,可以通过如下方式,在样本图像中确定预测对象:通过n个融合层对样本图像特征和样本文本特征进行处理,得到融合图像特征和融合文本特征;通过
映射层对融合图像特征和融合文本特征进行处理,以确定预测对象。
[0229]
可选地,可以通过如下方式,得到融合图像特征和融合文本特征:通过第1个融合层对样本图像特征和样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;通过第i个融合层对第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,i依次取2、3、
……
、n。
[0230]
可选地,当i等于n时,可以将第n个中间图像特征确定为融合图像特征,以及将第n个中间文本特征确定为融合文本特征。
[0231]
确定融合图像特征和融合文本特征之后,则可以通过映射层对融合图像特征和融合文本特征进行处理,以将融合图像特征和融合文本特征映射到相同的维度,进而可以对融合图像特征和融合文本特征进行相似度计算,得到样本文本与样本图像中各个对象的相似度,并将相似度最高的对象确定为预测对象。
[0232]
例如,若样本图像如图4所示,样本图像中包括5个对象,样本图像特征中包括该5个对象的对象特征,若样本文本为“左下角的电脑”,则通过n个融合层进行处理之后,可以得到融合图像特征和融合文本特征,融合图像特征中可以包括该5个对象对应的融合特征,分别为融合特征1、融合特征2、融合特征3、融合特征4和融合特征5,则初始模型可以分别计算融合文本特征与该5个融合特征之间的相似度。例如,若融合文本特征与融合特征1之间的相似度为20%、融合文本特征与融合特征2之间的相似度为25%、融合文本特征与融合特征3之间的相似度为21%、融合文本特征与融合特征4之间的相似度为90%、融合文本特征与融合特征5之间的相似度为80%,若融合特征4对应的对象为电脑1,则由于融合文本特征与融合特征4之间的相似度最高,则可以将电脑1确定为预测对象。
[0233]
可选地,由于每个对象都有对应的目标框,则确定预测对象之后,可以根据预测对象所在的目标框,对样本图像进行图像分割,以输出预测对象。
[0234]
例如,若样本图像如图4所示,通过初始模型确定预测对象为电脑1,若电脑1所在的目标框1为[20,98,40,23],则可以根据该目标框1,对样本图像进行分割,以输出电脑1。
[0235]
s204、根据预测对象和标注对象,更新初始模型的模型参数。
[0236]
电子设备确定预测对象和标注对象之后,则根据预测对象和标注对象,确定损失函数(loss);根据损失函数,更新初始模型的模型参数。
[0237]
可选地,当loss值不再下降,则可以结束对初始模型的训练,以得到训练完成的初始模型。
[0238]
例如,若样本图像如图4所示,标注对象为电脑1,预测对象为电脑1,则可以根据预测对象和标注对象确定loss值,若确定loss值为0.05,对初始模型再次训练若干轮,得到的loss值仍为0.05,不再下降,则可以结束对初始模型的训练,以得到训练完成的初始模型。
[0239]
在本技术实施例中,电子设备可以获取样本数据,并确定初始模型。可以通过初始模型中的n个融合层和映射层对样本图像特征和样本文本特征进行处理,以在样本图像中确定与样本文本相似度最高的预测对象,并根据预测对象和标注对象,更新初始模型的模型参数。由于初始模型中包括n个融合层,每个融合层中可以包括图像注意力层和文本注意力层,可以通过图像注意力层和文本注意力层,对样本图像特征和样本文本特征进行融合处理,以将样本图像特征和样本文本特征关联起来,相比通过模型分别对样本图像和样本文本进行处理,提高了模型确定目标对象的准确性。
[0240]
图6为本技术示例性实施例提供的另一种模型训练方法的流程示意图。请参见图6,该方法可以包括:
[0241]
s601、获取样本数据。
[0242]
样本数据中可以包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象。标注对象与样本文本的相似度可以在预设范围内。
[0243]
在一可选实施例中,可以通过如下方式,获取样本数据:获取样本图像和样本文本;通过第一模型对样本图像进行处理,得到样本图像特征;通过第二模型对样本文本进行处理,得到样本文本特征;根据样本文本对样本图像中的对象进行标注处理,以确定标注对象。
[0244]
可选地,第一模型可以在样本图像中进行对象识别,确定样本图像中的多个对象。针对任意一个对象,第一模型可以生成对象的初始特征,并且可以在样本图像中识别出对象的对象类别,根据该对象类别在数据库中确定该对象类别对应的类别特征。第一模型可以对对象的初始特征和类别特征进行拼接,以生成该对象的对象特征。
[0245]
可选地,通过第一模型确定样本图像中各对象的对象特征之后,则可以根据多个对象的对象特征,生成样本图像特征。样本图像特征中可以包括多个对象的对象特征,可以通过矩阵t表示。
[0246]
可选地,可以通过第二模型对样本文本进行处理,得到样本文本特征。
[0247]
需要说明的是,确定样本图像特征、样本文本特征的具体执行过程可以参见步骤s201中确定样本图像特征、样本文本特征的具体执行过程,此处不再进行赘述。
[0248]
在一可选实施例中,可以根据样本文本对样本图像中的对象进行标注处理,以确定标注对象。
[0249]
可选地,标注对象与样本文本的相似度可以在预设范围内。该预设范围可以为最高范围、最低范围或某个区间范围。例如,预设范围可以为相似度大于90%、或者相似度小于10%、或者相似度为70%-90%。
[0250]
例如,若样本图像如图4所示,若样本文本1为“电脑”,若预设范围为0%-30%,则可以根据该样本文本1,确定样本图像中与样本文本相似度在预设范围内的对象,即样本图像中的人物1、人物2和人物3,并进行标注处理,以确定该样本文本1对应的标注对象为人物1、人物2和人物3。
[0251]
可选地,电子设备可以将样本图像特征、样本文本特征、以及标注对象,确定为样本数据。
[0252]
可选地,针对样本图像中的任意一个对象,还可以通过第一模型确定对象在样本图像中的对象坐标、以及对象所在的目标框。
[0253]
需要说明的是,确定对象所在的目标框的具体执行过程,可以参见步骤s201中确定对象所在的目标框的具体执行过程,此处不再进行赘述。
[0254]
s602、确定初始模型。
[0255]
需要说明的是,步骤s602的具体执行过程,可以参见步骤s202的具体执行过程,此处不再进行赘述。
[0256]
s603、通过n个融合层和映射层对样本图像特征和样本文本特征进行处理,以在样本图像中确定与样本文本的相似度可以在预设范围内的预测对象。
[0257]
可选地,预测对象与样本文本的相似度可以在预设范围内。
[0258]
在一可选实施例中,可以通过如下方式,在样本图像中确定预测对象:通过n个融合层对样本图像特征和样本文本特征进行处理,得到融合图像特征和融合文本特征;通过映射层对融合图像特征和融合文本特征进行处理,以确定预测对象。
[0259]
可选地,可以通过如下方式,得到融合图像特征和融合文本特征:通过第1个融合层对样本图像特征和样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;通过第i个融合层对第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,i依次取2、3、
……
、n。
[0260]
可选地,当i等于n时,可以将第n个中间图像特征确定为融合图像特征,以及将第n个中间文本特征确定为融合文本特征。
[0261]
确定融合图像特征和融合文本特征之后,则可以通过映射层对融合图像特征和融合文本特征进行处理,以将融合图像特征和融合文本特征映射到相同的维度,进而可以对融合图像特征和融合文本特征进行相似度计算,得到样本文本与样本图像中各个对象的相似度,并将与样本文本的相似度可以在预设范围内的对象确定为预测对象。
[0262]
例如,若样本图像如图4所示,样本图像中包括5个对象,样本图像特征中包括该5个对象的对象特征,若预设范围为0%-30%,若样本文本为“电脑”,则通过n个融合层进行处理之后,可以得到融合图像特征和融合文本特征,融合图像特征中可以包括该5个对象对应的融合特征,分别为融合特征1、融合特征2、融合特征3、融合特征4和融合特征5,则初始模型可以分别计算融合文本特征与该5个融合特征之间的相似度。例如,若融合文本特征与融合特征1之间的相似度为20%、融合文本特征与融合特征2之间的相似度为25%、融合文本特征与融合特征3之间的相似度为21%、融合文本特征与融合特征4之间的相似度为90%、融合文本特征与融合特征5之间的相似度为80%,若融合特征1对应的对象为人物1、融合特征2对应的对象为人物2、融合特征3对应的对象为人物3,则由于融合文本特征与融合特1、融合特征2、融合特征3之间的相似度处于预设范围,则可以将人物1、人物2和人物3确定为预测对象。
[0263]
可选地,由于每个对象都有对应的目标框,则确定预测对象之后,可以根据预测对象所在的目标框,对样本图像进行图像分割,并对预测对象进行处理。
[0264]
例如,若样本图像如图4所示,若预设范围为0%-30%,若样本文本为“电脑”,则可以通过初始模型确定预测对象为人物1、人物2和人物3,则可以根据人物1、人物2和人物3分别所在的目标框,对样本图像进行分割,并对预测对象进行处理。例如,电子设备通过可以根据人物1、人物2和人物3分别所在的目标框,在样本图像中删除人物1、人物2和人物3。
[0265]
s604、根据预测对象和标注对象,更新初始模型的模型参数。
[0266]
电子设备确定预测对象和标注对象之后,则根据预测对象和标注对象,确定损失函数(loss);根据损失函数,更新初始模型的模型参数。
[0267]
可选地,当loss值不再下降,则可以结束对初始模型的训练,以得到训练完成的初始模型。
[0268]
例如,若样本图像如图4所示,标注对象为人物1、人物2和人物3,预测对象为人物1、人物2和人物3,则可以根据预测对象和标注对象确定loss值,若确定loss值为0.05,对初始模型再次训练若干轮,得到的loss值仍为0.05,不再下降,则可以结束对初始模型的训
练,以得到训练完成的初始模型。
[0269]
在本技术实施例中,电子设备可以获取样本数据,并确定初始模型。可以通过初始模型中的n个融合层和映射层对样本图像特征和样本文本特征进行处理,以在样本图像中确定预测对象,预测对象与样本文本的相似度可以在预设范围内。电子设备可以根据预测对象和标注对象,更新初始模型的模型参数。由于初始模型中包括n个融合层,每个融合层中可以包括图像注意力层和文本注意力层,可以通过图像注意力层和文本注意力层,对样本图像特征和样本文本特征进行融合处理,以将样本图像特征和样本文本特征关联起来,相比通过模型分别对样本图像和样本文本进行处理,提高了模型确定目标对象的准确性。
[0270]
下面,在图2或图6所示实施例的基础上,结合图7,对图2所示实施例中步骤s203或图6所示实施例中步骤s603进行进一步详细说明。
[0271]
图7为本技术示例性实施例提供的又一种模型训练方法的流程示意图。请参见图7,该方法可以包括:
[0272]
s701、将i初始化为1。
[0273]
电子设备可以确定初始模型中包括n个融合层,融合层的顺序可以通过i表示,i=1、2、3、
……
、n。
[0274]
可以将i初始化为1,表示从初始模型中第1个融合层开始进行处理。
[0275]
s702、通过第i个融合层中的图像编码器对第i-1个中间图像特征进行处理,得到第i编码图像特征。
[0276]
当i=1时,可以通过第1个融合层中的图像编码器对样本图像特征进行处理,得到第一编码图像特征。
[0277]
例如,若初始模型如图5所示的vilbert模型,若向vilbert模型输入的样本图像特征为则当i=1时,可以通过第1个融合层中的图像编码器trm-11对该样本图像特征进行处理,得到第一编码图像特征。例如,第一编码特征通过3*200矩阵表示。
[0278]
可选地,针对任意一个样本图像,由于样本图像特征中包括多个对象特征,在通过第1个融合层对样本图像特征进行处理时,初始模型还可以对样本图像中的任意一个对象特征进行随机掩盖(mask),以去除样本图像特征中的部分图像特征。
[0279]
例如,若样本图像中包括3个对象,分别为对象1、对象2和对象3,样本图像特征为其中,若对象1的对象特征1为s1=[0.17,0.09,
…
,0.02,0.12,0.07,
…
,0.09],对象2的对象特征2为s2=[0.52,0.27,
…
,0.46,0.09,0.07,
…
,0.26],对象3的对象特征3为s3=[0.06,0.01,
…
,0.73,0.91,0.42,
…
,0.33],则初始模型可以对对象特征1进行掩盖,即可以对象特征1进行置0,则掩盖后的样本图像特征可以表示为
[0280]
当i大于1时,可以通过第i个融合层中的图像编码器对第i-1个中间图像特征进行
处理,得到第i编码图像特征。第i编码图像特征可以通过矩阵表示。
[0281]
例如,若i=3,则可以通过第3个融合层中的图像编码器对第2个中间图像特征进行处理,得到第3编码图像特征。其中,第2个中间图像特征可以是通过步骤s704得到的。
[0282]
s703、通过第i个融合层中的文本编码器对第i-1个中间图像特征进行处理,得到第i编码文本特征。
[0283]
当i=1时,可以通过第1个融合层中的文本编码器对样本文本特征进行处理,得到第一编码文本特征。
[0284]
例如,若初始模型如图5所示的vilbert模型,若向vilbert模型输入的样本文本特征为z1=[0.05,0.14,
…
,0.35],则可以通过第1个融合层中的文本编码器trm-12对样本文本特征进行处理,得到第一编码文本特征。例如,第一编码文本特征可以通过1*200矩阵表示。
[0285]
可选地,针对任意一个样本文本,由于样本文本中包括多个文字,则在通过第1个融合层对样本文本特征进行处理时,初始模型还可以对样本文本中的任意一个文字或词语进行随机掩盖,以去除样本文本特征中的部分文本特征。
[0286]
例如,若样本文本为“左边第一个人”,则样本文本中包括6个文字,则初始模型可以对该样本文本中的“左”进行掩盖,则可以将“左”替换为“mask”,得到掩盖后的样本文本可以为“[mask]边第一个人”。
[0287]
当i大于1时,可以通过第i个融合层中的文本编码器对第i-1个中间图像特征进行处理,得到第i编码文本特征。第i编码文本特征可以通过矩阵表示。
[0288]
例如,若i=3,则可以通过第3个融合层中的文本编码器对第2个中间文本特征进行处理,得到第3编码文本特征。其中,第2个中间文本特征可以是通过步骤s705得到的。
[0289]
需要说明的是,步骤s702和步骤s703可以按照步骤顺序执行,也可以同步执行。
[0290]
在步骤s702或步骤s703中,在初始模型进行随机掩盖时,可以预先设置随机掩盖的概率。例如,若设置随机掩盖的概率为90%,则表示在样本图像或者样本文本中,有90%的特征可以进行随机掩盖,10%保持不变。通过这种在样本图像或样本文本中进行随机遮盖的方式,可以使初始模型对遮盖部分进行预测,以使模型更好的学习样本图像特征或样本文本特征,从而提高初始模型预测目标对象的准确性。
[0291]
s704、通过第i个融合层中的图像注意力层对第i编码图像特征和第i编码文本特征进行融合处理,得到第i个中间图像特征。
[0292]
通过步骤s702得到第i编码图像特征、通过步骤s703得到第i编码文本特征之后,则可以执行步骤s704。
[0293]
当i=1时,可以通过第1个融合层中图像注意力层对第一编码图像特征和第一编码文本特征进行融合处理,得到与文本特征关联的第1个中间图像特征。
[0294]
例如,若初始模型如图5所示的vilbert模型,若第一编码图像特征为3*200矩阵、第一编码文本特征为1*200矩阵,若i=1,则可以通过第1个融合层中的图像注意力层co-trm-11对该3*200矩阵和该1*200矩阵进行融合处理,得到与文本特征关联的第一个中间图像特征。例如,第一个中间图像特征可以为4*200矩阵。
[0295]
当i大于1时,可以通过第i个融合层中的图像注意力层对第i编码图像特征和第i编码文本特征进行融合处理,得到与文本特征关联的第i个中间图像特征。第i个中间图像
特征可以用矩阵表示。
[0296]
例如,若i=3,则可以通过第3个融合层中的图像注意力层对第3编码图像特征和第3编码文本特征进行融合处理,得到第3个中间图像特征。
[0297]
s705、通过第i个融合层中的文本注意力层对第i编码图像特征和第i编码文本特征进行融合处理,得到第i个中间文本特征。
[0298]
通过步骤s702得到第i编码图像特征、通过步骤s703得到第i编码文本特征之后,则可以执行步骤s705。
[0299]
当i=1时,可以通过第1个融合层中文本注意力层对第一编码图像特征和第一编码文本特征进行融合处理,得到与图像特征关联的第1个中间文本特征。
[0300]
例如,若初始模型如图5所示的vilbert模型,若第一编码图像特征为3*200矩阵、第一编码文本特征为1*200矩阵,若i=1,则可以通过第1个融合层中的文本注意力层co-trm-12对该3*200矩阵和该1*200矩阵进行融合处理,得到与图像特征关联的第一中间文本特征1。例如,第一中间文本特征1可以为1*200矩阵。
[0301]
当i大于1时,可以通过第i个融合层中的文本注意力层对第i编码图像特征和第i编码文本特征进行融合处理,得到第i个中间文本特征。第i个中间文本特征可以用矩阵表示。
[0302]
例如,若i=3,则可以通过第3个融合层中的文本注意力层对第3编码图像特征和第3编码文本特征进行融合处理,得到与图像特征关联的第3个中间文本特征。
[0303]
可选地,通过第i个融合层对样本图像特征和样本文本特征进行处理时,向图像注意力层和文本注意力层输出的特征可以涉及3种类型,分别为图像特征、文本特征和特殊标识(token)。
[0304]
特殊标识token可以用于分隔不同特征,和/或消除歧义。特殊标识token可以包括cls、sep、img、end等标识。其中,cls用于标记样本文本特征的开始;sep用于分隔不同的特征;img用于标记样本图像特征的开始;end用于标记结束。
[0305]
例如,向文本注意力层输入的图像特征可以标记为[img][对象特征1][对象特征2][end],输入的文本特征可以标记为“[cls]左边第一个[mask][end]”,则文本注意力层可以确定[img]与[cls]是否对齐,以对图像特征和文本特征进行匹配对齐,使得文本特征和图像特征可以关联起来。若图像特征和文本特征为对齐状态,则说明样本文本正确地描述了样本图像。
[0306]
需要说明的是,步骤s704和步骤s705可以按照步骤顺序执行,也可以同步执行。
[0307]
s706、将i更新为i+1。
[0308]
当得到第i个中间图像特征和第i个中间文本特征后,电子设备可以更新i,将i+1作为新的i。
[0309]
例如,当得到第3个中间图像特征和第3个中间文本特征后,电子设备可以更新i,将4作为新的i。
[0310]
s707、判断i是否小于或等于n。
[0311]
由于初始模型中有n个融合层,i可以取1、2、3、
……
n,则i的最大值为n。若判断i小于或者等于n时,则说明初始模型中还有第i个融合层没有进行特征处理,则可以执行s702,和/或s703;若i大于n,则说明初始模型中第n个融合层已经进行过特征处理,则可以执行
s708。
[0312]
s708、将第i个中间图像特征确定为融合图像特征,以及将第i个中间文本特征确定为融合文本特征。
[0313]
当i=n时,则可以将第i个中间图像特征确定为融合图像特征,以及将第i个中间文本特征确定为融合文本特征,即将第n个中间图像特征确定为融合图像特征,以及将第n个中间文本特征确定为融合文本特征。
[0314]
s709、在样本图像中确定预测对象。
[0315]
可选地,可以通过初始模型中的映射层对融合图像特征和融合文本特征进行处理,以将融合图像特征和融合文本特征映射到相同的维度,进而可以对融合图像特征和融合文本特征进行相似度计算,得到样本文本与样本图像中各个对象的相似度,并根据相似度确定预测对象。
[0316]
可选地,若设定预测对象为样本图像中与样本文本的相似度最高的对象,则电子设备得到样本文本与样本图像中各个对象的相似度之后,可以将样本图像中与样本文本的相似度最高的对象,确定为预测对象。
[0317]
可选地,若预测对象为样本图像中与样本文本的相似度在预设范围内的对象,则电子设备得到样本文本与样本图像中各个对象的相似度之后,可以与样本文本的相似度在预设范围内的对象,确定为预测对象。
[0318]
需要说明的是,在图2、图6和图7所示实施例中,一维向量、矩阵中的数据仅为一种示例,并不构成对实际工作中数据的限定。
[0319]
在本技术实施例中,可以通过初始模型中的n个融合层对样本图像特征和样本文本特征进行特征处理,得到融合图像特征和融合文本特征;并且可以通过初始模型中的映射层对融合图像特征和融合文本特征进行处理,进而可以在样本图像中确定预测对象。由于每个融合层中可以包括图像注意力层和文本注意力层,可以通过图像注意力层和文本注意力层,对样本图像特征和样本文本特征进行融合处理,以将样本图像特征和样本文本特征关联起来,相比通过模型分别对样本图像和样本文本进行处理,提高了模型确定目标对象的准确性。
[0320]
下面,在上述任一实施例的基础上,结合具体示例,对上述模型训练方法进行进一步详细说明。
[0321]
图8为本技术实施例提供的一种模型训练方法的过程示意图。请参见图8,以第一模型为mask-r cnn模型,第二模型为bert模型、初始模型为vilbert模型为例,进行说明。
[0322]
可以将样本图像输入到mask-r cnn模型中,以使mask-r cnn模型对样本图像进行初步处理。
[0323]
针对任意一个样本图像,mask-r cnn模型可以在样本图像中确定多个对象、以及对象的对象类别。针对样本图像中的任意一个对象,mask-r cnn模型可以生成对象的初始特征,并且可以根据对象类别在数据库中,确定对象类别对应的类别特征,将类别特征作为补充特征,以增强对象特征。mask-r cnn模型可以根据对象的初始特征、以及对象类别对应的类别特征,生成对象特征。确定多个对象特征之后,可以根据多个对象特征,生成样本图像特征。样本图像特征中可以包括多个对象特征,样本图像特征可以用矩阵表示。
[0324]
可以将样本文本输入到bert模型中,以使bert模型对样本文本进行初步处理。
[0325]
针对任意一个样本文本,bert模型可以对样本文本进行处理,得到该样本文本对应的样本文本特征。
[0326]
可选地,由于中文中存在同义词,语义具有多样性,bert模型可以对语义进行优化。例如,bert模型可以对“女生”和“女孩”进行优化处理,使得“女生”和“女孩”对应的样本文本特征相同。
[0327]
确定样本图像特征和样本文本特征之后,还可以对样本图像中的对象进行标注,确定标注对象。样本数据中可以包括将样本图像特征、样本文本特征和标注对象。可以将样本数据输入到vilbert模型,以使vilbert模型对样本图像特征和样本文本特征进行处理。
[0328]
如图8所示,vilbert模型中可以包括n个融合层和映射层。融合层的顺序可以通过i表示,i=1、2、3、
……
、n。针对任意一个融合层,融合层中可以包括图像编码器、图像注意力层、文本编码器和文本注意力层。
[0329]
当i=1时,在vilbert模型的第1个融合层中,可以通过图像编码器trm-11对样本图像特征进行处理,得到第一编码图像特征;可以通过文本编码器trm-12对样本文本特征进行处理,得到第一编码文本特征。进而可以通过图像注意力层co-trm-11对第一编码图像特征和第一编码文本特征进行融合处理,得到与文本特征关联的第一个中间图像特征;可以通过文本注意力层co-trm-12对第一编码图像特征和第一编码文本特征进行融合处理,得到与图像特征关联的第一个中间文本特征。
[0330]
i可以依次取1、2、3、
……
、n,以通过第i个融合层进行处理。
[0331]
当i=n时,在vilbert模型的第n个融合层中,可以通过图像编码器trm-n1对第i-1个中间图像特征进行处理,得到第n编码图像特征;可以通过文本编码器trm-n2对第i-1个中间文本特征进行处理,得到第n编码文本特征。进而可以通过图像注意力层co-trm-n1对第n编码图像特征和第n编码文本特征进行融合处理,得到与文本特征关联的第n个中间图像特征;可以通过文本注意力层co-trm-n2对第n编码图像特征和第n编码文本特征进行融合处理,得到与图像特征关联的第n个中间文本特征。可以将第n个中间图像特征确定为融合图像特征,以及将第n个中间文本特征确定为融合文本特征。
[0332]
确定融合图像特征和融合文本特征之后,则可以通过映射层对融合图像特征和融合文本特征进行处理,以将融合图像特征和融合文本特征映射到相同的维度,进而可以对融合图像特征和融合文本特征进行相似度计算,得到样本文本与样本图像中各个对象的相似度,并根据相似度确定预测对象。
[0333]
可选地,初始模型可以根据预测对象和标注对象确定损失函数,进而根据损失函数,更新初始模型的模型参数,对初始模型进行优化,直至得到训练完成的初始模型。
[0334]
在本技术实施例中,电子设备可以通过第一模型对样本图像进行初步处理,得到样本图像特征;可以通过第二模型对样本文本进行初步处理,得到样本文本特征。可以通过初始模型中的n个融合层和映射层对样本图像特征和样本文本特征进行处理,以在样本图像中确定预测对象,并根据预测对象和标注对象,更新初始模型的模型参数。由于初始模型中包括n个融合层,每个融合层中可以包括图像注意力层和文本注意力层,可以通过图像注意力层和文本注意力层,对样本图像特征和样本文本特征进行融合处理,以将样本图像特征和样本文本特征关联起来,相比通过模型分别对样本图像和样本文本进行处理,提高了模型确定目标对象的准确性。
[0335]
对初始模型训练完成之后,则可以通过初始模型对图像和文本进行处理。下面,结合图9,对使用模型的过程进行说明。
[0336]
图9为申请示例性实施例提供的一种图像处理方法的过程示意图。请参见图9,该方法可以包括:
[0337]
s901、获取待处理图像和目标文本。
[0338]
可选地,可以将待处理图像和目标文本输入到电子设备中,以使电子设备获取待处理图像和目标文本。
[0339]
例如,若目标文本为“穿黄衣服的女孩”,待处理图像可以为图像1,则可以将图像1和“穿黄衣服的女孩”输入到电子设备中,以使电子设备获取图像1和“穿黄衣服的女孩”。
[0340]
s902、通过目标模型对待处理图像和目标文本进行处理,以在待处理图像中确定目标对象。
[0341]
目标模型可以为图2所示实施例中训练完成的初始模型,或者图6所示实施例中训练完成的初始模型。
[0342]
电子设备可以确定目标模型,并将通过目标模型对待处理图像和目标文本进行特征处理,并计算相似度,以在待处理图像中确定目标对象。目标对象可以为待处理图像中与目标文本相似度最高的对象,也可以为待处理图像中与目标文本相似度在预设范围内的对象。
[0343]
例如,若目标对象为待处理图像中与目标文本相似度最高的对象,若目标文本为“黄衣服的女孩”,待处理图像可以为图像1,图像1中包括3个对象,分别对象1、对象2、对象3,其中对象1为穿黄衣服的女孩,对象2为一棵树,对象3为穿蓝衣服的女孩,则电子设备可以通过目标模型对该目标文本和待处理图像进行处理,计算目标文本与待处理图像中3个对象的相似度。假设,计算得到目标文本与对象1之间的相似度为90%、目标文本与对象2之间的相似度为20%、目标文本与对象3之间的相似度为70%,则电子设备可以通过目标模型确定对象1为穿黄衣服的女孩,并输出对象1。
[0344]
例如,若目标对象为待处理图像中与目标文本相似度在预设范围内的对象,预设范围为相似度70%-90%,若目标文本为“女孩”,待处理图像可以为图像1,图像1中包括3个对象,分别对象1、对象2、对象3,其中对象1为穿黄衣服的女孩,对象2为一棵树,对象3为穿蓝衣服的女孩,则电子设备可以通过目标模型对该目标文本和待处理图像进行处理,计算目标文本与待处理图像中3个对象的相似度。假设,计算得到目标文本与对象1之间的相似度为90%、目标文本与对象2之间的相似度为20%、目标文本与对象3之间的相似度为80%,则电子设备可以通过目标模型确定对象1和对象3为目标对象,并输出对象1和对象3,即穿黄衣服的女孩和穿蓝衣服的女孩。
[0345]
在本技术实施例中,电子设备可以获取待处理图像和目标文本,并通过目标模型对待处理图像和目标文本进行处理,以在待处理图像中确定目标对象。由于目标模型中包括融合层,每个融合层中可以包括图像注意力层和文本注意力层,可以通过图像注意力层和文本注意力层,对待处理图像的图像特征和目标文本的文本特征进行融合处理,实现了以文找图,提高了目标模型确定目标对象的准确性。
[0346]
图10为本技术示例性实施例提供的一种模型训练装置的结构示意图,请参见图10,该模型训练装置10可以包括:获取模块11、确定模块12、处理模块13和更新模块14,其
中,
[0347]
所述获取模块11用于,获取样本数据,所述样本数据中包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象,所述标注对象为所述样本图像中与所述样本文本相似度最高的对象;
[0348]
所述确定模块12用于,确定初始模型,所述初始模型中包括n个融合层和映射层,所述融合层包括图像编码器、图像注意力层、文本编码器和文本注意力层,所述图像注意力层和所述文本注意力层分别用于融合所述图像编码器和所述文本编码器输出的特征,所述为正整数;
[0349]
所述处理模块13用于,通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定与所述样本文本相似度最高的预测对象;
[0350]
所述更新模块14用于,根据所述预测对象和所述标注对象,更新所述初始模型的模型参数。
[0351]
本技术实施例提供的模型训练装置可以执行上述方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0352]
在一种可能的实施方式中,所述处理模块13具体用于:
[0353]
通过所述n个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征;
[0354]
通过所述映射层对所述融合图像特征和所述融合文本特征进行处理,以确定所述预测对象。
[0355]
在一种可能的实施方式中,所述n为大于1的整数;所述处理模块13具体用于:
[0356]
通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;
[0357]
通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,所述i依次取2、3、
……
、n,并将第n个中间图像特征确定为所述融合图像特征,以及将所述第n个中间文本特征确定为所述融合文本特征。
[0358]
在一种可能的实施方式中,所述处理模块13具体用于:
[0359]
通过所述第1个融合层中的图像编码器对所述样本图像特征进行处理,得到第一编码图像特征;
[0360]
通过所述第1个融合层中的文本编码器对所述样本文本特征进行处理,得到第一编码文本特征;
[0361]
通过所述第1个融合层中图像注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间图像特征;
[0362]
通过所述第1个融合层中文本注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间文本特征。
[0363]
在一种可能的实施方式中,所述处理模块13还用于:
[0364]
在所述样本图像特征中去除部分图像特征;和/或,
[0365]
在所述样本文本特征中去除部分文本特征。
[0366]
在一种可能的实施方式中,所述处理模块13具体用于:
[0367]
通过所述第i个融合层中的图像编码器对所述第i-1个中间图像特征进行处理,得到第i编码图像特征;
[0368]
通过所述第i个融合层中的文本编码器对所述第i-1个中间文本特征进行处理,得到第i编码文本特征;
[0369]
通过所述第i个融合层中的图像注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间图像特征;
[0370]
通过所述第i个融合层中的文本注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间文本特征。
[0371]
在一种可能的实施方式中,所述获取模块11具体用于:
[0372]
获取所述样本图像和所述样本文本;
[0373]
通过第一模型对所述样本图像进行处理,得到所述样本图像特征;
[0374]
通过第二模型对所述样本文本进行处理,得到所述样本文本特征
[0375]
根据所述样本文本对所述样本图像中的对象进行标注处理,以确定所述标注对象。
[0376]
在一种可能的实施方式中,所述获取模块11具体用于:
[0377]
通过所述第一模型在所述样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;
[0378]
根据所述样本图像中的多个对象、以及各对象的对象类别,生成所述样本图像特征。
[0379]
在一种可能的实施方式中,所述更新模块14具体用于:
[0380]
根据所述预测对象和所述标注对象,确定损失函数;
[0381]
根据所述损失函数,更新所述初始模型的模型参数。
[0382]
本技术实施例提供的模型训练装置可以执行上述方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0383]
图11为本技术示例性实施例提供的另一种模型训练装置的结构示意图,请参见图11,该模型训练装置20可以包括:获取模块21、确定模块22、处理模块23和更新模块24,其中,
[0384]
所述获取模块21用于,获取样本数据,所述样本数据中包括样本图像的样本图像特征、样本文本的样本文本特征和标注对象,所述标注对象与所述样本文本的相似度在预设范围内;
[0385]
所述确定模块22用于,确定初始模型,所述初始模型中包括n个融合层和映射层,所述融合层包括图像编码器、图像注意力层、文本编码器和文本注意力层,所述图像注意力层和所述文本注意力层分别用于融合所述图像编码器和所述文本编码器输出的特征,所述n为正整数;
[0386]
所述处理模块23用于,通过所述n个融合层和所述映射层对所述样本图像特征和所述样本文本特征进行处理,以在所述样本图像中确定预测对象,所述预测对象与所述样本文本的相似度在所述预设范围内;
[0387]
所述更新模块24用于,根据所述预测对象和所述标注对象,更新所述初始模型的
模型参数。
[0388]
本技术实施例提供的模型训练装置可以执行上述方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0389]
在一种可能的实施方式中,所述处理模块23具体用于:
[0390]
通过所述n个融合层对所述样本图像特征和所述样本文本特征进行处理,得到融合图像特征和融合文本特征;
[0391]
通过所述映射层对所述融合图像特征和所述融合文本特征进行处理,以确定所述预测对象。
[0392]
在一种可能的实施方式中,所述n为大于1的整数;所述处理模块23具体用于:
[0393]
通过第1个融合层对所述样本图像特征和所述样本文本特征进行处理,得到第1个中间图像特征和第1个中间文本特征;
[0394]
通过第i个融合层对所述第i-1个中间图像特征和第i-1个中间文本特征进行处理,得到第i个中间图像特征和第i个中间文本特征;其中,所述i依次取2、3、
……
、n,并将第n个中间图像特征确定为所述融合图像特征,以及将所述第n个中间文本特征确定为所述融合文本特征。
[0395]
在一种可能的实施方式中,所述处理模块23具体用于:
[0396]
通过所述第1个融合层中的图像编码器对所述样本图像特征进行处理,得到第一编码图像特征;
[0397]
通过所述第1个融合层中的文本编码器对所述样本文本特征进行处理,得到第一编码文本特征;
[0398]
通过所述第1个融合层中图像注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间图像特征;
[0399]
通过所述第1个融合层中文本注意力层对所述第一编码图像特征和所述第一编码文本特征进行融合处理,得到所述第1个中间文本特征。
[0400]
在一种可能的实施方式中,所述处理模块23还用于:
[0401]
在所述样本图像特征中去除部分图像特征;和/或,
[0402]
在所述样本文本特征中去除部分文本特征。
[0403]
在一种可能的实施方式中,所述处理模块23具体用于:
[0404]
通过所述第i个融合层中的图像编码器对所述第i-1个中间图像特征进行处理,得到第i编码图像特征;
[0405]
通过所述第i个融合层中的文本编码器对所述第i-1个中间文本特征进行处理,得到第i编码文本特征;
[0406]
通过所述第i个融合层中的图像注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间图像特征;
[0407]
通过所述第i个融合层中的文本注意力层对所述第i编码图像特征和所述第i编码文本特征进行融合处理,得到所述第i个中间文本特征。
[0408]
在一种可能的实施方式中,所述获取模块21具体用于:
[0409]
获取所述样本图像和所述样本文本;
[0410]
通过第一模型对所述样本图像进行处理,得到所述样本图像特征;
[0411]
通过第二模型对所述样本文本进行处理,得到所述样本文本特征
[0412]
根据所述样本文本对所述样本图像中的对象进行标注处理,以确定所述标注对象。
[0413]
在一种可能的实施方式中,所述获取模块21具体用于:
[0414]
通过所述第一模型在所述样本图像中进行对象识别,确定样本图像中的多个对象、以及各对象的对象类别;
[0415]
根据所述样本图像中的多个对象、以及各对象的对象类别,生成所述样本图像特征。
[0416]
在一种可能的实施方式中,所述更新模块24具体用于:
[0417]
根据所述预测对象和所述标注对象,确定损失函数;
[0418]
根据所述损失函数,更新所述初始模型的模型参数。
[0419]
本技术实施例提供的模型训练装置可以执行上述方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0420]
图12为本技术示例性实施例提供的一种图像处理装置的结构示意图,该图像处理装置30可以包括:获取模块31和处理模块32,其中,
[0421]
所述获取模块31用于,获取待处理图像和目标文本;
[0422]
所述处理模块32用于,通过目标模型对所述待处理图像和所述目标文本进行处理,以在所述待处理图像中确定目标对象;其中,所述目标模型为上述任一实施例介绍的模型训练方法训练得到的。
[0423]
本技术实施例提供的图像处理装置可以执行上述方法实施例所示的技术方案,其实现原理以及有益效果类似,此处不再进行赘述。
[0424]
本技术示例性实施例提供一种电子设备的结构示意图,请参见图13,该电子设备40可以包括处理器41和存储器42。示例性地,处理器41、存储器42,各部分之间通过总线43相互连接。
[0425]
所述存储器42存储计算机执行指令;
[0426]
所述处理器41执行所述存储器42存储的计算机执行指令,使得所述处理器41执行如上述方法实施例所示的模型训练方法,或者图像处理方法。
[0427]
相应地,本技术实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当所述计算机执行指令被处理器执行时用于实现上述方法实施例所述的模型训练方法,或者图像处理方法。
[0428]
相应地,本技术实施例还可提供一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时,可实现上述方法实施例所示的模型训练方法,或者图像处理方法。
[0429]
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0430]
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流
程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0431]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0432]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0433]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0434]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0435]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0436]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0437]
以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1