基于优化模糊深度网络的林木胸径材积精准预测方法
1.本发明属于林木参数研究技术领域,具体涉及一种基于优化模糊深度网络的林木胸径材积精准预测方法。
背景技术:
2.林木胸径与材积的精准预测在森林资源调查和国家木材战略储备及碳汇评估中发挥十分重要的作用。近年以来,针对林木参数预测的方法大致分为两类,分别为基于人工测量与激光点云的林木参数预测方法。上述两种方法在数据获取上存在差异,但建立预测模型的方法又具有一定的相似性。
3.基于每木检尺的林木参数预测方法通常建立候选模型估测林木参数值,结合树高残差方法确立树高-胸径预测模型,或利用逐步回归法和偏最小二乘法建立四种候选模型预估森林的蓄积量,或基于非线性混合效应模型预测人工林的冠积、树冠表面积及生物量。此类研究往往会选取很多常用的生长模型或相关的扩展模型作为候选模型,通过一系列的评价标准对其进行筛选,然而候选模型的类型和数量往往因研究目标而异。
4.随着激光测量技术的高速发展并应用于林业信息化,获取林木参数的方式从传统每木检尺转变为三维激光点云中生成。激光扫描具有非常高的距离探测能力和稳定性,同时,前人工作结合计算机图形学、机器学习等理论展开林木三维点云的处理分析,如:利用分水岭算法对林木点云进行树冠分割,采用支持向量机建立树种识别框架,或使用随机霍夫变换和八叉树分割估计单木胸径,并根据树木生长方向提取树高,也取得了一定的进展。
5.现今,随着人工智能技术不断取得新的突破,以及激光点云扫描技术的成熟,使得机器学习技术在林木点云处理中崭露头角,一些林木参数预测模型应运而生。如2020年提出的森林参数预测模型提出了一种分层估计方法,将来自合成孔径雷达(sar)、lidar和无源光学系统正演模型结合起来,生成真实森林林分的几何模型与电磁模型,并将二者相结合估计森林参数;2021年提出的胸径预测模型基于广义非线性混合效应方法,添加站点级别的随机效应提高模型的泛化能力,并以单木和激光点云层面的变量作为预测因子,实现了较高的预测精度。其中一些工作直接从森林点云中获取信息,基于林分尺度参数建立预测模型,如建立k近邻预测模型、异速生长模型、融合点云特征的预测模型和有限区域生长等方法开展瑞典大面积森林地上生物量预测、研究热带森林中胸径与森林生物量之间的关系、银杏人工林树冠覆盖率的计算、祁连山大野口森林林分的自动分割。还有一些研究对森林点云进行单株分割获取单株林木参数,然后采用随机森林、支持向量机、bp神经网络建立落叶松-云冷杉混交林单木胸径预测模型、构建大岗山人工林分断面积生长模型、创建乐县林场杉木的树高预测模型等。
6.尽管机器学习在林木参数预测上取得了一定的成就,但依然存在如下问题:1)实际林地中存在部分个体受到自然灾害或林木竞争影响发生坏死、压迫等成为异常样本,而大多林木参数预测模型缺少判断异常样本的机制,模型易受到该样本的干扰,其预测精度有待提升;2)基于机器学习的预测模型,采用试凑法、经验公式等方法确定模型参数,无法
对算法参数数量作进一步选择且依赖先验经验,相关预测模型在结构和模块上还有改进的空间;3)实时获取林木生长参数有利于大规模人工林的种植培育,而人工智能和机载激光雷达相互结合并运用于林木参数预测的相关工作目前还不多。
技术实现要素:
7.本发明所要解决的技术问题是针对现有技术的不足提供一种基于优化模糊深度网络的林木胸径材积精准预测方法,本基于优化模糊深度网络的林木胸径材积精准预测方法开展林木参数预测模型,建立林木参数之间的非线性关系,提出自适应算法以增强林木参数预测模型对不同林木品种的泛化能力,嵌入注意力机制模块增强网络的鲁棒性,融合鸽群优化算法实时调整模糊深度网络的参数,达到进一步提升模型的预测精度与学习能力。
8.为实现上述技术目的,本发明采取的技术方案为:
9.基于优化模糊深度网络的林木胸径材积精准预测方法,包括:
10.步骤1:通过机载激光雷达获取林地点云数据;
11.步骤2:对点云数据进行去噪处理,并采用点云地面点滤波方法对点云数据进行滤波,对滤波后的点云数据进行单木分割;
12.步骤3:根据分割后的单株树木点云,获取单株树木的林木参数,包括东西冠幅、南北冠幅、树高、点云密度和冠积;
13.步骤4:采用人工测绘方法获取对应树木的胸径和材积;
14.步骤5:将多株树木的东西冠幅、南北冠幅、树高、点云密度、冠积、胸径和材积作为训练样本数据集;
15.步骤6:建立林木参数预测网络,林木参数预测网络包括模糊深度网络和鸽群优化模块,采用训练样本数据集对林木参数预测网络进行训练,其中林木参数预测网络的输入为树木的东西冠幅、南北冠幅、树高、点云密度和冠积,输出为树木的胸径和材积,模糊深度网络训练完成后输出预测值并将预测值输送给鸽群优化模块,鸽群优化模块更新模糊深度网络的参数,当鸽群优化模块完成模糊深度网络的最优参数搜寻后,模糊深度网络依据最优参数完成自适应训练,建立最终的林木参数预测模型;
16.步骤7:采集待测林地点云数据并按照步骤2和步骤3的方法获取待测林地中每株树木的东西冠幅、南北冠幅、树高、点云密度和冠积,将树木的东西冠幅、南北冠幅、树高、点云密度和冠积输入至最终的林木参数预测模型,得到对应树木的胸径和材积的预测值。
17.作为本发明进一步改进的技术方案,所述的步骤3中单株树木的林木参数的获取方法为:
18.在单株树冠点云的东西方向选取最大距离为东西冠幅;在单株树冠点云的南北方向选取最大距离为南北冠幅;单株树冠点云最高点与水平面的垂直距离为树高;单株点云的总数量除以树冠的投影面积为点云密度;计算单株树冠点云的凸包体积,凸包体积即为冠积。
19.作为本发明进一步改进的技术方案,所述的步骤4中树木的胸径和材积的获取方法为:
20.在树木离地面1.3m处的树干部位,通过卷尺获取树干的周长,该周长为树木的胸
径;
21.选取树木的树干上部直径为处作为形点,d是树木胸径,测量形点到树梢的长度为h
t
,测量胸径的横断面积为sd,测量树木的树高为h,则树木的材积为:
[0022][0023]
式中:r为干形指数;s
vl
为树木的材积。
[0024]
作为本发明进一步改进的技术方案,所述步骤6中的模糊深度网络从输入至输出依次包括自适应模糊层、模糊推理层、基于注意力的权值更新层。
[0025]
作为本发明进一步改进的技术方案,所述的自适应模糊层的计算过程为:
[0026]
输入属性xu在自适应模糊层有k个模糊子集,u∈{1,2,3,4,5},其中x1、x2、x3、x4、x5是自适应模糊层的输入属性,依次分别为东西冠幅、南北冠幅、树高、点云密度和冠积,每个输入属性均有k个模糊子集;则自适应模糊层共有5
×
k个模糊子集;训练样本传入自适应模糊层中输入属性xu所属的第j个模糊子集,输出隶属度如公式(2)所示:
[0027][0028]
式中:xu在自适应模糊层的第j个模糊子集的中心为xu在自适应模糊层的第j个模糊子集的方差为j=1,
…
,k,输入属性的模糊子集总数皆为k,且k由鸽群优化模块更新,i=1,
…
,n,n为训练样本的个数,即训练样本的树木总株数;
[0029]
根据xu的n个训练样本求解的局部密度和距离i=1,
…
,n,u∈{1,2,3,4,5},局部密度计算公式为:
[0030][0031]
式中:是的局部密度,du为xu的截断距离,u∈{1,2,3,4,5},i=1,2,
…
,n,m=1,2,
…
,n;
[0032]
分别计算局部密度大于的所有训练样本与的欧式距离,其中最小值作为的距离如公式(4)所示:
[0033][0034]
式中:是的局部密度且m=1,2,
…
n;为与之间的欧
氏距离,u∈{1,2,3,4,5};若的局部密度最大,则且m≠i;
[0035]
计算作为输入属性xu进行聚类初始中心的可能性值如公式(5)所示:
[0036][0037]
式中:max(ρu)为ρu中n个局部密度的最大值;min(ρu)为ρu中n个局部密度的最小值;max(δu)为δu中n个距离的最大值;min(δu)为δu中n个距离的最小值;ρu为n个训练样本作为输入属性xu的局部密度,包括n个局部密度;δu为n个训练样本作为输入属性xu的距离,包括n个距离;
[0038]
步骤(a)、输入属性xu的n个训练样本中按照值大小进行降序排序,取前k个样本点作为xu的n个训练样本进行dpkm聚类的初始中心点;步骤(b)、计算输入属性xu的n个训练样本与k个类别中心的欧氏距离,按照最小距离分配原则,将训练样本分配到最近中心所在的类别中;步骤(c)、n个训练样本都完成一次分配后,计算每个类别的均值,将均值作为新的类别中心并更新类别中心;重复上述步骤(b)和步骤(c),直到类别中心的变化小于设定误差;完成dpkm聚类,此时k个聚类的中心为xu在自适应模糊层的第j个模糊子集的中心j=1,
…
,k;
[0039]
当输入属性xu在自适应模糊层的第j个模糊子集的中心以及所属dpkm聚类确立后,按照如下自适应算法计算xu在自适应模糊层的第j个模糊子集的方差
[0040]
首先计算xu的k个模糊子集中心的中心如公式(6)所示:
[0041][0042]
然后求解聚类的内部样本与的平均欧氏距离如公式(7)所示:
[0043][0044]
式中:表示的内部样本与欧氏距离;为的内部样本的数量;
[0045][0046]
式中:为的宽度因子;α为方差缩放系数,由鸽群优化模块更新;为输入属性xu的k个模糊子集中心两两之间最大距离;u∈{1,2,3,4,5},j=1,2,
…
,k。
[0047]
作为本发明进一步改进的技术方案,所述的模糊推理层的计算过程为:
[0048]
隶属度为模糊推理层的输入,采用乘积推理的方法,建立模糊推理层的模糊单元,
并计算第i株训练样本的第j个单元输出值作为模糊单元输出,如公式(9)所示:
[0049][0050]
式中:为第i株训练样本在不同输入属性的第j个模糊子集隶属度的乘积;归一化处理后为u∈{1,2,3,4,5},i=1,
…
,n,j=1,2,
…
,k,n为训练样本中树木总株数,模糊单元总数量为k。
[0051]
作为本发明进一步改进的技术方案,所述的基于注意力的权值更新层的计算过程为:
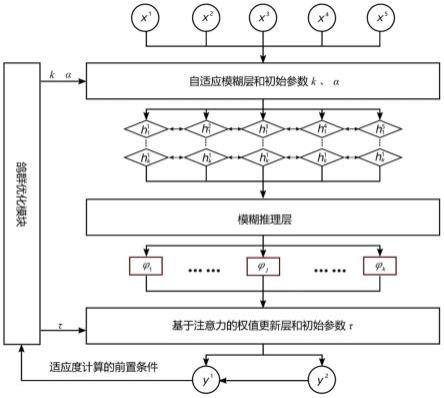
[0052]
损失函数如公式(10)所示:
[0053][0054]
式中:y1为胸径预测值,y2为材积预测值;为胸径实测值,为材积实测值;qi为第i株训练样本的注意力权重,i=1,2,
…
,n;
[0055]
模糊推理层输出的和胸径之间的连接权值为和胸径之间的连接权值为和材积之间的连接权值为则对所有的训练样本有:
[0056][0057]
式中:表示第i株训练样本从模糊推理层输出的第j个值;表示第i株训练样本的胸径预测值,表示第i株训练样本的材积预测值;j=1,2,
…
,k,i=1,2,
…
,n,n为训练样本总株数,模糊单元总数量为k;
[0058]
对训练样本进行归一化预处理,然后,训练样本中第i株林木参数矩阵含有7个实测的林木参数,林木参数矩阵zi中从左至右依次为东西冠幅、南北冠幅、树高、点云密度、冠积、材积和胸径,所有训练样本的东西冠幅平均值为avg1,所有训练样本的南北冠幅平均值为avg2,所有训练样本的树高平均值为avg3,所有训练样本的点云密度平均值为avg4,所有训练样本的冠积平均值为avg5,所有训练样本的材积平均值为avg6,所有训练样本的胸径平均值为avg7,每个林木参数在训练样本中的平均值矩阵为avg=[avg1,
…
,avg7],qi的计算方式如公式(12)所示:
[0059][0060]
式中:表示林木参数矩阵zi中从左往右第p个林木参数,avg
p
表示平均值矩阵avg从左往右第p个平均值,p∈{1,2,3,4,5,6,7};余弦相似度sim(zi,avg)与欧氏距离dist(zi,avg)均表示第i株树木的林木参数与平均值avg之间的内在联系;τ为注意力权值缩放系数,由鸽群优化模块更新;i=1,2,
…
,n;
[0061]
基于注意力的连接权值通过反向传播的方式不断更新,更新方式如公式(13)所示:
[0062][0063]
式中:η取值范围为0<η<1,表示学习效率;t为当前迭代次数;
[0064]
基于注意力的连接权值的初始值随机给定,通过反向传播的方式不断更新,当迭代次数达到最大时,终止更新。
[0065]
作为本发明进一步改进的技术方案,所述的鸽群优化模块的计算过程为:
[0066]
鸽群优化模块用于优化模糊深度网络中的参数k、α、τ,将k、α、τ的取值组合称之为模型参数组合δ[k,α,τ],参数搜索空间范围中,k为0~100且必须为整数,α取值为0~30,τ取值为0~10;鸽群优化模块初始为l组模型参数δ
l
[k
l
,α
l
,τ
l
](l=1,2,
…
l),即该鸽群优化模块有l组模型参数开展优化和t
max
次迭代;
[0067]
第t次迭代的第l组模型参数组合取值为其适应度如公式(14)所示:
[0068][0069]
式中:t是鸽群当前迭代次数;l=1,2,
…
l;i=1,2,
…
,n,n为训练样本总株数;为模糊深度网络的胸径预测值,为模糊深度网络的材积预测值,为胸径实测值,为材积实测值;
[0070]
模型参数组合的搜索策略按照迭代次数分为两个阶段,初始为第一个阶段,当迭
代次数达到最大迭代次数t
max
的80%时进入第二个阶段,具体的搜索策略如下所示:
[0071]
模型参数组合的搜索策略的第一个阶段的计算过程如公式(15)所示:
[0072][0073]
式中:为余弦迭代权重项;t
max
为鸽群最大迭代次数;ε是一个极小常数;rand(0,1)为[0,1]之间的随机数;数组为第t次迭代的第l组模型参数组合为第t次迭代的第l组模型参数组合为数组的速度;l=1,2,
…
l;
[0074]
当l组模型参数组合的最优参数组合适应度长时间不发生改变时,将l组模型参数组合按照适应度进行降序排序,适应度较高的组参数进行种群变异,变异方式如公式(16)所示:
[0075][0076]
式中:为种群变异的更新值,做取整处理;如果在0~100范围内,否则否则取值在0~30范围内就更新,否则不更新;取值在0~10范围内就更新,否则不更新;rand(-1,1)为[-1,1]范围里的随机数;
[0077]
模型参数组合搜索策略的第二个阶段的计算过程如公式(17)所示:
[0078][0079]
式中:式中:为t时刻第l组模型参数的暂定取值;若则更新第l组模型参数,即否则不更新,即l=1,2,
…
l;
[0080]
每次迭代后,舍弃部分适应度值较高的模型参数组合,更新模型参数群体数量l,当迭代次数达到最大迭代次数t
max
或者只剩一组模型参数组合时结束迭代,输出此时l组模型参数组合中适应度最低的参数组合,即给定参数k、α、τ的最优取值,并将该模型参数组合传入模糊深度网络完成训练。
[0081]
本发明的有益效果为:
[0082]
本发明提出优化的模糊深度网络开展橡胶树林木参数预测模型,建立林木参数之间的非线性关系,提出自适应算法以增强预测模型对不同橡胶林木品种的泛化能力,嵌入注意力机制模块增强网络的鲁棒性,融合鸽群优化算法(pigeon-inspired optimization)实时调整模糊深度网络的参数,达到进一步提升模型的预测精度与学习能力。面向不同品种的橡胶林木,本发明计的橡胶林木参数预测模型能够精准反演复杂的林木参数并为橡胶树不同品种的营林造林及生长抚育提供量化决策与数据支撑。
[0083]
本发明基于模糊深度网络,可以对复杂的预测模型精准化,提出自适应学习算法确定网络结构,结合鸽群优化算法搜寻最优参数,使得自适应算法效果提升,并加入注意力机制判断训练样本的异常数据。本发明的林木参数预测模型进一步提升了橡胶林关键参数的预测结果精度。
[0084]
本发明通过建立林木参数预测模型,由机载激光点云自动获取的部分林木参数预测单株橡胶树的胸径和材积。该林木参数预测模型结合了模糊深度网络、注意力机制和鸽群优化算法的优点,可根据林木参数之间的非线性关系、异常样本的权重分配、模型参数寻优策略,实现自适应建立模型,可适用于大多数复杂林木关系的建立,具有良好的普适性和鲁棒性。基于模糊深度网络与多种人工智能算法相结合,根据林木参数预测模型完成不同品种的橡胶树自动完成模型的训练,且适应于同林地同品种橡胶树关键参数的预测,是人工智能技术在林业邻域的落地应用之一。
附图说明
[0085]
图1中的(a)为橡胶林样地1的位置示意图。
[0086]
图1中的(b)为橡胶林样地2的位置示意图。
[0087]
图1中的(c)为橡胶林样地3的位置示意图。
[0088]
图1中的(d)为热垦628示意图。
[0089]
图1中的(e)为热垦525示意图。
[0090]
图1中的(f)为热研72059示意图。
[0091]
图1中的(g)为pr107示意图。
[0092]
图2中的(a)为橡胶林样地1的单木分割结果图。
[0093]
图2中的(b)为橡胶林样地2的单木分割结果图。
[0094]
图2中的(c)为橡胶林样地3的单木分割结果图。
[0095]
图3为热垦628、热垦525、热研72059和pr107的橡胶树点云数据。
[0096]
图4为林木参数预测网络总体框架图。
[0097]
图5为基于注意力的权值更新过程图。
[0098]
图6中的(a)为鸽群优化模块面向热研72059橡胶树网络参数迭代优化结果图。
[0099]
图6中的(b)为鸽群优化模块面向热垦525橡胶树网络参数迭代优化结果图。
[0100]
图6中的(c)为鸽群优化模块面向热垦628橡胶树网络参数迭代优化结果图。
[0101]
图6中的(d)为鸽群优化模块面向pr107橡胶树网络参数迭代优化结果图。
[0102]
图7为鸽群优化模块群体最优参数组的适应度随着网络训练次数增加的变换曲线图。
[0103]
图8中的(a)为pr107橡胶树在反向传播过程中损失值的迭代曲线图。
[0104]
图8中的(b)为热研72059橡胶树在反向传播过程中损失值的迭代曲线图。
[0105]
图8中的(c)为热垦525橡胶树在反向传播过程中损失值的迭代曲线图。
[0106]
图8中的(d)为热垦628橡胶树在反向传播过程中损失值的迭代曲线图。
[0107]
图9中的(a)为胸径预测值与实测值比对分析图
[0108]
图9中的(b)为材积预测值与实测值比对分析图。
具体实施方式
[0109]
下面根据附图对本发明的具体实施方式作出进一步说明:
[0110]
近年来,机载激光雷达在森林资源调查与参数反演上具有广泛的应用,但也受到视角遮蔽导致不易测量的复杂林木参数,如胸径、材积等获取困难问题。针对此问题,本实施例提供一种基于优化模糊深度网络的林木胸径材积精准预测方法,首先,构造了融合注意力机制模块的优化模糊学习网络,并加入基于鸽群优化算法的多参数自主优化模块。其次,运用单株分离算法结合人工林调从三个林地的机载点云中提取四个品种的橡胶树(热垦628、热垦525、热研72059、pr107)的多个生长参量作为训练集带入深度学习网络中优化训练参数。最后,四个品种的测试集分别带入训练好的网络中以预测林木关键参量并与真实值比对分析,结果表明四种橡胶树胸径预测值和实测值的对比结果为:rmse《1.75cm,r2》91.42%;四种橡胶树材积预测值和实测值的对比结果都满足:rmse《0.052m3,r2》90.14%。相较于传统的后向传播与径向基神经网络,本文的深度学习网络获取的林木参数反演结果相关性高出4-9%。本实施例将最新的人工智能技术应用于林地机载激光点云中实现林木胸径与蓄积量的精准预测,能够满足大范围橡胶林参数反演与经营调查。具体步骤阐述如下。
[0111]
1、材料与数据:
[0112]
1.1、研究区与数据采集:
[0113]
研究区域位于儋州市橡胶树种植园内,海南岛西北部,本实施例从其中选取三个多品种橡胶林样地,在谷歌地图中如图1中的(a)、(b)、(c)所示。该地区地形是典型的丘陵高原,属热带季风气候,年平均降水量1815毫米,雨季(5月至10月)占全年总降雨量的89%以上,年平均气温约23℃,能够满足橡胶树的生长需要。三个样地中热垦628、热垦525、热研72059、pr107橡胶树品种是具有高产稳产、抗逆性强、存树率高等特点的优良品种,在海南地区均有大规模种植。其中,热垦628抗寒与抗风能力都比较强,是产量相对稳定且适应广的优良品种;热垦525和热垦523生长速度快,早熟,产量较高,是优良的胶木兼优品种。pr107初期割胶产量低,但其干胶含量高、耐刺激、耐高频割胶,后期干胶产量不断增加,是一个优良的高产品种。因此,在多品种橡胶树人工种植园中选取上述四个品种的橡胶树(树龄不同),如图1中的(d)、(e)、(f)、(g)所示分别为热垦628、热垦525、热研72059、pr107。
[0114]
搭载velodyne hdl-32e激光雷达传感器的机载激光雷达,能够实现从-30.67
°
到+10.67
°
垂直视野(fov),提供一个360
°
的水平视野,工作频率为10hz,测量范围为70m,测量的精度为+/-2cm。机载激光雷达的拍摄模式设置为连续拍摄,飞线路线为预先编程的“来回矩形平行”路线(如图1中的(b)中虚线),飞行速度、飞行高度和激光扫描重叠分别设置为10m/s、30m(高于起飞位置)、30%,旨在保证枝干参数的获取完整和清晰的橡胶树垂直结
构,最终提取的点云以las 1.2格式存储。
[0115]
1.2、训练样本与测试样本:
[0116]
通过机载激光雷达获取橡胶树林地的点云数据后,使用高斯滤波进行去噪处理,并采用点云地面点滤波(csf)消除地形的不利因素。然后,本实施例采用了现有的双高斯滤波器和能量函数最小化的单木分割方法,该方法在中国亚热带森林具有普适性。经实验验证后适用于橡胶林地,在树冠的交界处也有较好的分割效果,三块橡胶树样地的分割结果用不同颜色表示,具体如图2所示。图2中的(a)为橡胶林样地1的单木分割结果图。图2中的(b)为橡胶林样地2的单木分割结果图。图2中的(c)为橡胶林样地3的单木分割结果图。
[0117]
三块多克隆型多品种橡胶树样地共有1364株橡胶树林木,以单株枝干尽可能完整的原则,通过人工目视检验单株点云数据,从样地中选出813株林木,包含四个品种(每个品种200株左右),不同品种的具体单株形态特征如图3所示。图3为不同克隆品种的橡胶树点云数据。图3中,自上至下;第一行和第二行的单株橡胶树为热垦628;第三行和第四行的单株橡胶树为热垦525;第五行和第六行的单株橡胶树为热研72059;第七行和第八行的单株橡胶树为pr107。
[0118]
热垦628树身提拔、茎干直立,几乎无分枝,树冠较小,呈扫帚型,叶片椭圆、肥厚、有光泽,三小叶分离。热垦525树体歪斜少,枝干产生分枝的高度较低、角度较大,分枝数量较多,树冠较大,呈多头型。热研72059树体较柔软、容易弯曲、下垂枝条较多,分枝数量较多且分枝角度较大,树冠较大,呈扇形。pr107树体较直,抗风能力强,枝干产生分枝的高度较高,分枝较少,二分枝较多,树冠较小,呈扫帚型,叶长椭圆形,叶缘具规则小波浪。
[0119]
根据分割后的单株橡胶树点云,按照下列方法自动获取林木参数中东西冠幅、南北冠幅、树高、点云密度和冠积,方法具体如下所示。在每棵树冠点云的东西方向选取最大距离为东西冠幅参数;南北冠幅的参数在南北方向提取类似;单株点云最高点与水平面的垂直距离为树高参数;单株点云的总数量,除以树冠的投影面积即点云密度;使用alphashape方法计算单株树冠点云的凸包体积,即为冠积参数。
[0120]
由于橡胶树胸径、材积等林木参数不易从机载单株点云中直接获取,本实施例采用人工测绘的方式获取橡胶树的胸径和材积,具体方法如下所示。在橡胶树离地面1.3m处的树干部位,通过卷尺获取树干的周长,进而得出胸径参数。使用测树学方法获取立木材积参数,实际测量中选取橡胶树干上部直径为处作为形点,d是橡胶树胸径,测量形点到树梢的长度为h
t
,测量胸径的横断面积sd,测量橡胶树的树高h,利用如下公式获取橡胶树材积。
[0121][0122]
式中:r为干形指数;s
vl
为橡胶树材积。从单株点云自动获取参数和人工测绘后,获取每个品种200株左右的林木参数,并对其划分训练集和测试集,热垦628、热垦525、热研72059、pr107四种橡胶树的林木参数与训练样本如表1所示。
[0123]
表1为研究样地中不同品种橡胶树林木参数与训练样本:
[0124][0125]
2、林木参数预测模型:
[0126]
2.1、模型总体架构设计:
[0127]
胸径、材积等林木参数不易从机载单株点云中获取,通过找寻林木参数之间的对应关系,建立林木参数预测模型获取胸径、材积等参数十分重要。多品种橡胶树人工林具有相同土壤、气候等条件,通常同一橡胶树品种的林木参数在该品种林木参数平均值附近呈正态分布,但存在橡胶树坏死、种内竞争等因素导致部分个体的林木参数与其余群体存在较大差异,因此要求预测模型能够自主识别差异个体。面对橡胶树人工种植园中存在多个品种,不同品种的生长形态存在差异,因此参数预测时需要自适应的学习;此外预测模型的参数优化也极大的影响预测效果。
[0128]
对常用的神经网络预测模型进行综合研究发现,注意力机制有效增强预测模型抗干扰能力,加入林木参数注意力机制,提升林木参数预测模型的鲁棒性,使得预测模型精度上升。
[0129]
模糊深度网络中模糊子集的隶属度函数往往采用高斯函数,自适应确定模糊子集的中心和方差,体现了模糊深度网络的学习能力。因此,本实施例提出密度峰值聚类算法(density peaks clustering,dpc)与k-means算法相结合的dpkm算法确定隶属度函数的中心,并根据中心之间的欧氏距离提出自适应确定方差的算法。鸽群优化算法(pigeon-inspired optimization,pio)可以有效解决模糊深度网络的参数优化问题,因此设计了融合鸽群优化模块与模糊深度网络的林木参数预测模型。
[0130]
本实施例提出的林木参数预测网络总体框架如图4所示,共分为模糊深度网络和鸽群优化模块。鸽群优化模块更新模糊深度网络的参数,网络完成训练后输出预测值并返回鸽群模块,作为鸽群模块给出参数适应度值求解的前置条件。当鸽群模块完成模糊深度网络的最优参数搜寻后,模糊深度网络依据最优参数完成自适应训练,建立最终的林木参数预测模型。模糊深度网络由输入至输出,分别为自适应模糊层、模糊推理层、基于注意力的权值更新层。x1、x2、x3、x4、x5是自适应模糊层的输入属性,分别为东西冠幅、南北冠幅、树高、点云密度、冠积,每个输入属性都有相同的模糊子集数量,模糊子集隶属度函数的中心和方差由自适应算法确定。输入属性的样本传入自身模糊子集输出隶属度值和方差由自适应算法确定。输入属性的样本传入自身模糊子集输出隶属度值xu对应的隶属度为u∈{1,2,3,4,5},j=1,
…
,k,模糊子集总数量为k。乘积推理确定模糊推理层的模糊单元,隶属度h传入模糊单元,一个单元对应一个输出,输出值为j=1,
…
,k,模糊单元总数量为k。传入基于注意力的权值更新层,该层通过反向传播的方式不断更新连接权值,最后经过加权运算输出预测值y1、y2,其中y1为胸径预测值,y2为材积预测值。
[0131]
2.2、自适应模糊层:
[0132]
输入属性xu在自适应模糊层有k个模糊子集,u∈{1,2,3,4,5},则自适应模糊层共有5
×
k个模糊子集。训练样本传入自适应模糊层中输入属性xu所属的第j个模糊子集,输出隶属度如公式(2)所示。
[0133][0134]
式中:xu在自适应模糊层的第j个模糊子集的中心、方差分别为xu的训练样本依据本实施例提出dpkm算法完成聚类,为聚类中心;根据之间的欧氏距离,及所属dpkm聚类内部的样本密度,自适应确定方差j=1,
…
,k,输入属性的模糊子集总数皆为k,且k由鸽群优化模块更新,i=1,
…
,n,n为训练样本的橡胶树总株数。
[0135]
dpkm算法根据xu的n个训练样本求解的局部密度和距离并依据上述二者计算作为聚类初始中心的可能性值然后进行聚类,具体方法如下所示,i=1,
…
,n,u∈{1,2,3,4,5}。
[0136][0137]
式中:是的局部密度,du为xu的截断距离,u∈{1,2,3,4,5},i=1,2,
…
,n,m=1,2,
…
,n。计算需要考虑xu的n个训练样本与的欧氏距离,以截断距离du确定的邻域,在公式(3)中截断距离放大邻域内训练样本对的局部密度影响,降低邻域外样本点的作用;du的选取原则,让xu训练样本中邻域内的个数与总株数n的比值为1%~2%。xu的n个训练样本按照局部密度的大小进行降序排序,局部密度大于的训练样本中任意俩个样本之间最小的欧氏距离,作为的距离如下式所示。
[0138][0139]
式中:是的局部密度且m=1,2,
…
n;为与之间的欧氏距离,u∈{1,2,3,4,5}。特别的,若的局部密度最大,且m≠i。
[0140]
当的局部密度和距离确定后,计算作为输入属性xu进行dpkm聚类时初始中心的可能性值如公式(5)所示。
[0141][0142]
式中:max(ρu)、min(ρu)分别为ρu中n个局部密度的最大值、最小值;max(δu)、min(δu)分别为δu中n个距离的最大值、最小值。公式(5)目的是将不同尺度的局部密度ρu和距离δu,归一化为同一尺度的乘积。ρu是指第u个输入属性的局部密度,第u个输入属性有n个局部
密度。δu是指第u个输入属性的距离,第u个输入属性有n个距离。
[0143]
至此,xu的n个训练样本中按照值大小进行降序排序,取前k个样本点作为xu的n个训练样本进行dpkm聚类的初始中心点;其次,计算输入属性xu的n个训练样本与k个类别中心的欧氏距离,按照最小距离分配原则,将训练样本分配到最近中心所在的类别中;再次,n个样本都完成一次分配后,计算每个类别的均值,更新类别中心,重复上述二个步骤(即其次和再次二个步骤),直到类别中心的变化小于设定误差;完成dpkm聚类,此时k个聚类的中心为xu的模糊子集中心j=1,
…
,k。
[0144]
当输入属性xu的模糊子集中心以及所属dpkm聚类确立后,按照如下自适应算法计算xu的模糊子集方差首先计算xu的k个模糊子集中心的中心如公式(6)所示。
[0145][0146]
然后求解聚类的内部样本与的平均欧氏距离是计算方差的前置条件,如公式(7)所示。
[0147][0148]
式中:表示的内部样本与欧氏距离;为的内部样本的数量。
[0149][0150]
式中:为的宽度因子;α为方差缩放系数,由鸽群优化模块更新;为输入属性xu的k个模糊子集中心两两之间最大距离;u∈{1,2,3,4,5},j=1,2,
…
,k。
[0151]
本层给定初始的模糊子集数量k和方差缩放系数α,当鸽群优化模块传递新的k、α取值后,自适应模糊层的模型结构也随之改变。
[0152]
2.3、模糊推理层:
[0153]
模糊深度网络对不同的输入属性依次模糊化处理,以便林木参数之间复杂的非线性关系进行模糊推理,在处理难以精准化的复杂模型中显得十分有效,这一点弥补了传统神经网络的缺陷。
[0154]
隶属度为模糊推理层的输入,采用乘积推理的方法,建立模糊推理层的模糊单元,并计算第i株训练样本的第j个单元输出值作为模糊单元输出。
[0155][0156]
式中:为第i株训练样本在不同输入属性的第j个模糊子集隶属度的乘积;归一化处理后为u∈{1,2,3,4,5},i=1,
…
,n,j=1,2,
…
,k,n为训练样本中橡胶树总株数,模糊单元总数量为k。
[0157]
2.4、基于注意力的权值更新层:
[0158]
基于注意力的连接权值w的初始值随机给定,通过反向传播的方式不断更新如图5所示,当迭代次数达到最大时,终止更新。模糊推理层的值作为本层的输入,与连接权值w进行加权运算输出预测值y,实现模糊深度网络的反模糊化计算。
[0159]
损失函数融合了预测值y、实测值注意力权值q,如公式(10)所示。
[0160][0161]
式中:y1为胸径预测值,y2为材积预测值;为对应的实测值;qi为第i株训练样本的注意力权重,i=1,2,
…
,n。适应度值和胸径之间的连接权值为和胸径之间的连接权值为和材积之间的连接权值为则对所有的训练样本有:
[0162][0163]
式中:表示第i株训练样本从模糊推理层输出的第j个值;表示第i株训练样本的胸径预测值,表示第i株训练样本的材积预测值;j=1,2,
…
,k,i=1,2,
…
,n,n为训练样本总株数,模糊单元总数量为k。
[0164]
注意力机制本质是权重分配,在损失函数中对橡胶树样本分配权重q,对异常生长状态的橡胶树训练样本具有抗干扰能力。为了消除不同林木参数之间量纲的影响,对训练样本进行归一化预处理。然后,训练样本中第i株林木参数矩阵共有7个实测的林木参数分别为东西冠幅、南北冠幅、树高、点云密度、冠积、材积、胸径,每个林木参数在训练样本中的平均值矩阵为avg=[avg1,
…
,avg7],qi由训练样本中zi与avg之间的内在联系获取。
[0165][0166]
式中:表示林木参数矩阵zi中从左往右第p个林木参数,avg
p
表示平均值矩阵avg从左往右第p个平均值,p∈{1,2,3,4,5,6,7};余弦相似度sim(zi,avg)与欧氏距离dist(zi,avg)表示第i株橡胶树林木参数与平均值avg之间的内在联系;τ为注意力权值缩放系数由鸽群优化模块更新;i=1,2,
…
,n。
[0167]
连接权值w通过反向传播的方式不断更新,更新方式如公式(13)所示。
[0168][0169]
式中:η取值范围为0<η<1,表示学习效率;t为当前迭代次数。
[0170]
同时,给定初始的注意力权值缩放系数τ,鸽群优化模块每次更新τ值时,模糊深度网络的林木参数预测效果也随之改变。
[0171]
2.5、鸽群优化模块:
[0172]
该模块是对模糊深度学习网络中的关键参数k、α、τ的优化,k为自适应模糊层的模糊子集总数、α为公式(8)的方差缩放系数、τ为公式(12)的注意力权值缩放系数τ。将k、α、τ的取值组合称之为模型参数组合δ[k,α,τ],参数搜索空间范围中,k为0~100且必须为整数,α取值为0~30,τ取值为0~10。鸽群优化模块初始为l组模型参数δ
l
[k
l
,α
l
,τ
l
](l=1,2,
…
l),即该模块有l组模型参数开展优化和t
max
次迭代,第t次迭代按照本文的搜索策略对的取值进行更新,当迭代终止后,搜寻l组模型参数中最优的参数组合δ
l
,并传入模糊深度网络中,完成模糊深度网络的训练。
[0173]
首先,自适应模糊层的参数k、α更新会导致该层输出值的更新;其次,注意力机制的系数τ更新会影响注意力权值q的计算,进而影响损失函数即公式(10)对连接权值w的迭代;最后,模糊深度学习网络的预测值随着与连接权值w的更新而发生改变。本实施例利用已经完成的模糊深度训练模型输出预测值和实测值,计算模型参数组合的适应度,如公式(14)所示,适应度值越低说明此组参数越接近最优模型参数组合。
[0174][0175]
式中:第t次迭代的第l组模型参数组合取值为t是鸽群当前迭代次数;l=1,2,
…
l;i=1,2,
…
,n,n为训练样本总株数;为模糊深度网络的胸径、材积预测值,为与对应的实测值。
[0176]
模型参数组合的搜索策略按照迭代次数分为两个阶段,初始为第一个阶段,当迭代次数达到最大迭代次数的80%时进入第二个阶段,具体的搜索策略如下所示。
[0177]
在模型参数组合搜索策略的第一个阶段,本实施例提出余弦迭代权重项和种群变异思想帮助个体跳出局部最优解,以便给定最优的模型参数组合,使得模糊深度网络完成训练。加入余弦迭代权重项,使得迭代初期更注重全局搜索能力,迭代后期局部搜索能力更强一些,符合实际迭代需求,如下所示。
[0178][0179]
式中:为余弦迭代权重项;t
max
为鸽群最大迭代次数;ε是一个极小常数;rand(0,1)为[0,1]之间的随机数;第t次迭代的第l组模型参数组合的取值为1)为[0,1]之间的随机数;第t次迭代的第l组模型参数组合的取值为值更新时需要进行取整处理;为数组的速度;l=1,2,
…
l;
[0180]
为了进一步加强pio算法跳出局部最优解的能力,当l组模型参数组合的最优参数组合适应度长时间不发生改变时,说明本实施例的林木参数预测模型陷入局部极值。此时,将l组模型参数组合按照适应度进行降序排序,l=1,2,
…
l,适应度较高的组参数进行种群变异,变异方式如下所示。
[0181][0182]
式中:为种群变异的更新值,做取整处理;如果在0~100范围内,否则按照的更新方式,取值分别在0~30、0~10范围内就更新,否则不更新;rand(-1,1)为[-1,1]范围里的随机数。
[0183]
在模型参数组合搜索策略的第二个阶段,调整模型参数的更新策略,假设δc(t)是t时刻所有模型参数组合的中心位置,参数组朝着中心位置飞行。
[0184][0185]
式中:式中:为t时刻第l组模型参数的暂定取值;若则更新第l组模型参数否则不更新l=1,2,
…
l。每次迭代后,舍弃部分适应度值较高的模型参数组合,更新模型参数群体数量l,这样既保留较优的模型参数组合又同时保证算法的收敛。当迭代次数达到最大迭代次数t
max
或者只剩一组模型参数组合时结束迭代,输出此时l组模型参数组合中适应度最低的参数组合,即给定参数k、α、τ的最优取值,并将该模型参数组合传入模糊深度网络完成训练。
[0186]
3、结果与讨论:
[0187]
3.1、鸽群优化模块的训练与测试结果:
[0188]
林木参数预测模型的训练和测试均是搭载了amd ryzen 7 4800h cpu@2.9ghz处理器和16gb-ram的windows10-64位的服务器上进行。在本实施例构建的林木参数预测模型中,权值更新层的最大迭代次数设置为200,学习效率η设置为8;鸽群优化模块的模型参数组合总数l设置为32,最大迭代轮次t
max
设置为50。
[0189]
初始轮次的32组模型参数进行随机取值,均匀的分布在参数搜索空间,随着鸽群模块的不断迭代,模型参数组合中k、α、τ的取值不断更新,不同品种训练集在迭代不同阶段的最优模型参数组合结果如表2所示,各品种的32组参数逐渐向最优数组收敛,表明鸽群模块能够自适应学习不同品种橡胶树的最优模型参数组合,如图6所示。图6中的(a)为鸽群优化模块面向热研72059橡胶树网络参数迭代优化结果图。图6中的(b)为鸽群优化模块面向热垦525橡胶树网络参数迭代优化结果图。图6中的(c)为鸽群优化模块面向热垦628橡胶树网络参数迭代优化结果图。图6中的(d)为鸽群优化模块面向pr107橡胶树网络参数迭代优化结果图。
[0190]
表2为鸽群优化模块的模型参数组合在不同阶段的最优结果:
[0191][0192]
鸽群模块寻找训练集的最优模型参数组合的迭代过程中每一轮次有32组模型参数,其中适应度最低的为本轮最优模型参数组合,不同迭代阶段的最优模型参数组合构成的适应度曲线如图7所示。最优模型参数组合的适应度呈现下降趋势,说明本实施例的林木参数预测模型是一个全局优化过程。不同品种训练集的适应度曲线,在前30个epoch有显著的减少,表明林木参数预测模型的参数在快速靠近最优数组。模型参数依次传入模糊深度
网络的相应模块,在模糊深度网络依据训练样本自适应构建网络结构的基础上,调整神经网络中的相关系数,所以在初始轮次的最优参数组也能达到一个较好的适应度值。经过50个epoch后,热研72059、热垦525、热垦628、pr107训练样本的适应度值分别收敛到0.025、0.022、0.016、0.015,说明本实施例构建的林木参数预测模型具备精准参数预测的能力。
[0193]
当鸽群优化模块确认不同品种的最优模型参数组合后,传入模糊深度网络中完成各品种林木参数预测模型的训练。此时,在基于注意力的权值更新层中,训练过程中损失值e如图8所示。图8中的(a)为pr107橡胶树在反向传播过程中损失值的迭代曲线图。图8中的(b)为热研72059橡胶树在反向传播过程中损失值的迭代曲线图。图8中的(c)为热垦525橡胶树在反向传播过程中损失值的迭代曲线图。图8中的(d)为热垦628橡胶树在反向传播过程中损失值的迭代曲线图。为了提高本实施例预测模型的训练效率,在基于注意力的权值更新层中采用小批量梯度下降(mini-batch gradient descent)方法进行反向传播,导致回归损失值的局部振荡。但是,随着学习过程的不断迭代,损失值e总体呈下降趋势,表明本实施例的模糊深度网络具有较好的收敛性。经过100次迭代后,pr107、热研72059、热垦525和热垦628的损失值e分别收敛到0.00176、0.00349、0.00345、0.00072,说明本实施例构建的模糊深度网络具备较好的林木参数预测能力。
[0194]
3.2、和现有方法比对:
[0195]
基于本实施例的预测模型和传统方法,橡胶树胸径、材积参数的预测结果如表3所示。bp(back propagation)神经网络是基于多层的前馈神经网络的方法,对于网络结构的确定依赖经验和试凑,且激励函数具有全局性,会相互产生干扰,因此容易陷入局部最小的问题。rbf(radial basis function)神经网络和bp都适用于非线性模型建立,但rbf的局部激励函数克服bp全局激励函数的相互干扰问题,且对于新的训练集,只需要隐含层神经元节点数及连接权值改变,学习速度较bp算法有较大的提高,收敛性也更容易保证,因此rbf容易获得更优的结果。grnn(general regression neural network)是径向基神经网络的一种,相比较传统的径向基网络,在隐含层和输出层之间增加了求和层,在样本数据较少、数据不稳定等方面比rbf更具优势。然而,rbf和grnn神经网络往往通过试凑法和经验公式确定网络结构,依赖先验经验;同时,上述方法缺乏判断训练样本中异常数据的机制,降低了神经网络的鲁棒性。本实施例方法基于模糊深度网络,可以对复杂的预测模型精准化,提出自适应学习算法确定网络结构,结合鸽群优化算法搜寻最优参数,使得自适应算法效果提升,并加入注意力机制判断训练样本的异常数据。表3列出了四种方法对胸径、材积预测的比较结果,从表中看出本实施例方法在决定系数(r2)、均方根误差(rmse)、平均绝对百分比误差(mape)三种指标上都取得了更好的量化结果,可见,本实施例的林木参数预测模型进一步提升了橡胶林关键参数的预测结果精度。
[0196]
表3为不同方法的林木参数预测结果:
[0197]
[0198]
3.3、林木参数预测结果分析:
[0199]
当模糊深度网络通过鸽群优化模块确立最优模型参数后,模糊深度网络根据不同橡胶树品种训练集,自适应建立各品种的林木参数预测模型。表4给出热垦628、热垦525、热研72059、pr107四种橡胶树胸径、材积的实际测量值和本实施例预测值。同时,通过比对指标r2,rmse和mape定量化分析本实施例方法的有效性,图9为具体参数对比结果。
[0200]
表4为本实施例方法获得的林木生长参数与实际测量值对比:
[0201][0202]
注意:(f):实际测量值;(o):本文的方法。
[0203]
图9分别展示了胸径、材积参数预测的结果,四种橡胶树的参数预测值和实测值构成实验点均匀分布在45
°
回归线附近,二者呈线性关系。
[0204]
图9中的(a)显示了本实施例方法获取四种橡胶树的胸径预测值和实测值的比较结果。其中热垦525和热研72059的比对结果分别为(r2=92.24%,rmse=1.70cm,mape=5.08%)和(r2=91.42%,rmse=1.75cm,mape=5.10%)。相对于前两个品种而言,本实施例的研究模型预测热垦628和pr107的胸径有较好结果,分别为(r2=94.31%,rmse=1.44cm,mape=4.87%)和(r2=93.87%,rmse=1.48cm,mape=5.03%)。这主要是由于热研72059胶园树木存在风害倾斜现象,相邻橡胶树相互遮挡导致点云数据获取不完整,进而影响了最终的参数预测结果。热垦525生长形态较为复杂,产生分枝的部位较低、分枝数量多且密集,不同株橡胶树的胸径参数差异性较大。而热垦628和pr107抗风能力较强,不易倒伏,生长形态较为简单,分枝数量少,获取的枝干数据较为完整,点云质量更高,预测精度更好。
[0205]
图9中的(b)显示了四种橡胶树的材积预测值与实际测量值的比对结果。其中热研72059(r2=91.25%,rmse=0.050m3,mape=6.06%)和热垦525(r2=90.14%,rmse=0.052m3,mape=8.19%)的rmse相对热垦628(r2=93.88%,rmse=0.027m3,mape=5.02%)和pr107(r2=93.73%,rmse=0.028m3,mape=5.33%)明显高很多。这一现象可以解释为热垦628和pr107分枝数量较少,不同株林木在同林地、同气候条件,同品种的情况下,材积参数的差异性较小;热垦628和pr107的树冠较小,受相邻同品种林木遮挡影响小,获取林木参数更为准确。
[0206]
4、结语:
[0207]
通过建立林木参数预测模型,由机载激光点云自动获取的部分林木参数预测单株橡胶树的胸径和材积。该预测模型结合了模糊深度网络、注意力机制和鸽群优化算法的优点,可根据林木参数之间的非线性关系、异常样本的权重分配、模型参数寻优策略,实现自适应建立模型,可适用于大多数复杂林木关系的建立,具有良好的普适性和鲁棒性。本实施例的预测模型与bp、rbf、grnn三种预测方法相比,在预测胸径和材积上都取得了更好的结果,rmse分别为1.59
±
0.15cm、0.040
±
0.013m3。实验结果表明本实施例的林木参数预测模
型对多种橡胶树都可以取得较好的预测效果,四种橡胶树预测胸径的平均mape为5.02%扰动,预测材积的平均mape为6.15%扰动,能够有效获取人工林的单株林木参数,在实验样本中均优于传统的预测模型。在林木参数的预测研究中,不同橡胶树品种表现的差异性可以从自然环境对橡胶树样地的影响、林木间相互遮挡导致机载点云的获取不完整、不同品种的生长形态特征上找到规律。基于模糊深度网络与多种人工智能算法相结合,根据木参数预测模型完成不同品种的橡胶树自动完成模型的训练,且适应于同林地同品种橡胶树关键参数的预测,是人工智能技术在林业邻域的落地应用之一。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1