基于深度学习的集装箱港口装卸设备故障数据补全方法
1.本发明属于集装箱港口装卸设备故障数据补全领域,具体涉及一种基于深度学习的集装箱港口装卸设备故障数据补全方法。
背景技术:
2.随着经济全球化和世界经济一体化的发展,集装箱运输业在近些年呈现高速发展的势头。集装箱港口吞吐量的持续增加,对港口的货物转运能力与装卸效率提出了更高的要求。然而,随着现代工业设备不断向复杂化、港口营运向智能化方向的发展,集装箱港口大型装卸设备的结构越来越复杂,导致故障诊断的难度加大,加上其工作条件相对恶劣,需要在高负荷、大功率条件下连续运转,不可避免会发生故障,造成集装箱港口装卸作业停滞,从而成为集装箱供应链的转运瓶颈。集装箱港口装卸作业设备运维数据包括宏观数据、微观数据和非结构化数据,呈现多源异构的特点,且由于人为操作失误、系统故障等原因,存在运维数据缺失的问题,影响集装箱港口装卸作业设备的故障识别,降低港口作业效率,现有研究缺少利用集装箱港口多源异构运维数据对装卸设备故障数据进行补全的方法。
技术实现要素:
3.为解决上述问题,本发明在对集装箱港口运维数据特征进行分析的基础上,针对运维数据中设备停机原因数据繁杂且存在缺失的问题,构建基于高层特征融合的深度学习模型,利用一维卷积神经网络(1d convolutional neural network,1d-cnn)子模型、朴素长短时记忆(long short term memory,lstm)子模型、vgg16子模型,分别对结构化非时间序列数据、时间序列数据及非结构化图像数据进行处理,构建长效循环卷积网络(lrcn)子模型对非结构化视频数据进行特征提取,进行高层特征融合和设备停机原因的识别,进而完成集装箱港口装卸设备故障数据补全。
4.本发明的技术方案:
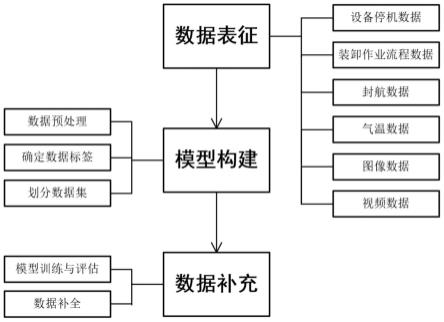
5.一种基于深度学习的集装箱港口装卸设备故障数据补全方法,步骤如下:
6.步骤一:集装箱装船作业设备故障数据表征
7.根据数据类型将数据划分为结构化数据和非结构化数据。
8.在集装箱港口运维数据中,结构化数据主要包括设备停机数据、装卸作业流程数据、封航数据和气温数据等;非结构化数据包括能反应装卸设备状态的图像数据和监控拍摄的设备运行情况的视频数据。记集装箱港口运维数据全集为其中和分别表示结构化数据集合和非结构化数据集合。
9.记结构化数据集合为记结构化数据集合为其中,s
(s
′
)
,s
′
=1,2,
…
,s
′
表示单元素数据集合,即数据集中每个样本仅包含一个元素;m
(m
′
)
,m
′
=1,2,
…
,m
′
表示多元素非时间序列数据集合,即数据集中每个样本包含多个元素且元素之间不存在时间相关性;t
(t
′
)
,t
′
=1,2,
…
,
t
′
表示多元素时间序列数据集合,即数据集中每个样本包含多个元素,且可以处理为时间序列。
10.记非结构化数据集合为其中,i
(i
′
)
,i
′
=1,2,
…
,i
′
表示图像数据集合,v
(v
′
)
,v
′
=1,2,
…
,v
′
表示视频数据集合。
11.记集装箱港口装卸作业设备停机原因向量为b={b1,b2},其中,b1表示含有完整设备停机原因数据的样本集合,b2则表示设备停机原因数据缺失的样本集合。相应的,令a=a1∪a2,其中,a1为a中在数据采集时间上与b1相对应的数据集合,a2为a中与b2相对应的数据集合。b1中的第k个元素bk∈b1在a1中对应的样本记为:
[0012][0013]
其中,表示单元素数据集合s
(1)
中的第k个样本。
[0014]
步骤二:高层特征融合的深度学习模型构建
[0015]
高层特征融合深度学习模型的构建过程主要包括多源异构的数据集合进行预处理(包括特征提取和高层特征融合)、数据标签的确定、数据集的划分;
[0016]
(1)根据数据底盘中的数据类型,对各数据集合进行特征提取
[0017]
(1.1)单元素数据集合
[0018]
单元素数据集合s
(s
′
)
,s
′
=1,2,
…s′
的每个样本仅包含一个元素,可直接将其作为深度学习模型的高层特征融合的输入,其输出记为
[0019]
(1.2)多元素非时间序列数据集合
[0020]
一维卷积神经网络(1d convolutional neural network,1d-cnn)模型常用于处理多元素非时间序列数据集合,本发明利用一维卷积神经网络(1d-cnn)子模型对多元素非时间序列数据集合进行特征提取。
[0021]
经过1d-cnn子模型,模型的输入将转化为一个长度为的一维向量,即作为高层特征融合的一个输入。
[0022]
(1.3)多元素时间序列数据集合
[0023]
长短时记忆神经网络模型(lstm)是深度学习方法中应用较广泛的一种模型,朴素长短时记忆网络模型是模型指模型中仅包含一个lstm层。本发明采用朴素lstm子模型对多元素时间序列数据集合进行特征提取。
[0024]
经过朴素lstm子模型,模型的输入将转化为一个长度n为的一维向量,即作为高层特征融合的一个输入。
[0025]
(1.4)图像数据集合
[0026]
图像数据集合i
(i
′
)
,i
′
=1,2,
…
,i
′
的每个样本为一张rgb图像。vgg16模型是一种典型的二维卷积神经网络,包含16个参数层。本发明采用vgg16子模型对图像数据进行特征提取。
[0027]
经过vgg16子模型后,输出一个长度为4096的一维向量,记为作为高层特征融合的一个输入。
[0028]
(1.5)视频数据集合
[0029]
视频数据集合的每个样本均为一个视频,视频的不同帧图像之间存在时间相关性,通常采用卷积神经网络-长短时记忆(cnn-lstm)模型进行处理,但这种方式可能会造成信息丢失,影响预测精度。为解决这一问题,本发明构建长效循环卷积网络(lrcn)子模型对视频数据进行特征提取,该模型以二维卷积长短时记忆层(convlstm2dlayer)为模型主体,该层类似于lstm层,但输入和输出均为二维图像,因此可以同时处理图像时间序列包含的空间信息和时间信息,相比于传统的cnn-lstm模型,预测效果更好。
[0030]
对lrcn子模型进行说明:记为共包含帧图像的视频,用划窗将其划分为个图像序列,每个图像序列包含λ
(1)
帧图像,每个图像的尺寸为(宽
×
高
×
通道数),则
[0031]
在lrcn子模型中,要经过三个convlstm2d模块,分别是convlstm2d1_x,convlstm2d2_x和convlstm2d3_x,每个模块由两个convlstm2d层和一个二维最大池化层组成。
[0032]
不同于lstm层处理的序列元素是数值,convlstm2d层处理的序列元素是二维图像,即convlstm2d层的输入是以视频的形式体现的。在lrcn子模型中,输入是包含个时间步的图像的视频,其经过第一个convlstm2d层convlstm2d1_1后,其输出记为步的图像的视频,其经过第一个convlstm2d层convlstm2d1_1后,其输出记为的每个时间步的元素可通过下式计算:
[0033][0034][0035][0036][0037][0038]
其中,为中的第个子序列,是convlstm2d层的输入,分别为的输入门三维张量、遗忘门三维张量和输出门三维张量,是三个以sigmoid函数作为激活函数的神经网络。为记忆状态三维张量,为隐藏状态三维张量(或输出三维张量),是每个时间步的输出,也作为下一个时间步输入的一部分,和的初始值为0。表示权重张量,其下标用来区分不同的门和状态。表示偏差,其下标同样对应于不同的门或状态。tanh为双曲正切激活函数,*表示卷积操作,
°
表示hadamard乘积,
即矩阵的对应元素相乘。
[0039]
以及作为上述计算公式的输入,通过递推计算,即可得到每个时间步对应的输出其中,为convlstm2d1_1层中所用的卷积核数量。由于设定了convlstm2d1_1层的return sequence参数值为true,故其输出包含所有组成的序列,即
[0040]
将作为第二个convlstm2d层convlstm2d1_2的输入,由于convlstm2d1_2与convlstm2d1_1参数完全相同,故其输出尺寸与相同。
[0041]
会经过一个池化层,池化层的输入为其池化操作针对每个尺寸为的二维张量,经过最大池化操作后,其输出的每个元素可根据下式计算:
[0042][0043]
其中,λ=1,2,
…
,λ
(1)
,经过最大池化操作后,其输出其中,其中,即输入的分辨率变为之前的一半。
[0044]
会经过另外两个convlstm2d模块,convlstm2d2_x和convlstm2d3_x,由于convlstm2d2_x和convlstm2d3_x模块中的convlstm2d层的卷积核数量分别convlstm2d2_x中对应层的2倍和4倍,故经过convlstm2d3_x模块后的输出尺寸变为尺寸变为即其中,中,和的变化是由于经过convlstm2d2_x和convlstm2d3_x中各自的最大池化层造成的,的变化则是由于convlstm2d2_x和convlstm2d3_x两个模块中convlstm2d层中卷积核数量的加倍造成的。
[0045]
在经过上述的3个convlstm2d模块后,其输出将进入一个全连接模块,该模块类似于cnn模型中的全连接模块,包含一个扁平层,两个全连接层和两个dropout层。
[0046]
将由一个扁平层扁平化为一个一维向量其中,其中,将经过两个全连接层,其输出分别记为和和和和中的每个元素及可由下式确定:
[0047][0048][0049]
其中,和为全连接层的权重和偏差,l=1,2。在每个全连接层后都会跟随一个dropout层,以防止模型的过拟合,其输出尺寸不会发生变化。
[0050]
经过上述的lrcn子模型,模型输入将转化为一个长度为32的一维向量,即作为高层特征融合的一个输入。
[0051]
(2)高层特征融合
[0052]
(2.1)对各个特征向量进行批量归一化处理
[0053]
批量归一化处理通过批标准化(batch_normalization)层实现,将数据特征向量作为批标准化(batch_normalization)层的输入,其输出记为作为批标准化(batch_normalization)层的输入,其输出记为按下式计算:
[0054][0055]
其中,表示中的第j个元素,表示中的第j个元素,表示的期望,为的方差,和ψk为训练过程中学习的修正系数。经过批标准化(batch_normalization)层,每个元素都进行了标准化处理。
[0056]
(2.2)将经过归一化处理的各输出集合经过融合层进行融合
[0057]
融合层的作用是将上述步骤(2.1)获得的所有的特征向量按照顺序组合成一个新的一维向量,记融合层的输出为由于以上五个集合的特征向量长度分别为1、n、4096和32,故的尺寸c=1
×s′
+n
×m′
+n
×
t
′
+4096
×i′
+32
×u′
,其中,s
′
、m
′
、t
′
、i
′
和u
′
依次为5种数据的集合数量。
[0058]
(2.3)使输出通过激活函数为softmax且通道数为ω的全连接层,其中,ω为停机向量b中的停机原因分类标签总数,其输出记为p的每个元素根据下式计算:
[0059][0060]
其中,ω为停机原因的分类标签,ω=1,2,
…
,ω,wi为权重矩阵,bi为偏差向量,表示样本k的分类标签预测为ω的概率。对于第k个样本,中,最大的p值对应的ω即为该样本的分类标签。
[0061]
(3)数据标签的确定
[0062]
根据数据底盘中对停机原因的描述进行字符串匹配,确定b1数据标签向量。包括以下三种情况:
[0063]
等流程:对于包含“等”或“流程”一词的设备停机原因归为等流程。
[0064]
设备故障:对于包含“异常”、“故障”、“打滑”、“急停”、“更换”、“维护”任意一词的设备停机原因归为设备故障。
[0065]
其他:对于包含“清理”、“大风”、“大雪”、“通信”任意一词或是在不包括等流程和设备故障中的其他数据样本,将其停机原因归为其他。
[0066]
(4)数据集的划分
[0067]
将经过预处理和数据标签确定后的输入数据根据设备停机开始时刻与设备停机数据相匹配,记为{a,b},其中,a=a1∪a2,b={b1,b2},a1为数据全集a中含有数据标签的数据集,对应的数据标签向量记为b1,a2为全集中不含有数据标签的数据集,其对应的数据标签向量记为需要进行补全。
[0068]
根据交叉验证理论,数据集的划分概括为:
[0069]
记数据标签向量b1中设备停机原因为等流程、设备故障和其他的数据数量分别为n1、n2和n3,再对每部分的数据随机四等分。将四等分后数据构建4个数据集使每个数据集中包含三种停机原因的数据数量分别为n1/4、n2/4和n3/4。
[0070]
将数据划分为训练集、验证集和测试集。
[0071]
步骤三:基于高层特征融合的深度学习模型的数据补全
[0072]
(1)模型训练与性能评估
[0073]
利用训练集和验证集中的数据对深度学习模型进行训练,利用测试集中的数据对模型的预测性能进行评估。
[0074]
本发明选取分类交叉熵损失作为深度学习模型的损失函数。样本k的损失函数可按照下式计算:
[0075][0076]
其中,p
ω,k
为第k个样本的分类标签预测为ω的概率,t
ω,k
为ground truth,当第k个样本的真实标签为ω时,t
ω,k
的值为1,否则为0。对于训练集数据,其损失函数为
为训练集中的样本总数。
[0077]
本发明使用小批量梯度下降算法和自适应矩估计算法来对模型进行优化,模型的收敛准则是使训练集的损失函数的变化趋于稳定。将训练完毕的深度学习模型应用于测试集数据,可评估该模型的预测性能。
[0078]
(2)数据补全
[0079]
经过模型训练和性能评估的深度学习模型即可用于设备停机原因数据缺失的样本集合a2,以预测其数据标签b2向量的值,补全每个样本的设备停机原因,完成整个数据补全过程。
[0080]
本发明的有益效果:针对由于人为操作失误、系统故障等原因,导致的集装箱港区装卸作业系统数据底盘存在数据缺失问题,本发明构建了基于高层特征融合的深度学习模型,利用深度学习模型处理集装箱港区装卸作业系统的结构化数据和非结构化数据,为港口多源异构数据的融合提供了高精度的预测方法,实现了对集装箱港口装卸设备故障数据的补全,可有效避免由于数据缺失对集装箱港口装卸作业设备故障识别的不利影响,填补了现有研究缺少利用集装箱港口多源异构运维数据对装卸设备故障数据补全的空白。
附图说明
[0081]
图1是本发明的基本流程图。
[0082]
图2是基于高层特征融合的深度学习模型结构图。
具体实施方式
[0083]
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
[0084]
本发明的一种基于高层特征融合深度学习的集装箱港口装卸设备故障数据补全方法如图1所示。本实施例以我国某集装箱港口运维数据为例,并验证基于高层特征融合深度学习模型的集装箱港口装卸设备故障数据补全方法的有效性。
[0085]
步骤一:集装箱装卸作业设备故障数据表征
[0086]
以该港区的16台装卸设备2017到2018年共计126248条设备停机数据为基础,根据设备停机数据中的停机开始时刻,将数据标签与装卸设备停机相关数据集进行匹配,确定深度学习模型的输入{a,b},则
[0087]
其中,设备停机原因数据完整的数据数量为17228条,即与其对应的a中的部分为a1,{a1,b1}将划分为训练集、验证集和测试集,训练集和验证集用以训练深度学习模型,测试集用以评估深度学习模型性能。剩余的109020条数据的设备停机原因数据缺失,即其对应的a中的部分为a2。当模型训练完毕后,以a2作为经过训练的深度学习模型的输入,对b2中的每个值进行预测,即可完成设备停机原因数据的补全。
[0088]
步骤二:基于高层特征融合的深度学习模型构建
[0089]
面向集装箱港口运维数据的补全问题,构建基于高层特征融合的深度学习模型,模型结构见图2。
[0090]
(1)数据预处理
[0091]
经过预处理后的装卸设备停机相关数据主要包括:
[0092]
(1.1)单元素数据集合
[0093]
①
工班数据:哑变量,取值为1(白班)或者0(夜班)。
[0094]
②
气温数据:数值变量,取值为每小时的气温。
[0095]
(1.2)多元素非时间序列数据集合
[0096]
①
流程号:分类变量,经过独热编码(one-hot encodings)后,由于对象港区共有388种作业流程,每个样本的流程号变为一个长度为388的一维向量,该向量的第i个值为1,表示该流程号为388种作业流程中的第i种流程,其他值均为0。
[0097]
(1.3)多元素时间序列数据集合
[0098]
①
设备停机-流程相关性向量:一维时间序列数据,时间步以分钟为单位进行划分,长度取为1小时,则每个样本的设备停机-流程相关性向量为一个长度为60的一维向量,该向量的第i个值,表示在某一装卸设备停机结束后的第i分钟内是否有装卸作业在进行,若有正在进行的装卸作业且该装卸作业流程所包含装卸设备为该停机设备,则该值为1,否则为0。每一条设备停机数据对应的设备停机-流程相关性向量尺寸为1
×
n。
[0099]
②
设备停机-极端天气相关性向量:一维时间序列数据,类似于设备停机-流程相关性向量,长度为60,向量的第i个值表示装卸设备停机结束后的第i分钟内是否存在极端天气,若存在极端天气,则该值为1,否则为0。
[0100]
(1.4)图像数据集合
[0101]
①
装卸设备图像:经过尺寸变换的装卸设备图像,其尺寸为224像素
×
224像素(宽
×
高)。
[0102]
(1.5)视频数据集合
[0103]
①
装卸设备停机发生前10秒内的视频:取视频每秒的第一帧图像为代表,组成图像序列,则每个序列包含10幅图像,变换图像尺寸为224像素
×
224像素(宽
×
高)。
[0104]
(2)确定数据标签
[0105]
将数据标签b1中每个元素的值划分为等流程、设备故障和其他三种情况之一。经过数据标签的确定后,三种情况的数据分别为12088、3403和1737条。
[0106]
(3)划分数据集
[0107]
将a1中的数据根据设备停机原因标签四等分,并构建4个数据集确保每个数据集中包含的设备停机原因为等流程、设备故障和其他的数据数量分别为3022、851和434。按照2:1:1的比例划分训练集、验证集合测试集。
[0108]
4种数据集划分情况(cv1到cv4),见表1。
[0109]
表1训练集、验证集和测试集
[0110][0111]
(4)设定深度学习模型参数
[0112]
深度学习模型参数设定包括优化算法、训练次数和评价指标。采用的两种优化算法与4种数据集划分情况cv1-cv4组合后,共有8种工况:工况s1-s4的数据集划分情况分别为cv1-cv4并采用随机梯度下降(sgd)算法,工况s5-s8的数据集划分情况分别为cv1-cv4并采用自适应矩估计(adam)算法。
[0113]
步骤三:基于高层特征融合深度学习模型的集装箱港口装卸设备故障数据补全
[0114]
(1)模型训练及性能评估
[0115]
以训练集和验证集数据对深度学习模型在s1-s8共8种工况下进行训练。对比采用两种算法的各工况,相比于随机梯度下降(sgd)算法,自适应矩估计(adam)算法收敛速度更快,但训练过程可能会有波动。两种算法均可快速收敛(训练次数在300次以内),模型训练结果差别不大,且都可以得到满足工程实际需求的训练结果,可用于测试集数据,对深度学习模型的预测效果进行评估。
[0116]
(2)数据补全
[0117]
将训练完毕的深度学习模型应用于测试集数据,可得各工况s1-s8的混淆矩阵,见表2。
[0118]
表2工况s1-s8混淆矩阵
[0119][0120]
根据各工况混淆矩阵,可计算各工况的计算精度,结果见表3。
[0121]
表3各工况测试集精确度
[0122][0123]
从表3可知:
[0124]
①
各工况下的测试集精确度均在86%左右,预测精度基本满足要求,可用于缺失设备停机原因数据的补全。
[0125]
②
由于在划分数据集时采用了交叉验证方法,表3中的结果也表明深度学习模型对数据的鲁棒性较好,不会因为数据集的变化使结果产生较大波动。
[0126]
③
随机梯度下降(sgd)算法和自适应矩估计(adam)算法均可作为深度学习模型的优化算法,对预测结果影响不大,表明深度学习模型对采用的优化算法的鲁棒性较好。
[0127]
将训练完毕的深度学习模型应用于设备停机原因数据缺失的109020条数据中,以a2作为经过训练的深度学习模型的输入,对b2中的每个值进行预测,即可完成设备停机原因数据的补全和数据底盘的清洗。本实施例中,经数据补全后的109020条数据中,停机原因为等流程的数据量为92013条,停机原因为设备故障的数据量为11590条,停机原因为其他的数据量为5417条。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1