SDN环境下基于改进的残差卷积网络的细粒度流量分类方法
sdn环境下基于改进的残差卷积网络的细粒度流量分类方法
技术领域
1.本发明属于软件技术领域,涉及sdn环境下基于改进的残差卷积网络的细粒度流量分类方法。
背景技术:
2.随着物联网、云计算以及5g的发展,接入网络的节点不断增加,网络传输速率不断增长,各种新型应用不断涌现,网络流量呈指数级增长,使得网络不堪重负,容易造成资源浪费、网络拥塞等问题。流量分类是一项重要的网络功能,其目的是将流量划分为多个优先级或多个服务,它提供了一种通过识别不同流量类型来执行细粒度网络管理的方法。借助流量分类,网络运营商可以更有效地处理不同的业务和分配网络资源,提升网络质量和用户体验。
3.sdn是一种新兴的、有前途的网络模式,它可以极大地简化网络管理,提高网络资源利用率,优化网络性能,降低运营成本。软件定义网络(sdn)为我们提供了在网络内部实现智能化的新机会,具体而言:
4.第一,sdn集中式架构使控制器具有网络的中央视图,能够收集各种网络数据,能够有效解决深度学习中的数据获取难题,便于深度学习算法的应用。第二,基于实时和历史网络数据,深度学习技术可以通过数据分析、网络优化和网络服务的自动化提供,为sdn控制器带来智能。第三,sdn的可编程性允许应用程序对网络进行编程,进而使得深度学习算法做出的最优网络解决方案可以在网络上实时执行。第四,图形处理单元(gpu)和张量处理单元(tpu)等计算技术的最新进展为在网络领域应用深度学习技术提供了技术支撑。因此,在sdn中应用深度学习技术是合适和有效的。
5.传统机器学习方法进行流量分类的结果非常依赖于网络流量的特征工程,而这需要大量的时间和人力,这对于一些核心或边缘设备上是不适用的,此外传统机器学习方法并不能适用于加密流量的分类识别,大大降低了机器学习方法的通用性。深度学习是一种端到端的学习方式,其输出不受输入数据特征的影响,不需要人为提取特征,摆脱了繁重的特征学习和特征选择工作,因此基于深度学习的方法能够进行更准确、更快速、更细粒度的流量分类问题。
6.深度学习算法的结果根据分类级别可以分为两类:粗粒度和细粒度。粗粒度分类根据粗略的流量类型(如web浏览器、批量传输、voip等)将流量识别为几个类别。细粒度分类旨在区分单个应用程序或功能模型(如facebook应用程序可以生成视频、语音、音频共享流等),而不是将它们分类为粗略的流量类别,这有利于运营商进一步分析流量组成和用户画像,提高网络服务质量。
7.sdn网络作为一种极具前景的网络架构已经被广泛讨论研究,但网络安全和qos质量仍然面临着巨大的挑战,因此,sdn网络中的流量分类问题也成为了一项重要的研究。目前,有文献将深度学习方法应用到软件定义网络中的各种挑战和问题,从流量分类、路由优化、qos/qoe预测、资源管理和安全的角度,详细讨论了ml算法在sdn领域的应用。对于流量
分类任务的研究有很好的总览性作用。
8.网络流量分类技术发展至今大概经历了四个阶段:
9.一是基于端口流量分类,但随着动态端口、隐藏端口的出现,该方法的识别准确率大幅下降。
10.二是基于有效负载的流量分类,如深度包检测,通过在ip包的有效负载中搜索应用程序的签名,能够在一定程度上避免动态端口问题。但该类方法需要不断地更新和维护协议特征库,面对快速发展的网络会产生极大的资源消耗,此外当出现加密流量时,该方法很难实现且计算开销很高。
11.三是基于传统深度学习的流量分类,该方法主要依据流量的一些外部统计特征,如包间时间、总包数、流量持续时间等实现流量的分类,常见的有支持向量机svm、随机森林rf、决策树dt、k均值算法,该类方法对动态端口和加密流量等具有高适应性,但需要复杂的特征工程,增加了该方法的复杂性。
12.四是基于深度学习的流量分类,基于深度学习的方法的特征提取与选择是通过模型训练自动完成的,与传统的深度学习方法相比,深度学习的方法具有更高的学习能力,此外,深度学习的方法可以直接学习原始流量的特征而不需要额外的人工设计的特有或私有流量信息,这些特性使得基于dl的方法成为一种非常理想的流量分类方法。现有一种具有一维卷积神经网络的端到端加密流量分类方法,该方法将特征提取、特征选择和分类器集成到一个统一的端到端框架中,使用公共iscx vpn-non vpn流量数据集进行验证。但文章没有对模型的参数进行优化讨论,因此其模型的泛化能力有待进一步验证。现有一种深度数据包deep packet框架,该框架分别实现了sae和一维cnn,对网络流量进行自动提取以对流量进行分类,可以处理应用程序识别和流量表征任务。该篇文献依旧使用公共流量数据集iscx vpn-non vpn进行验证,两个网络都能够准确地对数据包进行分类。作者表明deep packet框架在应用程序识别和流量表征方面均胜过iscx vpn-non vpn流量数据集上的所有类似工作。但作者没有解决多通道分类问题(即细粒度分类,例如同一应用程序的不同功能流)。现有一种基于深度学习的轻量级流量分类和入侵检测框架,称为深度全范围(dfr),该框架实现了一维cnn、lstm、sae,使用两个公共数据集iscx vpn non vpn和iscx 2012 ids进行评估并能够达到很高的准确率。现有一种基于生成对抗网络(gan)的半监督学习加密流量分类方法bytesgan,嵌入在sdn边缘网关中实现流量分类的目标,进一步提高网络资源利用率。基于公共数据集“iscx2012 vpn-non vpn和crossmarket进行实验,结果表明bytesgan可以有效提高流量分类器的性能。但gan训练的模式崩溃和不稳定性成为了是该篇文章需要考虑和解决的问题。现有一种新的基于流时空特征的加密流量分类方案tscrnn,用于工业物联网的高效管理,tscrnn使用cnn提取抽象特征,然后通过堆栈bi-ltsm学习基于这些低维特征图的时间特征。现有一种用于暗网流量分类和应用识别的新型自注意力深度学习方法darknetsec。利用一维的级联模型卷积神经网络(1d cnn)和双向长短期记忆(bi-lstm)网络从数据包的有效负载内容中捕获局部时空特征,同时将自注意机制集成到上述特征提取网络中挖掘先前提取的内容特征之间的内在关系和隐藏联系。现有一种基于卷积神经网络(cnn)的在线多媒体流量分类框架,能够进行快速早期分类以及类增量学习。作者应用滑动窗口技术和概率分布函数进行特征设计。为了更好地支持新服务的添加,使用知识蒸馏和偏差校正技术开发了类增量学习模型。但特征提取的时间消耗使该方
法具有一定的局限性。
13.表1相关论文总结
[0014][0015][0016]
综上所述,目前的相关流量分类文献存在几个主要问题:一是作者选择的数据集都选取了每一类别具有很高的一致性、不同类别的流量具有明显的区分度的流量数据集,因此能够达到很高的准确度,但在实际网络环境下,准确区分同一应用产生的细粒度网络流更为重要。二是没有统一的流量预处理方案,各种特征处理或流量提取的方法大幅增加了前期的时间消耗。三是在模型的选择方面大部分研究都选择了cnn和lstm,只有较少文章
探索了其他深度学习的方法在网络流量分类任务中的表现。
[0017]
针对这些问题,本文首先从公共数据集网站中选择了类别之间既有区分度又有相似度的数据集,然后利用统一的流量预处理方法将原始的网络流量数据集处理为图像数据并进一步转化为模型可识别的形式,最后提出了一种改进的基于残差卷积网络的模型框架对预处理数据进行分类并进行多项对比实验验证模型的可靠性。
技术实现要素:
[0018]
有鉴于此,本发明的目的在于提供一种sdn环境下基于改进的残差卷积网络的细粒度流量分类方法。
[0019]
为达到上述目的,本发明提供如下技术方案:
[0020]
sdn环境下基于改进的残差卷积网络的细粒度流量分类方法,该方法包括以下步骤:
[0021]
s1:对网络流量类别进行分类,定义网络流量拆分粒度;
[0022]
s2:在sdn中进行流量分类任务;
[0023]
s3:数据准备、数据预处理、数据可视化;
[0024]
s4:设计基于残差卷积网络的细粒度流量分类系统。
[0025]
可选的,所述s1具体为:
[0026]
根据协议、应用程序和流量类型的粒度对流量类别进行分类;
[0027]
网络流量拆分粒度包括:tcp连接、流、会话、服务和主机;不同的分割粒度会导致不同的流量单位;流定义为具有相同5元组的所有数据包,即时间戳、源ip、目标ip、协议和数据包长度;会话为双向流,包括两个方向的流量;
[0028]
设网络流量由一系列连续的数据包组成p=p1,p2,...,pi,...pn,,其中pi代表第i个数据包;通过使用流量切分工具splitcap从数据包头中提取五元组,每个数据包定义为pi=(ti,srci,dsti,proi,leni),i=1,2,...,|p|,其中ti代表时间戳,srci代表源ip地址,dsti表示目的ip地址,proi表示协议类型,leni表示数据包长度。
[0029]
可选的,所述s2具体为:
[0030]
s21:交换机收集网络流量,并通过openflow协议发送给控制器;
[0031]
s22:控制器提取流量数据,然后将特征发送给预处理模块对原始数据集进行处理;
[0032]
s23:处理结果发送到分类模块,对流进行分类;
[0033]
s24:将分类结果发送给sdn控制器;
[0034]
s25:控制器根据分类结果分析流量组成并做出管理与调度的决策。
[0035]
可选的,所述s3中,所述数据准备为:
[0036]
从公开数据集网站中获取11类真实环境下的原始数据集,包括facebook_audio、facebook_chat、facebook_video、hangout_chat、hangouts_audio、hangouts_video、skype_audio、netflix、vimeo、youtube和email,并将其命名为cic_tf。
[0037]
可选的,所述s3中,所述数据预处理为:
[0038]
将原始的pcap格式的流量数据转化为残差卷积网络可识别的idx格式的数据,包括流量分割、归一化、图像化和png转idx,具体包括:
[0039]
1)流量分割:将原始连续的pcap流量数据以会话+所有层的形式为粒度拆分为更小的离散的pcap流量数据;删除空文件和重复文件;
[0040]
2)归一化:将所有文件修剪为统一的长度将文件统一为28*28,784字节,当文件大小大于784字节,则将其修剪为784字节,当文件大小小于784个字节,则在最后添加0x00以补充到784个字节;修剪完成之后将所有文件按1:9的比例划分为测试集和训练集;
[0041]
3)图像化:该步骤将步骤3)处理的具有相同大小的文件转换为灰度图像;原始文件的每个字节代表一个像素,0x00表示黑色,0xff表示白色,批量将所有文件转化为28*28的灰度图像;
[0042]
4)png转idx:将png格式的图像数据转化为网络模型可识别的数据格式,利用idx填充生成器将大小一致的图像数据转化为二维格式的idx文件。
[0043]
可选的,所述s3中,所述数据可视化为:
[0044]
将步骤3)图像化生成的部分图像进行可视化,每个灰度图像的大小为28*28字节。
[0045]
可选的,所述s4具体为:
[0046]
若将每一层都视为一个非线性函数,则整个网络视为一个复合的非线性多元函数:
[0047]
f(x)=fn(...f3(f2(f1(x)*w1+b1)*w2+b2)...)
[0048]
其中:f(x)表示神经网络的输出,f表示激活函数处理之后的结果函数,x代表神经网络的输入,w代表权重,b代表偏置;很明显,这种链式结构的输出会随着网络层数以及激活函数的大小而呈指数级的变化,也就是深度学习中典型的的梯度爆炸和梯度消失问题;
[0049]
深度残差网络是由一个个的残差模块堆叠而成,残差块的结构如下:
[0050]
残差块分为恒等映射和残差映射两部分;设神经网络的输入是x,期望输出是h(x),通过直接映射的方式,直接把输入x传到输出,如果f(x)和x的通道相同,则直接相加输出结果为h(x)=f(x)+x,如果f(x)和x的通道不相同则利用卷积神经网络中特殊的一维卷积核调整通道数使之与f(x)通道相同,输出结果为:h(x)=f(x)+wx,当f(x)=0时,两种情况下的输出结果为:h(x)=x,即恒等映射;
[0051]
(1)卷积层
[0052]
设输入形状是nh*nw,卷积核的形状是kh*kw,填充大小为p,步长为s,那么输出形状为:
[0053][0054]
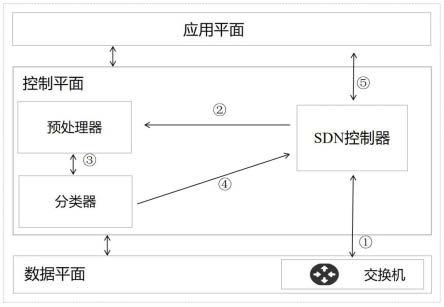
完整的特征图是通过多个卷积核来获得的,第l层第k个特征图在位置(i,j)的输出表示如下:
[0055][0056]
其中,和分别是第l层的第k个卷积核的权重向量和偏置项,是以第l层位置(i,j)为中心的感受野;
[0057]
对于每个mini-batch,一次训练过程里面包含m个训练实例,对隐层内每个神经元的激活值进行如下变换:
[0058][0059]
卷积层的最后往往需要使用非线性激活函数,生成输入输出之间的非线性映射,进一步增强网络的特征学习能力,激活函数处理之后的输出表示为:
[0060][0061]
(2)自适应平均池化层
[0062]
设padding为0,池化核的大小表示为:
[0063][0064]
在残差卷积网络中,从idx文件中读取batch_size=n张,大小为i=28*28*1的灰度流量图片;然后经过两个残差层,每个残差层包括卷积层、批量归一化层和激活函数层,使用batchnorm和relu函数对网络结果进行优化,再通过一个卷积层和归一化层将其转化为n_classes个特征图,最后通过自适应平均池化层adaptiveavgpool2d输出每个类别的特征值。
[0065]
本发明的有益效果在于:
[0066]
1)提出了一种sdn环境下基于残差卷积网络的流量分类方法,在公共流量数据集上实现了高精度分类效果。
[0067]
2)设计了一种基于表征学习的流量数据集预处理方法,将原始的流量数据转换为网络模型可识别的数据形式。
[0068]
3)实现了高精度的细粒度的流量分类,有效解决了传统深度学习方法在识别细粒度流量时可能出现的梯度消失问题。
[0069]
4)与目前流行的深度学习方法进行了对比实验,结果证明本文所使用的方法能显著提高细粒度流量分类准确率。
[0070]
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
[0071]
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
[0072]
图1为sdn中流量分类基本架构图;
[0073]
图2为数据预处理流程;
[0074]
图3为数据可视化;
[0075]
图4为cnn模型在cic_tf数据集上的训练loss值;
[0076]
图5为残差块的基本结构;
[0077]
图6为混淆矩阵结果图;
[0078]
图7为模型在ustc-tk数据集上预测的混淆矩阵图;
[0079]
图8为对比实验结果图;
[0080]
图9为各类超参数对模型效果的影响;图9(a)为训练周期,图9(b)为残差块数量,图9(c)为学习率,图9(d)为批量大小。
具体实施方式
[0081]
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
[0082]
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0083]
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
[0084]
一、问题定义
[0085]
(1)分类粒度
[0086]
构建流量分类器的第一步就是明确分类目标。典型的目标包括保障qos、资源分配和入侵检测等。为了实现这些目标,可以根据以下粒度对流量类别进行分类:
[0087]
1.协议(例如ftp、http)
[0088]
2.应用程序(例如youtube、qq)
[0089]
3.流量类型(例如视频、音频、聊天)
[0090]
因此,目标是用相应的流量类别标记每个流,本文主要从qos和资源分配的角度对不同类型的网络流量进行分类,实现更精细化的网络管理。
[0091]
(2)流量粒度
[0092]
网络流量拆分粒度包括:tcp连接、流、会话、服务和主机。不同的分割粒度会导致不同的流量单位。流定义为具有相同5元组的所有数据包,即时间戳、源ip、目标ip、协议和数据包长度。会话为双向流,包括两个方向的流量。此外,从网络流量的osi七层模型来看,一方面流量的固有特性直观地反映在应用层(第七层),另一方面,其他层的数据也应包含一些流量特征信息如传输层的端口信息等。因此,本文使用了所有层+会话的分割粒度,最大程度的保留原始流量的数据特征。
[0093]
为了更好地描述问题,将其表述如下:
[0094]
网络流量由一系列连续的数据包组成p=p1,p2,...,pi,...pn,,其中pi代表第i个数据包。通过使用流量切分工具splitcap从数据包头中提取五元组,则每个数据包可以定义为pi=(ti,srci,dsti,proi,leni),i=1,2,...,|p|,其中ti代表时间戳,srci代表源ip地址,dsti表示目的ip地址,proi表示协议类型,leni表示数据包长度。
[0095]
二、基本架构
[0096]
如图1所示,sdn是一种新的网络模式,它通过分离控制和数据平面化来实现网络基础设施虚拟化,从而创建一个动态、灵活、自动化和可管理的三层体系结构。sdn控制器是整个sdn体系结构的关键组成部分,它主要控制sdn交换机来管理整个数据流。最重要的是,sdn的可扩展性和可编程性为深度学习技术的部署提供了可能。
[0097]
sdn中流量分类任务可以概括为以下步骤:
[0098]
①
交换机收集网络流量,并通过openflow协议发送给控制器。
[0099]
②
控制器提取流量数据,然后将特征发送给预处理模块对原始数据集进行处理。
[0100]
③
处理结果发送到分类模块,对流进行分类。
[0101]
④
最后再将分类结果发送给sdn控制器。
[0102]
⑤
控制器根据分类结果分析流量组成并做出高效的管理与调度的决策。
[0103]
三、数据预处理
[0104]
(1)数据准备
[0105]
为了达到不同流量类型分类即细粒度分类的目的,从公开数据集网站中获取了11类真实环境下的原始数据集(即facebook_audio、facebook_chat、facebook_video、hangout_chat、hangouts_audio、hangouts_video、skype_audio、netflix、vimeo、youtube、email),并将其命名为cic_tf,涉及几类常见的音频、视频和会话流量数据集,既包括粗粒度的不同应用程序数据集,又包括细粒度的同一应用程序的不同会话数据集。每个类包含的数据包数量如表2所示,其中各种流量数据占比各不相同且视频流量数据占比较大,这也符合实际情况中的流量分布。
[0106]
表2数据集结构
[0107]
traffictypequantitypercentage(%)facebook_audio4606110.68facebook_chat55271.28facebook_video15690.36hangout_chat75871.76hangouts_audio8733420.26hangouts_video80831.87skype_audio6020713.96netflix5193212.04vimeo9270521.50youtube397429.22email304107.05
[0108]
(2)预处理过程
[0109]
该过程的目的是将原始的pcap格式的流量数据转化为残差卷积网络可识别的idx
格式的数据,同时解决数据不一致、冗余数据等问题。它包括四个步骤:流量分割、归一化、图像化、png转idx。其基本流程如图2所示:
[0110]
1)流量分割:在此过程中,我们利用splitcap工具进行处理,它可以根据5元组等标准将pcap文件拆分为更小的文件。首先,我们将原始连续的pcap流量数据以会话+所有层的形式为粒度拆分为更小的离散的pcap流量数据。但某些拆分后数据包具有相同的内容时会生成相同的文件,并且重复数据会在训练网络模型时产生偏差,所以还需要删除空文件和重复文件,消除干扰。
[0111]
2)归一化:此步骤将所有文件修剪为统一的长度。残差网络输入数据的大小必须是固定的,受经典图片数据集minist的启发我们将文件统一为784字节(即28*28),当文件大小大于784字节,则将其修剪为784字节,当文件大小小于784个字节,则在最后添加0x00以补充到784个字节。修剪完成之后将所有文件按1:9的比例划分为测试集和训练集。
[0112]
3)图像化:该步骤将步骤3)处理的具有相同大小的文件转换为灰度图像。原始文件的每个字节代表一个像素,0x00表示黑色,0xff表示白色,批量将所有文件转化为28*28的灰度图像。
[0113]
4)png转idx:残差网络模型并不能直接训练图像数据,该步骤需要进一步将png格式的图像数据转化为网络模型可识别的数据格式,idx-ubyte格式是深度学习中常见的文件格式,我们利用idx填充生成器将大小一致的图像数据转化为二维格式的idx文件,便于后续的模型训练。
[0114]
算法1详细描述了整个预处理过程的详细步骤:
[0115][0116]
算法1中涉及的符号解释如表3所示:
[0117]
表3符号说明
[0118][0119]
(3)数据可视化分析
[0120]
本部分将数据预处理过程的第3步生成的部分图像进行了可视化如图3所示,其中每个灰度图像的大小为28*28字节。
[0121]
从图3的可视化分析可以看出,同一个应用的不同服务类型流量之间没有明显的区分程度,例如facebook中的audio、chat和video流量。不同应用程序的统一服务类型流量之间也没有较高的一致性,如facebook_video、hangots_video和youtube。因此,要想最大程度的区分这些更小粒度的服务流量必须要学习到尽可能多的特征。
[0122]
四、基于残差卷积网络的细粒度流量分类系统设计
[0123]
流量分类技术发展至今应用最多且分类效果最好的是深度学习中的神经网络,特别是卷积神经网络,但我们在实验过程中发现当数据集类别之间存在一定相似性的时候,一般的卷积神经网络的分类效果会大幅降低,并且随着训练epoch的增加,模型逐渐开始退化,出现梯度消失问题。
[0124]
图4是使用cnn模型在cic_tf数据集上的训练loss值,横坐标表示epochs,纵坐标为放大100倍的loss值,从图中可以看出当epochs在0到50之间时,模型能够很好的学习数据特征,训练损失值能快速平滑的下降;当epochs值在50到150之间时,loss值开始上下大幅波动,模型的学习能力开始逐渐下降;当epochs值大于150时,loss值甚至直接等于0,此时,模型已完全退化。由此可见,简单的cnn模型已经不能解决细粒度流量数据集的分类问题。而残差卷积网络能够通过残差模块让该层网络恒等映射上一层的输入,这样网络的效果不会比上一层更差,很大程度上解决了网络的退化问题,同时卷积层的引入又继承了一般卷积神经网络的优点。
[0125]
在深度学习研究中,一般网络结构越深,越能够拟合出最真实的函数,但深层的网络是由许多非线性层堆叠而来的,若将每一层都视为一个非线性函数,那么整个网络可视为一个复合的非线性多元函数:
[0126]
f(x)=fn(...f3(f2(f1(x)*w1+b1)*w2+b2)...)
[0127]
其中:f(x)表示神经网络的输出,f表示激活函数处理之后的结果函数,x代表神经网络的输入,w代表权重,b代表偏置。很明显,这种链式结构的输出会随着网络层数以及激活函数的大小而呈指数级的变化,也就是深度学习中典型的的梯度爆炸和梯度消失问题。
[0128]
深度残差网络是由一个个的残差模块堆叠而成,其主要思想是恒等映射,保证深层效果不弱于浅层。残差块的基本结构如下:
[0129]
如图5所示:残差块分为恒等映射和残差映射两部分。假设神经网络的输入是x,期望输出是h(x),通过直接映射(即图中右边曲线部分)的方式,直接把输入x传到输出,如果f
(x)和x的通道相同,则直接相加输出结果为h(x)=f(x)+x,如果f(x)和x的通道不相同则利用卷积神经网络中特殊的一维卷积核调整通道数使之与f(x)通道相同,输出结果为:h(x)=f(x)+wx,当f(x)=0时,那么两种情况下的输出结果均为:h(x)=x,也就是恒等映射。
[0130]
(1)卷积层
[0131]
卷积网络相比于传统神经网络最大的优点在于参数共享和稀疏连接,极大地降低了神经网络模型训练的复杂性,目前已经被广泛应用于图像识别、目标检测等各个领域。卷积层的主要目标是利用卷积核在输入图像上的移动来计算特征值,进而构成一个当前卷积核对应的特征图。其中卷积核的数值就是所谓的权重,当卷积核对应位置没有输入数据时需要使用padding进行填充,卷积核每次移动的单位为步长stride。假设输入形状是nh*nw,卷积核的形状是kh*kw,填充大小为p,步长为s,那么输出形状为:
[0132][0133]
完整的特征图是通过多个卷积核来获得的,第l层第k个特征图在位置(i,j)的输出表示如下:
[0134][0135]
其中,和分别是第l层的第k个卷积核的权重向量和偏置项,是以第l层位置(i,j)为中心的感受野。
[0136]
深度神经网络随着网络深度的加深,训练会变得越来越困难,收敛速度也越来越慢,而随着神经网络的训练,每一层神经网络的参数是不断变化的,因此,即使上一层网络的输入服从相同的分布,经过网络参数的变化,上一层网络的输出数据与上一次迭代时的输出数据不再服从同一个分布。从而导致,当前层神经网络的当前次的输入数据与上一次迭代时的输入数据服从不同的分布。这种想象也被称为内部协变量漂移。
[0137]
为了解决该问题,本文使用了batchnorm(bn)方法,其基本原理是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到域的标准正态分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,输入的小变化就会导致损失函数较大的变化,进而同时避免梯度消失问题产生,而且梯度变大能大大加快训练的速度。
[0138]
对于每个mini-batch来说,一次训练过程里面包含m个训练实例,其具体bn操作就是对于隐层内每个神经元的激活值进行如下变换:
[0139][0140]
卷积层的最后往往需要使用非线性激活函数,生成输入输出之间的非线性映射,进一步增强网络的特征学习能力,激活函数处理之后的输出可以表示为:
[0141][0142]
(2)自适应平均池化层
[0143]
池化层的加入可以对卷积层采集到的样本特征进行下采样,进一步减少参数量,自适应平均池化层可以通过输入原始尺寸和目标尺寸,自适应地动态计算核的大小和每次
移动的步长且每次运算采用取平均值的方法。相比于普通的池化层,它不需要手动指定具体核的大小、步长、填充值等参数。其中池化核的大小采用最大化原则向上取整,然后再在特征图上计算等距的位置点,计算起始坐标时采用最小原则向下取整。假设padding为0,池化核的大小可简化表示为:
[0144][0145]
本文提出的残差卷积网络中,首先从idx文件中读取batch_size=n张,大小为i=28*28*1的灰度流量图片。然后经过两个残差层,每个残差层包括卷积层、批量归一化层和激活函数层,为了使网络训练更加容易以及网络泛化性更强,本文使用了batchnorm和relu函数对网络结果进行优化,再通过一个卷积层和归一化层将其转化为n_classes个特征图,最后通过自适应平均池化层adaptiveavgpool2d输出每个类别的特征值。具体参数如表4所示:
[0146]
表4模型参数设置、输出大小与参数个数
[0147][0148]
五、实验设置与结果分析
[0149]
(1)损失函数
[0150]
本文使用交叉熵损失函数(cross entropy loss),交叉熵主要刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设x为输入样本特征值,概率分布p为期望输出,概率分布q为实际输出,h(p,q)为交叉熵,则:
[0151][0152]
(2)优化器
[0153]
梯度下降法是目前优化神经网络最常使用的方法。梯度下降法的最终目标是找到一组合适的θ(w1,w2,...,wn)使得目标函数j(θ)值最小的一种方法。具体做法是利用目标函数关于参数的梯度的反方向来更新参数,直到达到全局最小值或局部最小值。基本计算公式如下:
[0154]
[0155]
其中α表示学习率,表示对θ的偏导数。
[0156]
本文选择使用小批量梯度下降法(mini-batch gradient descent),它结合了批梯度下降法和随机梯度下降法的优点,这种方法减小了参数更新的方差使得收敛更加稳定,同时可以利用成熟的深度学习库中高度优化的矩阵优化方法,高效地根据每个小批量数据求解参数的梯度。使用n个小批量训练样本在第i次更新时的结果为:
[0157][0158]
为了帮助sgd在相关方向上加速并抑制抖动,可以通过在当前更新向量中的历史更新向量增加一个分量β来实现:
[0159][0160]
θ=θ-v
t
[0161]
其中,v
t
表示第t个数的估计值,β为一个可调参数。训练伪代码如算法2所示:
[0162][0163][0164]
(3)评估指标
[0165]
准确率:对于单标签任务而言,每个样本都只有一个正确的类别,因此分类最直观的指标就是准确率(accuracy),用来预测样本是否分类正确,计算方法如下:
[0166][0167]
记样本xi的类别为yi,类别种类为(0,1,...,n),预测类别函数为f,则top-1accuracy的计算方法如下:
[0168][0169]
精确率:精确率是针对预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。
[0170]
[0171]
召回率:召回率是针对原来的样本而言的,它表示的是样本中的正例有多少被预测正确。
[0172][0173]
f1-score:该指标是评估召回率和精确率的指标,只有在精确率和召回率都高且差距较小的情况下,f1-score才会很高,因此f1-score是一个平衡性能的指标。计算方式如下:
[0174][0175]
其中:tp:将正类预测为正类数,fn:将正类预测为负类数,fp:将负类预测为正类数,tn:将负类预测为负类数。
[0176]
由于是多分类问题,对于单一类型使用pr、rc、f1并不方便。因此,使用macroaverage计算每个类别的precision、recall、f1的平均值如下:
[0177][0178][0179][0180]
混淆矩阵:混淆矩阵是一个误差矩阵,常用来可视化地评估模型的性能,混淆矩阵大小为(n_classes,n_classes)的方阵,其中n_classes表示类的数量。这个矩阵的每一行表示真实类中的实例,而每一列表示预测类中的实例。
[0181]
本文的实验环境为:
[0182]
nvidia-smi 460.32.03gpu作为加速器,python 3.7.13+pytorch 1.12.0作为实验框架,实验数据随机选择十分之一的数据作为测试数据,其余为训练数据。训练时读取的最小批量大小为128,损失函数选择交叉熵损失函数,pytorch的内置sgd作为优化器,学习率为0.01,momentum参数设置为0.9,训练时间为150个周期。
[0183]
(4)实验结果
[0184]
表5显示了数据集cic_tf中每一类在本文提出的残差卷积网络模型上的精确率、召回率和f1分数的大小,最后计算了宏平均和加权平均的结果,其中宏平均是对所有类别的分类结果进行平均,加权平均是对宏平均的一种改进,考虑了每个类别样本数量在总样本中占比,实验结果显示模型的整体分类准确率可以达到99.93%,宏平均精确率、召回率和f1分数分别可以达到99.98%、100%、100%,加权平均精确率、召回率和f1分数分别可以达到100%、100%、100%。总之,不管是对于样本量较少的ftps_down、skype_audio流量还是样本量加较多的ftp流量都能实现很高的准确率。此外,同一种应用程序的不同服务流如facebook中的会话和视频流量模型也能准确的进行分类,而不同应用程序相似的服务流如facebook的视频流、hangouts的视频流、skype的视频流,模型也能较好地提取特征并有效区分。总之,本文所提出的残差卷积网络模型在针对相似的细粒度流量数据进行分类时有
较好的性能。
[0185]
表5每一类的精确率、召回率、f1分数、样本量和各类准确率
[0186][0187][0188]
为了更好地观察每一类流量在分类时模型将其所分到的具体类型,我们还计算了模型分类结果的混淆矩阵图如图6所示,其中,右侧表示分类准确率的热力值,准确率越高,分类的精度就越高,颜色也就越深,横坐标表示模型预测的结果,纵坐标表示真实的标签。从图中可以明显第地看出对角线上的值颜色最深,这也表明模型能够很好地区分各类流量,同时也可以看出各类流量在进行分类时会被模型分到哪些类别,比如hangouts_chat流量在进行分类时会有0.001%的样本被分为facebook_chat流量。
[0189]
(5)比较实验
[0190]
数据集
[0191]
为了验证模型在流量分类任务上的有效性和多功能性,使用与上述实验相同的超参数在ustc-tk流量数据集上进行了实验,该流量数据集包含了十种流量,其中有八种通用的不同应用程序流量,这些流量一部分是从真实网络环境中收集的来自公共网站的恶意软件流量,另一部分是使用ixia bps流量模拟设备收集的正常流量。实验之前对数据集进行了相同的预处理操作,将原始的pcap形式流量转化为idx形式的数据。实验结果如下表,由于数据集中的十类流量属于不同应用程序,具有明显的区分度,因此我们的模型可以实现几乎100%的分类准确率。从图7的混淆矩阵也可以看出几乎所有样本都能给正确归类,只有0.3%的ftp流量被识别为了mysql流量。因此,本文所提出的模型同样适用于其他粒度的流量数据集的分类任务。
[0192]
表6 ustc-tk数据集每一类的精确率、召回率、f1分数、样本量和各类准确率
[0193][0194][0195]
(6)与其他先进方法比较
[0196]
为了验证本文提出的模型在细粒度流量分类任务中的先进性,我们横向比较了经典的残差网络模型resnet-18在cic_tf数据集上的表现,同时纵向比较了其他深度学习方法如1d-cnn、lstm,模型具体参数设置如表7所示(以实验过程中的最佳效果为准):
[0197]
表7对比模型具体参数设置
[0198][0199]
实验的准确率、精确率、召回率以及f1分数结果如表8及图8所示,从表8中可以看出,目前先进的深度学习方法均能实现80%以上的分类准确率,具体而言,普通一维卷积神经网络、循环神经网络、经典残差网络的整体分类准确率分别能达到86%、92%、95%,而本文提出的改进的残差卷积模型的整体准确率能达到99%,相比于其他三种方法分别能提高13%、7%、2%。从图8可以更直观地看出本文提出的模型明显优于其他类型的深度学习方法。
[0200]
表8对比实验结果(accuracy、precision、recall、f1-score)
[0201]
methodsaccuracyprecisionrecallf1-scoreproposed0.990.991.001.00resnet-180.950.890.870.901d-cnn0.860.850.830.84rnn0.920.910.880.90
[0202]
(7)超参数对比
[0203]
我们在数据集cic_tf上进行了一系列实验探索超参数设置对模型准确度的影响,
主要超参数包括:训练周期epoch、残差块的数量block_num、学习率lr、batch_size,对于每一个实验只改变一个参数的值,其他参数的值使用默认的值。图9为各类超参数对模型效果的影响。如图9(a)所示,随着epoch增加,模型准确率不断上升,在epoch为150时达到最优准确率,但当epoch继续增大时模型的学习能力开始下降。图9(b)显示了残差块的数量对模型效果的影响,当残差块数量只有一个时,模型并不能很好地学习所有的特征,当残差块增加到2时,模型效果有显著的提升,但残差块的数量并不是越多就能越好地学习,相反,随着残差块数量的增加模型可能开始退化。图9(c)显示了学习率对模型效果的影响,训练过程中以0.5倍更新学习率的大小,可以明显地看出,对于本文的模型而言,学习率为0.01时效果最佳,随着学习率的进一步减小,模型效果出现了灾难性的下降。图9(d)探索了批量大小对于模型分类效果的影响,相关实践证明batch的大小通常为2n时效果最佳,经过进一步实验发现,随着batch不断增大,模型效果显著提升并在128时达到最优,当batch继续增大,模型并不能学习到更细微的特征进而使模型的准确率开始下降。
[0204]
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1