一种数据纵向切分下保护隐私的动态关联预测方法及装置与流程
本发明涉及差分隐私的动态关联,尤其涉及一种数据纵向切分下保护隐私的动态关联预测方法及装置。
背景技术:
1、随着社会信息化和网络化的发展,数据俨然已成为信息时代重要的基础性战略资源和关键性生产要素。动态关联分析,是指基于用户过往的数据使用信息,以及用户之间的社会网络信息,来预测特定用户感兴趣的数据。动态关联分析一方面可以为用户提供推荐服务,从而帮助用户解决数据爆炸式增长带来的信息过载问题,另一方面也可以帮助系统来检测用户对数据的异常读写需求,从而发现恶意的或者已经被攻击者攻陷的用户账户,因而有着广泛的应用场景。
2、对于动态关联分析方案来说,当拥有更充足的用户数据时,给出的预测结果通常也会更加准确。然而,同一用户的不同类型的数据可能分布在不同的数据方,同时各个数据方出于利益和法规的原因,不能直接交换各自所拥有的原始用户数据。那么,数据方如何在保护各自用户数据隐私的前提下,通过有效的协作共享来提升动态化分析算法的表现?差分隐私通过对数据集加入噪声数据进行微小扰动,以此实现更改单一数据实例并不影响数据集对特定问题的可用性。差分隐私作为一种保护隐私的理论框架,能够提供严格的隐私保护证明,同时支持对系统的隐私保护程度进行定量的组合分析,因而成为面向机器学习的最有前途的隐私保护途径之一,也是动态关联分析算法中保护隐私的重要技术。
3、现有基于差分隐私的动态关联分析方案的研究工作相对较少,已有的几种方法也都有一定的局限性,只能应用于二值型的用户与数据关系或者对用户的隐私保护强度有限。具体来说,2014年jorgensen等在扩展数据库技术国际会议上发表的《a privacy-preserving framework for personalized,social recommendations》一文和2018年guo等在国际期刊《information sciences》上发表的《differentially private graph-linkanalysis based social recommendation》一文,提出的方法都只适用于用户与数据之间的关系是二值型的,即用户最近使用过或者未使用过某一数据,但不能反映用户对数据的使用频次(即用户与数据之间的关系是数值型的)。为此,2017年xian等人在高性能计算与通信国际会议上发表的《pptrustcf:a new privacy protection algorithm for trustcollaborative filtering》一文和2018年meng等人在aaai人工智能会议上发表的《personalized privacy-preserving social recommendation》一文分别提出了针对数值型数据的基于差分隐私的社会化推荐算法,由于在目标函数上或梯度计算中的误差值上添加拉普拉斯噪声,虽然保护数值型的用户与数据关系的隐私,而用户是否使用过某一数据,是可以通过预测结果推断出来的,因此隐私保护强度有限。
4、为了提高动态关联分析预测结果的准确性和成功率,有时需要融合不同数据方(如不同的网站)所拥有的数据。根据数据融合的情况,可主要分为数据横向切分和数据纵向切分。前者指的是不同数据方拥有不相交的用户对相同数据项的评价数据(或用户使用数据的频次等用户与数据项的对应关系)。后者通常指的是不同数据方拥有相同用户对不相交的数据项集的评价数据(或用户使用数据的频次等用户与数据项的对应关系)。数据纵向切分在动态关联分析中更为常见,如2020年shmueli等在国际期刊《acm transactionson intelligent systems and technology》上发表的《mediated secure multi-partyprotocols for collaborative filtering》一文。此外,2019年yang等在国际期刊《acmtransactions on intelligent systems and technology》上发表的《federated machinelearning:concept and applications》则引入了另一种数据纵向切分的概念,即一个数据方拥有用户使用数据的情况,而另一个数据方拥有关于这些用户的用户特征信息,并提出了一种基于矩阵分解技术的联邦推荐算法。
5、联邦学习是一种保护数据隐私的分布式机器学习技术,数据不需要离开本地,而是通过参数交换来联合建立一个全局的共享模型。将联邦学习用于动态关联分析,来实现数据融合时的隐私保护,存在两个主要问题:首先,联邦学习作为隐私保护技术仍有缺陷,它主要保护用户终端收集数据过程中的安全性,但训练模型及其使用过程中还是可以恢复部分训练样本的信息。其次,使用联邦学习的动态关联分析时往往会导致推荐结果有损、运行效率较低。
技术实现思路
1、本发明要解决的技术问题是:
2、1)差分隐私是一种有效的隐私保护机制,但将其应用于动态关联分析时,会出现保护信息不全面、支持数据类型受限等问题。即,适用于对二值型数据的隐私保护;而将其用于数值型数据时,可以保护数值的隐私,但对用户是否使用了数据这一敏感信息起不到保护作用。
3、2)当动态关联分析使用联邦学习时,它对数据(即训练样本)的隐私保护是指本地数据不需要上传到参数服务器,但训练模型及其使用过程还是有可能泄露数据的部分信息。
4、3)当需要融合不同数据方之间的数据时,就会导致系统增加了不同数据方之间的通信开销,需要在保证系统安全和推荐准确的条件对系统的通信开销进行优化。
5、有鉴于此,本发明提供一种数据纵向切分下保护隐私的动态关联预测方法及装置。
6、本发明采取的技术方案是,所述一种数据纵向切分下保护隐私的动态关联预测方法,包括:
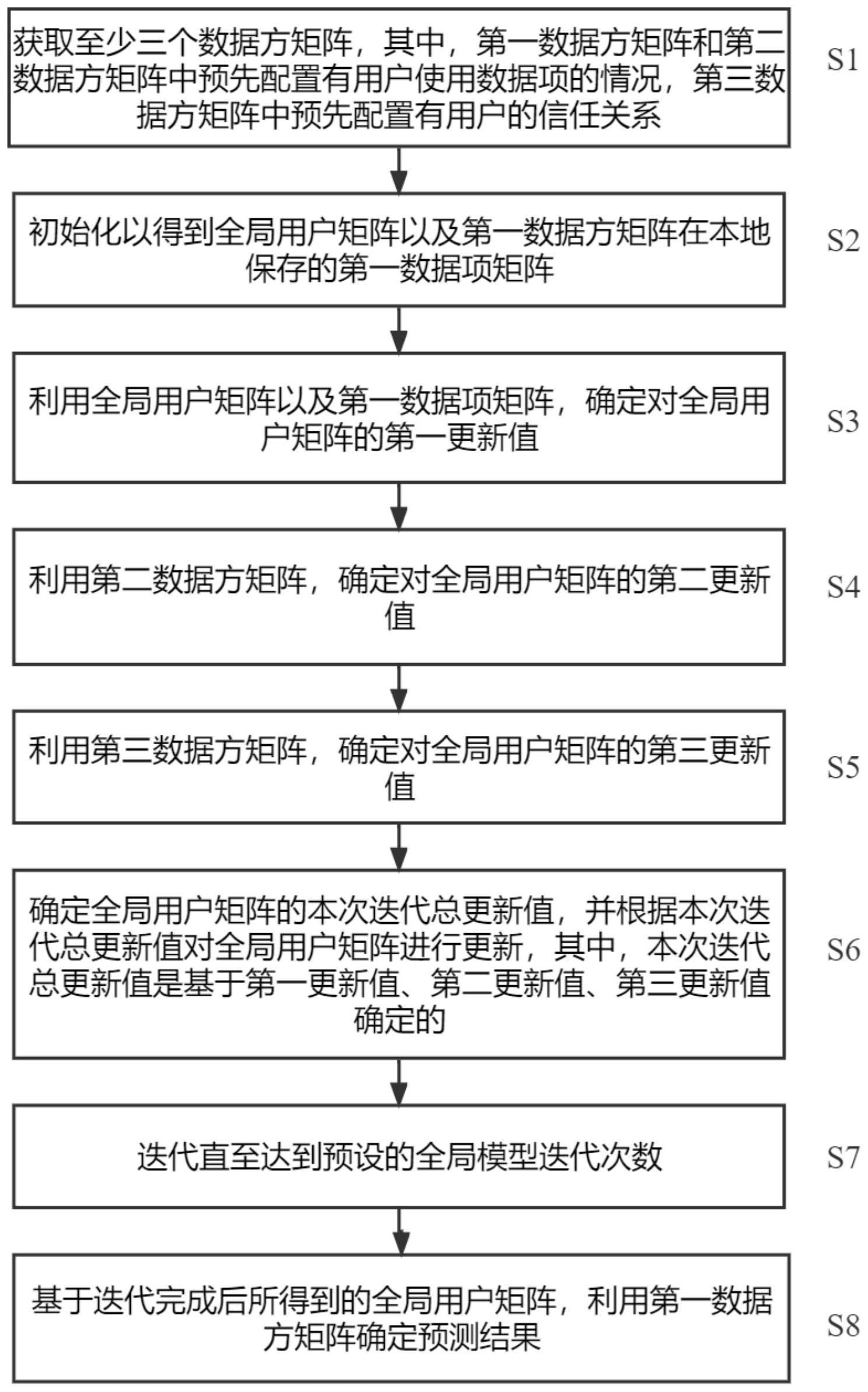
7、获取至少三个数据方矩阵,其中,第一数据方矩阵和第二数据方矩阵中预先配置有用户使用数据项的情况,第三数据方矩阵中预先配置有用户的信任关系;
8、初始化以得到全局用户矩阵以及所述第一数据方矩阵在本地保存的第一数据项矩阵;
9、利用所述全局用户矩阵以及所述第一数据项矩阵,确定对所述全局用户矩阵的第一更新值;
10、利用所述第二数据方矩阵,确定对所述全局用户矩阵的第二更新值;
11、利用所述第三数据方矩阵,确定对所述全局用户矩阵的第三更新值;
12、确定所述全局用户矩阵的本次迭代总更新值,并根据所述本次迭代总更新值对所述全局用户矩阵进行更新,其中,所述本次迭代总更新值是基于所述第一更新值、所述第二更新值、所述第三更新值确定的;
13、迭代直至达到预设的全局模型迭代次数;
14、基于迭代完成后所得到的全局用户矩阵,利用所述第一数据方矩阵确定预测结果。
15、在一个实施方式中,当数据方矩阵的数量大于三个时,在已经确定所述第一数据方矩阵的情况下,若一数据方矩阵中预先配置有用户使用数据项的情况,则作为所述第二数据方矩阵进行处理,若一数据方矩阵中预先配置有用户的信任关系,则作为所述第三数据方矩阵进行处理。
16、在一个实施方式中,所述初始化以得到全局用户矩阵以及所述第一数据方矩阵在本地保存的第一数据项矩阵的步骤中,是采用随机值初始化以得到全局用户矩阵。
17、在一个实施方式中,所述利用所述全局用户矩阵以及所述第一数据项矩阵,确定对所述全局用户矩阵的第一更新值,包括:
18、将所述第一数据方矩阵配置为全局用户矩阵;
19、随机选取至少两条数据项数据,利用预先配置的第一算法,确定所述数据项数据对所述第一数据方矩阵以及所述第一数据项矩阵对应的梯度,即第一数据方梯度以及第一数据项梯度;
20、利用预先配置的第三算法,确定所述第一数据方梯度以及所述第一数据项梯度的平均值;
21、利用预先配置的第四算法,确定平均值对应的加噪梯度平均值;
22、利用预先配置的学习率,基于加噪梯度平均值对所述第一数据方矩阵以及所述第一数据项矩阵进行更新,以获得更新后的所述第一数据方矩阵;
23、将更新后的所述第一数据方矩阵以及所述全局用户矩阵的差值,确定为本次迭代中所述全局用户矩阵的更新量;
24、进行迭代更新直至达到预设的第一数据方矩阵迭代次数,以得到所述第一更新值。
25、在一个实施方式中,所述利用所述第二数据方矩阵,确定对所述全局用户矩阵的第二更新值,包括:
26、将所述第二数据方矩阵配置为全局用户矩阵;
27、利用预先配置的第一算法,确定已获取的数据项数据对所述第二数据方矩阵以及第二数据项矩阵对应的梯度,即第二数据方梯度以及第二数据项梯度;
28、利用所述第二数据方梯度以及第二数据项梯度分别本地更新所述第二数据方矩阵以及第二数据项矩阵,以获得更新后的第二数据方矩阵;
29、将更新后的所述第二数据方矩阵以及所述全局用户矩阵的差值,确定为本次迭代中所述全局用户矩阵的更新量;
30、进行迭代更新直至达到预设的第二数据方矩阵迭代次数,以得到所述第二更新值。
31、在一个实施方式中,所述利用所述第三数据方矩阵,确定对所述全局用户矩阵的第三更新值,包括:
32、将所述第三数据方矩阵配置为全局用户矩阵;
33、利用预先配置的第二算法,确定所述第三数据方矩阵对应的梯度,即第三数据方梯度;
34、利用所述第三数据方梯度本地更新所述第三数据方矩阵,以获得更新后的第三数据方矩阵;
35、将更新后的所述第三数据方矩阵以及所述全局用户矩阵的差值,确定为本次迭代中所述全局用户矩阵的更新量;
36、进行迭代更新直至达到预设的第三数据方矩阵迭代次数,以得到所述第三更新值。
37、在一个实施方式中,基于多方安全计算协议,利用所述第一更新值、所述第二更新值、所述第三更新值,确定所述本次迭代总更新值。
38、本发明的另一方面还提供了一种数据纵向切分下保护隐私的动态关联预测装置,包括:
39、获取模块,被配置为获取至少三个数据方矩阵,其中,第一数据方矩阵和第二数据方矩阵中预先配置有用户使用数据项的情况,第三数据方矩阵中预先配置有用户的信任关系;
40、初始化模块,被配置为初始化以得到全局用户矩阵以及所述第一数据方矩阵在本地保存的第一数据项矩阵;
41、第一数据方矩阵模块,被配置为利用所述全局用户矩阵以及所述第一数据项矩阵,确定对所述全局用户矩阵的第一更新值;
42、第二数据方矩阵模块,被配置为利用所述第二数据方矩阵,确定对所述全局用户矩阵的第二更新值;
43、第三数据方矩阵模块,被配置为利用所述第三数据方矩阵,确定对所述全局用户矩阵的第三更新值;
44、加权模块,被配置为利用所述第一数据方矩阵计算所述全局用户矩阵的本次迭代总更新值,并根据所述本次迭代总更新值对所述全局用户矩阵进行更新,其中,所述本次迭代总更新值是基于所述第一更新值、所述第二更新值、所述第三更新值确定的;
45、迭代模块,被配置为迭代直至达到预设的全局模型迭代次数;
46、预测模块,被配置为基于迭代完成后所得到的全局用户矩阵,利用所述第一数据方矩阵确定预测结果。
47、本发明的另一方面还提供了一种电子设备,所述电子设备包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述计算机程序被所述处理器执行时实现如上任一项所述的数据纵向切分下保护隐私的动态关联预测方法的步骤。
48、本发明的另一方面还提供了一种计算机存储介质,所述计算机存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项所述的数据纵向切分下保护隐私的动态关联预测方法的步骤。
49、采用上述技术方案,本发明至少具有下列优点:
50、本发明所述的数据纵向切分下保护隐私的动态关联预测方法,对数值型的用户与数据间的关联信息(包括用户是否使用过该数据的信息)进行了隐私保护;进一步加强了使用联邦学习过程中的安全性和隐私性;优化了在融合不同数据方数据时的通信开销。
- 还没有人留言评论。精彩留言会获得点赞!