基于模糊强化学习的销售语音推送决策方法与流程
1.本发明涉及语音营销领域,尤其是涉及基于模糊强化学习的保险销售语音推送决策方法。
背景技术:
2.在语音营销领域,常采用智能语音推送技术向客户推送信息以减少人工成本,降低工作强度。但目前成熟的语音推送技术多为单向推送,即语音机器人根据客户的行为习惯,建立信息推送模型,从而决策推送信息。交互式推送功能可以根据客户的回应,进行针对性的信息推动。但目前这种交互式推送的功能十分简单,通常只具备简单的语言识别功能,并根据识别结果,再次向客户提问是否是哪个问题,根据客户的回答“是”、“否”或者数字编号来完成交谈。其智能化水平较低,用户体验差。
3.同时,现有的语音推送技术,仅能对用户给出的如“是”、“不是”、“好”等确定性语言给出相应的回应。但如果客户表达的信息式模糊的,如“嗯,我在想想”或者说“嗯,还没有想好”之类带感情色彩,意义模糊话,现有电话语音推送技术就无法得出确定性的结论,进一步完成交谈,用户体验感极差。
4.在语音营销领域,各种各样差异性需求的客户常以模糊应答回应语音机器人,仅采用确定性信息来做决策无法有效满足销售行业的特殊需求。如目前保险电话销售行业,先使用语音机器人拨打潜在客户电话,采用自动语音的方式与客户联系,当客户没有关断电话或者听到“好”、“行”等简单的肯定的回答后,就由人工直接介入,继续与客户交流,促成销售成单率。如何在识别客户语音辨识语音频率后,根据客户模糊性的、具有感情色彩的信息反馈,进一步推送合理的语音内容,强化客户的信任感、认同感和价值感,从而提高销售成功率,还尚未由针对客户模糊性的、具有感情色彩的信息反馈的电话语音智能推送功能的产品。
技术实现要素:
5.本发明目的在于提供一种基于模糊强化学习的保险销售语音推送决策方法,解决客户以模糊应答回应语音机器人,无法推送合理语音内容的问题。
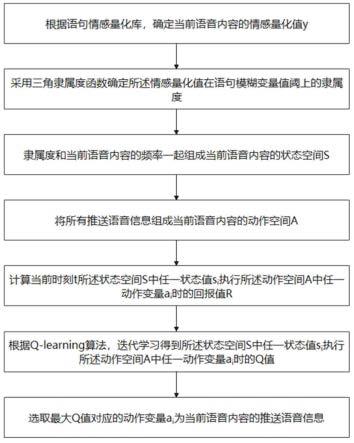
6.为实现上述目的,本发明采取下述技术方案:本发明所述的基于模糊强化学习的销售语音推送决策方法,包括以下步骤:s1,根据语句情感量化库,确定当前语音内容的情感量化值y;s2,采用三角隶属度函数确定所述情感量化值在语句模糊变量值阈上的隶属度;s3,所述隶属度组成当前语音内容的状态空间s;s4,将所有推送语音信息组成当前语音内容的动作空间a;s5,计算当前时刻t所述状态空间s中任一状态值si执行所述动作空间a中任一动作变量ai时的回报值;s6,根据q-learning算法,迭代学习得到所述状态空间s中任一状态值si执行所述
动作空间a中任一动作变量ai时的q值;s7,选取最大q值对应的动作变量ai为当前语音内容的推送语音信息。
7.本发明将识别的语音信息进行情感量化,其结果在建立的情感模糊模型上推理出语音信息在语句模糊变量值阈上的隶属情况。再通过q表的值和决策算法确定推送的语句,通过多次迭代学习,可使q值表学习到适应销售语音推送的最优值。
8.进一步地,所述语句情感量化库根据历史经验,抽取语句关键词,并语句及关键词评分。
9.进一步地,所述语句模糊变量值阈 ,其中分别代表很不高兴、不高兴、一般、高兴、很高兴;的取值范围为进一步地,所述动作空间a中所述所有推送语音信息的编码按照情感等级从低到高排列。
10.进一步地,所述回报值计算公式为:;其中为权重因子,表示所述语句模糊变量阈值中和变化的权重。
11.进一步地,所述q值迭代规则为:其中和为学习率,r为当前所述状态空间s中任一状态值si执行所述动作空间a中任一动作变量ai后的回报值;为当前所述状态空间s中状态值si执行所述动作空间a中动作变量ai后进入下一个状态值s
i’执行所述动作空间a中动作变量ai的值;max代表取状态值s
i’执行所述动作空间a中所有动作变量ai的值的最大值。
12.进一步地,所述状态值si为所述隶属度除以0.1取整后再乘以0.1。
13.本发明的优点在于在电话销售过程中,对客户表达信息进行模糊建模,从而确定较为精确的客户需求;同时采用强化学习原理,设计语音推送内容的智能决策方法,针对客户的模糊的语言内容、感情色彩,推送合理的语音内容,提高电话销售的智能化水平,提高语音机器人的智能化水平。
附图说明
14.图1是本发明所述方法流程图。
15.图2是本发明所述方法中三角隶属度函数示意图。
具体实施方式
16.下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
17.如图1所示,本发明所述的基于模糊强化学习的销售语音推送决策方法,包括以下步骤:s1,根据语句情感量化库,确定当前语音内容的情感量化值y;根据销售人员的历史经验,从众多客户语句中抽取语句关键词,并根据销售人员的历史经验,给这些语句及关键词评分。评分范围可为[-1,1],其中-1表示最大的负面情绪,1表示最大的正面情绪。当前语音内容的情感量化值y参照已经评分的语句或关键词确定。
[0018]
s2,采用三角隶属度函数确定所述情感量化值在语句模糊变量值阈上的隶属度;首先根据模糊理论,建立语句模糊变量阈,,其中分别代表很不高兴、不高兴、一般、高兴、很高兴;的取值范围为。如图2所示,的取值范围为,其中的范围为,的范围为,的范围为,的范围为,的范围为。
[0019]
采用三角隶属度函数确定s1步中确定的当前语音内容的情感量化值,计算出述情感量化值在语句模糊变量值阈上的隶属度。如当前客户语音内容为“还可以吧”,其情感量化值y=0.8,如图2所示,根据三角隶属度函数确定出该值在5个语句模糊变量值的隶属度为0,0,0,0.1,0.6。
[0020]
s3,隶属度和当前语音内容的频率一起组成当前语音内容的状态空间s;状态空间s中的状态变量包括,其中的值分别对应5个语句模糊变量值的隶属度,的值为当前语音内容的频率f。
[0021]
s4,将所有推送语音信息组成当前语音内容的动作空间a;动作空间a中所述所有推送语音信息的编码按照情感等级从低到高排列。
[0022]
根据销售人员的历史经验,整体所有的n条推送语音信息组成动作空间a,且将每条推送语音信息记为ai,其中i为该条推送语音信息的编号,i的取值为1至n之间的整数。所有的n条推送语音信息按照情感等级从低到高的顺序赋予编号,组成动作空间a。
[0023]
s5,计算当前时刻t所述状态空间s中任一状态值si执行所述动作空间a中任一动作变量ai时的回报值;回报值反映了在状态变量为si时,执行动作ai,用户反馈的下一时刻的情感变化结果,如果情感变差则回报值为负数;情感变好时,则为回报值为正数。回报值函数仅考虑当前语音内容的情感量化值在5个语句模糊变量值的隶属度,不考虑当前语音内容的频率f。
[0024]
回报值计算公式为:,其中为权重因子,表示所述语句模糊变量阈值中和变化的权重。通常情况下。取值范围为,ai取值范围为a1至an。
[0025]
s6,根据q-learning算法,迭代学习得到所述状态空间s中任一状态值si执行所述动作空间a中任一动作变量ai时的q值;q-learning算法是基于马尔科夫决策过程的强化学习算法。其根据建立的状态空间、动作空间和回报值,迭代学习更新q值,即在状态变量为si时,执行动作ai后,系统后续变化所带来的回报值的叠加。如表1中的q值表施例。
[0026]
表1
在表1中,si的取值为:即,将si的值归一化到0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1几个等级上。当状态值为si执行动作a1时,则a1对应的位置为1,否则为0。
[0027]
q值迭代规则为:,其中和为学习率,r为当前所述状态空间s中任一状态值si执行所述动作空间a中任一动作变量ai后的回报值;为当前所述状态空间s中状态值si执行所述动作空间a中动作变量ai后进入下一个状态值s
i’执行所述动作空间a中动作变量ai的值;max代表取状态值s
i’执行所述动作空间a中所有动作变量ai的值的最大值。在初始状态下可将所有的q值预设为0或其他任意数值,然后按照q值迭代规则学习,直到q值收敛即可。
[0028]
s7,选取最大q值对应的动作变量ai为当前语音内容的推送语音信息。即在状态值为si执行动作ai时,q值最大,则该ai编号对应的推送语音信息为当前的最佳输出。当最大q值存在多个ai的,则在多个ai中随机选取一个动作值作为输出。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1