一种具有对比机制的相似度感知框架的医学图像分割方法
1.本技术属于带有限制性标注数据的医学图像分割领域,具体涉及一种具有对比机制的相似度感知框架的医学图像分割方法。
背景技术:
2.医学图像分割在医学图像处理中扮演着重要的角色,是分析医学图像的首要步骤。目的是使图像中解剖或病理结构的变化更加清晰,进而辅助解剖结构和感兴趣区域。
3.传统的医学图像分割大多基于阚值、区域、边缘检测和聚类分析。由于传统方法大多需要人工设计特征,不能够自动化地实现分割。并且不同的医学数据集需要不同的图像处理,传统的方法不足以应对日益增长的各式各样复杂的数据集。
4.由于神经网络拥有强大的表征能力,不再需要手工制作特征就可以实现端对端的分割,这也引起了研究人员的关注,并广泛地应用在生物医学领域。然而,深度学习的模型训练需要大量的标注数据才可以训练出一个具有强的表征能力模型。这需要花费大量的时间和成本,特别是获取大量带有高质量的标注的医学数据。
5.对比学习是一种自监督学习(self-supervised learning,ssl)方法,可以从大规模数据中学习图像级特征,而不需要任何手动标注。对比学习的主要思想是比较样本对在表示空间中的相似性,将相似对(正对)的表示集合在一起,分离不同对(负对)的表示。虽然对比学习是一种很有前途的方法,但目前对比学习不仅需要大量的正反例样本,而且对比学习是学习图像级特征,还没有能力操作用于像素级的任务,像对感兴趣的部分进行分割。因此,大多数先进的分割模型仍然基于监督学习,能稳定地产生准确的分割。
技术实现要素:
6.本技术提出了一种具有对比机制的相似度感知框架的医学图像分割方法,准确的生物医学图像分割是临床诊断的基础。基于卷积神经网和transformer的分割方法在各种医学成像模式中取得了优异的性能。这些方法大多是基于大规模精确注释的监督学习。然而,用于生物医学的专业注释数据很难获得。此外,大多数研究集中在复杂的网络结构上,而不是充分挖掘未标记图像的潜在特征。这些有监督的学习方法可以在注释良好的数据集中获得有竞争力的性能,但在还存在一定的空间可以继续提升分割性能。在本研究中,为了进一步提升带有限制性标注的医学图像分割的效果,我们提出了一种具有对比机制的相似度感知框架的医学图像分割方法,以保持监督学习的分割精度,并学习更多数据的潜在有效特征。与传统的对比学习不同,我们的方法将监督学习和对比学习同时结合起来,监督模块提供监督信息指导,并通过对比模块对未标注数据进行相似性分析,充分挖掘潜在特征。该框架可以在现有的模型上,进一步的完善模型,提高模型的分割精度。
7.为实现上述目的,本技术提供了如下方案:
8.一种具有对比机制的相似度感知框架的医学图像分割方法,包括以下步骤:
9.获取图像数据;
10.对所述图像数据进行增强,得到图像数据集;
11.基于所述图像数据集,选择分割模型;
12.对所述分割模型进行对比学习,提高所述分割模型分割性能;
13.对所述进行对比学习的分割模型再进行监督学习,共同训练模型;
14.对所述共同训练的模型进行损失优化,优化后的模型用于医学图像分割。
15.优选的,对所述图像数据进行增强的方法包括:组合数据增强和非线性变换增强。
16.优选的,所述组合数据增强的方法包括:几何变换与色彩空间变换的组合或几何变换与色彩空间变换自身的组合。
17.优选的,所述非线性变换增强的方法包括:随机擦除和cutmix。
18.优选的,对所述分割模型进行对比学习的方法包括:将所述数据增强的数据集输入分割模型,分割模型对其进行输出,对输出的数据进行矩不变量映射。
19.优选的,所述进行监督学习的方法包括:选择不同分割损失函数。
20.优选的,对所述共同训练的模型进行损失的方法包括:对比损失函数和监督损失函数。
21.优选的,所述对比损失函数的方法包括:
22.余弦相似度对比损失函数的公式如下:
23.余弦相似度公式如下:
[0024][0025]
其中,zi,zj表示两个矩不变量映射,sim(
·
)函数表示相似度计算,z
it
zj表示两个对应向量相乘,||zi||||zj||表示两个对应两个向量的模;
[0026][0027]
式中,zi,zj表示两个矩不变量映射,sim(
·
)函数表示相似度计算,exp(
·
)表示是指数函数;
[0028]
误差对比损失函数的公式如下:
[0029][0030]
||||2表示对符号里面取绝对值,即二范数;表示相对于zi的相对误差。
[0031]
优选的,所述监督损失函数的方法包括:监督损失函数的公式如下:
[0032][0033]
优选的,所述优化后的模型用于医学图像分割的方法包括:基于所述对比损失函数和所述监督损失函数确定最终总损失函数,然后最小化总损失函数,更新训练模型达到迭代次数为止。
[0034]
本技术的有益效果为:
[0035]
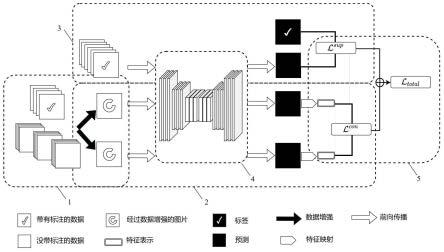
针对生物医学图像分割数据集稀缺的问题,本技术提出了一种基于对比度机制的相似感知的医学图像分割框架(simbis),可灵活应用于不同的分割模型。目前大多数研究都集中在复杂的网络结构上,而不是像本专利从数据层面上去充分地探索潜在的特征。该框架包括一个数据增强模块(1)、一个对比模块(2)、一个监督模块(3)、一个分割模型(4)和损失函数(5)。此外,网络模块可以灵活应用于任何不同的分割模型。能够做到即插即用,并且可以在原有的模型上再继续优化得到更精准的分割效果。
[0036]
simbis设计了多种数据增强功能。数据增强模块采用线性变换增强和非线性变换增强相结合的方法来提高增强图像的可分辨性,不仅提高图像的丰富性和多样性,数据增强模块还能与对比模块形成一种对抗机制。具体是,数据增强模块尽可能使图片的区分度更大,而对比模块通过自监督使图像的特征映射的相似度的误差更小(或者相似度更大),进而优化网络和得到更具泛化和稳定的分割模型。本技术采用数据增强模块,既能实现适当的数据增强,在一定程度上可以缓解小规模医学图像分割数据稀缺的问题;又能有效地避免因过度有标注的数据增强使训练数据趋向于同个分布,进而导致的过拟合现象。
[0037]
本技术设计一种监督学习和对比学习的联合学习策略。与现有模型相比,更充分地挖掘图像的潜在特征,获得更准确的分割。与传统的对比学习不同,simbis将监督学习和对比学习同时结合起来,通过监督模块提供监督信息指导,并通过对比模块充分挖掘数据中潜在的相似性分析和学习特征,以保持监督学习分割的准确性,并学习数据的潜在有效特征。
[0038]
在对比模块中设计了新的对比损失函数和特征投影映射。在监督模块的指导下,对比损失函数仅使用正例计算相似度损失。这样可以避免对比学习中需要大量正负例来计算相似度的问题,极大地减少了计算量和提升了计算效率。损失函数用一个低维向量矩不变量来测的网络输出之间的相似性,一方面,将数据转化为低维向量可以大幅度减少训练的计算量,另一方面矩不变量可以直接衡量目标的相似性,本技术利用矩不变量的特性,将其作为一种特征表示,并应用在衡量从网络推导出的预测的差异,它们应该是完全相同或者是几乎一致的,这也减少了人工地增加标注的时间和支出。通过最大化预测间的相似性(或最小化预测的差异),可以从另外一个角度来优化分割边界和预测的全局分布。
[0039]
在总的损失函数中,由于simbis框架结合了监督学习和对比学习,因此总损失函数是监督损失函数和对比损失的加权和。它可以权衡监督学习和对比学习两者的效益,并用于反向传播来优化分割模型。
附图说明
[0040]
为了更清楚地说明本技术的技术方案,下面对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0041]
图1为本技术实施例的一种具有对比机制的相似度感知框架的医学图像分割方法结构示意图;
[0042]
附图标记说明:
[0043]
1、数据增强模块;2、对比模块;3、监督模块;4、分割模型;5、损失函数。
具体实施方式
[0044]
发明人在对医学图像进行分割的时候,发现使用小规模带有标注的数据对模型训练,最终的分割效果不能过充分地得到理想的效果。根据实验分析,可能是因为数据规模不够不能充分训练好一个网络的参数。为此,我们想使用数据增强技术来扩充我们的数据集,以求得训练好一个更具有泛化性的神经网络。但是经过我们的实验表明,过多的增强的数据并不会提高模型的性能,反而会造成过拟合。对于这个问题,我们提出了一个数据增强模块,这是一种部分的随机增强技术,通过人为地设置一个数据增强比例,对这部分数据进行随机数据增强,这些数据增强变换可以简单的组合变换增强(几何变换与色彩空间变换的组合,也可以是几何变换与色彩空间变换自身的组合),也可以是一些简单的非线性变换(随机擦除,cutmix),以期待于产生新的样本,迫使模型学习更多的特征表示。对于单单使用数据增强技术是不够的,我们还想利用这些大量未标注的数据。通过利用对比学习的机制来学习到这些大量无标注数据的宝贵的底层特征,进而提高原有模型的分割性能。我们还设计了一个对比模块,还给出了新的对比损失函数和特征投影映射。在监督模块的指导下,对比损失函数仅使用正例计算相似度损失。对比损失函数用一个低维向量矩不变量来测的网络输出之间的相似性。最后,由于联合监督学习和对比学习,监督模块为对比模块的分割区域提供监督信息指导,对比模块可以通过相似度分析为监督模块挖掘更多潜在特征,进而得到更为精准又具备泛化性的模型。
[0045]
下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
[0046]
为使本技术的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本技术作进一步详细的说明。
[0047]
实施例一
[0048]
如图1所示,为本技术实施例的一种具有对比机制的相似度感知框架的医学图像分割方法结构示意图,包括以下步骤:
[0049]
获取数据;
[0050]
对数据进行增强,得到数据集;将从部分带有标注和未标注数据生成增强数据集,根据数据集的特征,选择符合数据集的数据增强的变换集合。
[0051]
组合数据增强可以是几何变换与色彩空间变换的组合,也可以是几何变换与色彩空间变换自身的组合。但是,数据增强的安全性必须根据任务来考虑。
[0052]
非线性变换增强包括随机擦除和cutmix两种变换增强,非线性变换增强t,t'~t有利于产生新的样本,使模型学习更多的特征表示。
[0053]
设t是数据增强操作的集合,组合数据增强t1和非线性变换增强t2是两个从数据增强t中采样的独立不同数据增强操作,{t1,t2}∈t;并且设随机擦除为t
re
,cutmix为t
cm
,非线性变换增强{t
re
,t
cm
}∈t2。
[0054]
数据集:本实施例使用了部分带有标注的数据和额外没有标注的相同域和相似域的数据通过上述的数据增强模块获得增强图像。其中,原始图像作为锚点,其增强后的图像作为正样本。{xi,xj}为一对经过数据增强t变换后的数据对。
[0055]
对于带有标注的图像{xn,yn}
n=1...n
和没有标注的图像{xm}
m=1...m
,设定比例因子α,只采取了αn+m张图片参与对比学习训练。
[0056]
对于所有的图片xk,k∈αn+m,它的两个变换可以表示为:xi=t(xk)、xj=t'(xk)生成用于对比学习的数据集。
[0057]
基于数据集,选择分割模型;选择现有的任何的适用的神经网络模型,包括基于cnn的模型或者transformer的模型;为了衡量我们算法的性能,本实施例以pranet为分割模型,使用kvasir-seg,cvc-clinicdb和isic2018分割任务进行测试。具体的性能见表1,表2,表3。
[0058]
表1
[0059]
methoddsciourecallprecisionu-net0.5970.4710.6170.672res-unet0.690.5720.7250.745res-unet++0.7140.6130.7420.784sfa0.7230.611
‑‑
resunet-mod0.7910.4290.6910.871doubleu-net0.8130.7330.840.861colonsegnet0.8200.7230.8490.843pspnet0.8410.7440.8360.890hrnet0.8450.7590.8590.878ddanet0.8570.780.88800.864deeplabv3+0.8640.7860.8590.906fanet0.8800.8100.9060.901pranet0.89800.84
‑‑
hardnet-mseg0.9120.857
‑‑
transfuse-s0.9180.868
‑‑
transfuse-l0.9180.868
‑‑
simbis(our)0.9280.8760.930.939
[0060]
表2
[0061]
methoddsciourecallprecisionsfa0.70.607
‑‑
res-unet0.7780.4540.6680.887u-net++0.7940.729
‑‑
res-unet++0.7950.7960.7020.878u-net0.8230.755
‑‑
deeplav3+(xception)0.8890.8700.9250.936deeplav3+(mobilenet)0.8980.8580.9160.928pranet0.8990.849
‑‑
doubleu-net0.9230.8610.8450.959hardnet-mseg0.9320.882
‑‑
transfuse-s0.9180.868
‑‑
transfuse-l0.9340.886
‑‑
simbis(our)0.9290.8870.9570.926
[0062]
表3
[0063]
methoddsciourecallprecisionu-net0.6740.5490.708-attentionu-net0.6650.5660.717-r2u-net0.6790.5810.792-attentionr2u-net0.6910.5920.726-bcdu-net0.851-0.785-medt0.8590.778
‑‑
fanet0.8730.8020.8650.923deeplav3+(xception)0.8770.8120.8680.927deeplav3+(mobilenet)0.8780.8230.8830.924ce-net0.8910.816
‑‑
transunet0.8940.822
‑‑
dobleu-net0.8960.8210.8780.945simbis(our)0.9090.8430.8950.941
[0064]
根据数据集的特点,整理模型的数据加载模块;根据数据集图像的通道和尺寸,调整模型参数。
[0065]
对分割模型进行对比学习,提高分割模型分割性能;
[0066]
在对比模块中设计了新的对比损失函数和特征投影映射。在监督模块的指导下,对比损失函数仅使用正例计算相似度损失。对比损失函数用一个低维向量矩不变量来测的网络输出之间的相似性。
[0067]
为了能充分地挖掘数据的潜能进而继续提高模型的分割性能,我们想利用对比模块来达到这个目的。因为对比模块可以利用自我监督对比学习的机制,使模型学到更多有用的底层特征。
[0068]
相比传统的对比学习,对比学习模块充当了训练pre-texttask的角色。一般pre-texttask中学习的模型是用给随后的downstream task。但是我们设计的simbis框架,pre-texttask和downstream task是同时进行的。这样的设计动机是我们将对比自监督学习用在分割任务上。如果单单只训练pre-texttask接着再用给downstream task,即使自监督学习的过程使用大量的正样本和负样本进行对比学习,模型也很难去找到感兴趣的分割感兴趣部位是什么和在图片的哪个位置。simbis框架结合了监督模块(downstreamtask),可以指导pre-texttask在对比自监督学习上准确地学习待分割目标的特征。
[0069]
利用自我监督对比学习,使模型学到更多有用的底层特征,进而挖掘数据的潜能,继续提高模型的分割性能。
[0070]
将数据增强的数据集输入分割模型,利用数据增强生成的数据集{xi,xj}作为分割模型f(
·
)的输入,将这些数据集输送进分割模型f(
·
),模型的输出即为数据集的各自预
测。对于一张增强图片xi,它的分割预测可以表示为:分割模型对其进行输出,对输出的数据进行矩不变量映射,将这些每一个预测转化为矩不变量来表示。矩不变量可以将图片映射成一个低维的向量,并且矩不变量被证明是对于缩放、平移和缩放具有不变性。矩不变量的选择可以是胡矩不变(humomentinvariants)、几何矩不变量(geometricmoment invariants)、复矩不变(complexmomentinvariants)、勒让德矩不变量(legendremomentinvariants)和泽尼克矩不变量(zernike momentinvariants)。
[0071]
本实施例中选择胡矩不变(humomentinvariants),定义矩不变量映射为p
moment
(
·
),一张增强图片xi的特征表示可以表示为:
[0072]
对所述进行对比学习的分割模型再进行监督学习,共同训练模型;维持监督学习的分割精度,并学习未标记数据的潜在有效特征。监督学习能为对比学习的分割区域提供监督信息指导,而对比学习能够挖掘更多潜在的特征并将其提供给监督学习过程的学习,进而得到优化和获得更为精准的分割性能表现。在对于不同的特定的分割任务,使用者可以选择不同分割损失函数。
[0073]
一般来说,采用自我监督学习的计算机视觉管道包括执行两个任务:pre-text task和downstream tasks。downstream tasks是应用程序特定的任务,利用在pre-text task中所学的知识。而我们的simbis框架是与对比学习同时进行的。它会隐式地给对比学习提供目标和分割位置。
[0074]
对所述共同训练的模型进行损失,优化模型;基于对比损失函数和监督损失函数确定最终总损失函数,然后最小化总损失函数,更新训练模型达到迭代次数为止;
[0075]
在对比损失函数l
con
的构造中,包括余弦相似度对比损失函数和误差对比损失函数其中,
[0076]
余弦相似度对比损失函数:
[0077]
对于给定的两个矩不变量映射zi,zj,它们的余弦相似度可以表示为:
[0078]
式中,zi,zj表示两个矩不变量映射,sim(
·
)函数表示相似度计算,z
it
zj表示两个对应向量相乘,||zi||||zj||表示两个对应两个向量的模,即向量的数值大小。
[0079]
由于simbis框架结合了监督学习和对预测映射的学习。simbis有了一种导向作用对感兴趣的分割部位进行学习。此外,引入大量的负例会要求训练模型需要大的批尺寸和产生大量的计算。因此我们的对比损失计算也只使用正例计算对比损失,使用较小的批尺寸便可以对模型进行训练。
[0080]
余弦相似度对比损失函数可的公式如下:
[0081][0082]
式中,zi,zj表示两个矩不变量映射,sim(
·
)函数表示相似度计算,exp(
·
)表示是指数函数,然后对an+m个相加,再取平均。
[0083]
误差对比损失函数:
[0084]
在本实施例中,我们还提供了另外一种方案。可能在计算损失梯度的时候,数值的误差比向量的相似度更有利于反向传播。误差对比损失函数的公式如下:
[0085][0086]
||||2指的是对符号里面取绝对值,也就是二范数。指的是相对于zi的相对误差。
[0087]
监督损失函数:
[0088]
给定的{xn,yn}
n=1...n
,定义监督损失函数l
sup
为:
[0089]
利用对比损失函数l
con
和监督损失函数l
sup
,确定w
sup
,w
con
。
[0090]
simbis框架结合了监督学习和对比学习,因此总损失函数l
total
是监督损失函数l
sup
和对比损失l
con
的加权和。最终,我们的损失函数可以表示为:l
total
=w
sup
l
sup
+w
con
l
con
,然后最小化总损失函数l
total
,训练模型达到到迭代次数e为止。
[0091]
通过模型在测试集上的表现采用mdice(dice coefficient),miou(intersection-over-union),recall和precision来衡量模型性能的指标。
[0092]
实施例二
[0093]
针对生物医学图像分割数据集稀缺的问题,本技术提出了一种基于对比度机制的相似度感知的医学图像分割框架(simbis),可灵活应用于不同的分割模型。目前大多数研究都集中在复杂的网络结构上,而不是像本专利从数据层面上去充分地探索潜在的特征。该框架包括一个数据增强模块、一个对比模块、一个监督模块、一个分割模型和损失函数。此外,网络模块可以灵活应用于任何不同的分割模型。能够做到即插即用,并且可以在原有的模型上再继续优化得到更精准的分割效果。
[0094]
针对生物医学图像分割数据集稀缺的问题,提出了一种基于对比度机制的相似感知的医学图像分割框架。分割框架如图1所示。分割框架包含一个数据增强模块(1)、一个对比模块(2)、一个监督模块(3)、一个分割模型(4)和损失函数(5)。
[0095]
数据增强模块将从部分带有标注和未标注数据生成增强数据对,作为对比模块的输入。将对比模块(2)与监督模块(3)相结合,挖掘图像感兴趣区域的潜在特征,进一步提高目标任务的分割性能。分割模型(4)将为对比模块(2)与监督模块(3)提供分割模型。最后,损失函数(5)计算对比模块(2)与监督模块(3)的损失,并通过反向传播优化分割模型.具体simbis的算法可见算法1.
[0096]
[0097][0098]
本技术设计了多种数据增强功能。数据增强模块采用线性变换增强和非线性变换增强相结合的方法来提高增强图像的可分辨性,增加图像变换的多样性,还能与对比模块形成一种对抗机制。
[0099]
数据增强模块是为对比模块所服务的。所生成的增强图片将用于对比模块的对比学习。由于无监督对比学习比有监督学习更受益于数据增强,并且组合数据增加操作对于学习好的表征至关重要。
[0100]
不仅提高图像的丰富性和多样性,数据增强模块还能与对比模块形成一种对抗机制。具体是,数据增强模块尽可能使图片的区分度更大,而对比模块通过自监督使图像的特征映射的相似度的误差更小(或者相似度更大),进而优化网络和提高性能。
[0101]
在本技术中,数据增强操作t包含组合数据增强t1和非线性变换t2,其中{t1,t2}∈t。设t是数据增强操作的集合,其中t,t'~t是两个独立从t中采样的不同数据增强操作。
[0102]
组合变换增强:这些组合变换可以是几何变换与色彩空间变换的组合,也可以是几何变换与色彩空间变换自身的组合。但是,数据增强的安全性必须根据任务来考虑。
[0103]
非线性变换增强:为了提高图片的可区分度和增加图片变换的复杂性,我们引用了增加了随机擦除,t
re
和cutmix,t
cm
两种变换增强,{t
re
,t
cm
}∈t2。虽然非线性变换增强在一定的程度会破坏图片的完整性和产生对比相似度的误差。但是非线性变换增强似乎有利于产生新的样本,迫使模型学习更多的特征表示。
[0104]
在以往的研究已证明过多的数据增强并不会为监督学习带来更多的收益。另外,进行监督学习训练,加入过多带有标注的增强数据可能使数据趋于同一个分布,进而造成过拟合现象。对于带有标注的图像{xn,yn}
n=1...n
和没有标注的图像{xm}
m=1...m
,我们只采取了αn+m张图片参与对比学习训练,α为比例因子。
[0105]
本技术提出了一种监督学习和对比学习的联合学习策略。监督模块为对比模块的分割区域提供监督信息指导,对比模块可以通过相似度分析为监督模块挖掘更多潜在特征。
[0106]
相比传统的对比学习,对比学习模块充当了训练pre-text task的角色。一般pre-text task中学习的模型是用给随后的downstream task。但是我们设计的simbis框架,pre-texttask和downstream task是同时进行的。这样的设计动机是我们将对比自监督学习用在分割任务上。如果单单只训练pre-text task接着再用给downstream task,即使自监督学习的过程使用大量的正样本和负样本进行对比学习,模型也很难去找到感兴趣的分割感兴趣部位是什么和在图片的哪个位置。simbis框架结合了监督模块(downstream task),可以指导pre-text task在对比自监督学习上准确地学习待分割目标的特征。
[0107]
在监督模块,这里处理的任务是目标任务。对应地,它也是在对比学习中的downstream tasks。一般来说,采用自我监督学习的计算机视觉管道包括执行两个任务:pre-text task和downstream tasks。downstream tasks是应用程序特定的任务,利用在pre-text task中所学的知识。而我们的simbis框架是与对比模块同时进行的。它会隐式地给对比学习提供目标和分割位置。
[0108]
在对比模块中设计了新的对比损失函数和特征投影映射。在监督模块的指导下,对比损失函数仅使用正例计算相似度损失。对比损失函数用一个低维向量矩不变量来测的网络输出之间的相似性。
[0109]
为了能充分地挖掘数据的潜能进而继续提高模型的分割性能,我们想利用对比模块来达到这个目的。因为对比模块可以利用自我监督对比学习的机制,使模型学到更多有用的底层特征。
[0110]
数据对:我们使用了部分带有标注的数据和额外没有标注的相同域和相似域的数据通过上述的数据增强模块获得增强图像。其中,原始图像作为锚点,其增强(变换)后的图像作为正样本。{xi,xj}为一对经过数据增强t变换后的数据对。
[0111]
分割网络输出:我们将这些数据对喂进分割网络f(
·
),网络的输出即为数据对的各自预测。这也是simbis框架要同时结合监督模块(downstreamtask)的原因,可以得到靠近分割目标的预测。对于一张增强图片xi,它的分割预测可以表示为:
[0112][0113]
矩不变量映射:跟传统的对比学习类似,其使用一个浅层mlp将网络输出映射到一个低维的空间。由于网络的输出是各个数据对的预测,我们给出的方案是利用矩不变量,将这些每一个预测转化为矩不变量来表示。矩不变量可以将图片映射成一个低维的向量,并
且矩不变量被证明是对于缩放、平移和缩放具有不变性。我们可以最大化数据对的相似度(或者它们最小化误差),再经过反向传播,以此来迫使网络去学习这些数据对的底层特征表示。矩不变量的选择可以是胡矩不变(humoment invariants)、几何矩不变量(geometric moment invariants)、复矩不变(complex moment invariants)、勒让德矩不变量(legendre moment invariants)和泽尼克矩不变量(zernike moment invariants),可以默认选择胡矩不变(hu moment invariants)。我们定义矩不变量映射为p
moment
(
·
),一张增强图片xi的特征表示可以表示为:
[0114][0115]
对比损失函数:在对比损失函数l
con
的构造中,我们给出了两种方案:(1)余弦相似度对比损失函数(2)误差对比损失函数其中,
[0116]
余弦相似度对比损失函数:在对比设置中,最常用的相似度度量是余弦相似度,它作为不同对比损失函数的基础。对于给定的两个矩不变量映射zi,zj,它们的余弦相似度可以表示为:
[0117][0118]
其中,zi,zj表示两个矩不变量映射,sim(
·
)函数表示相似度计算,z
it
zj表示两个对应向量相乘,||zi||||zj||表示两个对应两个向量的模。
[0119]
由于simbis框架结合了监督模块(downstream task)和对预测映射的学习。simbis有了一种导向作用对感兴趣的分割部位进行学习。此外,引入大量的负例会要求训练模型需要大的批尺寸和产生大量的计算。因此我们的对比损失计算也只使用正例计算对比损失,使用较小的批尺寸便可以对模型进行训练。
[0120]
余弦相似度对比损失函数可表示为:
[0121][0122]
误差对比损失函数:在专利中,我们还给出了另外一种方案。我们给出的解释,可能在计算损失梯度的时候,数值的误差比向量的相似度更有利于反向传播。我们将误差对比损失函数定义为:
[0123][0124]
余弦相似度对比损失函数偏向两个矩不变量映射向量的方向,而欧拉误差对比损失函数偏向于两个矩不变量映射向量数值的变化。
[0125]
simbis框架结合了监督模块和对比模块,因此总损失函数l
total
是监督损失函数l
sup
和对比损失l
con
的加权和。最终,我们的损失函数可以表示为:
[0126]
l
total
=-w
sup
l
sup-w
con
l
con
[0127]
这里w
sup
和w
con
分别为l
sup
和l
con
的权重。
[0128]
simbis设计了多种数据增强功能。数据增强模块采用线性变换增强和非线性变换增强相结合的方法来提高增强图像的可分辨性,不仅提高图像的丰富性和多样性,数据增
强模块还能与对比模块形成一种对抗机制。具体是,数据增强模块尽可能使图片的区分度更大,而对比模块通过自监督使图像的特征映射的相似度的误差更小(或者相似度更大),进而优化网络和得到更具泛化和稳定的分割模型。本专利采用数据增强模块,既能实现适当的数据增强,在一定程度上可以缓解小规模医学图像分割数据稀缺的问题;又能有效地避免因过度有标注的数据增强使训练数据趋向于同个分布,进而导致的过拟合现象。
[0129]
本技术设计一种监督学习和对比学习的联合学习策略。与现有模型相比,更充分地挖掘图像的潜在特征,获得更准确的分割。与传统的对比学习不同,simbis将监督学习和对比学习同时结合起来,通过监督模块提供监督信息指导,并通过对比模块充分挖掘数据中潜在的相似性分析和学习特征,以保持监督学习分割的准确性,并学习数据的潜在有效特征。
[0130]
在对比模块中设计了新的对比损失函数和特征投影映射。在监督模块的指导下,对比损失函数仅使用正例计算相似度损失。这样可以避免对比学习中需要大量正负例来计算相似度的问题,极大地减少了计算量和提升了计算效率。损失函数用一个低维向量矩不变量来测的网络输出之间的相似性,一方面,将数据转化为低维向量可以大幅度减少训练的计算量,另一方面矩不变量可以直接衡量目标的相似性,本专利利用矩不变量的特性,将其作为一种特征表示,并应用在衡量从网络推导出的预测的差异,它们应该是完全相同或者是几乎一致的,这也减少了人工地增加标注的时间和支出。通过最大化预测间的相似性(或最小化预测的差异),可以从另外一个角度来优化分割边界和预测的全局分布。
[0131]
在总的损失函数中,由于simbis框架结合了监督学习和对比学习,因此总损失函数是监督损失函数和对比损失的加权和。它可以权衡监督学习和对比学习两者的效益,并用于反向传播来优化分割模型。
[0132]
以上所述的实施例仅是对本技术优选方式进行的描述,并非对本技术的范围进行限定,在不脱离本技术设计精神的前提下,本领域普通技术人员对本技术的技术方案做出的各种变形和改进,均应落入本技术权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1