一种足式机器人动态目标跟踪方法
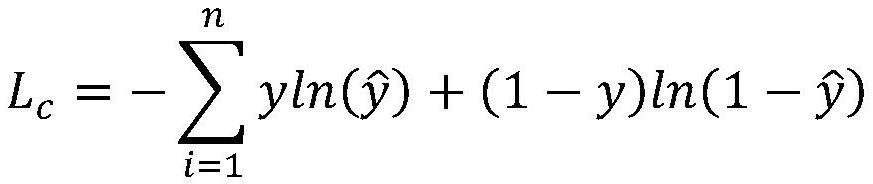
本发明涉及目标检测领域,具体为一种足式机器人动态目标跟踪方法。
背景技术:
1、在新冠病毒肺炎肆虐之下,国内疫情防控总体形势依然严峻,校园、医院、公园等环境人员密集、接触面广、流动性大,其疫情防控和安全保障任务十分艰巨。在人群密集场所采用足式机器人进行安全巡检,对重要目标进行准确识别和跟踪,将对当前的疫情防控具有重要的应用价值和现实意义。
2、基于视觉的动态目标跟踪是计算机视觉中较为基础的研究问题,正在被广泛地应用于智慧监控、工业检测和人机交互等诸多领域,具有重要的研究和应用价值,但其仍面临复杂场景下的诸多挑战,如视觉传感器震动导致获取的图像模糊不清、目标相互遮挡、环境光照变化明显、背景干扰等。
3、近年来,深度学习算法的深入研究进一步推动了环境感知性能的提升,在目标分类等任务上甚至达到或超过了人类识别的精度,因此,许多基于深度学习的目标跟踪方法被提出。相比于传统方法,基于深度学习的动态目标跟踪方法因其更强的准确性和鲁棒性受到了广大研究者的关注。
4、目标尺度和纵横比变化大在动态目标跟踪过程中非常容易发生,传统方法首先从输入视频图像帧中对动态目标进行识别,生成目标所在位置的边界框,判断目标种类并与视频下一帧进行比较,根据两帧图像之间的相关系数实现对动态目标的跟踪。但动态目标跟踪过程中目标尺度和纵横比会随着目标或视觉传感器的运动而变化,导致生成的包含目标的边界框超参数不够准确,因此无法有效匹配前后两帧图像中同一目标,很难判断下一帧图像中目标所在的具体位置,当目标运动或视觉传感器震动导致图像模糊不清时跟踪效果不佳。
5、近年来,一系列基于深度学习的动态目标跟踪方法已被提出,例如bertinetto等人在european conference on computer vision提出使用孪生网络(siamese network)进行动态目标识别,该网络包含识别分支和回归分支,分别用于获取下一帧图像中的目标语义特征和计算当前帧与下一帧中目标语义特征的相关系数,并根据所获得的相关系数对前后两帧图像帧中同一目标进行匹配。实验证明,该方法可得到更出色的动态目标跟踪性能,足以证明深度学习算法在动态目标跟踪上的确具有优异表现。然而这类方法不能很好地分析输入视频多帧图像中的动态目标语义特征信息,难以准确跟踪动态目标。经过相关技术检索发现,目前尚无满足当目标运动或视觉传感器震动导致图像模糊不清时基于深度学习的足式机器人动态目标跟踪方法。
技术实现思路
1、为了解决足式机器人动态目标跟踪方法无法解决受运动模糊影响下的动态目标跟踪准确率低的问题,本发明提出了足式机器人动态目标跟踪新方法,该方法通过融合输入视频多帧图像中的动态目标语义特征信息,能够在输入视频受运动模糊影响较大的情况下,对动态目标进行识别与跟踪,提高了足式机器人动态目标识别与跟踪的准确率。
2、本发明提供一种足式机器人动态目标跟踪方法,该方法包括训练和测试两个阶段,其中,
3、训练阶段由基于递归神经网络的目标识别模块,基于残差网络的目标语义特征提取模块以及基于孪生网络的目标跟踪模块实现。
4、基于残差网络的目标语义特征提取模块采用resnet-50模型作为基准网络,并删除了最后两层的下采样操作,其中第4组和第5组卷积块的步长设置为1。为了减少计算负担,在最后增加了1×1卷积块,将输出特征的通道数减小至256,并且仅使用模板分支中心7×7区域的特征,该特征仍可以捕获整个目标区域。该模块包含模板分支和搜索分支,分别用于提取当前图像帧中的目标语义特征和预测下一图像帧中的目标语义特征。
5、基于孪生网络的目标跟踪模块包含识别分支和回归分支,分别用于获取下一图像帧中的目标语义特征映射和计算当前图像帧与下一图像帧中目标语义特征映射间的相关系数,每个分支使用深度互相关层来组合特征图。
6、测试阶段:训练完成后,采用足式机器人搭载的基于递归神经网络的目标识别模块,判断行人是否佩戴口罩,利用基于孪生网络的目标跟踪模块对未佩戴口罩的行人进行跟踪。该方法包含以下步骤:
7、步骤1:训练数据集准备。
8、步骤2:将训练数据集中的视频输入递归神经网络,通过递归神经网络获取标记有行人是否佩戴口罩的信息及其面部边界框信息的相邻帧序列(ft-1,ft),t=2,…t-1,其中,ft表示标记有行人是否佩戴口罩信息及其面部边界框信息的第t帧图像,其中行人是否佩戴口罩的信息用于判断行人已正确佩戴口罩、未正确佩戴口罩或未佩戴口罩,边界框信息用于获取行人面部位置的坐标。
9、步骤3:将递归神经网络获取的相邻帧序列(ft-1,ft)输入基于残差网络的目标语义特征提取模块,获取第t帧和第t+1帧序列上行人面部语义特征信息,从模板分支提取的第t帧图像中的行人面部语义特征信息可表示为从搜索分支预测的第t+1帧图像中的行人面部语义特征信息可表示为模板分支的输出特征大小为127×127,搜索分支的输出特征大小为255×255。
10、步骤4:计算损失函数,其中,整体损失函数表达式更新如下:
11、
12、其中,λ1和λ2为超参数,分别定义了整体损失函数中各个分支的权重,λ1=1,λ2=1。
13、lc表示第t帧行人是否佩戴口罩的识别损失,采用基于交叉熵的损失函数,其表达式如下:
14、
15、其中y表示根据递归神经网络获取的第t帧图像中行人是否佩戴口罩的置信度值,表示采用残差网络预测的第t+1帧图像中行人是否佩戴口罩的置信度值。
16、lr表示第t帧行人面部语义特征的回归损失,采用基于交并比的损失函数,其表达式如下:
17、lr=1-iou
18、其中,iou表示第t帧图像中行人的面部边界框预测值与第t+1帧图像中行人的面部边界框真实值的交并比。
19、将残差网络提取到的行人面部语义特征信息和输入基于孪生网络的目标跟踪模块,采用识别分支和回归分支分别提取第t帧及第t+1帧图像中行人面部位置的语义特征映射,分别表示为
20、为了对第t帧和第t+1帧图像中的同一行人面部进行匹配,需要计算两帧之间行人面部语义特征映射:
21、
22、
23、其中*表示卷积操作,pc表示识别映射,pr表示回归映射。
24、为了对第t帧和第t+1帧图像中的同一行人面部进行匹配,可根据识别映射pc和回归映射pr计算两帧之间同一行人面部位置间的预测系数ps,其表达式如下:
25、ps=(1-ω)pc+ωpr
26、其中ω表示超参数,此处ω=0.6。
27、为了预测第t+1帧图像中行人面部位置的边界框坐标,可根据识别映射pc和回归映射pr进行计算,假设和分别代表第t+1图像中行人面部位置的边界框左上角和右下角坐标,可根据下面的表达式分别求取和
28、
29、
30、
31、
32、其中和分别表示回归映射pr的预测值,(pi,pj)表示行人面部位置边界框内可用于判断行人未佩戴口罩的区域的坐标值,(pi,pj)可通过以下表达式进行计算:
33、
34、其中gw,gh,分别表示第t帧图像中行人面部位置边界框的宽、高和中心点位置坐标真实值。当获取第t+1帧图像中行人面部位置的边界框坐标和且预测系数ps最高时,可判定该位置与第t帧图像中选取的行人面部位置相关性最高,此时即实现两帧之间同一行人面部位置的匹配。以此类推,遍历训练视频完成。
35、训练完成后,将所提跟踪方法部署在足式机器人上,采用基于递归神经网络的目标识别模块,判断行人是否佩戴口罩。对于未佩戴口罩的行人,利用基于残差网络的目标语义特征提取模块提取当前图像帧中行人的面部语义特征,并预测下一图像帧中该行人的面部语义特征。通过基于孪生网络的目标跟踪模块计算当前帧及下一帧中行人面部位置语义特征映射间的相关系数并对其进行匹配,从而实现足式机器人对动态目标的跟踪。
- 还没有人留言评论。精彩留言会获得点赞!