一种基于对齐自纠正的鲁棒跨模态检索方法
1.本发明涉及多媒体信息处理领域,具体涉及一种基于对齐自纠正的鲁棒跨模态检索方法。
背景技术:
2.跨模态检索是给定一个模态的查询词去查询另外一个模态的语义匹配样本。随着互联网技术的蓬勃发展和智能设备的普及与国内外购物软件与通讯软件等移动端app的流行,多媒体数据在数量爆炸式增长,多媒体数据的激增带来了大量的跨模态检索的需求,目前使用文字去检索想购买的目标商品和检索图片与视频的需求已经相当普遍。经过研究发现,目前方法在训练数据带有噪声时,例如:图文不匹配,性能会大幅下降。
3.跨模态检索一般可通过两种方式实现。第一种是通过对比学习最小化负例之间相似度,最大化正例之间相似度,但当正例是不匹配的样本时,模型仍然会错误地最大化正例之间的相似度。第二种是通过图文匹配任务进行二分类,对匹配的样本分类为1,不匹配的样本分类为0,但错误的标签也会降低模型的训练效果。所以需要设计一种鲁棒的跨模态检索方法,其在噪声数据存在时,仍然可以保持较好的检索性能。
技术实现要素:
4.本发明的目的在于提出一种基于对齐自纠正的鲁棒跨模态检索方法,结合多任务训练提高模型鲁棒性,利用贝塔混合分布对样本损失进行建模并对标签进行修正,以应对在噪声数据存在情况下鲁棒的模型训练需求。
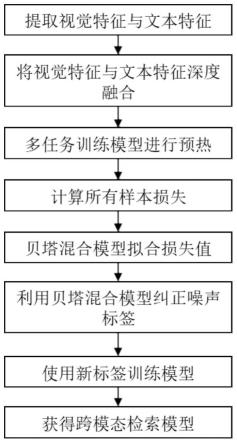
5.实现本发明目的的技术解决方案为:第一方面,本发明提供一种基于对齐自纠正的鲁棒跨模态检索方法,包括如下步骤:
6.步骤1、提取视觉特征与文本特征;
7.步骤2、将视觉特征与文本特征输入跨模态检索网络中做深度融合;
8.步骤3、使用多任务训练模型进行预热;
9.步骤4、使用预热后的模型计算所有样本对的损失;
10.步骤5、对损失数值拟合贝塔混合模型;继续训练跨模态检索模型,计算样本损失值属于均值较大的贝塔混合模型的后验概率并对对齐标签进行自纠正;
11.步骤6、利用贝塔混合模型对数据中对齐标签进行自纠正;
12.步骤7、使用新标签训练模型至收敛得到跨模态检索模型。
13.第二方面,本发明提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面所述的方法的步骤。
14.第三方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面所述的方法的步骤。
15.本发明与现有技术相比,其显著优点在于:(1)本发明利用多任务训练,有效缓解
了transformer模型对噪声过拟合速度过快问题,为进行标签纠正扩大了时间窗口;(2)本发明利用贝塔混合模型,对跨模态检索中数据进行自适应聚类与标签纠正,提高了模型在噪声数据监督下的检索性能。
16.下面结合附图对本发明做进一步详细的描述。
附图说明
17.图1为本发明基于对齐自纠正的鲁棒跨模态检索方法流程图。
18.图2为本发明基于对齐自纠正的鲁棒跨模态检索方法网络框架图。
19.图3为本发明在40%噪声的flickr30k数据集上拟合贝塔混合模型的可视化图。
20.图4为本发明在40%噪声的flickr30k数据集上的训练集可视化图。
具体实施方式
21.如图1、图2所示,一种基于对齐自纠正的鲁棒跨模态检索方法,提取视觉特征与文本特征;将视觉特征与文本特征输入跨模态检索网络t
θ
中做深度融合;使用多任务训练模型进行预热;使用预热后的模型t
θ
计算所有样本对的损失;对损失数值拟合贝塔混合模型b;利用贝塔混合模型对数据中对齐标签进行自纠正;使用新标签训练模型至收敛得到跨模态检索模型。本发明使用transformer模型作为基本模型进行模态间充分融合,结合多任务训练与图片噪声标签学习技术,提高了在噪声干扰下跨模态检索模型性能。下面对本发明步骤进行详细说明:
22.步骤1、提取视觉特征与文本特征:
23.对于视觉文本样本(ii,ti),利用faster r-cnn网络提取视觉模态特征向量v=[v1,
…
vm],bert网络模型提取文本特征向量t=[t1,
…
tn]。
[0024]
步骤2、使用多任务训练模型进行预热:
[0025]
将视觉特征与文本特征输入跨模态检索网络t
θ
中做深度融合具体过程为:将视觉特征与文本特征进行拼接[v1,
…
vm,t1,
…
tn],拼接后输入跨模态检索transformer网络t
θ
中做深度融合。
[0026]
步骤3、使用多任务训练模型进行预热:
[0027]
(1)将transformer网络t
θ
输出的全局[cls]特征二分类,计算交叉熵损失,进行图片文本匹配任务,具体形式为:
[0028][0029][0030]
其中,classifier(
·
)为两层神经网络,l
bce
为二分类损失,为全局[cls]特征的分类预测,yi为当前图片文本对的对齐标签,yi∈{0,1}。
[0031]
(2)将transformer网络t
θ
输出的《mask》的特征进行掩码预测,计算分类损失,进行单词掩码预测任务,具体形式为:
[0032]
l
mlm
=-e
(t,v)~d
log p
θ
(tm|t
\m
,v)
[0033]
其中,e(
·
)为取均值,(t,v)~d为对数据集d中数据采样得到的图片文本对特征(t,v),l
mlm
为掩码预测损失,p
θ
(tm|t
\m
,v)为观测到《mask》外的单词t
\m
与所有图片区域v后
对《mask》单词的预测。
[0034]
步骤4、使用预热后的模型t
θ
计算所有样本对的损失:
[0035]
在不更新模型的前提下,使用预热后的模型t
θ
计算所有样本对的图片文本匹配任务的二分类损失。
[0036]
步骤5、对损失数值拟合贝塔混合模型b:
[0037]
(1)首先建立含有两成分的贝塔混合模型(bmm):
[0038][0039]
其中p(l)为损失值l出现的概率,μk为第k个混合成分的混合系数,f(l∣αk,βk)为第k个贝塔混合分布的概率密度函数,即:
[0040][0041]
其中γ(
·
)为伽马函数,αk,βk为第k个贝塔分布的参数且αk,βk》0;
[0042]
(2)利用期望最大化算法(em)拟合损失值求出bmm模型参数:
[0043]
设潜在变量λk(l)=p(k∣l)表示损失值l属于第k个混合成分的后验概率。
[0044]
e步:固定参数μk,αk,βk,使用贝叶斯法则更新潜在变量:
[0045][0046]
m步:固定λk(l),估计分布参数αk,βk:
[0047][0048]
e步是期望步,m步是最大化步;
[0049]
其中表示每个样本的损失加权平均值,代表加权方差值:
[0050][0051][0052]
估计混合成分系数μk:
[0053][0054]
其中,n为样本数量。
[0055]
步骤6、利用贝塔混合模型对数据中对齐标签进行自纠正:
[0056]yiref
=h((1-λ
t
(li))yi+λ
t
(li)zi)
[0057]
其中,zi为模型的类别预测,h(
·
)为取概率值大的类为类别标签,为修正后的标签,λ
t
(li)损失值l属于噪声混合成分的后验概率,我们认为均值较大的混合成分为噪
声混合成分。
[0058]
步骤7、使用新标签训练模型至收敛得到跨模态检索模型:
[0059][0060]
其中,l
ref
为修正后的损失。
[0061]
表1方法在含有40%噪声的flickr30k数据集上的比较
[0062][0063][0064]
表1是本发明的方法,简写为rcar,与其他在线方法在含有40%噪声的flickr30k数据集上结果的比较。评测指标包括image2text表示使用图片检索文本,text2image表示使用文本检索图片,r@k表示在最接近查询的k个点中,正确检索项的查询的分数,符号
“↑”
表示值越高性能越好。可以发现,本发明在这6个指标上都取得最高的排名,充分证明了本发明可以有效地训练鲁棒的跨模态检索模型。
[0065]
图3是本发明在40%噪声的flickr30k数据集上拟合贝塔混合模型的可视化图,可以发现贝塔混合模型较好地拟合了干净与噪声两类样本的损失分布。图4展示了本发明在40%噪声的flickr30k数据集的训练集的特征分布图,可以发现噪声样本大都集中在与负例同类的区域,模型并没有对噪声样本过拟合。
[0066]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1