一种基于改进编辑距离的品牌名称提取方法及系统与流程
本发明涉及文本处理,特别指一种基于改进编辑距离的品牌名称提取方法及系统。
背景技术:
1、连锁店的品牌名称是非常有价值的数据,其应用十分广泛,比如运营商可用其进行集团用户管理。但目前,各商户命名连锁店的品牌名称多种多样,导致在统计各品牌名称对应的商户时较为复杂,且不易区分;因此,产生了从商户名称中提取品牌名称的需求。
2、由于poi数据中包含了大量的商户名称以及商户所属的类别信息,因此,现有技术是从poi数据中提取连锁店的品牌名称。针对品牌名称的提取,传统上需要通过人工对大量的poi数据进行标注以形成训练样本,再利用训练样本对品牌名称提取模型进行训练,但传统方法的标注过程十分繁琐,效率低下,需要耗费大量人力成本,且标注失误会直接影响品牌名称提取模型的提取精度。
3、因此,如何提供一种基于改进编辑距离的品牌名称提取方法及系统,实现提升品牌名称提取的效率以及精度,降低品牌名称提取的成本,成为一个亟待解决的技术问题。
技术实现思路
1、本发明要解决的技术问题,在于提供一种基于改进编辑距离的品牌名称提取方法及系统,实现提升品牌名称提取的效率以及精度,降低品牌名称提取的成本。
2、第一方面,本发明提供了一种基于改进编辑距离的品牌名称提取方法,包括如下步骤:
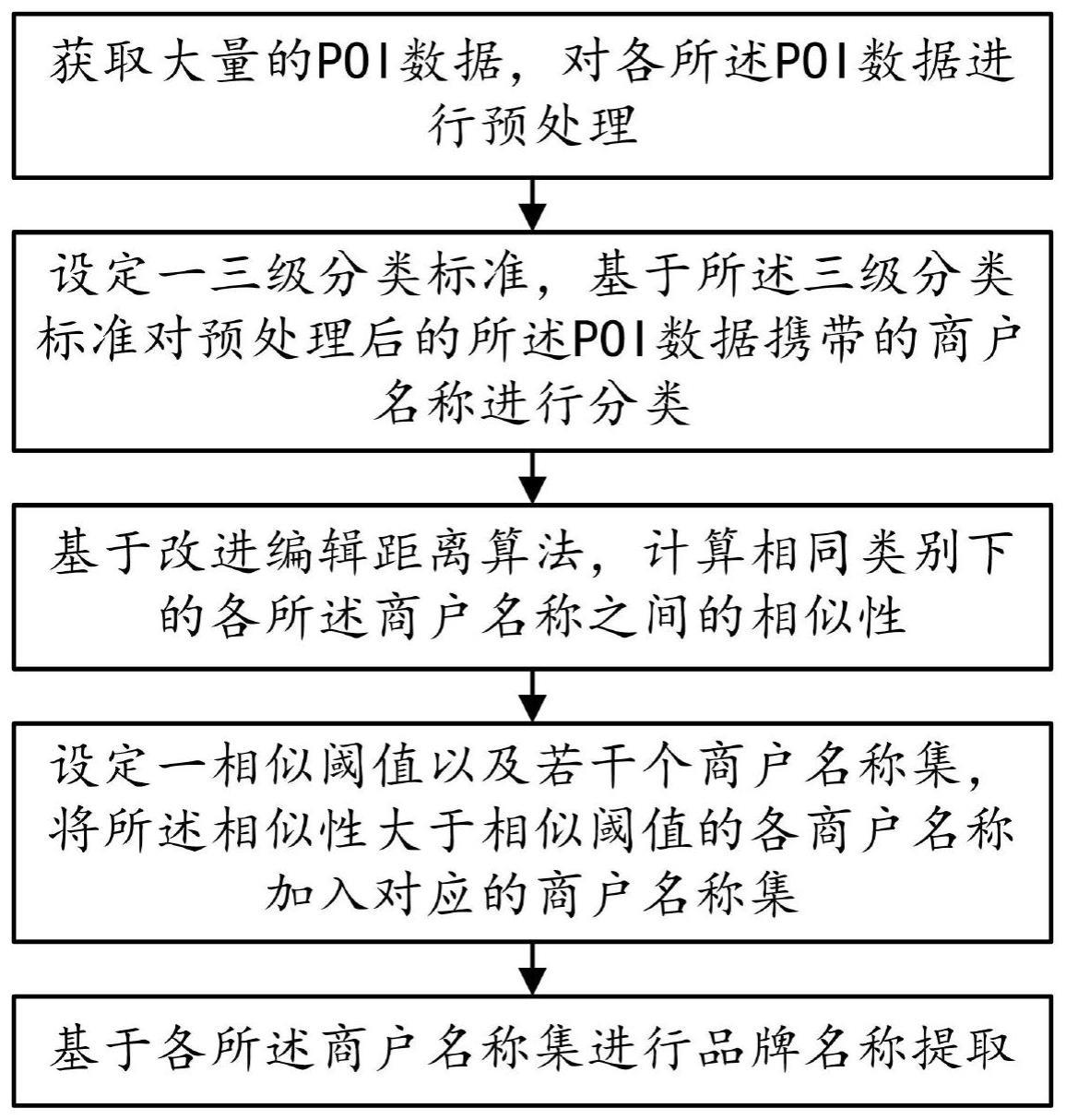
3、步骤s10、获取大量的poi数据,对各所述poi数据进行预处理;
4、步骤s20、设定一三级分类标准,基于所述三级分类标准对预处理后的所述poi数据携带的商户名称进行分类;
5、步骤s30、基于改进编辑距离算法,计算相同类别下的各所述商户名称之间的相似性;
6、步骤s40、设定一相似阈值以及若干个商户名称集,将所述相似性大于相似阈值的各商户名称加入对应的商户名称集;
7、步骤s50、基于各所述商户名称集进行品牌名称提取。
8、进一步地,所述步骤s10具体为:
9、获取同一商户的大量的poi数据,对各所述poi数据按预设规则进行无关数据剔除的预处理。
10、进一步地,所述步骤s30中,所述改进编辑距离算法具体为:
11、设字符串s={s1,s2,...,sm},字符串v={v1,v2,...,vn},利用贪心算法计算字符串s和字符串v的最长公共前缀tpre和最长公共后缀tsuf,将字符串s和字符串v的首尾均减去最长公共前缀tpre和最长公共后缀tsuf,得到字符串s′和字符串v′;
12、利用传统编辑距离算法计算字符串s′和字符串v′的编辑距离dis;
13、基于编辑距离dis、字符串s和字符串v计算相似性:
14、
15、进一步地,所述步骤s40中,所述相似阈值的取值为0.5。
16、进一步地,所述步骤s50具体包括:
17、步骤s51、判断所述商户名称集中的商户名称数量是否大于等于5,若是,则进入步骤s52;若否,则进行下一个所述商户名称集的判断;
18、步骤s52、判断所述商户名称集中的各商户名称是否一致,若是,则将商户名称作为备用品牌名称,并进入步骤s57;若否,则进入步骤s53;
19、步骤s53、判断所述商户名称集中的商户名称数量是否大于10,若是,则进入步骤s54;若否,则提示不存在品牌名称,并结束流程;
20、步骤s54、使用结巴分词对所述商户名称集中的商户名称进行分词,得到若干个词组,提取所述词组的词性,基于所述词性对各词组进行合并,得到合并词;
21、步骤s55、设定一词长阈值以及若干个停用词,筛选词长超过所述词长阈值,且不包含所述停用词的合并词,对筛选的各所述合并词进行词频统计,保留词频最高的前3个所述合并词;
22、步骤s56、判断各所述合并词对应的商户名称是否一致,若是,则将对应的商户名称作为备用品牌名称,并进入步骤s57;若否,则将词频最高的前10个所述合并词对应的商户名称作为备用品牌名称,并进入步骤s57;
23、步骤s57、对各所述备用品牌名称进行汇总,将词频大于5的所述备用品牌名称作为品牌名称。
24、第二方面,本发明提供了一种基于改进编辑距离的品牌名称提取系统,包括如下模块:
25、poi数据预处理模块,用于获取大量的poi数据,对各所述poi数据进行预处理;
26、商户名称分类模块,用于设定一三级分类标准,基于所述三级分类标准对预处理后的所述poi数据携带的商户名称进行分类;
27、相似性计算模块,用于基于改进编辑距离算法,计算相同类别下的各所述商户名称之间的相似性;
28、商户名称集创建模块,用于设定一相似阈值以及若干个商户名称集,将所述相似性大于相似阈值的各商户名称加入对应的商户名称集;
29、品牌名称提取模块,用于基于各所述商户名称集进行品牌名称提取。
30、进一步地,所述poi数据预处理模块具体用于:
31、获取同一商户的大量的poi数据,对各所述poi数据按预设规则进行无关数据剔除的预处理。
32、进一步地,所述相似性计算模块中,所述改进编辑距离算法具体为:
33、设字符串s={s1,s2,...,sm},字符串v={v1,v2,...,vn},利用贪心算法计算字符串s和字符串v的最长公共前缀tpre和最长公共后缀tsuf,将字符串s和字符串v的首尾均减去最长公共前缀tpre和最长公共后缀tsuf,得到字符串s′和字符串v′;
34、利用传统编辑距离算法计算字符串s′和字符串v′的编辑距离dis;
35、基于编辑距离dis、字符串s和字符串v计算相似性:
36、
37、进一步地,所述商户名称集创建模块中,所述相似阈值的取值为0.5。
38、进一步地,所述品牌名称提取模块具体包括:
39、第一商户名称数量校验单元,用于判断所述商户名称集中的商户名称数量是否大于等于5,若是,则进入第一商户名称一致性校验单元;若否,则进行下一个所述商户名称集的判断;
40、第一商户名称一致性校验单元,用于判断所述商户名称集中的各商户名称是否一致,若是,则将商户名称作为备用品牌名称,并进入汇总提取单元;若否,则进入第二商户名称数量校验单元;
41、第二商户名称数量校验单元,用于判断所述商户名称集中的商户名称数量是否大于10,若是,则进入分词单元;若否,则提示不存在品牌名称,并结束流程;
42、分词单元,用于使用结巴分词对所述商户名称集中的商户名称进行分词,得到若干个词组,提取所述词组的词性,基于所述词性对各词组进行合并,得到合并词;
43、词频统计单元,用于设定一词长阈值以及若干个停用词,筛选词长超过所述词长阈值,且不包含所述停用词的合并词,对筛选的各所述合并词进行词频统计,保留词频最高的前3个所述合并词;
44、第二商户名称一致性校验单元,用于判断各所述合并词对应的商户名称是否一致,若是,则将对应的商户名称作为备用品牌名称,并进入汇总提取单元;若否,则将词频最高的前10个所述合并词对应的商户名称作为备用品牌名称,并进入汇总提取单元;
45、汇总提取单元,用于对各所述备用品牌名称进行汇总,将词频大于5的所述备用品牌名称作为品牌名称。
46、本发明的优点在于:
47、通过对获取的poi数据进行预处理后,利用设定的三级分类标准对poi数据携带的商户名称进行分类,再基于改进编辑距离算法计算相同类别下的各商户名称之间的相似性,最后基于各商户名称集进行品牌名称提取,即基于poi数据进行无监督的品牌名称提取,无需人工对poi数据进行标注;通过对传统编辑距离算法进行改进,即利用贪心算法计算最长公共前缀和最长公共后缀,减去最长公共前缀和最长公共后缀后再进行相似性计算,有效提升计算效率;通过对商户名称集中的商户名称进行分词、词性规整等操作,有效提升品牌名称提取的准确性和覆盖率,最终极大的提升了品牌名称提取的效率以及精度,极大的降低了品牌名称提取的成本。
- 还没有人留言评论。精彩留言会获得点赞!