一种多视角零样本图像识别方法
1.本发明属于图像识别技术领域,具体涉及一种多视角零样本图像识别方法。
背景技术:
2.模式识别技术在近十几年取得了长足的进展。传统的模式识别方法需要使用大量的标记数据来进行训练以保证模型的泛化性能。然而在许多现实场景中,对细粒度样本进行标记往往需要专门的领域知识,因此,为所有类别收集大量的标记良好的样本仍然是一个挑战。为了解决这个问题,零样本分类得到越来越多的关注。
3.零样本分类试图通过从已见类(有现成样本的类别)的标记样本中获取迁移知识,从而构建能够识别未见类(没有现成样本的类别,即零样本类)样本的模型。零样本分类方法通过构建一个语义嵌入空间来建立已见类和未见类之间的内在联系,并在这个空间中嵌入已见类和未见类的语义标签(视为先验信息,可以是类别属性特征,也可根据类别的相关知识或文本描述采用词嵌入等方法获取)。这样,每个类别在语义空间中都与一个类语义标签向量相关联,进而可以通过建立样本特征与类别语义标签向量之间的映射关系来获取迁移知识,从而实现对未见类样本的判别。
4.公开号为cn115147607a的发明申请是在视觉-语义映射模型下,通过引入ramp型损失函数、cccp迭代框架以及admm更新方法,降低已见类图片样本的标记噪声样本带来的负面影响。
5.但迄今为止,大部分零样本分类的研究仅针对单视角数据。随着计算机技术的发展,在许多现实场景中,多视角数据(多源异构数据)己经变得非常普遍,譬如,医生通常需要综合病人的多视角生理数据做出诊断,包括结构化数据以及诸如文本、磁共振成像mri、ct等的非结构化数据。因此,如何通过提取和利用已见类别多视角数据中的信息来提升零样本分类的学习效果,是亟待解决的问题。
技术实现要素:
6.发明目的:本发明的目的在于克服现有方法的不足,提供一种多视角零样本图像识别方法。
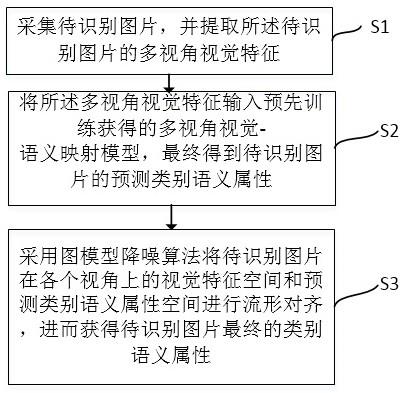
7.技术方案:本发明提供多视角零样本图像识别方法,包括以下步骤:s1采集待识别图片,并提取所述待识别图片的多视角视觉特征;s2将所述多视角视觉特征输入预先训练获得的多视角视觉-语义映射模型,最终得到待识别图片的预测类别语义属性;s3采用图模型降噪算法将待识别图片在各个视角上的视觉特征空间和预测类别语义属性空间进行流形对齐,进而获得待识别图片最终的类别语义属性。
8.进一步的,包括:所述步骤s2中,预先训练获得的多视角视觉-语义映射模型包括训练阶段,所述训练阶段包括以下步骤:
s21获取已见类训练集,已见类训练集包括图片样本的多视角视觉特征和图片样本的类别语义属性;s22构建多视角视觉-语义映射模型,将图片样本的多视角视觉特征作为多视角视觉-语义映射模型的输入,将图片样本的类别语义属性作为多视角视觉-语义映射模型的输出;并基于不同视角视觉特征之间的一致性和互补性原则,建立优化问题;s23使用交替方向乘子法对所述优化问题变量进行更新迭代,直至优化问题的变量在两次连续迭代中的变化量小于定值,进而确定多视角视觉-语义映射模型中的相关参量,从而获得最终的多视角视觉-语义映射模型。
9.进一步的,包括:所述步骤s2中,预先训练获得的多视角视觉-语义映射模型还包括测试阶段,所述测试阶段包括以下步骤:s24获取未见类测试集,将所述未见类测试集输入所述最终的多视角视觉-语义映射模型,获得未见类测试集在各个视角上的预测类别语义属性;s25利用图模型降噪算法,将未见类测试集在各个视角上的视觉特征空间与未见类测试集的预测类别语义属性空间进行流形对齐,更新未见类测试集在各个视角上的类别语义属性,并将它们的平均值作为未见类测试集最终的类别语义属性;s26基于未见类测试集最终的类别语义属性和未见类在各个视角上的类别语义属性,确定未见类测试集中每个图片样本最终的预测类别;s27根据未见类测试集中图片样本的真实类别,统计未见类测试集中图片样本最终的预测类别的正确数量,并计算未见类测试集的类别预测准确率;s28若未见类测试集的类别预测准确率大于设定的未见类阈值,则判定最终的视觉-语义映射模型合格,否则,返回到训练阶段。
10.进一步的,包括:步骤s22中,构建多视角视觉-语义映射模型,实现方法为:多视角视觉-语义映射模型的表达式为:其中,分别为图片样本在两个不同视角上的视觉特征,分别为两个视角的视觉特征的维度,和为图片样本的类别语义属性,和分别为两个视角的视觉特征空间到各自的潜在子空间的投影矩阵,和分别为两个视角的各自的潜在子空间到类别语义属性空间的投影矩阵,t为转置。
11.进一步的,包括:步骤s22中,基于不同视角视觉特征之间的一致性和互补性原则,建立优化问题,实现步骤包括:s221建立基于类别语义属性空间的相似度模型的损失函数,若图片样本在各个视角上的视觉特征在类别语义属性空间的投影与图片样本对应的类别语义属性的相似度大于设定的阈值,则损失值为零;s222优化问题表示为:
其中,tr(*)为矩阵的迹运算;为矩阵的f-范数;分别为已见类训练集中所有图片样本在两个不同视角上的视觉特征矩阵,n为样本数量,为已见类训练集中的所有图片样本对应的类别语义属性的矩阵,的每一列均为所有已见类的类别语义属性的平均值,的列数为已见类训练集中的图片样本数量;p1和p2分别为两个视角的潜在子空间到各自视觉特征空间的逆投影矩阵;i为单位矩阵;为损失函数中设定的阈值;和分别为两个视角上的松弛变量;β1,β2,c和为权系数。
12.进一步的,包括:建立所述优化问题,具体原则包括:a)最小化图片样本的损失值;b)最小化图片样本在不同视角上的视觉特征在类别语义属性空间的投影的差异,从而满足不同视角之间的一致性原则;c)根据多视角视觉-语义映射模型在图片样本每个单视角上的拟合表现调节其他视角上的损失值,从而满足不同视角之间的互补性原则;d)在多视角视觉-语义映射模型中为每一个视角添加一个潜在子空间。
13.进一步的,包括:所述步骤s23具体包括以下步骤:s231通过引入松弛变量,将公式(1)中的不等式约束改写成等价的等式约束:
ꢀ
s232公式(2)的增广拉格朗日函数为:s232公式(2)的增广拉格朗日函数为:其中,为罚参数;是拉格朗日乘子; s233更新矩阵b1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:
采用拉格朗日乘子法求解公式(4),获得关于矩阵b1的西尔维斯特方程:s234更新矩阵b2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:采用拉格朗日乘子法求解公式(6),获得关于矩阵b2的西尔维斯特方程:s235更新矩阵q1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(8),获得关于矩阵q1的西尔维斯特方程:s236更新矩阵q2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(10),获得关于矩阵q2的西尔维斯特方程:s237更新矩阵p1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:令,通过奇异值分解计算h1x
1t
q1=u1s
1v1t
,u1、s1和v1分别为奇异值分解的矩阵,得到p1=u
1v1t
;s238更新矩阵p2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:
令,通过奇异值分解计算h2x
2t
q2=u2s
2v2t
,u2、s2和v2分别为奇异值分解的矩阵,得到p2=u
2v2t
;s239更新矩阵w1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(14),获得矩阵w1的表达式:s2310更新矩阵w2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(16),获得矩阵w2的表达式:s2311更新,同时固定其余变量和拉格朗日乘子,求解如下优化问题:最小化公式(18),并考虑到的非负性,获得的更新格式:s2312更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(20),并考虑到的非负性,获得的更新格式: s2313更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(22),并考虑到的非负性,获得的更新格式:s2314更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:
最小化公式(24),并考虑到的非负性,获得的更新格式:s2315更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(26),并考虑到的非负性,获得的更新格式:s2316更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(28),并考虑到的非负性,获得的更新格式:s2317固定所有变量,更新各个拉格朗日乘子如下:的数值增加,的数值增加,的数值增加,的数值增加,的数值增加,的数值增加 ,的数值增加,的数值增加;罚参数更新为,ρ和μ
max
为设定的参数;s2318若各个变量在两次连续迭代中的变化量均分别小于定值,则结束运行,确定多视角视觉-语义映射模型中的w1,w2和q1,q2,获得最终的多视角视觉-语义映射模型,进入步骤s233。
14.另一方面,本发明提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述所述的方法。
15.最后,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述的方法。
16.有益效果:本发明提出一种多视角零样本图像识别方法,针对零样本识别中的多视角数据融合问题提出一种有效的解决途径,通过兼顾不同视角之间的一致性原则和互补性原则,并给出与之相匹配的交替方向乘子法,有效提升零样本识别的精度。
附图说明
17.图1为本发明所述的多视角零样本图像识别方法流程图。
具体实施方案
18.下面结合附图和具体实施方式对本发明作进一步的说明。
19.本发明提供一种多视角零样本图像识别方法,包括:获取待识别图片;提取待识别图片的多视角视觉特征;多视角类似多模态,比如同一个事物可以用文本和图像来描述,再比如,不同角度(正面,侧面)的图像也是不同视角。将待识别图片的多视角视觉特征输入预先训练获得的多视角视觉-语义映射模型,输出待识别图片的预测类别语义属性;利用图模型降噪算法,将待识别图片在各个视角上的视觉特征空间和预测类别语义属性空间进行流形对齐,获得待识别图片最终的类别语义属性。
20.进一步地,本实施例中预先训练获得多视角视觉-语义映射模型,如图1所示,通过以下步骤实现:步骤(1),获取已见类训练集,已见类训练集包括图片样本的多视角视觉特征和图片样本的类别语义属性;步骤(2),构建多视角视觉-语义映射模型,将图片样本的多视角视觉特征作为多视角视觉-语义映射模型的输入,将图片样本的类别语义属性作为多视角视觉-语义映射模型的输出;基于不同视角视觉特征之间的一致性和互补性原则,建立优化问题;步骤(3),使用交替方向乘子法对优化问题变量进行更新迭代,直至优化问题的变量在两次连续迭代中的变化量小于定值,确定多视角视觉-语义映射模型中的相关参量,从而获得最终的多视角视觉-语义映射模型。
21.进一步地,本实施例中步骤(4),获取未见类测试集;将未见类测试集输入最终的多视角视觉-语义映射模型,获得未见类测试集在各个视角上的预测类别语义属性;利用图模型降噪算法,将未见类测试集在各个视角上的视觉特征空间与未见类测试集的预测类别语义属性空间进行流形对齐,更新未见类测试集在各个视角上的类别语义属性,并将它们的平均值作为未见类测试集最终的类别语义属性;基于未见类测试集最终的类别语义属性和各个未见类的类别语义属性,确定未见类测试集中每个图片样本最终的预测类别;根据未见类测试集中图片样本的真实类别,统计未见类测试集中图片样本最终的预测类别的正确数量,并计算未见类测试集的类别预测准确率;若未见类测试集的类别预测准确率大于设定的未见类阈值,则判定最终的视觉-语义映射模型合格。
22.进一步地,本实施例中步骤(2),构建多视角视觉-语义映射模型,通过以下步骤实现:多视角视觉-语义映射模型的表达式为:其中分别为图片样本在两个不同视角上的视觉特征,分别为两
个视角的视觉特征的维度,为图片样本的类别语义属性,分别为两个视角的视觉特征空间到各自的潜在子空间的投影矩阵,分别为两个视角的各自的潜在子空间到类别语义属性空间的投影矩阵,t为转置;步骤(2),基于不同视角之间的一致性和互补性原则,建立优化问题,通过以下步骤实现:建立基于类别语义属性空间的相似度模型的损失函数,若图片样本在各个视角上的视觉特征在类别语义属性空间的投影与图片样本对应的类别语义属性的相似度大于设定的阈值,则损失值为零。建立优化问题,具体细节如下:a)最小化图片样本的损失值;b)最小化图片样本在不同视角上的视觉特征在类别语义属性空间的投影的差异,从而满足不同视角之间的一致性原则;c)根据多视角视觉-语义映射模型在图片样本单个视角上的拟合表现调节其他视角上的损失值,从而满足不同视角之间的互补性原则;d)在多视角视觉-语义映射模型中为每一个视角添加一个潜在子空间。
23.优化问题:优化问题:其中,tr(*)为矩阵的迹运算;为矩阵的f-范数;分别为已见类训练集中所有图片样本在两个不同视角上的视觉特征矩阵,n为样本数量,为已见类训练集中的所有图片样本对应的类别语义属性的矩阵,的每一列均为所有已见类的类别语义属性的平均值,的列数为已见类训练集中的图片样本数量;p1和p2分别为两个视角的潜在子空间到各自视觉特征空间的逆投影矩阵;i为单位矩阵;为损失函数中设定的阈值; 分别为两个视角上的松弛变量;和为权系数。
24.进一步地,本实施例中步骤(3),使用交替方向乘子法对优化问题的变量进行更新迭代,直至优化问题的变量在两次连续迭代中的变化量小于定值,确定多视角视觉-语义映射模型中的相关参量,从而获得最终的多视角视觉-语义映射模型,通过以下步骤实现:
步骤(3-1),通过引入松弛变量,将公式(1)中的不等式约束改写成等价的等式约束:等价的等式约束:步骤(3-2),公式(2)的增广拉格朗日函数为:
其中,为罚参数;是拉格朗日乘子。
25.步骤(3-3),更新矩阵b1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:采用拉格朗日乘子法求解公式(4),获得关于矩阵b1的西尔维斯特方程:步骤(3-4),更新矩阵b2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:采用拉格朗日乘子法求解公式(6),获得关于矩阵b2的西尔维斯特方程:步骤(3-5),更新矩阵q1,同时固定其余变量和拉格朗日乘子,求解如下子优化问
题:最小化公式(8),获得关于矩阵q1的西尔维斯特方程:步骤(3-6),更新矩阵q2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(10),获得关于矩阵q2的西尔维斯特方程:步骤(3-7),更新矩阵p1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:令通过奇异值分解计算h1x
1t
q1=u1s
1v1t
,u1、s1和v1分别为奇异值分解的矩阵,得到p1=u
1v1t
。
26.步骤(3-8),更新矩阵p2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:令,通过奇异值分解计算h2x
2t
q2=u2s
2v2t
,u2、s2和v2分别为奇异值分解的矩阵,得到p2=u
2v2t
。
27.步骤(3-9),更新矩阵w1,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(14),获得矩阵w1的表达式:步骤(3-10),更新矩阵w2,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(16),获得矩阵w2的表达式:
步骤(3-11),更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(18),并考虑到的非负性,获得的更新格式:步骤(3-12),更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(20),并考虑到的非负性,获得的更新格式:步骤(3-13),更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(22),并考虑到的非负性,获得的更新格式:步骤(3-14),更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(24),并考虑到的非负性,获得的更新格式: 步骤(3-15),更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:最小化公式(26),并考虑到的非负性,获得的更新格式:步骤(3-16),更新,同时固定其余变量和拉格朗日乘子,求解如下子优化问题:
最小化公式(28),并考虑到的非负性,获得的更新格式:步骤(3-17),固定所有变量,更新各个拉格朗日乘子如下:的数值增加,的数值增加,的数值增加,的数值增加,的数值增加,的数值增加 ,的数值增加,的数值增加;罚参数更新为,ρ和μ
max
为设定的参数。
28.步骤(3-18),若各个变量在两次连续迭代中的变化量均分别小于定值,则结束运行,确定多视角视觉-语义映射模型中的w1,w2和q1,q2,获得最终的多视角视觉-语义映射模型,进入步骤(3-3)。
29.另一方面,本发明提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述所述方法的步骤。
30.最后,本发明提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述所述方法的步骤。
31.实验数据及结果分析本实施例采用的awa数据集包含50个类别,共30485张图片样本,其中每个类别至少92张图片样本,每个类别都对应一个85维的类别语义属性向量。本发明将50个类别中的40个作为已见类,10个作为未见类。在已见类的图片样本中随机取15161个图片样本组成已见类训练集,在未见类的图片样本中随机取6985个图片样本组成未见类测试集。
32.本实施例采用的cub数据集包含200个类别,共11788张图片样本,其中每个类别至少45张图片样本,每个类别都对应一个312维的类别语义属性向量。本发明将200个类别中的150个作为已见类,50个作为未见类。在已见类的图片样本中随机取6596个图片样本组成已见类训练集,在未见类的图片样本中随机取2973个图片样本组成未见类测试集。
33.本发明获取已见类训练集和未见类测试集中图片样本的多视角视觉特征,通过以下步骤实现:在awa和cub数据集上进行测试,采用pytorch模块中googlenet预训练网络模型提取图片样本的视觉特征,并将第18层作为输出层,提取后视觉特征的维度为1024。
34.awa的1视角与2视角分别为图片样本中比例0.1*0.1大小的随机位置局部区域和完整的图片样本。
35.cub的1视角与2视角分别为图片样本中比例0.7*0.7大小的随机位置局部区域和完整的图片样本。
36.将本方法与zero-shot learning via robust latent representation and manifold regularization中的算法进行对比测试,得到结果如下表。
37.实验结果可以看出,本发明所提出的多视角零样本图像识别方法显著提高了未见类测试集的识别精度。从表1中可以发现,相比单视角方法,本方法的精度提升在awa数据集上达15.34%,在cub数据集上达15.57%。
38.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1