用于驾驶辅助的目标检测方法及装置、计算机设备和介质与流程
本发明涉及智能驾驶,特别是涉及一种用于驾驶辅助的目标检测方法及装置、计算机设备和介质。
背景技术:
1、在智能驾驶领域,车路协同的概念受到广泛关注。目标检测是车路协同的基础,各种道路事件以及车流估计都非常依赖目标检测的结果。通常地,使用多个摄像机对驾驶场景进行拍摄,并对所拍摄的视频进行目标检测以实现车路协同,车路协同中的目标检测模型需要检测出一定范围(例如0至400米)内的车辆在驾驶中需要关注的目标位置和状态。
2、在车路协同要求告知车辆一定距离内的目标的位置和状态,因此,车路协同中的目标检测对于远端和近端的目标都非常关注。由于在摄像机视野中位于远端的目标尺度较小且分布密集,因此对目标检测模型的检测精度要求较高。
技术实现思路
1、本申请提供一种用于驾驶辅助的目标检测方法及装置、计算机设备及介质。
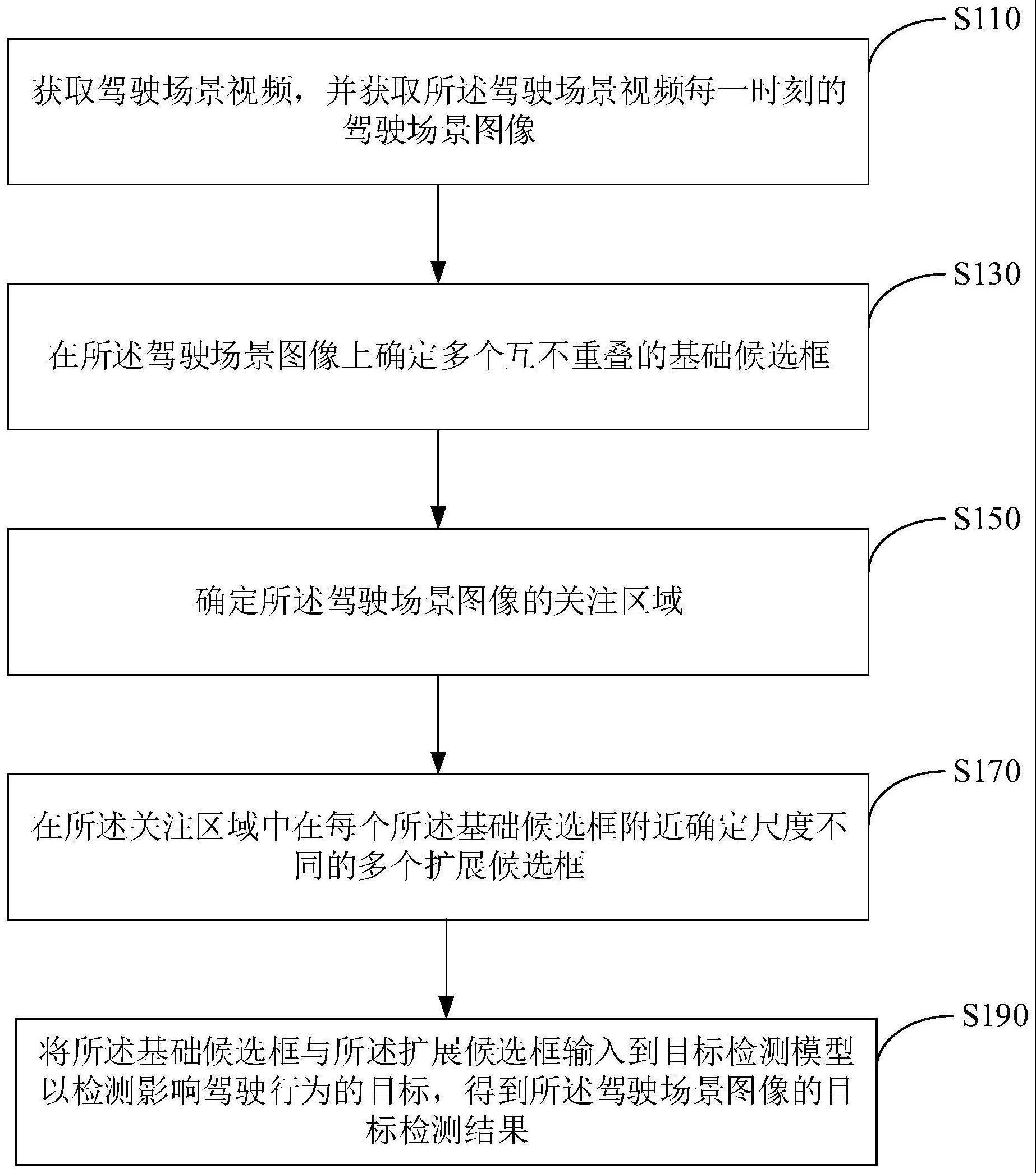
2、本申请的第一方面涉及一种用于驾驶辅助的目标检测方法,包括:获取驾驶场景视频,并获取所述驾驶场景视频每一时刻的驾驶场景图像;在所述驾驶场景图像上确定多个互不重叠的基础候选框;确定所述驾驶场景图像的关注区域;在所述关注区域中在每个所述基础候选框附近确定尺度不同的多个扩展候选框;以及将所述基础候选框与所述扩展候选框输入到目标检测模型以检测影响驾驶行为的目标,得到所述驾驶场景图像的目标检测结果。
3、在一实施例中,根据本申请的用于驾驶辅助的目标检测方法还包括:基于当前时刻的驾驶场景图像的目标检测结果,预测下一时刻的关注区域,并利用所预测的下一时刻的关注区域更新所述关注区域。
4、在一实施例中,确定所述驾驶场景图像的关注区域包括:获取预先指定的区域作为所述关注区域。
5、在一实施例中,确定所述驾驶场景图像的关注区域包括:确定所述驾驶场景图像中的小目标密集区作为所述关注区域,其中,所述小目标密集区是在所述驾驶场景图像中所述目标的尺度小于预定尺度阈值或密度大于预定密度阈值的区域。
6、在一实施例中,确定所述驾驶场景图像中的小目标密集区作为所述关注区域包括:将所述驾驶场景视频的初始时刻的所述驾驶场景图像的基础候选框输入到所述目标检测模型中以检测所述目标,得到初始时刻的目标检测结果;以及基于初始时刻的目标检测结果确定所述小目标密集区,作为所述关注区域。
7、在一实施例中,在所述驾驶场景图像上确定多个互不重叠的基础候选框包括:确定正方形的基础候选框,所述基础候选框的边长为s,且s为所述目标检测模型的下采样倍数的2x倍,其中x为整数;在所述关注区域中在每个所述基础候选框附近确定尺度不同的多个扩展候选框包括:在每个所述基础候选框附近确定多个第一扩展候选框,其中,所述第一扩展候选框包括多个边长为s的正整数倍的矩形,且所述多个第一扩展候选框的中心与所述基础候选框的中心重合,以及通过在所述驾驶场景图像上将所述多个第一扩展候选框与所述基础候选框一起向多个方向平移,确定多个第二扩展候选框。
8、在一实施例中,在将所述基础候选框与所述扩展候选框输入到目标检测模型以检测影响驾驶行为的目标之前,根据本申请的用于驾驶辅助的还包括:获取样本图像;在所述样本图像上确定互不重叠的多个基础候选框,并在每个所述基础候选框附近确定尺度不同的多个扩展候选框;随机保留所述基础候选框和所述扩展候选框中的一部分候选框,得到多个保留候选框;以及将所述保留候选框输入到所述目标检测模型进行训练。
9、在一实施例中,在所述样本图像上确定多个互不重叠的基础候选框,并在每个所述基础候选框附近确定尺度不同的多个扩展候选框,包括:确定正方形的基础候选框,所述基础候选框的边长为s,且s为所述目标检测模型的下采样倍数的2x倍,其中x为整数;在每个所述基础候选框附近确定多个第一扩展候选框,其中,所述第一扩展候选框包括多个边长为s的正整数倍的矩形,且所述多个第一扩展候选框的中心与所述基础候选框的中心重叠,以及通过在所述样本图像上将所述多个第一扩展候选框与所述基础候选框一起向多个方向平移,确定多个第二扩展候选框。
10、在一实施例中,随机保留所述基础候选框和所述扩展候选框中的一部分候选框,得到多个保留候选框,包括以下步骤中的一个或多个:随机选择所述样本图像中的一个或多个区域作为保留区域,仅保留位于所述保留区域的候选框作为所述保留候选框;将所述基础候选框和所述扩展候选框中全部候选框中的一定比例的候选框随机保留作为所述保留候选框;以及在所述基础候选框和所述扩展候选框中选择特定尺度的候选框作为所述保留候选框;或者选择位于相对于所述基础候选框特定位置处的候选框作为所述保留候选框。
11、在一实施例中,根据本申请的用于驾驶辅助的目标检测方法还包括:增加所述目标检测模型中的特征提取网络的卷积层数。
12、根据本申请的用于驾驶辅助的目标检测方法,对于作为驾驶场景中需要重点关注的区域的关注区域,铺设数量更多的且尺度更多样的候选框,有利于对关注区域提高目标检测的精度;同时,避免了对待检测图像的全部区域增加过多的候选框,并因此降低了目标检测模型的计算量,从而提高目标检测速度。另一方面,在对目标检测模型进行训练的过程中,为了避免在样本图像上铺设过多的候选框导致在训练过程中引入过多的负样本并因此导致模型检测精度的下降,随机丢弃并仅保留其中一部分候选框对目标检测模型进行训练,能够在提升目标检测模型的检测稳定性的同时保证检测精度。
13、根据本申请的第二方面,提供了一种用于驾驶辅助的目标检测装置,包括:获取模块,用于获取待检测目标的驾驶辅助视频,并获取所述驾驶辅助视频每一时刻的待检测图像;确定模块,用于在所述待检测图像上确定多个互不重叠的基础候选框,并且,确定所述待检测图像的关注区域,在所述关注区域中在每个所述基础候选框附近确定尺度不同的多个扩展候选框;以及检测模块,用于将所述基础候选框与所述扩展候选框输入到目标检测模型进行目标检测,得到所述待检测图像的目标检测结果。
14、根据本申请的第三方面,提供了一种计算机设备,包括存储器和处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现根据本申请第一方面的用于驾驶辅助的目标检测方法。
15、根据本申请的第四方面,提供改了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现根据本申请第一方面的用于驾驶辅助的目标检测方法。
16、本申请的一个或多个实施例的细节在下面的附图和描述中提出。本发明的其它特征、目的和优点将从说明书、附图以及权利要求书变得明显。
技术特征:
1.一种用于驾驶辅助的目标检测方法,包括:
2.根据权利要求1所述的方法,还包括:
3.根据权利要求1所述的方法,其中,确定所述驾驶场景图像的关注区域包括:
4.根据权利要求1所述的方法,其中,确定所述驾驶场景图像的关注区域包括:
5.根据权利要求4所述的方法,其中,确定所述驾驶场景图像中的小目标密集区作为所述关注区域包括:
6.根据权利要求1至5中任一项所述的方法,其中,在所述驾驶场景图像上确定多个互不重叠的基础候选框包括:
7.根据权利要求1至5中任一项所述的方法,在将所述基础候选框与所述扩展候选框输入到目标检测模型以检测影响驾驶行为的目标之前,还包括:
8.根据权利要求7所述的方法,其中,在所述样本图像上确定多个互不重叠的基础候选框,并在每个所述基础候选框附近确定尺度不同的多个扩展候选框,包括:
9.根据权利要求7所述的方法,其中,随机保留所述基础候选框和所述扩展候选框中的一部分候选框,得到多个保留候选框,包括以下步骤中的一个或多个:
10.根据权利要求7所述的方法,还包括:
11.一种用于驾驶辅助的目标检测装置,包括:
12.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现权利要求1至10中任一项所述的方法的步骤。
13.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现权利要求1至10中任一项所述的方法的步骤。
技术总结
本申请涉及一种用于驾驶辅助的目标检测方法,包括:获取驾驶场景视频,并获取驾驶场景视频每一时刻的驾驶场景图像;在驾驶场景图像上确定多个互不重叠的基础候选框;确定驾驶场景图像的关注区域;在关注区域中在每个基础候选框附近确定尺度不同的多个扩展候选框;以及将基础候选框与扩展候选框输入到目标检测模型以检测影响驾驶行为的目标,得到驾驶场景图像的目标检测结果。
技术研发人员:孙浩
受保护的技术使用者:黑芝麻智能科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!