一种融合多维度分布特征的分类超平面恒星光谱分类方法
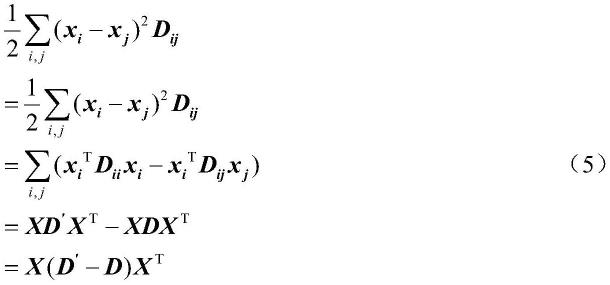
1.本发明涉及恒星光谱数据分类技术领域,尤其涉及一种融合多维度分布特征的分类超平面恒星光谱分类方法。
背景技术:
2.夜空繁星点点,其中大部分都是恒星,而描述地球与恒星之间距离的单位是光年。直接研究这些遥远的恒星成分和性质似乎不太可能。天文学者们发现恒星光谱,不论是连续谱还是线谱,差异极大,它主要取决于恒星的物理性质和化学组成,因此恒星光谱类型的差异反映了恒星性质的差异。天文学者们往往通过恒星光谱数据对遥远的恒星进行研究。
3.恒星光谱数据的数据量极大,随着计算机技术的发展,天文学者们往往借助于智能分类方法对恒星光谱进行分类。支持向量机及其变种是一种典型的智能分类方法,该类模型通过在数据空间构建一个分类超平面将两类分开。该类模型具有良好的鲁棒性和分类能力,因而被广泛应用于恒星光谱数据分类。纵观现有研究不难看出:这些研究往往在支持向量机及其变种的基础上,通过引入模糊隶属度函数将恒星光谱数据区别看待,以降低噪声点对分类结果的影响,并体现不同光谱数据对分类结果的差异化作用;有些研究在分类决策时考虑恒星光谱数据的分布特征,但利用的分布特征较为单一。值得注意的是,支持向量机及其变种对噪声点较为敏感,特别是分类面附近的噪声点,极易造成找到的分类超平面出现偏差。
技术实现要素:
4.为了解决现有技术的不足,本发明提供了一种融合多维度分布特征的分类超平面(hyperplane classification model with multi-dimensional distribution characteristics,hcm)恒星光谱分类方法,试图在恒星光谱数据空间中找到一个分类超平面将两类分开,而本模型找到的分类超平面与一类恒星光谱数据尽可能近且与另一类尽可能远;此外,本发明引入融合多维度分布特征的类间离散度和类内离散度用以表征恒星光谱数据的分布特征,模糊隶属度的引入以降低噪声点对分类结果的影响。
5.本发明为解决其技术问题所采用的技术方案是:提供了一种融合多维度分布特征的分类超平面恒星光谱分类方法,包括以下步骤:
6.s1、计算恒星光谱数据的全局分布特征,得到全局类间特征和全局类内特征;
7.s2、计算恒星光谱数据的局部分布特征,得到局部类间特征和局部类内特征;
8.s3、融合全局类间特征和局部类间特征,得到类间离散度;融合全局类内特征和局部类内特征,得到类内离散度;
9.s4、将类间离散度和类内离散度引入分类超平面优化问题中进行求解,完成恒星光谱分类。
10.步骤s1包括以下过程:
11.设恒星光谱数据集合为x={x1,x2,...,xn},其中第i条恒星光谱数据xi(i=1,
2,...,n)的规模为n,类别数为c,各类规模为ni(i=1,...,c),全局类间特征gd通过以下公式计算得到:
[0012][0013]
全局类内特征gs通过以下公式计算得到:
[0014][0015]
其中x表示全体恒星光谱数据均值,表示各类恒星光谱数据均值;x
ij
表示第i类的第j条恒星光谱数据。
[0016]
步骤s2包括以下过程:
[0017]
设d
ij
为异类紧密度函数,表示不同类恒星光谱数据之间关联的紧密程度,通过以下公式计算:
[0018][0019]
根据异类紧密度函数,将不同类恒星光谱数据之间的关系表示为以下最优化问题:
[0020][0021]
对最优化问题进行代数变化:
[0022][0023]
令局部类间特征ld=x(d'-d)x
t
,d'=∑
jdij
;
[0024]
设s
ij
为同类紧密度函数,表示同类恒星光谱数据之间关联的紧密程度,通过以下公式计算:
[0025][0026]
根据同类紧密度函数,将同类恒星光谱数据之间的关系表示为以下最优化问题:
[0027][0028]
对最优化问题进行代数变化:
[0029][0030]
令局部类内特征ls=x(s'-s)x
t
,s'=∑js
ij
。
[0031]
步骤s3包括以下过程:
[0032]
计算融合多维度分布特征的类间离散度md=αgd+(1-α)ld和融合多维度分布特征的类内离散度ms=βgs+(1-β)ls,其中α和β为常数,其取值范围为[0,1],可通过网格搜索策略获取α和β值。
[0033]
步骤s4包括以下过程:
[0034]
将类间离散度md和类内离散度ms引入分类超平面优化问题得到:
[0035][0036]
s.t.w
t
xi+b≤ξi,1≤i≤m1ꢀꢀꢀꢀꢀꢀꢀ
(10)
[0037]wt
xj+b≥ρ-ξj,m1+1≤j≤n
ꢀꢀꢀꢀꢀꢀ
(11)
[0038]
ξ≥0,ρ≥0,σ≤s≤1
ꢀꢀꢀꢀꢀꢀꢀ
(12)
[0039]
其中w表示分类超平面的法向量,ρ表示两类间隔,b为位移项,表示超平面与原点之间的距离,ξi表示松弛因子,si表示模糊隶属度函数,m1和m2分别表示两类恒星光谱数据规模,σ为大于零且小于1的任意数,ν、ν1和ν2分别为第一模型参数、第二模型参数和第三模型参数,取值均大于0;
[0040]
式(9)至式(12)描述的优化问题的对偶形式为:
[0041][0042][0043][0044][0045][0046]
其中αi为拉格朗日乘子,αi≥0;
[0047]
证明:分类超平面优化问题的拉格朗日方程为:
[0048][0049]
其中ai≥0,βk≥0,λ≥0分别为第一拉格朗日乘子、拉格朗日乘子和第三拉格朗日乘子;分别对w,ρ,ξ,b求偏导,并令偏导等于零,得到:
[0050][0051][0052][0053][0054][0055]
将式(19)至式(23)代入式(18)得到分类超平面优化问题的对偶形式;
[0056]
通过以下过程求解两类间隔ρ和位移项b:
[0057]
根据kkt条件,将式(10)和式(11)分别变换为一组松弛因子为0的等式,得到:
[0058]wt
xi+b=0,1≤i≤m1ꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0059]wt
xj+b=ρ,m1+1≤j≤n
ꢀꢀꢀꢀꢀꢀꢀ
(25)
[0060]
经过代数计算得到两类间隔ρ和位移项b的值分别为:
[0061]
ρ=w
t
(x
j-xi)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(26)
[0062]
b=-w
t
xiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(27)
[0063]
将式(19)代入式(26)和式(27)得到:
[0064][0065][0066]
对于一个类属未知的恒星光谱数据x,通过以下决策函数比较其与分类超平面之间的距离决定其类属:
[0067]
f(x)=sgn(w
t
x+b)
ꢀꢀꢀꢀꢀꢀ
(30)
[0068]
其中sgn()为符号函数。
[0069]
本发明基于其技术方案所具有的有益效果在于:
[0070]
(1)现有研究往往从恒星光谱数据对于分类超平面的重要程度来探讨传统支持向量机抗噪问题。本发明同时考虑模型设计思想和恒星光谱数据重要程度,以期进一步提升模型的抗噪能力。本发明找到的分类超平面不在两类中间,而是在偏向于某一类的同时,远离另一类。与传统支持向量机相比,这种设计思想在一定程度上降低了噪声点对分类超平
面的影响。此外,模糊隶属度的引入,将恒星光谱数据区别看待,特别是弱化噪声点对分类结果的影响。
[0071]
(2)有些研究在支持向量机引入恒星光谱数据分布特征,要么考虑全局特征,要么考虑局部特征,将两者均考虑在内的不多。个别将两者均考虑在内的研究,其全局特征和局部特征的表示、提取和融合等方面均存在一定差距。本发明面向恒星光谱数据,从全局特征与局部特征以及类间特征和类内特征等不同层面,对恒星光谱数据的多维度分布特征进行分析、表征与融合,以期在分类决策时充分考虑恒星光谱数据的分布特征,进而提高模型的分类能力。
具体实施方式
[0072]
下面结合实施例对本发明作进一步说明。
[0073]
本发明提供了一种融合多维度分布特征的分类超平面恒星光谱分类方法,包括以下步骤:
[0074]
s1、全局分布特征从恒星光谱数据集合角度分析各类恒星光谱数据的分布特征。全局分布特征由全局类间特征和全局类内特征表示。
[0075]
计算恒星光谱数据的全局分布特征,得到全局类间特征和全局类内特征。具体包括以下过程:
[0076]
设恒星光谱数据集合为x={x1,x2,...,xn},其中第i条恒星光谱数据xi(i=1,2,...,n)的规模为n,类别数为c,各类规模为ni(i=1,...,c),全局类间特征gd通过以下公式计算得到:
[0077][0078]
全局类内特征gs通过以下公式计算得到:
[0079][0080]
其中表示全体恒星光谱数据均值,表示各类恒星光谱数据均值;x
ij
表示第i类的第j条恒星光谱数据。
[0081]
s2、局部分布特征从恒星光谱数据个体角度分析各类恒星光谱数据的分布特征。局部分布特征由局部类间特征和局部类内特征表示。局部类间特征同时考虑不同类和同类恒星光谱数据的局部特征。
[0082]
计算恒星光谱数据的局部分布特征,得到局部类间特征和局部类内特征。具体包括以下过程:
[0083]
设d
ij
为异类紧密度函数,表示不同类恒星光谱数据之间关联的紧密程度,通过以下公式计算:
[0084][0085]
由异类紧密度函数可以看出,不同类恒星光谱数据之间的距离较大,则它们之间关联的紧密程度较大;同类恒星光谱数据之间关联的紧密程度为0。
[0086]
根据异类紧密度函数,将不同类恒星光谱数据之间的关系表示为以下最优化问题:
[0087][0088]
该优化问题给不同类恒星光谱数据赋予较高权重,不考虑同类恒星光谱数据。
[0089]
对最优化问题进行代数变化:
[0090][0091]
令局部类间特征ld=x(d'-d)x
t
,d'=∑
jdij
;
[0092]
设s
ij
为同类紧密度函数,表示同类恒星光谱数据之间关联的紧密程度,通过以下公式计算:
[0093][0094]
由同类紧密度函数可以看出,同类恒星光谱数据之间的距离较大,则它们之间关联的紧密程度较大;不同类恒星光谱数据之间关联的紧密程度为0。
[0095]
根据同类紧密度函数,将同类恒星光谱数据之间的关系表示为以下最优化问题:
[0096][0097]
该优化问题给同类恒星光谱数据赋予较高权重,不考虑不同类恒星光谱数据。
[0098]
对最优化问题进行代数变化:
[0099][0100]
令局部类内特征ls=x(s'-s)x
t
,s'=∑js
ij
。
[0101]
s3、将全局和局部类间特征和类内特征进行融合,形成多维度特征描述,有助于精准刻画恒星光谱数据的分布特征。融合全局类间特征和局部类间特征,得到类间离散度;融合全局类内特征和局部类内特征,得到类内离散度。即计算融合多维度分布特征的类间离
散度md=αgd+(1-α)ld和融合多维度分布特征的类内离散度ms=
[0102]
βgs+(1-β)ls,其中α和β为常数,起到平衡全局特征与局部特征的作用,其取值范围为[0,1],通过网格搜索策略获取α和β值。
[0103]
s4、本发明试图在恒星光谱数据空间中找到一个分类超平面将两类分开,该分类超平面与一类恒星光谱数据尽可能近且与另一类尽可能远。该模型引入融合多维度分布特征的类间离散度和类内离散度用以表征恒星光谱数据的分布特征,模糊隶属度的引入以降低噪声点对分类结果的影响。
[0104]
将类间离散度和类内离散度引入分类超平面优化问题中进行求解,完成恒星光谱分类。具体包括以下过程:
[0105]
将类间离散度md和类内离散度ms引入分类超平面优化问题得到:
[0106][0107]
s.t.w
t
xi+b≤ξi,1≤i≤m1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0108]wt
xj+b≥ρ-ξj,m1+1≤j≤n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0109]
ξ≥0,ρ≥0,σ≤s≤1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0110]
其中w表示分类超平面的法向量,ρ表示两类间隔,b为位移项,表示超平面与原点之间的距离,ξi表示松弛因子,si表示模糊隶属度函数,m1和m2分别表示两类恒星光谱数据规模,σ为大于零且小于1的任意数,ν、ν1和ν2分别为第一模型参数、第二模型参数和第三模型参数,取值均大于0,在不同的实验数据集上分别进行具体选择;
[0111]
式(9)至式(12)描述的优化问题的对偶形式为:
[0112][0113][0114][0115][0116][0117]
其中αi为拉格朗日乘子,αi≥0;
[0118]
证明:分类超平面优化问题的拉格朗日方程为:
[0119][0120]
其中ai≥0,βk≥0,λ≥0分别为第一拉格朗日乘子、拉格朗日乘子和第三拉格朗日
乘子;分别对w,ρ,ξ,b求偏导,并令偏导等于零,得到:
[0121][0122][0123][0124][0125][0126]
将式(19)至式(23)代入式(18)得到分类超平面优化问题的对偶形式;
[0127]
通过以下过程求解两类间隔ρ和位移项b:
[0128]
根据kkt(karush-kuhn-tucker)条件,将式(10)和式(11)分别变换为一组松弛因子为0的等式,得到:
[0129]wt
xi+b=0,1≤i≤m1ꢀꢀꢀꢀꢀꢀꢀꢀ
(24)
[0130]wt
xj+b=ρ,m1+1≤j≤n
ꢀꢀꢀꢀꢀꢀꢀ
(25)
[0131]
经过代数计算得到两类间隔ρ和位移项b的值分别为:
[0132]
ρ=w
t
(x
j-xi)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(26)
[0133]
b=-w
t
xiꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(27)
[0134]
将式(19)的代入式(26)和式(27)得到:
[0135][0136][0137]
对于一个类属未知的恒星光谱数据x,通过以下决策函数比较其与分类超平面之间的距离决定其类属:
[0138]
f(x)=sgn(w
t
x+b)
ꢀꢀꢀꢀꢀꢀ
(30)
[0139]
其中sgn()为符号函数。
[0140]
实验分析:
[0141]
实验的目的是通过与传统支持向量机模型(svm)以及当前主流方法比较,如基于支持向量机的噪声分类模型(apg_svm)和基于灰狼优化算法的支持向量机模型(sch-svm),来验证本发明提出的一种融合多维度分布特征的分类超平面恒星光谱分类方法(hcm)的有效性。数据集sdss dr10中的k型恒星光谱数据包括k1、k3、k5、k7次型,选取信噪比区间(60,65)的k型恒星光谱数据作为实验数据集。上述实验数据如表1所示。将30%、40%、50%、60%的实验数据集作为训练样本,其余部分用作测试。
[0142][0143]
表1实验数据集
[0144]
实验中选用距离函数作为模糊隶属度函数,其定义如下:
[0145][0146]
其中表示类中心,r表示类半径且
[0147]
利用10折交叉验证和网格搜索法来确定实验中的参数。其中,hcm中的参数ν在网格{1,5,10,15,20,25,30}中搜索,ν1和ν2分别在网格{0.01,0,05,0.1,0.5}中搜索;svm中的参数c在网格{0.01,0.05,0.1,0.5,1,5,10}中搜索;apg_svm中参数c在网格{1,5,10,50,100,500,1000,5000}中搜索,调和参数para在网格{0.1,0.2,0.3,0.4,0.5}中搜索;sch-svm中的分组参数p和v分别在网格{104,5
×
104,105}和{103,2
×
103,3
×
103,4
×
103,5
×
105}中搜索。实验参数和实验结果分别列入表2和表3。
[0148][0149]
表2实验参数
[0150][0151][0152]
表3实验结果
[0153]
由表3可以看出,本发明hcm在各类比例数据集上均具有最优的分类精度。具体而言,当训练样本数为30%时,hcm分类性能最优,apg_svm次之,svm最差,hcm分类精度分别比svm、sch-svm、apg_svm高0.0987、0.0701、0.0480;当训练样本数为40%时,hcm分类性能最优,apg_svm与sch-svm相当,svm最差,hcm分类精度分别比svm、sch-svm、apg_svm高0.0905、0.0602、0.0602;当训练样本数为50%时,hcm分类性能最优,apg_svm次之,svm最差,hcm分类精度分别比svm、sch-svm、apg_svm高0.1129、0.0907、0.0592;当训练样本数为60%时,hcm分类性能最优,apg_svm次之,svm最差,hcm分类精度分别比svm、sch-svm、apg_svm高0.1212、0.0911、0.0687。从平均精度看,hcm的平均分类性能最优,达到0.9206,分别比svm、
sch-svm、apg_svm高0.1058、0.0780、0.0590。hcm在大部分数据集上取得了最优的分类性能,其主要原因是:与svm和apg_svm相比,hcm的设计思想在一定程度上降低了噪声点对分类超平面的影响,此外,hcm还引入了模糊隶属函数,也有助于降低噪声点的影响,因而具有更优的分类精度。hcm和sch-svm在分类决策时均考虑噪声点对分类结果的影响,但与sch-svm相比,hcm引入融合多维度分布特征的类间离散度和类内离散度来表征恒星光谱数据的分布特征,在一定程度上提高了分类精度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1