一种基于重构损失的自监督立体匹配方法
1.本发明涉及机器人视觉领域,尤其是涉及一种基于重构损失的自监督立体匹配方法。
背景技术:
2.随着全球智慧城市的稳步构建与交通网络化的推进,探究道路的日常质量勘测工作对数字城市发展有着深远的意义。而在对道路进行三维重建的过程中非常重要的一步就是对图像进行立体匹配。
3.立体匹配的全监督学习算法需要标记数据来分析预测未知数据的结果。对于大型可标记训练数据集,手动数据标记具有费时低效等缺点。同时,对于无法或难以获得基准真值的数据集,如对路面信息的立体匹配领域,带有绝对基准真值的数据集少之又少,人们常用虚拟数据集进行学习训练,而利用虚拟数据训练模型应用到真实场景时的结果存在精度低的问题。
技术实现要素:
4.本发明的目的就是为了提供一种基于重构损失的自监督立体匹配方法,提高立体匹配的准确性,并减少对视差真值的依赖,具有实用性。
5.本发明的目的可以通过以下技术方案来实现:
6.一种基于重构损失的自监督立体匹配方法,包括以下步骤:
7.获取立体图像对信息,所述立体图像对信息包括一个左图和一个右图,以及图像深度信息;
8.建立端到端立体匹配网络psmnet;
9.将立体图像对信息输入端到端立体匹配网络psmnet,得到预测视差值;
10.基于预测视差值对右图进行重构,并计算重构后的右图与左图之间的重构损失;
11.基于重构损失反向传播对端到端立体匹配网络psmnet进行迭代训练;
12.利用训练完成的端到端立体匹配网络psmnet进行立体图像的匹配。
13.所述端到端立体匹配网络psmnet执行以下步骤:
14.将左图和右图分别输入cnn卷积神经网络模块进行初步特征提取;
15.将左图和右图的初步特征提取结果分别依次输入空间金字塔池化模块和卷积模块提取特征点附近的信息得到特征图;
16.将左、右特征图拼接成一个代价损失量矩阵;
17.基于3d cnn和上采样对代价损失量矩阵进行融合得到代价损失值;
18.基于代价损失值和深度信息进行视差回归计算得到预测视差值。
19.所述cnn卷积神经网络模块的前三层为标准卷积层,后四层为采用残差结构的标准卷积层和空洞卷积层。
20.所述空间金字塔池化模块由四个固定大小的平均池化层组成,将专注的信息由全
局转向局部,并与cnn卷积神经网络模块的部分结果进行拼接,得到特征信息。
21.所述将左、右特征图拼接成一个代价损失量矩阵具体为:通过在每个视差水平上将左特征图和对应的右特征图连接起来,形成一个高度
×
宽度
×
视差
×
通道的四维矩阵,得到代价损失量矩阵。
22.基于堆叠沙漏卷积网络对代价损失量矩阵进行融合得到代价损失值,其中所述堆叠沙漏卷积网络包括三个主要的沙漏网络,对沙漏网络的输出分别进行双线性插值处理得到代价损失值。
23.假设视差等级有d个,对每个视差d的左右特征图误差概率cd进行softmax操作σ(
·
)得到权重,cd大于0小于1,其中,视差基于深度信息得到,左右特征图误差概率cd即为代价损失值,
24.则,预测视差值为通过概率加权的每个视差d的总和:
[0025][0026]
当前特征点在视差d下的匹配误差越大,则cd越大,-cd越小,σ(-cd)函数则越接近于0,对的影响越小。
[0027]
所述基于预测视差值对右图进行重构为对右图中的每个像素向右移动预测视差值大小的像素。
[0028]
对右图进行重构时,其像素点的移动为小数级别。
[0029]
所述重构损失采用平滑l1损失计算:
[0030][0031][0032]
其中,p为左图中点的像素强度,为重构后的右图中对应点的像素强度,为平滑l1损失函数。
[0033]
与现有技术相比,本发明具有以下有益效果:
[0034]
(1)本发明提出了更具通用性的立体匹配方法,引入重构损失概念,如果视差预测准确,则重构后的像素rgb值与左图相近;视差预测错误,则重构后的图像与原图差别较大,重构损失较大,模型则因此进行迭代修改,从而优化网络性能,减少了立体匹配网络对视差真值的依赖。
[0035]
(2)自监督网络的引入可以做到使用全监督网络无法使用的真实数据集进行训练测试,提高了模型在真实场景下的立体匹配表现,打破了真实数据集无基准真值的瓶颈。
[0036]
(3)本发明选取了无需进行后处理的端到端网络psmnet,且此网络在路面数据集上适用性较强。
[0037]
(4)本发明cnn卷积神经网络模块中空洞卷积的运用在没有扩大计算量的基础上扩大了感受野,且相对于同样的池化操作,没有牺牲分辨率指标。
[0038]
(5)本发明采用平滑l1损失(smooth l1 loss)计算重构损失,结合了平均绝对误
差与均方误差的优点,既解决了均方误差在零点附近倒数不连续的缺点,又吸取了平均绝对误差收敛速度迅速的优点,其可以保证在训练初期稳定于某一数值也可以在训练尾声很好地收敛至某一数值,保证梯度下降。
附图说明
[0039]
图1为本发明的方法流程示意图;
[0040]
图2为端到端立体匹配网络psmnet的工作流程图;
[0041]
图3为cnn卷积神经网络模块的结构示意图;
[0042]
图4为空间金字塔池化模块的结构示意图;
[0043]
图5为对代价损失量矩阵进行融合的两种网络架构示意图。
具体实施方式
[0044]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0045]
本实施例提供一种基于重构损失的自监督立体匹配方法,如图1所示,包括以下步骤:
[0046]
1)获取立体图像对信息,所述立体图像对信息包括一个左图和一个右图,以及图像深度信息。
[0047]
2)建立端到端立体匹配网络psmnet。
[0048]
端到端立体匹配网络psmnet的工作流程图如图2所示,其执行以下步骤:
[0049]
21)将左图和右图分别输入cnn卷积神经网络模块进行初步特征提取。
[0050]
cnn卷积神经网络模块的结构如图3所示,前三层为标准卷积层,卷积核大小为3*3,通道大小为32,卷积步长为2,将原本的图片大小下采样为原来的一半。后四层为采用残差结构的标准卷积层和空洞卷积层。conv1_x进行了3次重复,conv2_x进行了16次重复,且将原本图片大小下采样到原来的一半,通道数为64;conv3_x进行了3次重复选用了扩张率为2的空洞卷积,conv4_x进行了3次重复选用了扩张率为2的空洞卷积。空洞卷积的运用在没有扩大计算量的基础上扩大了感受野,且相对于同样的池化操作,没有牺牲分辨率指标。
[0051]
22)将左图和右图的初步特征提取结果分别依次输入空间金字塔池化模块和卷积模块提取特征点附近的信息得到特征图。
[0052]
空间金字塔池化模块的结构如图4所示,由四个固定大小的平均池化层:64
×
64、32
×
32、16
×
16和8
×
8组成,池化尺寸从大到小,将专注的信息由全局转向局部,并与cnn卷积神经网络模块的部分结果进行拼接,最终的输出结果包括平均池化层不同层次像素点周围信息的特征,以及cnn模块不同感受野的信息。
[0053]
23)将左、右特征图拼接成一个代价损失量矩阵:通过在每个视差水平上将左特征图和对应的右特征图连接起来,形成一个高度
×
宽度
×
视差
×
通道的四维矩阵,得到代价损失量矩阵。
[0054]
24)基于3d cnn和上采样对代价损失量矩阵进行融合得到代价损失值。
[0055]
在对代价损失量矩阵进行融合时,有两种可选的架构,如图5所示,一种为基础架
构,一种是堆叠沙漏卷积网络,其中,折线信息代表了将当前层的信息复制相加到箭头对应的神经网络层。
[0056]
基础架构包含12个由残差结构堆叠的3
×3×
3卷积层,然后通过双线性插值将特征图采样到大小h
×w×
d。
[0057]
堆叠沙漏卷积网络包括三个主要的沙漏网络,对沙漏网络的输出分别进行双线性插值处理得到代价损失值。每个沙漏网络输出一个视差图。堆叠沙漏网络可以利用不同尺度的特征信息并进行融合工作。
[0058]
25)基于代价损失值和深度信息进行视差回归计算得到预测视差值。
[0059]
假设视差等级有d个,对每个视差d的左右特征图误差概率cd进行softmax操作σ(
·
)得到权重,cd大于0小于1,其中,视差基于深度信息得到,左右特征图误差概率cd即为代价损失值,
[0060]
则,预测视差值为通过概率加权的每个视差d的总和:
[0061][0062]
当前特征点在视差d下的匹配误差越大,则cd越大,-cd越小,σ(-cd)函数则越接近于0,对的影响越小。
[0063]
此视差回归计算方法比基于分类的立体匹配方法更稳健。
[0064]
3)将立体图像对信息输入端到端立体匹配网络psmnet,得到预测视差值。
[0065]
4)对右图中的每个像素向右移动预测视差值大小的像素,完成对右图进行重构,并计算重构后的右图与左图之间的重构损失。
[0066]
其中,在对右图进行重构时,其像素点的移动为小数级别,不存在将模型计算结果整数后再移动这个过程。
[0067]
所述重构损失采用平滑l1损失(smooth l1 loss)计算:
[0068][0069][0070]
其中,p为左图中点的像素强度,为重构后的右图中对应点的像素强度,为平滑l1损失函数。
[0071]
5)基于重构损失反向传播对端到端立体匹配网络psmnet进行迭代训练。
[0072]
6)利用训练完成的端到端立体匹配网络psmnet进行立体图像的匹配。
[0073]
基于上述方法,本实施例对有/无透视变换的数据进行了训练测试,以及对现有全监督模型与本发明所述的模型做了训练测试。
[0074]
a.评判指标
[0075]
本实施例采用了以下参数对立体匹配结果进行了测试评估。
[0076]
(1)平均像素误差
[0077]
平均像素误差代表了网络预测视差与基准真值之间的像素差异,它代表了网络预
测的平均水平,其具体计算方法如下式所示:
[0078][0079]
其中m为图像像素个数,比如在具体实验中对输入psmnet的图像进行了随机裁剪进行数据增强工作,最终裁剪大小为640
×
480,那么m即为307200。而predispi代表了psmnet对第i个像素进行的视差预测结果,gti代表了此像素点的视差真值,二者相差的绝对值代表了每个像素点视差预测值与视差真值之间的差,则对其求和并与像素个数相除则代表了平均像素误差。比如若平均像素误差为1.488,则可以称此网络误差精度为1.488。
[0080]
(2)1像素误差
[0081]
与平均像素误差不同,1像素误差代表了网络预测结果中有百分之多少的像素点其预测视差在1像素以内,其具体计算方法如下式所示:
[0082][0083]
在图像处理领域,常对其原本误差乘100,并省略百分比符号。例如,若立体匹配的1像素误差结果为5.314,则表示整幅图像中,有5.314%的像素点其预测误差与视差真值的差的绝对值大于1像素。
[0084]
(3)3像素误差
[0085]
1像素误差条件有时会过于苛刻,在立体匹配领域也常使用3像素误差进行误差测试,其具体计算方法如下式所示:
[0086][0087]
3像素误差的容错率相比于1像素误差提高了很多,故此评判指标更为常用。
[0088]
b.测试结果
[0089]
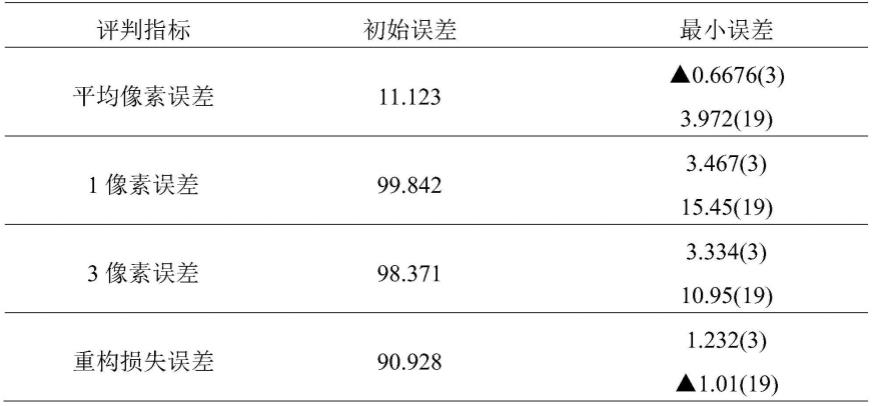
表1展示了基于真值进行训练与验证的现有全监督模型的测试结果,表2展示了本发明所述方法的测试结果,其中,括号内为此时对应的epoch,数字代表在此epoch下的表现,
▲
代表全局最优,表中最后一行展示了引入重构损失的测试结果。
[0090]
表1
[0091][0092]
表2
[0093][0094]
由上表可以看出,本发明所述方法可以有效降低系统的各种误差,但相比于引入重构损失的现有全监督网络还是稍有逊色。重构损失误差的本质是计算左图像素点与右图对应视差距离的像素点之间的相似度,但对于单一颜色区域或者重复纹理区域,可能由重构损失计算出的损失代价极为相似,比如左图像素块a本与右图中像素块b进行像素之间的一一对应,但由于周围场景相似度极高,或者纹理区域不明显等原因,立体匹配网络将像素块a与右图中像素块c进行了匹配,并计算得到预测视差d,如果是全监督立体匹配训练,则通过计算视差真值d'预测视差d之间的损失代价可知,此时的损失代价较高,模型预测不准确并将视差结果反向传输,让模型朝正确方向迭代。但如果采用本发明所述的自监督立体匹配方法,则有可能由于像素块b与像素块c之间的相似度过高,导致其重构损失较低,从而使网络模型以为其匹配正确,网络架构参数得不到有效更新。重构损失具备的此缺点不仅存在于此方法,它还存在于所有无监督模型网络中,故而在测试结果中展示的本发明所述的自监督网络的表现相比引入重构损失的全监督网络稍显逊色,但本发明所述方法能够很好的应用于无需真值的测试场景,打破了真实数据集无基准真值的瓶颈。
[0095]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术
人员依据本发明的构思在现有技术的基础上通过逻辑分析、推理、或者有限的实验可以得到的技术方案,皆应在权利要求书所确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1