基于人工智能分类的检测标准检索系统和方法与流程
1.本发明涉及检测领域,更详而言之地涉及一检测标准检索系统和方法,从而智能地为检测中心和检测人员服务,方便检测人员检测。
背景技术:
2.在产品上市、安全卫生和新产品开发等过程中,产品检测占据重要角色,例如食品、材料、环境或工业原料上市前需要进行安全卫生等质量检测。为了规范检测项目、检测手段和检测流程等等,检测标准成为检测领域的“法律”。具体地,不同的产品涉及不同的检测项目,并且针对产品不同用途或不同地域等,产品检测需要参考对应的国家标准、国际标准、地方标准等等。以国内水果上市销售为例,农药残留方面有可能需要检测多达58项的检测项目,也就是涉及至少58项国家标准。检测人员需要完全按照这些国家标准的要求检测水果,否则就会影响检测报告的准确性和权威性。
3.一直以来,国家标准的发布以文件的形式向大众提供,数量巨大,并随着技术的发展、问题的发现、社会对某些事物认知的变化和产品种类的新增等等不断更新。例如食品安全领域,目前存在上万件现行的国家标准文件,并且每个星期都会有新的国家标准发布。有时会出现,一个星期之内发布十几项甚至几十项新的国家标准文件。
4.如果凭借检测人员自行查找这些单个的国家标准文件,检测的时间和人力被大量浪费,尤其是每个检测中心的检测任务量庞大,任务种类也各有千秋。除此之外,也会浪费检测核对人和检测报告撰写人的时间和人力,检测核对人也需要一个个查找国家标准文件,一一核对检测的手段和流程是否符合规定,报告撰写人也需要将对应的标准文件和报告数据关联。这就导致整个检测中心的运营效率较低,增加运营成本的同时检测效率不高。
5.此外,我们考虑标准的分类的精确性,通过一种基于自然语言处理的cnn模型,将词与图像相关联,从而反映了词语与分类之间的概率对应关系,一改现有技术中基于rnn的不断扫描词和累积分类概率计算的单一方式。我们期望将图形化的标准作为分类的标志,以期在扫描识别邻域有扩展运用。
技术实现要素:
6.本发明所指的标准信息是指与标准文件相关的信息,应当理解为包括标准文件的原文内容,文件的名称、标准号的抽象信息概念或提供标准相关的的项目。本发明所述的反馈、推送标准信息就是指反馈、推送包括标准文件的原文内容,文件的名称、标准号在内的信息项目。而标准文件是指涵盖了这些信息项目的数据文档,在可以是包括电子版的数据文档。而文本化处理即是对其中的标准原文内容进行的。
7.历史标准信息是指标准数据库中在最近一次数据更新之前的存储的标准信息。
8.为了解决上述问题,本发明的一个目的在于提供基于人工智能分类的检测标准检索系统和方法,其中所述检测标准检索系统将检测项目和对应的检测标准关联,以供检测人员获取,无需检测人员花费人力和时间筛选,提高检测中心运营效率,尤其当检测项目数
量庞大或\和种类多杂时。
9.根据本发明的一个实施例,所述检测标准检索系统进一步标准分类模块,所述标准分类模块根据存储的所述标准信息进行自然语言处理,以确定检索的标准信息的分类,其中所述根据存储的所述标准信息进行自然语言处理具体包括如下步骤:
10.(1)标准分类模块获取取检测项目信息,或者产品名称、检测项目、检测标准号、判定标准号中一项或多项的组合对应的标准信息和历史标准信息进行文本化处理得到文本;
11.(2)对步骤(1)中的文本进行特殊词删除,对删除后的文本进行词性解析获得词性分析结果;
12.其中所述词性解析包括词提取过程、划分词过程,以及词性分析过程,从而形成词性分析结果,其中,采用第二隐马尔科夫模型对所述划分词过程的结果进行词性分析,去除停用词形成词性分析文本。
13.优选地,所述标准分类模块中包括新词搜索模块,采用同质图将所述词性分析文本中的词和词性,以及涉及细分科学领域分别作为图的节点而利用按照步骤(1)-(2)将历史标准信息进行词提取形成的历史词库以及经过词性分析得到的词性分析文本建立的词性库进行同质图构建,其中,
14.所述细分科学领域包括现有科学分类体系规定的科学分类、学科专业分类、以及以专利分类视角看待所述文本时的专利分类中至少一者作为复节点。
15.所述复节点是指涉及细分科学领域节点中包括可能不止一个目标对象,例如,当涉及细分科学领域节点中包括科学分类体系规定的科学分类、学科专业分类、专利分类三者时,该节点中即包含了三者作为节点的目标对象。只要词节点对应的词性节点在三者中归属于其中至少一类的,则图的“词性-涉及细分科学领域”边的一端点应属于该复节点。
16.应当理解的是,我们采用词性作为同质图的三元路径中的中间节点,目的是一些词的词性是多样的考虑,如果因为对漏考虑其可能的其他词性来说,也许会将其当作新词看待,从而增加了不必要的重复计算量。比如“过滤”,可以当做限量检测时的实验操作时的动词,但是作为方法步骤时,也可以作为概念名词。如果只偏其一,则势必会影响到另一类标准的漏分类。比如当识别为限量型标准时,则不会分类为检验方法型标准,而如果实际上该标准实际上是新的检验方法型标准时则对于检验方法技术人员来说就少了一篇新标准信息的获取可能。
17.将获取的所述对应的标准信息进行第一新词搜索时不断将删除特殊词后的文本进行词提取依次代入所述同质图词节点,进行边搜索,找到同质图中的对应的所有所述细分科学领域,如果与所述对应的标准信息对应的实际细分科学领域存在全部不同的情况,则将该词定义为疑似新词,如果有相同,则随机归入其中一类相同的细分科学领域路径一端的词节点(即如果有两类分类方式下的分类相同,则随机归入其中一类分类所在路径的另一端的词节点中,如果有三类分类都相同,则随机归入三者之一的分类所在路径的另一端的词节点中),定义为非疑似新词,则该被归入的词节点即成为词复节点,表示该词复节点下存在多种相关的词,或同一概念的其他描述方式等等。
18.利用第一隐马尔科夫模型、条件随机场、或支持向量机中任一模型将删除特殊词后的文本同样进行词提取而进行第二新词搜索,将得到的新词结果与疑似新词和非疑似新词做对比,如果与疑似新词不同,则将新词结果中的词以及疑似新词都作为新词更新词典,
如果与非疑似新词不同,则将新词结果中的词作为新词更新词典,而不将非疑似新词作为新词,而保留在所述一类相同的细分科学领域路径一端的词节点中;如果有相同,则将与之相同的疑似新词或与之相同的非疑似新词作为新词更新词典。
19.优选地,所述词节点中的词存在排序,并且排序同对应词典中词的排序,新词的排序方法如下:如果是采用第二搜索得到的新词则按照搜索得到的顺序排在词典顺序序列的最后,如果是采用第一搜索得到的新词,对于归入词节点的非疑似新词则按照归入时间顺序排序到排序前的节点中最后一个词的后面,形成词复节点,归入后,该词复节点中最后一个词与该词复节点之后的下一个词的节点中的第一个词在排序上定义为连续的。比如在a节点中存在多个因所述归入而存在的多个词a1,a2,a3,a4,与a节点之后排序的b节点中存在的排序为b1,b2,b3等词,则a4和b1定义为排序上连续,即节点a和b整体词的排序为a1,a2,a3,a4,b1,b2,b3等。而对于疑似新词则按照得到的先后顺序排到第二搜索得到的所有新词后面。
20.可以理解的是,采用同质图和非图形的第一隐马尔科夫模型、条件随机场、或支持向量机模型双验证模式,能够进一步弥补非图形模型的具体分类因素的考虑欠缺,也能弥补同质图中分类概率计算缺失的缺陷,而提高新词发现的检出率和准确率,为进一步标准信息准确分类以及推送奠定基础。
21.此外应当强调的是,新词的判断我们认为反而应当允许在一定范围内(5-10%以内)的允许失误,因为这种一定范围内的失误客观上扩充了自然语言识别的词汇量,从而降低分类失误的概率,尽管可能增加分类预测计算量,但只要控制在一定范围则与提高分类准确率相比是值得的。但也不能纵容这种失误率的攀升,因为到一定程度,会增加不必要的同一类词的判断,降低了预测效率。
22.我们双验证采用的模型各有优劣,能够相互弥补计算的不足之外又各自有一定失误率的叠加,从而两者博弈中获得我们想要的效果,即提高识别率同时一定概率上不太增加分类预测计算量。
23.优选地,其中所述特殊词包括,虚词。
24.(3)建立词-词性-分类模型,统计步骤(2)中所有词性分析文本中所有词与词性,输入所述词-词性-分类模型中得到分类结果。
25.其中词-词性-分类模型采用cnn(卷积神经网络)模型,具体步骤如下:
26.(3-1)将历史标准信息中经词性分析后得到词以及词性,分别各赋予规定的像素值,不同的词像素值不同,获得两个按照从左往右词-词性或从右往左词性-词的先后顺序排列的像素点的组;
27.(3-2)将历史标准信息中对应的标准文件的每一篇人工标准分类,并根据标准文件的页数而划分为10页以内短篇、11-20页中篇、21页以上长篇三类文件容量,并且其中的所述组中对应的词按照词典中顺序排序,形成像素点排布构成的方阵图像,方阵大小默认为224
×
224,并允许方阵图像中有百分之5%以内的空白像素,即未排布上具有赋予像素值的像素点的像素位置,也即相应的所述位置没有对应的词和词性,且每一篇中的所有组对应形成的所有像素点应完全排布在同一方阵图像中,而不允许拆分排布于不同的方阵图像中。
28.可选地,所述组中的词和词性各赋予的像素值相同或不同
29.(3-3)若排布完毕时空白像素超过5%,则从排布上的第一个组开始继续依次排序,若排完则继续循环同样排序,直到小于至多5%的空白。例如某一张方阵图排序情况是:第一个像素点为a,第二像素点为b,以及后续排序的像素点等等,且这张方阵图中存在>5%的空白,则继续从第一个空白像素点开始需要按照ab等等顺序排序下去,如果排完第一轮之后还有>5%的空白,则继续ab等等排序直到至少使得空白像素点小于至多5%,也即在排满和小于5%之间选择。
30.将每一类文件容量下得到的方阵图分为训练集、验证集、测试集三者比例为5-1:1:1-3。
31.从训练数据体量上考察我们的cnn算法是符合要求的,由于目前除企业之外的标准的件数已经超14万件,按照两万方阵图的分类训练量,至少可以分为7类这7类均分到三类文件容量下也是每一类文件容量下也至少能分到两类,如果加上企业标准的114万件则分类数可以更加细致。而事实上一般训练量10000次训练已经十分接近所预设的准确率了。
32.模型的稳定性也可以估计,按照前面每周十几件甚至几十件的新颁布速度看,按照一个月4周,一周20件计算,十年9600件才大致相当于一个新的训练分类产生。因此我们将分类数减少而更能体现模型的稳定性。
33.因此,优选地,每五年更新一次训练集、验证集
34.(3-4)对于每一类文件容量,将相应的训练集输入cnn中得到输出向量经过全连接fc之后输出到softmax或sigmoid函数分类为检验方法标准和限定量标准两类,进行训练,使用验证集验证准确率和损失函数值,进行反向传播修正cnn网络参数,反复代入不同的训练集预测分类与所述人工标准分类比较,直到准确率达到预设值且损失函数值稳定结束训练,形成三类cnn模型cnn1,cnn2,cnn3分别对应三类文件容量;
35.(3-5)将测试集按照步骤(3-1)和(3-2)形成方阵图像,输入相应的cnn模型中得到标准的分类,录入所述标准数据库以分类存储。
36.根据本发明的一个实施例,所述检测标准检索系统进一步包括一引用信息推送模块,其中所述引用信息推送模块根据所述检索结果,推送与所述检索结果所引用的判定标准号对应的标准信息。
37.根据本发明的一个实施例,所述引用信息推送模块包括一检验方法推送模块,其中所述检验方法推送模块根据检索结果所引用的检验方法的检测标准号,根据标准分类模块对该检测标准号对应的文件进行cnn分类的结果,或者从所述标准数据库分类存储的检验方法标准文件中调用而反馈对应的检验方法标准信息。
38.根据本发明的一个实施例,所述引用信息推送模块包括一限定量推送模块,其中所述限定量推送模块根据所述检索结果所引用的限量的检测标准号,根据标准分类模块对该检测标准号对应的文件进行cnn分类的结果,或者从所述标准数据库分类存储的限定量标准文件中调用而反馈对应的限量标准信息。
39.其中,所述检测项目包括在检测项目文件中,所述接收一检测项目作为检索条件,匹配所述标准数据库存储的标准信息具体包括:采用前面的自然语言处理方法获得检测项目文件所对应的方阵图,比较数据库各标准对应的方阵图的相似度,从而选择相似度前1-10位大的标准信息作为匹配结果。定义两个方阵图像a与b的相似度其中
和分别是方阵图像a和b中第i个像素点的像素值,求和是对方阵图像a和b的所有像素点进行。
40.根据本发明的一个实施例,所述检测标准检索系统进一步包括一模板建立模块,其中所述模板建立模块根据一模板建立指令,将被选择的标准信息关联为一模板组。
41.具体地,所述模板建立指令包括
42.根据本发明的一个实施例,所述检测标准检索系统进一步包括模板推送模块,其中当所述检索结果涉及所述模板组的标准信息时,所述模板推送模块被触发,推送所述模板组对应的标准信息。
43.根据本发明的一个实施例,所述检测标准检索系统进一步包括一检测项目建立模块,其中所述检测项目建立模块根据一检索需求,从对应的所述标准数据库获取对应的标准信息,形成一检测项目信息。
44.优选地,该检测项目信息进一步包括检测项目文件,并从其中经过词性分析而得到产品名称、检测项目(两者通过专有名词判定)、检测标准号、判定标准号中一项或多项的组合。
45.步骤(1)中标准分类模块获取检测项目信息,或者产品名称、检测项目、检测标准号、判定标准号中一项或多项的组合对应的标准信息和历史标准信息进行文本化处理。
46.此时,以检测项目信息,或者产品名称、检测项目、检测标准号、判定标准号中一项或多项的组合为检索条件,匹配所述标准数据库存储的标准信息,具体包括:采用前面的自然语言处理方法获得检测项目文件所对应的方阵图,比较数据库各标准对应的方阵图的相似度,从而选择相似度前1-10位大的标准信息作为匹配结果。
47.根据本发明的一个实施例,所述检测标准检索系统进一步包括一任务分配模块,其中所述任务分配模块分配所述检测项目信息,形成一任务分配信息。
48.根据本发明的一个实施例,所述检测标准检索系统进一步包括一检测数据录入模块,其中所述检测数据录入模块接收对应于一任务分配信息的一检索结果,其中所述检测数据录入模块根据检索结果对应的检测标准号,获取所述标准数据库对应的标准信息,以供一检测人员检测时参考。
49.根据本发明的一个实施例,所述检测数据录入模块链接所述标准数据库,获取标准信息对应的标准文件。
50.根据本发明的一个实施例,所述检测标准检索系统进一步包括一检测数据审核模块,其中所述检测数据审查模块接收所述检索结果和对应的标准信息,以供一审核人员审核检测数据。
51.依本发明的另一个方面,本发明进一步提供基于人工智能分类的检测标准检索方法,包括:
52.(a)建立标准数据库和前述的标准分类模块;
53.(b)根据检索条件,匹配所述标准数据库存储的标准信息,并反馈所述检索结果。
54.优选地,所述标准数据库契合于一检测中心的检测能力。
55.根据本发明的一个实施例,所述步骤(b)进一步包括步骤:
56.(b0)以检测项目信息或者以产品名称、检测项目、检测标准号、判定标准号中一项或多项的组合为检索条件,匹配所述标准数据库存储的标准信息,具体包括:采用前面的自
然语言处理方法获得检测项目文件所对应的方阵图,比较数据库各标准对应的方阵图的相似度,从而选择相似度前1-10位大的标准信息作为匹配结果;
57.(b1)根据一模板建立指令,将被选择的所述标准信息关联为一模板组;和
58.(b2)当一检索结果涉及该模板组的标准信息时,推送所述模板组对应的标准信息。
59.根据本发明的一个实施例,所述步骤(b)进一步包括步骤:
60.(b3)根据所述检索结果,推送与所述检索结果所引用的判定标准号对应的标准信息。
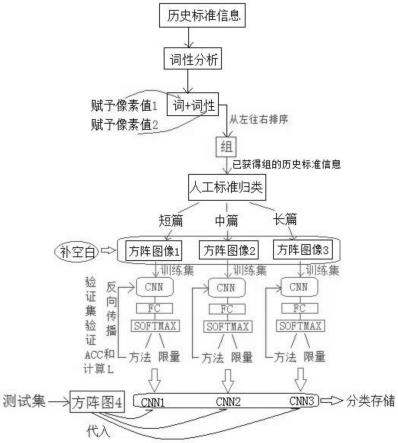
61.根据本发明的一个实施例,所述步骤(b)被实施为
62.(b4)根据一检索需求,匹配所述标准数据库,形成对应的检测项目信息。
63.有益效果
64.本发明采用同质图和非图形的第一隐马尔科夫模型、条件随机场、或支持向量机模型双验证模式对建立cnn模型中关键的方阵图中的词与词性进行新词搜索,以不断扩充词汇,并不断实现新的模型的更新可能。
65.将基于上述双验证过程得到的更新词典进行词+词性的组的像素排序获得代表标准信息的方阵图像,采用输入cnn模型进行训练获得按篇幅长短分类的标准信息的各至少两类的准确分类,为检测和审核人员高效获取准确的标准文件提供算法方案,完善了检测标准检索系统。
附图说明
66.图1本发明第一实施方式中实施例1对应的词性分析以及新词搜索流程图,
67.图2本发明第一实施方式中实施例1对应的同质图以及疑似新词和非疑似新词的搜索和非疑似新词的归入处理流程图,
68.图3本发明第一实施方式中实施例1中词典的词排序示意图,
69.图4本发明第一实施方式中实施例2中的基于双验证过程得到的更新词典进行短中长篇标准信息容量分类下各方阵图及其补空白过程,以及基于cnn的标准信息分类模型建立流程图,
70.图5本发明第一实施方式中实施例2中的方阵图结构,
具体实施方式
71.以下描述用于揭露本发明以使本领域技术人员能够实现本发明。以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。在以下描述中界定的本发明的基本原理可以应用于其他实施方案、变形方案、改进方案、等同方案以及没有背离本发明的精神和范围的其他技术方案。
72.可以理解的是,术语“一”应理解为“至少一”或“一个或多个”,即在一个实施例中,一个元件的数量可以为一个,而在另外的实施例中,该元件的数量可以为多个,术语“一”不能理解为对数量的限制。
73.第一实施方式
74.本实施方式是针对第二实施方式中涉及根据检索结果进行标准信息获取的过程
之前进行的标准信息的分类方案的描述。如无特别说明,第二实施方式中检索操作之前都已经进行了标准信息的分类和分类存储。同时涉及到的标准信息的推送方案中,采用的都可以是根据标准分类模块对检测标准号对应的文件进行cnn分类的结果,或者从所述标准数据库分类存储的检验方法标准文件中调用而反馈对应的检验方法或限定量标准信息。同时,模板建立和推送模板对应的标准信息的过程中被选择的标准信息或模板中被推送的标准信息都来自所述反馈对应的检验方法或限定量标准信息中的所述检验方法或限定量标准信息。
75.实施例1
76.如图1所示,本实施例说明的基于人工智能分类的检测标准检索系统包括:
77.标准数据库,用于存储标准信息,其中所述标准数据库包括检索模块,以及标准分类模块,其中,
78.所述检索模块根据检索条件,匹配对应存储的所述标准信息,反馈检索结果;
79.所述标准分类模块根据检索结果中标准号对应的标准信息进行自然语言处理,以确定检索的标准信息的分类,其中所述根据存储的所述标准信息进行自然语言处理具体包括如下步骤:
80.(1)标准分类模块获取标准号对应的标准信息和历史标准信息进行文本化处理得到文本;
81.(2)对步骤(1)中的文本进行虚词删除,对删除后的文本依次进行专有词提取过程、划分词过程,以及词性分析过程,其中,采用第二隐马尔科夫模型对所述划分词过程的结果进行词性分析,去除停用词形成词性分析文本。
82.如图2所示,所述标准分类模块中包括新词搜索模块,采用同质图结构将词性分析文本中的词和词性,以及涉及细分科学领域分别作为图的节点而利用按照步骤(1)-(2)将历史标准信息进行词提取形成的历史词库以及经过词性分析得到的词性分析文本建立的词性库进行同质图构建,其中所述细分科学领域包括现有科学分类体系规定的科学分类、学科专业分类、以及以专利分类视角看待所述文本时的专利分类三者作为复节点。
83.图1中将获得的对应的标准信息进行第一新词搜索时不断将删除虚词后的文本进行词提取,如图2所示,依次代入同质图词节点,进行边搜索,找到同质图中的对应的所有细分科学领域,如果与所述获得的对应的标准信息对应的实际细分科学领域存在全部不同的情况,则将该词定义为疑似新词,如果有相同,则随机归入其中一类相同的细分科学领域路径一端的词节点,定义为非疑似新词,比如文本词1在代入词节点中词3的过程中发现它在词3对应的图路径“词3-词性2-涉及细分科学领域”中,属于非疑似新词,则随机选择上述三者分类方式中的一者作为路径点断,而将该文本词1归入的词3节点中,使得词3节点即成为复节点,表示该词复节点下存在多种相关的词,或同一概念的其他描述方式等等。当然,在代入词1、词2、词4等其他节点的时候可能为对应路径中属于疑似新词或非疑似新词情况,则都属于第一新词搜索的结果。
84.在图1中,我们利用支持向量机将删除虚词后的文本同样进行词提取而进行第二新词搜索,将得到的新词结果与前述的疑似新词和非疑似新词做对比,如果与疑似新词不同,则将新词结果中的词以及疑似新词都作为新词更新词典,如果与非疑似新词不同,则将新词结果中的词作为新词更新词典,而不将非疑似新词作为新词,而保留在所述一类相同
的细分科学领域路径一端的词节点中(两种情况称作都不同),比如保留在前面提到的路径“词3-词性2-涉及细分科学领域”的词3节点中,也即此时对已经归入节点词3的非疑似新词(比如文本词1)不作任何操作。
85.如果有相同,则将相同的词(即所述疑似新词或所述非疑似新词)作为新词更新词典。
86.所述词节点中的词存在排序,并且排序同对应词典中词的排序,新词的排序方法如下:如果是采用第二搜索得到的新词则按照搜索得到的顺序排在词典顺序序列的最后,如果是采用第一搜索得到的新词,对于归入词节点的非疑似新词则按照归入时间顺序排序到排序前的节点中词或顺序中最后一个词的后面,归入后,该词复节点中最后一个词与该词复节点之后的下一个词的节点中的第一个词在排序上定义为连续的;而对于疑似新词则按照得到的先后顺序排到第二搜索得到的所有新词后面。
87.依据上面的新词搜索和排序的描述,例如所述新词结果中没有一个词与所有经过图2获得的疑似新词和非疑似新词有相同的,则将新词结果所有词按照搜索顺序依次排列到词典最后去,对于判定作为新词的疑似新词则按照得到的先后顺序排到第二搜索得到的所有新词后面。
88.由此获得词典的排序如图3所示。
89.实施例2
90.本实施例将说明标准信息的分类方法。
91.在实施例1的步骤(2)之后,步骤(3)建立词-词性-分类模型,统计步骤(2)中所有词性分析文本中所有词与词性,输入所述词-词性-分类模型中得到分类结果。
92.其中词-词性-分类模型采用cnn模型,具体步骤如下:
93.如图4所示,(3-1)将历史标准信息中经词性分析后得到词以及词性,分别各赋予规定的像素值,采用rgb三类像素值进行搭配而涵盖所有词,不同的词像素值不同,获得两个按照从左往右词-词性的先后顺序排列的像素点的组;所述组中的词和词性各赋予的像素值不同。
94.(3-2)将历史标准信息中对应的标准文件的每一篇人工标准分类,归并根据标准文件的页数而划分为10页以内短篇、11-20页中篇、21页以上长篇三类文件容量,并且其中的所述组中对应的词按照词典中顺序排序,从左往右,从上至下形成像素点排布,以构成方阵图像,方阵大小默认为224
×
224(如图5所示)。其中第1行为词1+词性2的组1,组2等排列,到第2行从左开始即为词255+词性255构成的组255进行排布,以此类推其他像素排布方式。
95.允许方阵图像中有百分之5%以内的空白像素,即未排布上具有赋予像素值的像素点的像素位置,也即相应的所述位置没有对应的词和词性,且每一篇中的所有组对应形成的所有像素点应完全排布在同一方阵图像中,而不允许拆分排布于不同的方阵图像中。
96.(3-3)若排布完毕时空白像素超过5%,则进行补空白操作(如图4),从方阵图像排布上的第一个像素点开始继续依次排序,若排完则继续循环同样排序,直到小于至多5%的空白。
97.例如图5所示,一张方阵图结构中排序情况是:第一个像素点为词1,第二像素点为词性1,以及后续排序的组2的两个像素点等等,且这张方阵图中存在>5%的空白,则继续从词1开始需要按照词1、词性1、组2包括的两个像素等等顺序排序下去,如果排完第一轮之
后还有>5%的空白,则继续词1、词性1、组2包括的两个像素等等顺序排序直到至少使得空白像素点小于至多5%,也即在排满和小于5%之间选择。
98.将每一类文件容量下得到的方阵图分为训练集、验证集、测试集三者比例为3:1:1,每五年更新一次训练集、验证集。
99.(3-4)对于每一类文件容量,将相应的训练集输入cnn中得到输出向量经过全连接fc之后输出到softmax函数分类为检验方法标准和限定量标准两类,进行训练,使用验证集验证准确率和损失函数值,进行反向传播修正cnn网络参数,反复代入不同的训练集预测分类与所述人工标准分类比较,直到准确率acc不小于预设值80%且计算损失函数l的值稳定结束训练,形成三类cnn模型cnn1,cnn2,cnn3分别对应三类文件容量(如图4所示);
100.(3-5)将测试集按照步骤(3-1)和(3-2)形成方阵图4,输入相应的cnn模型中得到标准的分类,录入所述标准数据库以分类存储。
101.第二实施方式
102.本实施方式建立在第一实施方式的标准分类方案上进行的检测标准检索系统和方法
103.本发明提供一检测标准检索系统和方法,为检测中心和检测人员提供信息化服务,建立契合检测中心检测能力的标准数据库,将信息化的标准数据和检测中心的流程关联,提高检测中心运营效率,节省检测人员检测时间和人力。
104.具体地,所述检测标准检索系统包括标准数据库,其中所述标准数据库获取标准文件的标准信息,为标准文件的信息化提供模板。例如,数据库维护人员或软件开发中心将标准文件的对应内容逐一输入所述标准数据库对应项内;或者数据库维护人员或软件开发中心上传标准文件,所述标准数据库自动识别标准文件的对应信息,并填入对应项内;或者所述标准数据库自动获取新的标准文件,自动识别标准文件的对应信息,更新对应项,例如所述标准数据库自动获取检测标准发布官网更新的文件。
105.所述标准数据库信息化地集成多领域的标准文件的信息,例如涉及食品安全、药品、环境和材料等多个领域,并不限制。所述标准数据库可以收集尽可能全面的信息为主,从而提供综合的标准检索服务。或者,所述标准数据库信息化地集成某一领域的标准信息,例如仅集成食品安全领域的标准文件。所述标准总库集成的标准信息包括但不限于判定标准号、检测项目、检测标准号、检测方法、所属行业、产品类型、产品名称、判定标准限量、定量限、检出限、限量单位、检测标准名称、判定标准名称、项目分类、标准类型、适用部门、发布部门、标准启用状态等等。
106.其中,所述检测项目包括检测项目文件,所述接收一检测项目作为检索条件,匹配所述标准数据库存储的标准信息具体包括:采用前面的自然语言处理方法获得检测项目文件所对应的方阵图,比较数据库各标准对应的方阵图的相似度,从而选择相似度前5位大的标准文件作为匹配结果。
107.比如在检测项目文案中获得反映与蛋白质检测领域相关的方阵图,从而比较过后得到限量类型标准下与蛋白质相关的标准文件对应的方阵图相似度最大的全5位,将5件文件进行调用。
108.例如调用结果为,判定标准号为gb11674-2010,检测项目为蛋白质、检测标准号为gb5009.5-2016,检测方法为第一法:凯氏定氮法,所述行业为食品及食品相关产品,二级产
品类型为乳与乳制品,三级产品类型为乳清粉和乳清蛋白粉,产品名称为乳清蛋白粉等等。
109.所述检索条件可以包括是产品名称在内的、检测项目、检测标准号、判定标准号中一项或多项的组合,统称为所述检测项目信息,该信息进一步包括检测项目文件,并从其中经过词性分析而得到。此时步骤(1)中标准分类模块获取产品名称、检测项目、检测标准号、判定标准号中一项或多项的组合对应的标准信息和历史标准信息进行文本化处理。
110.本领域的技术人员应理解,上述描述及附图中所示的本发明的实施例只作为举例而并不限制本发明。本发明的目的已经完整并有效地实现。本发明的功能及结构原理已在实施例中展示和说明,在没有背离所述原理下,本发明的实施方式可以有任何变形或修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1