一种系统自动化维护方法与流程
1.本发明具体涉及一种系统自动化维护方法,属于linux系统ibm websphere application server集群运行技术领域。
背景技术:
2.当前erp系统使用的中间件为websphere application server(was)集群,该集群配置的各节点之间是高可用+负载均衡结构,如图1所示,每个功能模块均有4个was实例节点做互为主备以及负载均衡,当出现持续性占用内用的作业或者程序错误时,会导致该节点宕机,一个节点宕机会导致其他实例节点压力过大,从而容易引发其他节点出现问题甚至宕机;若不及时处理,严重情况下会导致整个功能模块瘫痪;另外,当前业务用户存在频繁点击某项需求现象或代码层面未关闭连接等问题,从而引发负责该功能模块的几个实例节点相继宕机,若该模块几个节点全部宕机且未及时处理,该模块则无法使用,从而影响到生产。
技术实现要素:
3.为解决上述问题,本发明提出了一种系统自动化维护方法,能够实现收集was集群节点状态、was集群节点连接数超高和was集群节点宕机故障运维处理的自动化,从而提高效率、减小故障时间和降低风险,促进运维组织的成熟和各种能力的升级;具有确定性、可用性、及时性特性。
4.本发明的系统自动化维护方法,所述方法具体如下:1)通过编写shell脚本收集ibm was集群节点状态,所述shell脚本包括检测脚本和重启脚本;2)对每台主机上配置文件,所述文件包括was节点实例名列表和端口列表;3)shell脚本收集was集群节点状态,脚本定期调用was集群各节点状态接口,在检查到节点状态异常时,对该节点进行及时重启处理。
5.进一步地,所述步骤3)工作过程如下:系统定时去检测was实例各节点状态,若检测到状态异常时,对该节点进行重启处理并将异常节点以及时间点记录到log文件中,若节点状态正常则脚本终止,等待下一轮检测。
6.再进一步地,在was集群运行过程以及节点异常时,通过以下步骤完成节点状态的获取以及维护:(1)由于各主机已完成文件配置,通过shell脚本获取was实例名,根据实例名去匹配对应端口,将获取到的实例名以及端口带入至实例状态检测接口,获取实例的状态;(2)当was实例因内存堆溢出产生宕机或者连接数满时,导致对应节点无法访问,此时检测脚本检测到后,会针对故障节点进行重启操作,从而对内存释放或连接释放;同时将故障节点以及故障时间记录到log文件中。
7.进一步地,所述脚本定期调用的调用周期为15分钟一个循环。
8.本发明的系统自动化维护方法,通过编写shell脚本,实现收集was集群节点状态、was集群节点连接数超高和was集群节点宕机故障运维处理的自动化,从而提高效率、减小故障时间和降低风险,促进运维组织的成熟和各种能力的升级;具有确定性、可用性、及时性特性;其中,确定性是指自动化运维必须要有确定的响应能力,主要包括实时性和检测性;可用性是指外部资源得到一定程度的保证前提下,自动化运维可执行规定功能的能力;主要包括:可靠性和安全性;及时性是指自动化运维在任何时刻都要及时处理故障问题,包括夜间无人值守。
9.与现有技术相比,本发明的系统自动化维护方法,用以保障erp系统was节点的可用性、可靠性以及降低其故障风险性;有效实现故障发现、故障响应、故障定位和故障处理环节,处理夜间故障以及持续性作业导致节点宕机时尤为明显,能够最大限度的增加tbf(无故障时长)和缩短ttr(故障修复时长)。
附图说明
10.图1是现有的现有的was集群节点处理业务操作图。
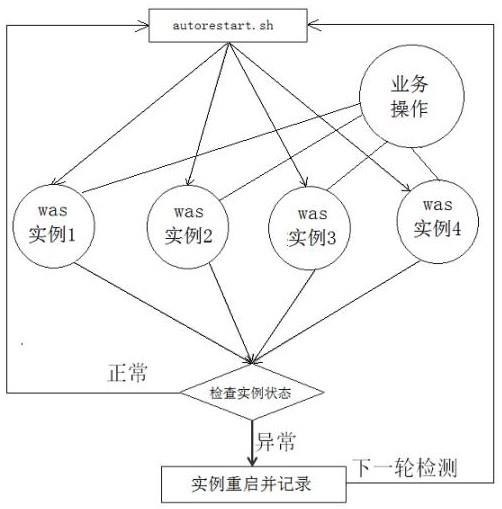
11.图2为本发明的自动化维护方法处理逻辑图。
具体实施方式
12.实施例1:本发明的系统自动化维护方法,通过编写shell脚本,实现收集ibm websphere application server(以下简称was)集群节点状态、was集群节点连接数超高和was集群节点宕机故障运维处理的自动化,其具体为:所述系统自动化维护的收集was集群节点状态,脚本会定期调用was集群各节点状态接口,在检查到节点状态异常时,对该节点进行及时重启处理,达到恢复业务的效果,减少故障影响时间;所述系统自动化维护的was集群节点连接数超高,was集群配置的各节点连接数为60,当代码层面出现问题(如代码层面未关闭连接)时,程序的连接数就会增高,其它作业将无法建立新的连接从而影响到使用;脚本检测到后,会针对这种情况进行处理,从而恢复业务;所述方法通过指定针对was集群节点的各种状态进行收集,从而达到故障处理的效果,并且定时去检测,可以及时恢复业务。
13.实施例2:本发明的系统自动化维护方法,包括以下步骤:1)通过编写shell脚本收集ibm was集群节点状态,所述shell脚本包括检测脚本和重启脚本;2)对每台主机上配置文件,所述文件包括was节点实例名列表和端口列表;3)shell脚本收集was集群节点状态,脚本定期调用was集群各节点状态接口,在检查到节点状态异常时,对该节点进行及时重启处理。
14.其中,所述步骤3)工作过程为:系统定时去检测was实例各节点状态,若检测到状态异常时,对该节点进行重启处理并将异常节点以及时间点记录到log文件中,若节点状态正常则脚本终止,等待下一轮检测。在was集群运行过程以及节点异常时,通过以下步骤完成节点状态的获取以及维护:
(1)由于各主机已完成文件配置,通过shell脚本获取was实例名,根据实例名去匹配对应端口,将获取到的实例名以及端口带入至实例状态检测接口,获取实例的状态;(2)当was实例因内存堆溢出产生宕机或者连接数满时,导致对应节点无法访问,此时检测脚本检测到后,会针对故障节点进行重启操作,从而对内存释放或连接释放;同时将故障节点以及故障时间记录到log文件中。
15.如图2所示,脚本根据流程,定时去检测was实例各节点状态,若检测到状态异常时,对该节点进行重启处理并将异常节点以及时间点记录到log文件中,以便于后期排查根因;若节点状态正常则脚本终止,等待下一轮检测;在was集群运行过程以及节点异常时,通过以下步骤完成节点状态的获取以及维护:(1)通过shell脚本获取was实例名,根据实例名去匹配对应端口,将获取到的实例名以及端口带入至实例状态检测接口,获取实例的状态;(2)当was实例因内存堆溢出产生宕机或者连接数满时,会导致该节点无法访问,此时检测脚本检测到后,会针对故障节点进行重启操作,从而达到释放内存或释放连接的效果;同时也会将故障节点以及故障时间记录到日志文件,便于故障分析复盘;(3)检测机制:在erp系统配置15分钟检测一次,检测设置15分钟依据为:根据大量节点重启过程数据分析,单个节点仅启动需要时间5~7分钟,同时考虑了主机资源和故障影响时间因素,从而配置了15分钟一个循环,在一个循环内,即不会频繁的调用主机资源,也不会造成单节点故障太长时间。
16.其中,系统自动化维护方法包含两个脚本:autorestart.sh(检测脚本)、jvmoom.sh(重启脚本);每台主机上配置两个文件:ap01.lst(was节点实例名列表)和port(端口列表)。
17.上述实施例,仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述的构造、特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1