一种基于时空势能场的城市人群流动预测系统及其方法
1.本发明涉及智慧城市技术领域,更具体的说是涉及一种基于时空势能场的城市人群流动预测系统及其方法。
背景技术:
2.城市人群流动预测问题一直是时空数据挖掘领域中的广受研究者们关注的重点问题,随着城市化水平的推进,大量人口涌入城市人口数量激增,给城市的运营管理问题产生了巨大的影响,而城市人群流动预测作为智慧城市的核心技术之一,在真实世界里有至关重要的帮助。例如城市范围内人流量预测能够支持政府部门更好的了解和管理城市人群流动情况,促进多项工作的开展如交通管制等,特定区域的例如景区、市中心等的人流量的预测能够让组织者更好地保证大规模聚会时的人员安全问题。
3.早期的城市人群流动预测方法主要是关注于较为浅层的统计模型,该类模型将城市人群流动视为时间序列并运用以差分整合移动平均自回归模型(arima)为代表的统计模型来解决问题。而近些年,以深度学习为基础的城市人群预测模型开始在工业界和学术界大放光彩,这类模型通常使用循环神经网络(rnn)和卷积神经网络(cnn),前者能够捕捉城市人群流的时间依赖性,而后者则可以提取到城市人群数据的空间依赖性。而如果城市人群数据是由非欧氏空间的结构所组成的,例如路网结构,图神经网络则更为擅长处理该类数据类型。
4.然而,大部分这些统计学习模型遵守的是数据驱动的方针,这样的模型缺乏对城市人群流动原理机制的理解,从而导致预测模型的泛化性能被限制和模型可解释性欠佳的问题,因此尽管这些模型在许多实际运用中表现出类拔萃,但是依然无法得到人们的完全信任,尤其是在重要的应用领域上例如公共安全和应急管理。
5.因此,如何提供一种准确可靠的城市人群流动预测系统及其方法是本领域技术人员亟需解决的问题。
技术实现要素:
6.有鉴于此,本发明提供了一种基于时空势能场的城市人群流动预测系统及其方法,能够更加精确有效地对城市人群流动进行预测。
7.为了实现上述目的,本发明采用如下技术方案:
8.一种基于时空势能场的城市人群流动预测系统,包括:pef提取模块和数据驱动模块;
9.所述pef提取模块,用于将基于网格的历史城市人群流图分解为多个基于多叉树的历史势能场;
10.所述数据驱动模块包括时空深度学习模型和城市人群流图重建单元;
11.其中所述时空深度学习模型包括时间建模组件和空间建模组件;
12.所述时间建模组件包括短期相关性建模单元和长期相关性建模单元,所述短期相
关性建模单元用于捕获所述历史势能场的短期相关性,所述长期相关性建模单元用于引入门控机制来捕获所述历史势能场的长期相关性,并将所述短期相关性和所述长期相关性进行叠加形成时间相关性输入至所述空间建模组件;
13.所述空间建模组件,用于将加权定向注意机制以及多头注意力机制引入图注意力机制gat来捕捉空间相关性,并与所述时间相关性进行融合,融合后的结果输入到mlp中用于输出势能场预测值;
14.所述城市人群流图重建单元,用于根据所述势能场预测值推导相应的城市人群流图,从而完成城市人群流动预测。
15.优选的,所述pef提取模块包括社区划分单元、方向分解单元、多叉树分解单元和势能场产生单元;
16.所述社区划分单元,用于将待预测区域进行区域划分,获得若干个社区,使得社区内部流量最大化和社区间人群流动最小化;
17.所述方向分解单元,用于将具有双向流动的社区分解为两个子图,每个子图内的相邻结点之间仅为单向流动;
18.所述多叉树分解单元,用于将分解后的每个子图对应的流量图分别分解为一组多叉树,其中每个多叉树均为有向无环图;
19.所述势能场产生单元,用于针对分解后的每个多叉树获取基于多叉树的势能场。
20.优选的,所述多叉树分解单元的具体内容包括:
21.(1)每个时空流量图均可以被分解为两个梳子状的流量多叉树t1和t2,而每个多叉树都有互相垂直的梳子主干方向和梳齿方向,将一个流量图中最大的流量对应的方向设定为t1的梳子主干方向,对应的垂直方向即为t2的梳齿方向,而t2的梳子主干方向则为t1的梳齿方向,t2的梳齿方向为t1的梳子主干方向,之后为每棵多树选择对应的骨干节点,骨干节点的选择方式为该多叉树主干方向的最大流量边的初始结点;
22.(2)按照(1)中初始化所述建模时空流量图的流量多叉树t1和t2,并为每棵多树选择对应的骨干节点b1和b2;
23.(3)先对于t1多叉树,沿梳子主干方向扩展骨干节点b1得到骨干子图gb,并加入所述流量多树t1;
24.(4)沿着梳齿方向扩展所述骨干子图gb中的每个节点得到齿边子图gt,并加入所述流量多树t1;
25.(5)判断所述齿边子图t1中所有节点是否均被扩展选择过,如果是,则生成所述流量多树t1;否则,选择一个未选择过的节点vt沿梳子主干方向选择不会成环的边扩展节点m,并加入所述骨干子图gb和所述多树t1中,将m设置成b1并返回(3)和(4);
26.(6)对于t2多叉树同理,重复以上(3)、(4)和(5);
27.(7)获得多树t1和多树t2,若一条边同时出现在t1和t2中,则将该边在两棵多树中的流量均减半。
28.优选的,所述多叉树分解单元还用于对表示跨社区的人群流的宏流量图进行分解,具体内容包括:
29.将宏流量图通过主次划分算法根据流量的大小划分为主子图和次子图,所述主子图和次子图均包含宏流量图的所有结点和单向边,而对于没有双向流的主子图和次子图,
通过泛多叉树算法来将其分解为多个边互不相交的多叉树,所述泛多叉树算法的具体内容为:
30.①
对于输入的宏流量图mg,设置mg的每一条边的访问数t
uv
=0,初始化每一条边的权重为w
uv
=1/e
uv
,同时将输出的边不互交的流量多叉树集mt设置为空集;
31.②
计算扩展系数φ=w
max
/w
min
+1;
32.③
考虑将mg的每个结点作为一个独立的树;
33.④
从边集中取出权重最小边e
uv
,如果u和v属于两个不同的树,就将两棵树合并,重复步骤4直到所有的结点属于一棵树t,并将树t加入到多叉树集合mt中;
34.⑤
对
①
中的参数进行更新,对于
④
生成的树t的每条边,均进行如下更新
35.t
uv
←
t
uv
+1
[0036][0037]
⑥
重复
②
、
③
、
④
和
⑤
,直到原输入图mg的每一条边的访问数t
uv
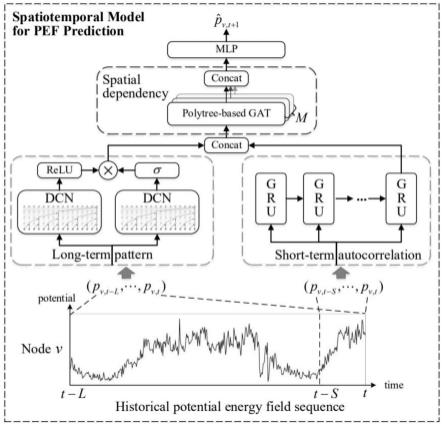
都大于0;
[0038]
⑦
最后根据t
uv
将人群流动平均分给包含边e
uv
的多叉树,得到输出多叉树集合mt。
[0039]
需要说明的是:
[0040]
上述主次划分算法的思想与前面的方向分解单元一致,目的都是为了把一对节点间的双向流划分为两个单向流,一个为主一个为次。区别在于主次划分算法适用于任何图(graph),而方向分解单元只适用于网格图。
[0041]
优选的,所述势能场产生单元的生成势能场的具体内容包括:
[0042]
分解之后得到流量多叉树,两个节点之间的流量大小作为两个节点的势能差,随机选择一个树节点为0势能点,并进一步获得所有节点的势能,从而得到一个流量多树对应的势能场;
[0043]
当势能场中存在负值时,以每个节点的当前势能减去最小节点势能的方式将所有势能值归一化到[0,正无穷)。
[0044]
优选的,所述短期相关性建模单元获取短期相关性的具体内容为:
[0045]
使用类rnn网络的gru模型来捕获短期相关性;
[0046]
将任意结点v历史势能场表示为通过gru对历史势能场数据进行循环编码得:
[0047]hv,t
=gru(h
v,t-1
,p
v,t
)
[0048]
其中是一个在时间t结点v的隐层时间表示,ks为短期相关性建模单元的隐层表示的维度,s为短期相关性建模单元中输入势能时间序列的长度。
[0049]
优选的,所述长期相关性建模单元获取长期相关性的具体内容为:
[0050]
采用类cnns的dcn模型来捕获长期相关性;
[0051]
将任意结点v历史势能场表示为过滤器θ∈rr,dcn操作符定义为:
[0052]
[0053]
其中θi是θ的第i个元素,d表示膨胀因子,l为长期相关性建模单元中输入势能时间序列的长度;
[0054]
将一段历史时间内的势能序列输入dcn进行长期建模,引入了一种门控机制来切换dcn中的模式:
[0055][0056]
其中是结点v在时间t的势能场长时间表达,σ是sigmoid函数,
⊙
是逐元素乘法,θ1,表示可学习的卷积滤波器,n
l
是dcn中的卷积层数目;
[0057]
将长期时间表达c
v,t
与自回归表达h
v,t
进行叠加:nv=[h
v,t
,c
v,t
]作为时间t结点v的最终表达。
[0058]
优选的,所述空间建模组件捕捉空间相关性的具体内容包括:
[0059]
在空间建模组件中,采用图注意力机制gat来捕捉空间相关性,将n
vk
视为势能场中结点v的表达,在时间t,gat方法逐步更新包括所有势能场n
vk
的矩阵
[0060]n(z)
=gat(n
(z-1)
|t)
[0061]
其中z是迭代次数,对每个vk初始化结点表示
[0062]
在更新过程中,将加权定向注意机制引入gat:
[0063][0064][0065]
其中分别表示较低势能和较高势能结点vi的邻居;
[0066]
采用多头注意力机制使用注意力生成每个多叉树节点的表示:
[0067][0068]
其中||表示拼接,m是注意力端数目,是由第m个注意力机制计算的归一化注意力分数。
[0069]
一种基于时空势能场的城市人群流动预测方法,包括以下步骤:
[0070]
s1.将基于网格的历史城市人群流图分解为多个基于多叉树的历史势能场;
[0071]
s2.捕获所述历史势能场的短期相关性,引入门控机制来捕获所述历史势能场的长期相关性,并将所述短期相关性和所述长期相关性进行叠加形成时间相关性;
[0072]
s3.将加权定向注意机制以及多头注意力机制引入图注意力机制gat来捕捉空间相关性,并与所述时间相关性进行融合,融合后的结果输入到mlp中用于输出势能场预测
值;
[0073]
s4.根据所述势能场预测值推导相应的城市人群流图,从而完成城市人群流动预测。
[0074]
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于时空势能场的城市人群流动预测系统及其方法,将基于网格的城市人群流图分解为多个基于多叉树的势能场(pef),并通过学习时空深度学习模型来预测pef的动态,并分别捕获势能场的短期相关性和长期相关性,同时通过空间建模组件使用加权定向注意力扩展gat,来模拟势能场中的不对称空间结构,最后通过时空深度学习模型预测的势能场来得到人群流动预测结果,具有高效性与准确性。
附图说明
[0075]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
[0076]
图1为本发明实施例提供的社区划分和方向分解示意图;
[0077]
图2为本发明实施例提供的分解流量图为两个多叉树流程示意图;
[0078]
图3为本发明实施例提供的st-pef+模型中预测pef的时空深度学习模型示意图。
具体实施方式
[0079]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0080]
本发明实施例公开了一种基于时空势能场的城市人群流动预测系统,包括:pef提取模块和数据驱动模块;
[0081]
pef提取模块,用于将基于网格的历史城市人群流图分解为多个基于多叉树的历史势能场;
[0082]
数据驱动模块包括时空深度学习模型和城市人群流图重建单元;
[0083]
其中时空深度学习模型包括时间建模组件和空间建模组件;
[0084]
时间建模组件包括短期相关性建模单元和长期相关性建模单元,短期相关性建模单元用于捕获历史势能场的短期相关性,长期相关性建模单元用于引入门控机制来捕获历史势能场的长期相关性,并将短期相关性和长期相关性进行叠加形成时间相关性输入至空间建模组件;
[0085]
空间建模组件,用于将加权定向注意机制以及多头注意力机制引入图注意力机制gat来捕捉空间相关性,并与时间相关性进行融合,融合后的结果输入到mlp中用于输出势能场预测值;
[0086]
城市人群流图重建单元,用于根据势能场预测值推导相应的城市人群流图,从而完成城市人群流动预测。
[0087]
需要说明的是:
[0088]
流量图定义为g(vg,eg),是一个有向带权图,其中结点是空间网格里的空间区域,边是相邻区域之间的有向人群流动。并且用vi∈vg表示结点,从vi到vj的人群流动表示e
ij
∈eg。
[0089]
在知道某个城市t-t到t时间历史流量图序列的情况下,城市人群流动预测问题可认为是构造一个生成函数f,其中认为是构造一个生成函数f,其中是g
(t+1)
的预测值。
[0090]
通常预测城市人群流动的模式是建模和g
(t+1)
之间的相关性。在本发明中则使用基于场理论的模型来提升预测模型的泛化性和可解释性。考虑地球表面的水流,水流的速度和方向由地球表面的重力场决定。相似地,本发明中模型也假设,城市不同地点之间的人群流是由一些建立在城市功能上的潜在“势能场”驱动的。例如,在早高峰时段,住宅区比工作区具有更高的势能,这促使人们从家到工作场所。相比之下,在晚高峰时段,工作区比住宅区更有势能,驱使人们从工作场所回家。
[0091]
于是为了建模势能场,本发明提出了一种一种基于时空势能场的城市人群流动预测系统,称为st-pef+,该模型包括了势能场抽取模块和数据驱动模块,前者是一种势能场抽取算法,后者是一种城市人群流动预测深度学习模型。
[0092]
为了进一步实施上述技术方案,pef提取模块包括社区划分单元、方向分解单元、多叉树分解单元和势能场产生单元;
[0093]
社区划分单元,用于将待预测区域进行区域划分,获得若干个社区,使得社区内部流量最大化和社区间人群流动最小化;
[0094]
方向分解单元,用于将具有双向流动的社区分解为两个子图,每个子图内的相邻结点之间仅为单向流动;
[0095]
多叉树分解单元,用于将分解后的每个子图对应的流量图分别分解为一组多叉树,其中每个多叉树均为有向无环图;
[0096]
势能场产生单元,用于针对分解后的每个多叉树获取基于多叉树的势能场。
[0097]
需要说明的是:
[0098]
在势能场抽取模块中,其内容包括三部分:社区划分、方向分解、多叉树分解,通过这三步,将流量图转换为多个势能场。其中方向分解和多叉树分解分别解决了转换过程中出现的双向流量问题和流量环路问题。
[0099]
如图1(a)-(c),社区划分的目标是将研究的区域分为多个社区、最大化社区内部流量和最小化社区间人群流动,这样有利于减少输入的流量图大小和更容易建模。于是,在给予历史空间网格t-t到t时间城市人群流动图的情况下,本实施例建立一个累计的流量图接着将分为多个连接子图,表示为其中cp代表社区划分,c是社区列表,gc是社区c的流量图。
[0100]
在本实施例中划分社区的算法选择girvan-newman(gn)算法来生成社区,这个算法逐渐移除图里的边直到产生足够的子图。而为了将跨社区流量纳入势能场,对于每个社区,本发明将与其边界相邻但属于其他社区的网格扩展到社区中。并且为了更方便的建模和训练,本发明为流量图序列选择了一个固定的社区结构。此外本发明视为社区代表一个长期结构,因此本发明将长期历史数据考虑到划分过程中。
[0101]
方向分解的目标是处理双向流动的问题,方向分解能够将每个社区划分为两个子图,每个子图的相邻结点只包含单向流动。在这一步中,本发明将从底部向顶部流动的边视为边集e
↑
,从顶部向底部流动的边视为边集e
↓
,如果边集e
↑
的流量之和大于e
↓
,则e
↑
为主方向,e
↓
为次方向,反之亦然。同理,本发明定义边集e
←
和e
→
,并且从两个边集中找出主方向和次方向。如图1.c所示,黑色的箭头代表主方向,黄色的箭头代表此方向。在主方向子图和次方向子图中,两个相邻结点被无向边所连接,只包含单向流动。
[0102]
第三步多叉树分解目标在于解决流量环路问题,这个步骤会将流量图分解为一组多叉树,每个多叉树都是有向无环图。
[0103]
为了进一步实施上述技术方案,多叉树分解单元的具体内容包括:
[0104]
(1)每个时空流量图均可以被分解为两个梳子状的流量多叉树t1和t2,而每个多叉树都有互相垂直的梳子主干方向和梳齿方向,将一个流量图中最大的流量对应的方向设定为t1的梳子主干方向,对应的垂直方向即为t2的梳齿方向,而t2的梳子主干方向则为t1的梳齿方向,t2的梳齿方向为t1的梳子主干方向,之后为每棵多树选择对应的骨干节点,骨干节点的选择方式为该多叉树主干方向的最大流量边的初始结点;
[0105]
(2)按照(1)中初始化建模时空流量图的流量多叉树t1和t2,并为每棵多树选择对应的骨干节点b1和b2;
[0106]
(3)先对于t1多叉树,沿梳子主干方向扩展骨干节点b1得到骨干子图gb,并加入流量多树t1;
[0107]
(4)沿着梳齿方向扩展骨干子图gb中的每个节点得到齿边子图gt,并加入流量多树t1;
[0108]
(5)判断齿边子图t1中所有节点是否均被扩展选择过,如果是,则生成流量多树t1;否则,选择一个未选择过的节点vt沿梳子主干方向选择不会成环的边扩展节点m,并加入骨干子图gb和多树t1中,将m设置成b1并返回(3)和(4);
[0109]
(6)对于t2多叉树同理,重复以上(3)、(4)和(5);
[0110]
(7)获得多树t1和多树t2,若一条边同时出现在t1和t2中,则将该边在两棵多树中的流量均减半。
[0111]
需要说明的是:
[0112]
流量多叉树是t(v
t
,e
t
)流量网格图g(vg,eg)的有向生成树,其结点包括了所有g的结点,v
t
=vg,并且边集是流量图的子集,如图1(d)就是主要流量图的多叉树(黑色)。
[0113]
多叉树分解是将流量图gg分解为k个多叉树t1,t2,
…
,tk的过程,且。
[0114]
本发明提出的多叉树分解(ptd)算法,使用该算法可以将一个流量图分解为梳子状的主要子图和次要子图如1(d)所示。对于每个多叉树,这个算法首先确定梳子主干方向和梳子梳齿方向,接着这个算法会沿着这两个方向交替的扩展结点生成多叉树。
[0115]
图2为ptd算法样例,首先本发明决定梳子主干方向为流量最大的方向,梳子梳齿方向为梳子主干方向的垂直方向,接着本发明设置多叉树t1为梳子主干方向和梳子齿状方向,t2的边方向为t1梳子主干方向和梳子齿状方向的正交方向,如图2(a),结点9到10为最大流量,所以t1梳子主干方向为从西到东。第二步,本发明将流量最大的结点设置为初始结点
(结点9),然后顺着主干方向延伸多叉树如图2(b),延伸完毕后再顺着梳子梳齿方向延伸如图2(c),如此交替进行得到多叉树t1(如图2(e)所示),图2(d)展示了交替迭代过程中的一个状态。同理,通过得到图2(e)的方法也可以得到t2(如图2(f)所示)。最后找到t1,t2的共同边将流量折半即可。
[0116]
为了进一步实施上述技术方案,多叉树分解单元还用于对表示跨社区的人群流的宏流量图进行分解,具体内容包括:
[0117]
将宏流量图通过主次划分算法根据流量的大小划分为主子图和次子图,主子图和次子图均包含宏流量图的所有结点和单向边,而对于没有双向流的主子图和次子图,通过泛多叉树算法来将其分解为多个边互不相交的多叉树,泛多叉树算法的具体内容为:
[0118]
①
对于输入的宏流量图mg,设置mg的每一条边的访问数t
uv
=0,初始化每一条边的权重为w
uv
=1/e
uv
,同时将输出的边不互交的流量多叉树集mt设置为空集;
[0119]
②
计算扩展系数φ=w
max
/w
min
+1;
[0120]
③
考虑将mg的每个结点作为一个独立的树;
[0121]
④
从边集中取出权重最小边e
uv
,如果u和v属于两个不同的树,就将两棵树合并,重复步骤4直到所有的结点属于一棵树t,并将树t加入到多叉树集合mt中;
[0122]
⑤
对
①
中的参数进行更新,对于
④
生成的树t的每条边,均进行如下更新
[0123]
t
uv
←
t
uv
+1
[0124][0125]
⑥
重复
②
、
③
、
④
和
⑤
,直到原输入图mg的每一条边的访问数t
uv
都大于0;
[0126]
⑦
最后根据t
uv
将人群流动平均分给包含边e
uv
的多叉树,得到输出多叉树集合mt。
[0127]
需要说明的是:
[0128]
结点势能:在一个流量多叉树里,结点vi的势能定义为其中和e
ij
分别是结点vi的势能和从结点vi到结点vj的人群流动。通过定义一个多叉树里的零势能结点,其他结点的相对势能就都可以计算得知。
[0129]
结点势能场:一个流量势能场pt是定义在流量多叉树t的所有结点的标量,其中每个结点vi都有势能p
vi
,此外本发明保证pt最小的势能的值为0。
[0130]
如图1(d)和1(e)展示了如何生成一个基础的多叉树势能场.图1(f)保证了最小的势能0并且产生了一个势能场。
[0131]
宏流量图:一个宏流量图mgv
mg
,e
mg
是一个有向图,其结点为社区,其边描述了相邻社区的聚合人群流。
[0132]
结点势能和结点势能场:只能处理社区内的势能场,但无法建模跨社区的势能场。于是本发明提出了宏流量图来描述跨社区的人群流。在跨社区人群流中,双向流和有环流问题仍然存在,因此本发明进一步提出了主次划分和泛多叉树分解算法来解决问题。
[0133]
主次划分算法将其具有较高流量的方向划分为主子图,而将另一个划分为次子图。这样,宏流量图被划分为两个子图。每个子图包含宏流量图的所有结点和单向边。
[0134]
而对于没有双向流的主子图和次子图,本发明提出了泛多叉树算法来将其分解为多个边互不相交的多叉树。
[0135]
该算法的核心思路是应用修改后的kruskal最小生成树算法,kruskal算法包括四
步,第一步将宏流量图的每个结点视为独立树,第二步从宏流量子图逐步地选择两颗独立树的最小权重边,第三步,合并由所选边连接的两颗独立树,第四步,重复第二步和第三步知道宏流子图的所有结点属于同一棵树,就得到了生成树。在这个算法里,本发明设置边的权重为人群流的导数,但是,如果本发明宏流量图的边权重不变,那么kruskal算法每次运行都会产生相同的生成树。为了解决这个问题,本发明在每次运行完kruskal算法后都会动态更新宏流量图的边权重,本发明将第i次运行kruskal算法生成的多叉树表示为e
t
,e
t
的权重为w
uv
,,表示扩展系数,分子和分母分别为最大边权重和最小边权重,则:
[0136][0137]
是一个比例因子,它以指数方式增加由先前多叉树选择的边的权重。这样,本发明可以减少在之前的运行中被多次选择的边缘的选择概率,扩展系数和缩放因子都可以减少多树之间重叠边的数量。
[0138]
为了进一步实施上述技术方案,势能场产生单元的生成势能场的具体内容包括:
[0139]
分解之后得到流量多叉树,两个节点之间的流量大小作为两个节点的势能差,随机选择一个树节点为0势能点,并进一步获得所有节点的势能,从而得到一个流量多树对应的势能场;
[0140]
当势能场中存在负值时,以每个节点的当前势能减去最小节点势能的方式将所有势能值归一化到[0,正无穷)。
[0141]
为了进一步实施上述技术方案,短期相关性建模单元获取短期相关性的具体内容为:
[0142]
使用类rnn网络的gru模型来捕获短期相关性;
[0143]
将任意结点v历史势能场表示为通过gru对历史势能场数据进行循环编码得:
[0144]hvt
=gru(h
v,t-1
,p
v,t
)
[0145]
其中是一个在时间t结点v的隐层时间表示,ks为短期相关性建模单元的隐层表示的维度,s为短期相关性建模单元中输入势能时间序列的长度。
[0146]
为了进一步实施上述技术方案,长期相关性建模单元获取长期相关性的具体内容为:
[0147]
对于长期时间相关性,使用的dcn模型是一个一维卷积模型,但随着隐藏层数量的增加,感受域呈指数级增长。dcn通过在输入中填充0来保留因果顺序,以便当前时间步长的预测只涉及历史信息。
[0148]
采用类cnns的dcn模型来捕获长期相关性;
[0149]
将任意结点v历史势能场表示为过滤器θ∈rr,dcn操作符定义为:
[0150][0151]
其中θi是θ的第i个元素,d表示膨胀因子,l为长期相关性建模单元中输入势能时间序列的长度;
[0152]
本发明将膨胀算子与增加的膨胀因子堆叠在一起,以便感受域呈指数增长。这使本发明的dcn能够以更少的层捕获更长的依赖关系。通过并行采用多个过滤器,dcn可以同时捕获不同的长期依赖关系,从而增强了建模能力。
[0153]
在本实施例中,将3天内的势能序列输入dcn进行长期建模,这样的长期序列通常包含不同时间段的不同模式,例如,在对高峰时间建模时,应该忽略常规时间的模式,反之亦然。为了实现它,本发明引入了一种门控机制来切换dcn中的模式:引入了一种门控机制来切换dcn中的模式:
[0154][0155]
其中是结点v在时间t的势能场长时间表达,σ是sigmoid函数,
⊙
是逐元素乘法,表示可学习的卷积滤波器,n
l
是dcn中的卷积层数目;
[0156]
将长期时间表达c
v,t
与自回归表达h
v,t
进行叠加:nv=[h
v,t
,c
v,t
]作为时间t结点v的最终表达。
[0157]
需要说明的是:
[0158]
城市人群流动预测目标是使用分解后的历史势能场序列来预测未来的城市人群流状态。这里本发明使用了两个步骤,首先先设计了一个时空深度学习模型来预测未来的势能场,其次根据势能场推导未来的城市人群流动。时空深度学习模型是一个相关性自适应时空深度学习模型如图3所示,该模型由一个时间建模组件和空间建模组件组成,在时间建模组件中还包括了两种神经网络结构分别来捕捉短期和长期的时间相关性。
[0159]
为了进一步实施上述技术方案,空间建模组件捕捉空间相关性的具体内容包括:
[0160]
在空间建模组件中,采用图注意力机制gat来捕捉空间相关性,将n
vk
视为势能场中结点v的表达,在时间t,gat方法逐步更新包括所有势能场n
vk
的矩阵
[0161]n(z)
=gat(n
(z-1)
|t)
[0162]
其中z是迭代次数,对每个vk初始化结点表示
[0163]
具体的更新过程,gat设置结点vi和vj的权重为
[0164][0165]
其中α(
·
)为注意力分数,w和w
(
·
)
为可学习参数,表示多叉树结点vi的邻居。然而,在本发明的模型中,pef在对应的多叉树中具有有向图结构,两个多叉树节点(现实中的两个不同位置)之间的空间影响通常是不对称的。为了对该特征进行建模,将加权定向注意机制引入gat:
[0166][0167][0168]
其中分别表示较低势能和较高势能结点vi的邻居;
[0169]
采用多头注意力机制使用注意力生成每个多叉树节点的表示:
[0170][0171]
其中||表示拼接,m是注意力端数目,是由第m个注意力机制计算的归一化注意力分数。
[0172]
将这种延伸过的gat网络命名为pb-gat,因为它的注意力涉及边缘方向和相应多叉树的权重。
[0173]
一种基于时空势能场的城市人群流动预测方法,包括以下步骤:
[0174]
s1.将基于网格的历史城市人群流图分解为多个基于多叉树的历史势能场;
[0175]
s2.捕获历史势能场的短期相关性,引入门控机制来捕获历史势能场的长期相关性,并将短期相关性和长期相关性进行叠加形成时间相关性;
[0176]
s3.将加权定向注意机制以及多头注意力机制引入图注意力机制gat来捕捉空间相关性,并与时间相关性进行融合,融合后的结果输入到mlp中用于输出势能场预测值;
[0177]
s4.根据势能场预测值推导相应的城市人群流图,从而完成城市人群流动预测。
[0178]
下面将通过试验来对本发明进行进一步说明:
[0179]
根据上述过程,本发明建立了一种基于势能场的城市人群流动预测方法名为st-pef+,在实验中,本发明评估了stpef+在三个真实世界数据集上的性能:西安、北京和波尔图出租车数据集。这三个数据集包含原始出租车gps从不同城市采集的具有不同采样间隔(gps间隔)的轨迹。本发明将城市的市区划分为不同大小的区域,并将出租车轨迹映射为区域之间的城市人群流。为了增加实验设置的多样性,本发明为不同的数据集设置了不同的城市人群流采样时间间隔如表1所示。
[0180]
本发明使用了mae、rmse、r2、evar四种评估指标,五类共九个基线模型作为对比。第一类是传统时间序列模型,包括历史平均法(ha)、向量自回归(var)。这种方法将历史城市人群流动序列视为纯时间序列来进行模型,而不考虑空间依赖性。第二类是循环预测模型,包括fc-lstm。。第三类是时空深度模型预测方法,本发明对比了时空深度模型预测方法例如st-resnet和stdn。第四类是基于图的时空方法,本发明对比了传统的基于图的人流预测方法例如stgcn、agcrn。第五类为基于注意力机制的人流预测模型,这里本发明使用了两个传统的模型:stawnet和stfgnn。
[0181]
表1模型结果对比
[0182][0183]
根据表1里的数据,st-pef+显着优于其他基线0.01水平的t检验。这证明了st-pef+在联合使用势能场和相关自适应深度学习方面的有效性。在以分析本发明性能提升的潜在原因具体的预测案例中,st-pef+比其他基线更准确地捕捉高峰时间的趋势。由于高峰时段城市人群流的动态范围很大,准确预测这部分可以显着提高预测性能。在st-pef+中,不同方向的城市人群流被分解成不同的pef,并通过不同的深度学习模型进行建模。通过这种方式,本发明模型的深度学习部分可以更精确地对高峰时段的城市人群流进行建模,这些城市人群流通常由一个方向的城市人群主导。本发明认为这可能是本发明的方法与基线相比具有显着性能改进的一个可能原因。
[0184]
对st-pef进行比较后,st-pef+在rmse中平均将st-pef提高12.4%。该结果验证了高级深度学习模块,例如具有定向注意力的pb-gat和捕获长期模式的门控dcn,对st-pef+的出色性能做出了很大贡献。如果没有改进的时空深度学习模块,即仅使用st-pef,所提出的模型很难超越最新的基线,即stfgn和stawnet,它们是在st-pef模型之后提出的。
[0185]
而基线之间,基于时空的方法往往比传统的时间序列方法和循环方法具有更好的性能,这表明时空依赖建模的有效性。在各种基线中,基于gnn的方法比其他方法具有更好的性能,表明将图信息聚合到城市人群流预测中的合理性。此外,注意力机制被证明在城市人群预测中是有效的。
[0186]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置
而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0187]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1