一种知识点在课程视频片段中定位的方法与流程
1.本发明涉及知识点定位技术领域,尤其涉及一种知识点在课程视频片段中定位的方法。
背景技术:
2.目前针对在线课程学习中的知识点定位视频片段技术,主要依赖视频摘要的提取技术,大多是利用视频每一帧图片之间的像素差异或者镜头分割来合并视频,现有的普遍流程大致如下:针对视频数据抽帧》》对视频聚类(图片相似度或者聚类)》》提取视频摘要》》知识点与摘要的相似度对比定位视频片段;
3.如申请号为:cn201710035223.5的一种提取视频摘要的方法,其包括计算待提取视频段中所有帧图像的hsv直方图;计算出相邻两帧图像的相似性;通过自适应局部双阈值法检测镜头的转换,在存在镜头转换的地方对视频进行切割,最后形成一个镜头集合;采用基于自适应阈值的聚类方法将相似的镜头规整到一个聚类集合中;取一个镜头聚类,进行的关键帧提取;重复s6操作,直到所有的镜头聚类都已完成关键帧提取为止;对获取的关键帧按照时间顺序进行组合,形成最后的视频摘要。
4.但是,过分的依赖视频本身的像素点的合并可能会忽略视频本身带有的文本信息;同时摘要提取的时候利用合并下来的视频片段的所有文本信息作为摘要,忽略了在实际应用场景中是只需要视频标题,而不需要太多的冗余信息。
技术实现要素:
5.本发明是一种应用于学生学习的在线教学平台中,针对视频课程的关键摘要提取的一种方法。先对视频抽帧,对类似帧图片进行合并之后再进行ocr识别,大大降低了ocr识别次数;之后采用自然语言处理技术合并、拆分、合并、去重的方式抽取视频的关键帧主题,保证了准确度的同时,在实际课程学习中快速定位到所学知识点的视频片段。
6.为了实现上述目的,本发明采用了如下技术方案:
7.本发明提供一种知识点在课程视频片段中定位的方法,其特征在于,包括以下步骤:
8.s100.视频抽帧,在给定课程视频的情况下,对视频抽帧,并通过计算连续视频像素余弦相似度,对像素接近的图片进行合并;
9.s200.对合并之后的关键帧ocr结果;
10.s300.关键帧的主题提取,采用分词+词性的方式获取分词结构,再通过摘要中去选取连续关键词合并,并清洗掉停用词和中文前后缀,由此得到关键帧的主题;
11.s400.主题清洗及重构,对关键帧的主题进行去重,利用中文前后缀语法和tf-idf得分进行清洗重构,达到语句连贯的效果;
12.s500.知识点主题相似度定位:利用知识点本身和关键帧主题进行文本比对,按照相似度得分排序,选取相似度最高的视频片段作为知识点教学视频的最终定位。
13.进一步地,所述视频抽帧采用每秒一帧图片的方式进行抽帧。
14.进一步地,所述通过计算连续视频像素余弦相似度,对像素接近的图片进行合并,包括:
15.s110.将每帧图片转成像素矩阵,对矩阵平铺构成向量;
16.s120.计算连续视频像素的余弦相似度,阈值设定0.9进行合并。
17.进一步地,所述对合并之后的关键帧ocr结果,包括:
18.s210.通过裁切的方式将图片按照位置区分成9个空间,;
19.s220.划分9个空间中五个区域的文本信息梯次递补主题备选,按照ocr定位位置最大的比例在哪个区间决定;
20.s230.按照文字的旋转角度、清晰度、位置进行筛选,获取视频关键帧文本的重要内容,用来进一步合并视频信息获取关键帧和关键帧摘要。
21.进一步地,步骤s210中的所述9个空间,分别是左上、中上、右上、左中、中中、右中、左下、中下、右下九个区域。
22.进一步地,步骤s220中的,划分9个空间中五个区域的文本信息依据是按照越靠近中间的文字越是讲解的重点的原则,划分了中上、中中、左上、左中、右中的文本信息。
23.进一步地,步骤s110中,所述图片的像素点数值组成一个n*m的矩阵,转成一维向量,向量长度为n*m。
24.进一步地,所述步骤s210中,所述通过裁切的方式将图片按照位置区分成9个空间的过程具体为:通过把图片,按照边界占比0.24~0.26的方式,把图片分割成九宫格,即左,右、上、下分别占比0.24~0.26,中间部分占比0.48~0.52,划分成左上、中上、右上、左中、中中、右中,左下,中下,右下。
25.进一步地,所述步骤s210中,所述通过裁切的方式将图片按照位置区分成9个空间的过程具体为:通过把图片,按照边界占比0.25的方式,把图片分割成九宫格,即左,右、上、下分别占比0.25,中间部分占比0.5,划分成左上、中上、右上、左中、中中、右中,左下,中下,右下。
26.进一步的,所述tf-idf得分的计算方式如下:
27.tf-idf=tf*idf
28.本发明至少具备以下有益效果:
29.本发明针对目前技术过分依赖视频本身像素点的关键帧合并以及过分依赖ocr文本信息抽取摘要主题的缺陷,造成关键帧抽取不准,摘要在实际业务中不可用的问题,本发明结合像素点的相似度和文本相处理两者的优点,极大的降低了ocr的识别次数的同时,利用合并、识别、合并、清洗、重构的处理思想,巧妙地避开了知识点直接定位视频片段的难度,利用关键帧的主题和知识点的文本相似度很好地解决了在线教育场景中的知识点视频定位的难题。
附图说明
30.为了更清楚地说明本发明实施例技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
31.图1为现有专利cn106851437a的流程图;
32.图2为本发明视频抽帧的流程图;
33.图3为本发明获取视频关键帧文本的示意图;
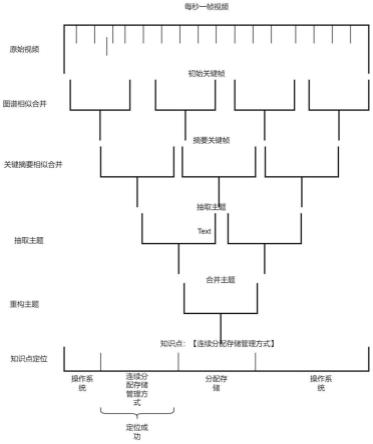
34.图4为本发明方法的流程图。
具体实施方式
35.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
36.本发明是一种应用于学生学习的在线教学平台中,针对视频课程的关键摘要提取的一种方法。先对视频抽帧,对类似帧图片进行合并之后再进行ocr识别,大大降低了ocr识别次数;之后采用自然语言处理技术合并、拆分、合并、去重的方式抽取视频的关键帧主题,保证了准确度的同时,在实际课程学习中快速定位到所学知识点的视频片段。
37.请参阅图4所示,本发明的知识点在视频片段中的定位过程如下:
38.s100.视频抽帧,在给定课程视频的情况下,对视频抽帧,并通过计算连续视频像素余弦相似度,对像素接近的图片进行合并;
39.其中,视频抽帧采用每秒一帧图片的方式进行抽帧;
40.在上述步骤中,通过计算连续视频像素余弦相似度,对像素接近的图片进行合并,包括:
41.先将每帧图片转成像素矩阵,对矩阵平铺构成向量,过程如下:
42.过程如下:图片是由像素点组成,像素点数值组成一个n*m的矩阵,转成一维向量,向量长度为n*m,例如向量为:按列平铺为向量:[1,4,2,5,3,6];
[0043]
然后,计算连续视频像素的余弦相似度,阈值设定0.9进行合并,具体的,就是使得图片内容比较接近,像素接近,内容大致接近的连续帧图片进行合并,
[0044]
s200.对合并之后的关键帧ocr结果;
[0045]
具体的对合并之后的关键帧ocr结果,包括:
[0046]
通过裁切的方式将图片按照位置区分成9个空间,具体过程如下:
[0047]
通过把图片,按照边界占比0.25的方式,把图片分割成九宫格,即左,右、上、下分别占比0.25,中间部分占比0.5,划分成左上、中上、右上、左中、中中、右中,左下,中下,右下;
[0048]
划分9个空间中五个区域的文本信息梯次递补主题备选,按照ocr定位位置最大的比例在哪个区间决定;
[0049]
按照文字的旋转角度、清晰度、位置进行筛选,获取视频关键帧文本的重要内容,用来进一步合并视频信息获取关键帧和关键帧摘要;
[0050]
其中,划分9个空间中五个区域的文本信息依据是按照越靠近中间的文字越是讲解的重点的原则,划分了中上、中中、左上、左中、右中的文本信息。
[0051]
s300.关键帧的主题提取,采用分词+词性的方式获取分词结构,再通过摘要中去选取连续关键词合并,并清洗掉停用词和中文前后缀,由此得到关键帧的主题;
[0052]
s400.主题清洗及重构,对关键帧的主题进行去重,利用中文前后缀语法和tf-idf得分进行清洗重构,达到语句连贯的效果;
[0053]
其中,中文前后缀的清洗是对常用的前后缀比如:*小节、*章、第一*等情况无异议前后缀清洗重构;
[0054]
进一步的,tf-idf得分的计算方式如下:
[0055]
tf-idf=tf*idf
[0056]
得分高表示该词相对于文档的重要性比较高,其中tf是词频,idf是逆文档频率;
[0057]
例如:假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率(idf)的方法是文件集里包含的文件总数除以测定有多少份文件出现过“母牛”一词。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是lg(10,000,000/1,000)=4。最后的tf-idf的分数为0.03*4=0.12;
[0058]
s500.知识点主题相似度定位:利用知识点本身和关键帧主题进行文本比对,按照相似度得分排序,选取相似度最高的视频片段作为知识点教学视频的最终定位。
[0059]
现以图3为参考,给出本技术的一个实施例:
[0060]
本发明的知识点在视频片段中的定位流程大致分四个:视频抽帧、文本相似合并关键帧、关键帧主题提取、主题清洗及重构、知识点主题相似度定位,具体过程如下:
[0061]
首先,请参阅图2所示,进行视频抽帧:在给定课程视频的情况下,对视频抽帧,每秒一帧图片,采用把图片转成像素矩阵,对矩阵平铺构成向量的方式,计算连续视频像素的余弦相似度,阈值设定0.9进行合并;
[0062]
接着,请参阅图3所示,通过文本相似合并关键帧:根据上述合并之后的关键帧ocr结果,把图片按照位置区分成9个空间,分别是左上、中上、右上、左中、中中、右中、左下、中下、右下九个区域,按照教学视频的规律,越靠近中间的文字越是讲解的重点的原则,划分中上、中中、左上、左中、右中的文本信息梯次递补主题备选,按照ocr定位位置最大的比例在哪个区间决定;同时按照文字的旋转角度、清晰度、位置进行筛选,获取视频关键帧文本的重要内容,用来进一步合并视频信息获取关键帧和关键帧摘要,如图3所示,图3中的9个区域中满足条件的文本如下:【以太网帧属性——以太网帧大小】-中上、【以太网的标准和ieee802.3标准将最小的帧定义为】-中中;
[0063]
然后,是关键帧的主题提取:经过图片相似度和文本相似度获取视频关键帧之后,本阶段需要对每个关键帧的主题进行提取,主要思想是采用分词+词性的方式获取分词结构,再去摘要中去选取连续关键词合并,并清洗掉停用词和中文前后缀,由此得到关键帧的主题;
[0064]
接着,进行主题清洗及重构:上述关键帧的主题还是会存在重复或者不可用的情况,因此本阶段是对关键帧的根据主题进行去重,得到区间更大,分段更少的视频关键帧,同时利用中文前后缀语法和tf-idf得分进行清洗重构,达到语句连贯的效果;
[0065]
最后,知识点主题相似度定位:最后利用知识点本身和关键帧主题进行文本比对,按照相似度得分排序,选取相似度最高的视频片段作为知识点教学视频的最终定位。
[0066]
本技术针对目前技术过分依赖视频本身像素点的关键帧合并以及过分依赖ocr文本信息抽取摘要主题的缺陷,造成关键帧抽取不准,摘要在实际业务中不可用的问题,本发
明结合像素点的相似度和文本相处理两者的优点,极大的降低了ocr的识别次数的同时,利用合并、识别、合并、清洗、重构的处理思想,巧妙地避开了知识点直接定位视频片段的难度,利用关键帧的主题和知识点的文本相似度很好地解决了在线教育场景中的知识点视频定位的难题。
[0067]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1