一种基于模糊自引导的结构保护生成对抗网络的方法
1.本发明涉及高质量的医学图像领域,具体为一种基于模糊自引导的结构保护生成对抗网络的方法。
背景技术:
2.医学图像含有大量与生物组织或解剖组织相关的信息,是临床诊断和治疗的重要依据。然而,在实际场景中采集的医学图像通常质量较低。近年来,医学图像增强因其具有较高的实用价值和广泛的应用场景而备受关注。医学图像增强的目的是统一图像亮度,改善图像结构,恢复图像的纹理细节,更清晰地显示图像所表达的特定病理内容。机器学习和计算机视觉技术已成为提高医学图像质量的研究热点。
3.在现有的图像增强方法中,用于提高图像质量的传统技术包括:直方图均衡化、使用小波变换的自适应滤波器、灰度校正等。传统的图像增强方法有一些明显的缺陷,例如导致高质量区域的过度增强和放大噪声。以直方图均衡化为例,采用累积分布函数作为映射函数。该原理简单快速,图像对比度可以直观地提高,但细节保存率低,噪声不可避免地会增强。此外,基于直方图均衡化的方法忽略了图像的不同部分对增强的不同要求,在医学图像处理中存在局限性。近年来,深度学习技术极大地提高了图像增强方法的性能。其中,生成对抗网络(gan)作为经典的无监督网络,被广泛应用于图像增强任务中。用于图像增强的gan通常使用成对图像进行训练。然而,成对的医学图像很难获取,模型的增强效果并不理想,为此本发明提出一种基于模糊自引导的结构保护生成对抗网络系统。
技术实现要素:
4.解决的技术问题
5.针对现有技术的不足,本发明提供一种基于模糊自引导的结构保护生成对抗网络的方法,通过独特设计的模糊判别器来区分输入图像和增强图像在真实域和模糊域中的差异,采用自引导的结构保护模块(ssrm)和光照分布校正模块(idcm),捕获神经纤维的结构信息,并校正图像的光照分布,以解决上述的问题。
6.(二)技术方案
7.为实现上述所述目的,本发明提供如下技术方案:
8.一种基于模糊自引导的结构保护生成对抗网络的方法,包括以下步骤:
9.第一步:利用基于模糊自引导的结构保护生成对抗网络系统中的自引导的结构保护模块探索并保留输入图像的结构信息;
10.第二步:基于光照分布校正模块校正增强图像的照度分布;
11.第三步:基于模糊判别器在模糊域中区分输入图像和增强图像;
12.第四步:采用循环一致性损失以及纹理保真度损失表示损失函数。
13.优选的,基于模糊自引导的结构保护生成对抗网络系统包括两个生成器以及分别与两个生成器连接的模糊判别器,生成器由图像增强模块、自引导的结构保护模块和光照
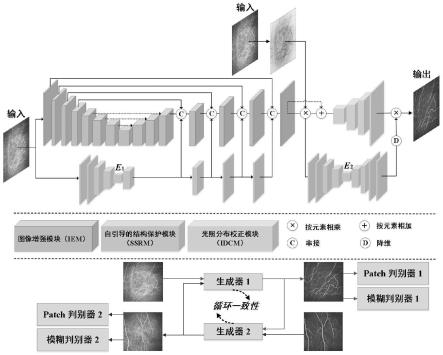
分布校正模块组成,自引导的结构保护模块负责探索医学图像中的神经纤维结构,并在解码期间按比例将特征图添加到主干网络中,光照分布校正模块通过使用低质量输入图像的先验注意图来校正主干网络输出图像的光照分布,使用两个具有相同体系结构的生成器。一个生成器的输出图像将被输入到另一个生成器,达到端到端的自学习。
14.优选的,所述图像增强模块以u-net为主干网络,u-net有八个编码层和八个解码层,编码层由残差卷积模块和最大池化层组成,解码层由上采样模块和残差卷积模块组成,编码层和解码层的残差卷积模块是相同的,包括两个堆叠卷积层+批次归一化层+leakyrelu,其中输入和输出以残差的形式连接。上采样模块是双线性插值上采样层+3
×
3卷积层+批量归一化层+leakyrelu+dropout层的串行结构。
15.优选的,所述自引导的结构保护模块提取的图像结构信息将与u-net的编码特征和前一层的解码特征逐级串联,并注入图像增强模块的解码路径。
16.优选的,所述自引导的结构保护模块用于探索和保留低质量输入图像的结构信息,并指导图像增强模块和光照分布校正模块重建医学图像,自引导的结构保护模块由两个结构相同的编码器-解码器网络组成,编码器由预先训练好的res-net-34初始化。
17.自引导的结构保护模块将原始输入和iem输出压缩到深度语义空间中,然后限制它们之间的距离,使两个阶段的潜在特征表示接近,两个网络的编码特征分别表示为e.1和e.2,并且自引导损失函数可以表示为:
[0018][0019]
其中lq和hq分别代表低质量图像集和高质量图像集。
[0020]
优选的,所述模糊判别器中模糊运算的具体步骤如下:
[0021]
(1)两个输入图像m1和m2分别通过一个1
×
1卷积层以获得相同大小和尺寸的特征图;
[0022]
(2)两个特征图由sigmoid函数进行非线性激活;
[0023]
(3)两个激活的特征图进行模糊和运算,即取同一维度的较小值,最后得到模糊特征图f.
[0024]
上述步骤可以表示为:
[0025]
f=fuzzy and[σ(c(m1)),σ(c(m2))];
[0026]
其中c和σ分别表示卷积层和sigmoid函数;
[0027]
让g
lq
→
hq
和g
hq
→
lq
分别表示高质量图像生成器和低质量图像生成器,fd
hq
和fd
lq
分别表示高质量模糊判别器和低质量模糊判别器,模糊判别器和生成器的损失函数可以表示为:l
adv1
=e
x∈lq
[logfd
lq
(x)]+e
y∈hq
[log(1-fd
lq
(g
hq
→
lq
(y)))]+e
y∈hq
[logfd
hq
(y)]+e
x∈lq
[log(1-fd
hq
(g
lq
→
hq
(x)))];
[0028]
图像块判别器的具体结构它包括3个步长为2的4
×
4卷积层和2个步长为1的4
×
3卷积层,它基于图像块来区分真假,图像块大小设置为50
×
50.同样,图像块判别器和生成器之间的对抗损失可以表示为:
[0029]
l
adv2
=e
x∈lq
[logd
lq
(x)]+e
y∈hq
[log(1-d
lq
(g
hq
→
lq
(y)))]+e
y∈hq
[logd
hq
(y)]+e
x∈lq
[log(1-d
hq
(g
lq
→
hq
(x)))];
[0030]
其中d
hq
和d
lq
分别表示高质量判别器和低质量判别器。
[0031]
最后,fs-gan的对抗损失表示为:
[0032]
l
adv
=l
adv1
+l
adv2
;
[0033]
优选的,所述损失函数包括循环一致损失l
cyc
和身份映射损失l
idt
.循环一致性损失的主要目的是实现低质量域和高质量域之间的相互转换,低质量图像x∈lq被输入到高质量生成器g
lq
→
hq
获取图像增强,然后增强图像被输入到低质量生成器g
hq
→
lq
以尽可能恢复图像,因此,x≈g
hq
→
lq
(g
lq
→
hq
(x)),对于向后循环一致性,y≈g
lq
→
hq
(g
hq
→
lq
(y)),其中y∈hq代表高质量图像,循环一致性损失可表示为:
[0034]
l
cyc
=e
x∈lq
[||g
hq
→
lq
(g
lq
→
hq
(x))-x||1]+e
y∈hq
[||g
lq
→
hq
(g
hq
→
lq
(y))-y||1];
[0035]
身份映射损失可以表示为:
[0036]
l
idt
=e
x∈lq
[||g
hq
→
lq
(x)-x||1]+e
y∈hq
[||g
lq
→
hq
(y)-y||1];
[0037]
纹理保真度损失l
tf
,将图像分为多个图像块进行精细处理和比较,具体表示为:
[0038][0039]
其中yi和xi分别表示高质量图像y和低质量图像x的第i个局部图像块,g
hq
→
lq
(y)i和g
lq
→
hq
(x)i分别表示两个生成的图像的第i个局部图像块,和表示原始图像的第i个图像块和相应生成图像的第i个图像块之间的协方差矩阵,和分别表示yi,g
hq
→
lq
(y)i,xi和g
lq
→
hq
(x)i对应的标准偏差矩阵,c是一个较小的常数,用于避免数值不稳定,p为图像分割成块的数量,值得注意的是,ssrm可以保护全局结构信息,纹理保真度损失l
tf
可以加强局部区域的纹理恢复;
[0040]
结合模糊判别器,fs-gan的损失函数可以表示为:
[0041]
l
fs-gan
=l
adv
+αl
cyc
+βl
idt
+γl
tf
+ηl
enc
;
[0042]
α,β,γ和η分别是循环一致性损失、身份映射损失、纹理保真度损失和自引导损失的权重。
[0043]
(三)有益效果
[0044]
与现有技术相比,本发明提供的基于模糊自引导的结构保护生成对抗网络的方法(fs-gan),具备以下有益效果:
[0045]
1、该基于模糊自引导的结构保护生成对抗网络的方法,开发了一个模糊判别器来区分输入图像和增强图像在真实域和模糊域中的差异,从而提高识别能力并优化增强效果。使用循环一致性损失和纹理保真度损失,使得fs-gan适用于非成对训练的情况,从而图像的内容信息和纹理细节在增强过程中不会迁移和丢失。
[0046]
2、该基于模糊自引导的结构保护生成对抗网络的方法,在生成器中嵌入了自引导的结构保护模块(ssrm),显著提高了网络的特征学习和感知能力,并避免了神经纤维结构被均匀化到背景中的情况。同时,设计了一个光照分布校正模块(idcm),它可以利用先验注意图校正增强图像的照度分布。
[0047]
3、该基于模糊自引导的结构保护生成对抗网络的方法,通过大量的对比实验,包括视觉观察、评价指标和下游任务性能等,将fs-gan与先进的方法进行了比较。实验结果表明,fs-gan具有最佳的增强性能,能够适应非成对医学图像增强。
附图说明
[0048]
图1为本发明实施例对抗网络方法的模块组成结构与流程示意图;
[0049]
图2为本发明实施例对抗网络方法的模糊判别器的结构与流程示意图;
[0050]
图3为本发明实施例对抗网络方法的不同方法增强图像纹理结构的比较示意图;
[0051]
图4为本发明实施例对抗网络方法的不同方法增强图像的光照分布比较示意图;
[0052]
图5为本发明实施例对抗网络方法的不同方法增强图像分割结果的比较示意图;
[0053]
图6为本发明实施例对抗网络方法的ssrm和idcm的有效性分析示意图;
[0054]
图7为本发明实施例对抗网络方法的模糊判别器的有效性分析示意图。
具体实施方式
[0055]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0056]
实施例
[0057]
本发明实施例提供的基于模糊自引导的结构保护生成对抗网络的方法,提供高质量的医学图像为医生作为临床诊断和治疗的重要依据,其包括以下步骤:
[0058]
第一步:基于自引导的结构保护模块探索并保留输入图像的结构信息;
[0059]
第二步:基于光照分布校正模块校正增强图像的照度分布;
[0060]
第三步:基于模糊判别器在模糊域中区分输入图像和增强图像;
[0061]
第四步:采用循环一致性损失以及纹理保真度损失表示损失函数。
[0062]
具体的,请参阅图1-7,为了获得纹理结构清晰、对比度均衡的高质量医学图像,本发明提供的基于模糊自引导的结构保护生成对抗网络的方法,构建了一种模糊自引导的结构保护生成对抗网络系统(fs-gan)。fs-gan的架构如图1所示,它嵌入了ssrm和idcm,以更好地捕获光纤结构细节和图像的均匀光照分布。自我引导机制和循环一致性使其可以用于非成对训练。此外,fs-gan结合模糊理论,分别在真实域和模糊域区分低质量输入图像和高质量增强图像,从而提高增强图像的质量。下文详细描述了fs-gan的重要组成部分。
[0063]
图1为本发明实施例提供的基于模糊自引导的结构保护生成对抗网络的方法的生成器结构示意图。该生成器由三个模块组成,分别是图像增强模块(iem)、自引导的结构保护模块(ssrm)和光照分布校正模块(idcm)。ssrm负责探索医学图像中的神经纤维结构,并在解码期间按比例将特征图添加到主干网络中。idcm通过使用低质量输入图像的先验注意图来校正主干网络输出图像的光照分布。循环一致性如上所示,使用两个具有相同体系结构的生成器。一个生成器的输出图像将被输入到另一个生成器,以实现端到端的自学习。
[0064]
图像增强模块
[0065]
u-net能够充分提取图像的多层特征,在医学图像分割和重建领域表现优异。因此,本发明的图像增强模块(iem)以u-net为主干网络。具体来说,u-net有八个编码层和八个解码层。编码层由残差卷积模块和最大池化层组成,解码层由上采样模块和残差卷积模块组成。具体结构如表1所示。从表1可以看出,编码层和解码层的残差卷积模块是相同的,包括两个堆叠卷积层+批次归一化层+leakyrelu。其中输入和输出以残差的形式连接。上采
样模块是双线性插值上采样层+3
×
3卷积层+批量归一化层+leakyrelu+dropout层的串行结构。
[0066]
自引导的结构保护模块(ssrm)提取的图像结构信息将与u-net的编码特征和前一层的解码特征逐级串联,并注入iem的解码路径,以引导iem更好地学习和恢复纹理细节。
[0067]
表1:主干网络的具体结构:它包括8个编码层和8个解码层,其中ic表示输入维度,oc表示输出维度。
[0068][0069]
自引导的结构保护模块
[0070]
当使用gan增强图像时,通常希望模型生成具有不同背景的图像,而忽略了对输入图像的全局结构和局部细节的保护。然而,作为医生诊断的基础,医学图像所表达的具体结构细节应该是非常重要的。一些神经纤维结构的丢失将导致诊断错误和病理描述失真。当前的一些单通道方法在增强过程中不注重区分背景和前景,这导致一些神经纤维被均匀化到背景中。
[0071]
为解决这一问题,本发明设计了自引导的结构保护模块(ssrm)。它可用于探索和保留低质量输入图像的结构信息,并指导iem和光照分布校正模块(idcm)重建医学图像。从图1可以看出,ssrm由两个结构相同的编码器-解码器网络组成。编码器由预先训练好的res-net-34初始化。第一个编码器-解码器网络的每个解码操作器提取的信息通过跳转连接注入到u-net,以引导iem恢复纹理细节。另一个编码器-解码器网络负责校正iem输出的光照分布。受多阶段细化工作的启发,本发明将两个编码器-解码器网络设计为顺序细化和相互指导。首先,ssrm将原始输入和iem输出压缩到深度语义空间中,然后限制它们之间的距离,使两个阶段的潜在特征表示接近。这两个网络的编码特征分别表示为e
·1和e
·2,并且自引导损失函数可以表示为:
[0072][0073]
其中lq和hq分别代表低质量图像集和高质量图像集。自引导的设计可以很好地解决未配对的任务,这样输入图像的细节不会被错误迁移,并且原始结构信息将被保留。此外,前后两个模块在端到端的基础上相互学习和指导,有利于图像重建。
[0074]
光照分布校正模块
[0075]
对于光照分布不平衡的低质量医学图像,可以增强暗区,以便在视觉上与亮度正常的其他区域保持一致。受正则化研究的启发,本发明将原始输入图像的光照通道标准化为[0,1]以获得i,然后将1-i作为注意力图a,为idcm纠正光照分布提供先验知识。idcm的输入是iem输出和a之间的残差,经过四个3
×
3卷积块。值得一提的是,虽然这有助于提高光照的均匀性,但在此过程中对比度会降低,并且很容易丢失一些重要的纹理细节,本发明所提供的ssrm可以抑制idcm,以确保神经纤维结构的完整性。
[0076]
模糊判别器
[0077]
gan的工作原理是在对抗中对生成器和判别器进行优化。判别器的性能越好,生成器就可以生成更高质量的图像。为了进一步提高模型的判别能力,本发明设计了一种模糊判别器。模糊判别器的结构如图2所示。其工作原理是使用四个卷积块提取特征后,通过模糊运算将输入图像投影到模糊域中,从而减少了增强图像与真实高质量图像之间的差异,进一步增加了判别的难度。
[0078]
模糊运算的具体步骤如下:
[0079]
(1)两个输入图像m1和m2分别通过一个1
×
1卷积层以获得相同大小和尺寸的特征图;
[0080]
(2)两个特征图由sigmoid函数进行非线性激活;
[0081]
(3)两个激活的特征图进行模糊和运算,即取同一维度的较小值,最后得到模糊特征图f.
[0082]
上述步骤可以表示为:
[0083]
f=fuzzy and[σ(c(m1)),σ(c(m2))]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0084]
其中c和σ分别表示卷积层和sigmoid函数。
[0085]
让g
lq
→
hq
和g
hq
→
lq
分别表示高质量图像生成器和低质量图像生成器,fd
hq
和fd
lq
分别表示高质量模糊判别器和低质量模糊判别器。模糊判别器和生成器的损失函数可以表示为:
[0086]
l
adv1
=e
x∈lq
[logfd
lq
(x)]+e
y∈hq
[log(1-fd
lq
(g
hq
→
lq
(y)))]+
[0087]ey∈hq
[logfd
hq
(y)]+e
x∈lq
[log(1-fd
hq
(g
lq
→
hq
(x)))]
ꢀꢀꢀꢀ
(3)
[0088]
图像块判别器的具体结构包括3个步长为2的4
×
4卷积层和2个步长1的4
×
3卷积层,它基于图像块来区分真假。图像块大小设置为50
×
50.同样,图像块判别器和生成器之间的对抗损失可以表示为:
[0089]
l
adv2
=e
x∈lq
[logd
lq
(x)]+e
y∈hq
[log(1-d
lq
(g
hq
→
lq
(y)))]+
[0090]ey∈hq
[logd
hq
(y)]+e
x∈lq
[log(1-d
hq
(g
lq
→
hq
(x)))]
ꢀꢀꢀꢀ
(4)
[0091]
其中d
hq
和d
lq
分别表示高质量判别器和低质量判别器。
[0092]
最后,fs-gan的对抗损失表示为:
[0093]
l
adv
=l
adv1
+l
adv2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0094]
损失函数
[0095]
作为一个双向gan框架,fs-gan适用于非成对训练,包括两个基本损失项:循环一致损失l
cyc
和身份映射损失l
idt
.循环一致性损失的主要目的是实现低质量域和高质量域之间的相互转换。对于前面的增强任务,低质量图像x∈lq被输入到高质量生成器g
lq
→
hq
获取图像增强,然后增强图像被输入到低质量生成器g
hq
→
lq
去尽可能恢复图像,因此,x≈g
hq
→
lq
(g
lq
→
hq
(x))。同样,对于向后循环一致性,最好是y≈g
lq
→
hq
(g
hq
→
lq
(y)),其中y∈hq代表高质量图像。因此,循环一致性损失可以被表示为:
[0096]
l
cyc
=e
x∈lq
[||g
hq
→
lq
(g
lq
→
hq
(x))-x||1]+e
y∈hq
[||g
lq
→
hq
(g
hq
→
lq
(y))-y||1]
ꢀꢀꢀ
(6)
[0097]
身份映射损失是为了确保生成器的专一性,即当将同一域的图像输入到生成器时,应执行身份映射。身份映射损失可以表示为:
[0098]
l
idt
=e
x∈lq
[||g
hq
→
lq
(x)-x||1]+e
y∈hq
[||g
lq
→
hq
(y)-y||1]
ꢀꢀꢀꢀꢀꢀ
(7)
[0099]
在校正医学图像的光照分布时,一些对医学诊断很重要的前景结构可能被均匀化
到背景中,这不是图像增强的初衷。虽然传统的结构相似性损失综合考虑了亮度、对比度和结构,但它仅基于全局视角对图像进行比较,较为粗糙,特别是对于医学图像。低质量医学图像的每个区域的增强难度和要求是不同的。一些背景区域不需要重点关注,而一些区域需要重点关注。本发明采用纹理保真度损失l
tf
,将图像分为多个图像块进行精细处理和比较,具体表示为:
[0100][0101]
其中yi和xi分别表示高质量图像y和低质量图像x的第i个局部图像块。g
hq
→
lq
(y)i和g
lq
→
hq
(x)i分别表示两个生成的图像的第i个局部图像块。和表示原始图像的第i个图像块和相应生成图像的第i个图像块之间的协方差矩阵。和分别表示yi,g
hq
→
lq
(y)i,xi和g
lq
→
hq
(x)i对应的标准偏差矩阵。c是一个较小的常数,用于避免数值不稳定。p为图像分割成块的数量。值得注意的是,ssrm可以保护全局结构信息,纹理保真度损失l
tf
可以加强局部区域的纹理恢复。
[0102]
最后,fs-gan的损失函数可以表示为:
[0103]
l
fs-gan
=l
adv
+αl
cyc
+βl
idt
+γl
tf
+ηl
enc
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0104]
其中α,β,γ和η分别是循环一致性损失、身份映射损失、纹理保真度损失和自引导损失的权重。
[0105]
实验例
[0106]
实验设置
[0107]
实验数据集
[0108]
实验在已发布的角膜共焦显微镜(ccm)数据集corn-2上进行。corn-2包含688张共焦显微图像,大小为384
×
384.两位专业人员将这些图像分为高质量图像和低质量图像进行训练,分别为340张和288张。此外,还有60幅低质量图像可供测试。其中,低质量共焦图像的特点是低对比度、斑点噪声和非均匀光照。
[0109]
比较算法
[0110]
为了证明fs-gan的优越性能,选择了一些sota方法进行比较实验,包括两种传统方法clahe和dcp,以及五种深度学习方法nst、msg net、enlightengan、cyclegan和stillgan.这些方法适用于非配对训练,其相关参数设置参考原始论文和发布的代码。为了公平比较,这五种深度学习方法使用与fs-gan相同的数据预处理过程。
[0111]
图像质量评估
[0112]
定性分析
[0113]
在本节中,我们使用视觉观察来定性分析生成图像的质量,并评估纹理结构的完整性和光照分布的合理性。
[0114]
从图3可以看出,原始低质量图像的纹理细节相对模糊,不利于医学诊断。clahe和dcp这两种传统方法对角膜共焦图像纹理结构的改善非常有限,而六种基于深度学习的方法表现得更好。在所有的图像中,本发明方法生成的图像不仅具有清晰的整体结构,而且能够恢复最完整的纹理细节,是八种方法中最好的。
[0115]
从图4可以看出,原始低质量图像的光照分布非常不均匀,有些地方曝光过度,而有些地方很暗,掩盖了许多重要的病理信息。尽管依赖于先验信息的dcp和enlightingan在
一定程度上调节了光照分布,但它们在某些过度曝光区域很难发挥良好的增强效果。总体而言,stillgan和fs-gan(本发明方法)生成的图像的光照分布与高质量图像的光照分布最接近,更均匀,更适合临床诊断。如果放大局部区域,本发明方法不仅可以调整光照分布,还可以在这过程中恢复一些纹理细节。从上述分析可以看出,本发明方法增强纹理细节的能力最强,其生成的图像与人的视觉最为一致。
[0116]
表2:不同方法增强图像质量在5个评价指标的比较。在这些图像质量评价指标中,entropy和avg为正指标,brisque、niqe和piqe为负指标。
[0117] entropy
↑
avg
↑
brisque
↓
niqe
↓
piqe
↓
original4.743
±
0.0955.137
±
1.3020.498
±
0.16528.939
±
5.0979.498
±
2.248clahe6.964
±
0.9836.935
±
0.1680.492
±
0.01125.622
±
3.86910.655
±
2.427dcp5.565
±
0.0417.327
±
0.2170.532
±
0.20722.601
±
6.00211.494
±
2.479nst5.897
±
0.5376.547
±
0.0840.492
±
0.00227.687
±
3.04522.044
±
3.575msg-net6.583
±
0.0966.544
±
0.0430.493
±
0.01131.863
±
5.2352.289
±
0.227cyclegan6.479
±
0.2136.511
±
0.2140.508
±
0.02730.104
±
3.5632.658
±
0.324enlightengan6.229
±
1.0786.695
±
0.3380.487
±
0.11626.290
±
4.6907.098
±
1.974stillgan6.546
±
0.3996.587
±
0.1250.492
±
0.00131.649
±
4.2461.861
±
0.165本发明方法6.785
±
0.1387.332
±
0.0240.484
±
0.00528.107
±
6.0731.774
±
0.235
[0118]
定量分析
[0119]
为了定量分析图像质量,本发明使用了5个指标来评估图像质量,包括entropy、avg、brisuqe、niqe和piqe。
[0120]
表2显示了每张增强图像的评价指标值。在所有方法中,本发明方法的avg、brisque和piqe是最好的,分别比排在第二的方法高0.005、0.008和0.087,这表明本发明方法生成的图像质量最高。
[0121]
应用效果评估
[0122]
定性分析
[0123]
医学图像的应用价值也是衡量其质量的一种方法。因此,本发明使用cs-net分割每个增强图像,并通过每个方法的分割性能评估其增强效果。从图5可以看出,由于光照不均和结构模糊等因素,低质量图像的分割效果很差,这反映在神经纤维难以识别和延续。从fs-gan(本发明方法)生成的图像中分割出的神经纤维结构具有很强的连续性,并且最接近真实情况。本发明方法可以解决一些区域的错误分割问题,大大提高了医学图像的后续应用价值。
[0124]
定量分析
[0125]
每张增强图像的分割评估指标值如表3所示。其中,本发明方法的六个分割指标值均显著高于其他方法,分割效果最好。可以认为,本发明方法增强图像的质量和应用价值最高。
[0126]
表3:不同方法增强图像分割指标的比较。这些分割指标都是正的,即值越大,分割效果越好。
[0127] aucaccuracysensitivityg-meankappadiceoriginal0.603
±
0.0460.953
±
0.0500.231
±
0.1000.467
±
0.1090.287
±
0.1020.291
±
0.102clahe0.613
±
0.0410.960
±
0.0100.248
±
0.8780.488
±
0.0970.316
±
0.0940.320
±
0.095
dcp0.649
±
0.0460.955
±
0.0100.324
±
0.0980.561
±
0.0890.398
±
0.0980.402
±
0.099nst0.645
±
0.0510.958
±
0.0160.330
±
0.1090.565
±
0.1000.383
±
0.1040.388
±
0.105msg-net0.616
±
0.0640.949
±
0.0050.266
±
0.1410.493
±
0.1400.314
±
0.1130.332
±
0.114cyclegan0.675
±
0.0820.962
±
0.0110.411
±
0.2030.623
±
0.1210.382
±
0.0960.396
±
0.142enlightengan0.661
±
0.0550.959
±
0.0130.363
±
0.1110.593
±
0.0970.387
±
0.1030.392
±
0.104stillgan0.698
±
0.0660.987
±
0.0030.453
±
0.1290.662
±
0.1050.409
±
0.1250.415
±
0.125本发明方法0.731
±
0.0480.988
±
0.0010.518
±
0.0970.713
±
0.0840.451
±
0.1830.452
±
0.095
[0128]
消融研究
[0129]
为了验证fs-gan(本发明方法)组件的有效性,本发明进行了两个消融实验。
[0130]
首先,本发明以iem为主干网络,将ssrm和idcm分别嵌入到网络中,验证这两个模块用于图像增强的必要性和有效性。图6显示了每个消融方案的增强图像。可以看出,嵌入ssrm后,生成的图像的神经纤维结构更加完整。idcm显著校正了光照分布,其生成的图像更适合临床诊断。因此,可以说,ssrm和idcm发挥了各自的作用。
[0131]
同样,也验证了模糊判别器的效果。从图7可以看出,嵌入模糊判别器后,fs-gan(本发明方法)可以在某些区域抑制噪声,如第一列和第二列中的虚线框所示。fs-gan增强图像的视觉效果最好,表明模糊判别器可以有效地增强模型的判别能力。
[0132]
为了生成高质量的医学图像,本发明实施例提出了一种模糊自引导的结构保护生成对抗网络系统(fs-gan),它可以应用于非配对数据的训练。特别的是,本发明开发了一种模糊判别器在模糊域中区分真实图像和生成的图像,可以提高模型的增强性能。此外,还设计了自引导的结构保护模块(ssrm)和光照分布校正模块(idcm),以自引导的方式捕获神经纤维的结构信息,并校正图像的光照分布,提高视觉效果。对比实验结果表明,fs-gan可以显著提高医学图像的质量,并在下游应用任务中表现良好,可以为医生的临床诊断和治疗提供强有力的支持。
[0133]
图中:
[0134]
图1:本文方法的结构。生成器由三个模块组成,分别是图像增强模块(iem)、自引导的结构保护模块(ssrm)和光照分布校正模块(idcm)。ssrm负责探索医学图像中的神经纤维结构,并在解码期间按比例将特征图添加到主干网络中。idcm通过使用低质量输入图像的先验注意图来校正主干网络输出图像的光照分布。循环一致性如上所示,使用两个具有相同体系结构的生成器。一个生成器的输出图像将被输入到另一个生成器,以实现端到端的自学习。
[0135]
图2:模糊判别器的结构。与传统的判别器不同,模糊判别器嵌入一个模糊运算单元来融合输入图像和相应的深度特征,即将输入图像投影到模糊域中进行真假判别。
[0136]
图3:不同方法增强图像纹理结构的比较。第一行、第三行和第五行是完整的图像,第二行、第四行和第六行分别是第一行、第三行和第五行中用红色框起的区域的放大图像。从左到右的图像是原始图像,clahe、dcp、nst、msg net、cyclegan、enlighten gan、stillgan和fs-gan(本发明方法)。
[0137]
图4:不同方法增强图像的光照分布比较。第一行、第三行和第五行是完整的图像,第二行、第四行和第六行分别是第一行、第三行和第五行中用红色框起的区域的放大图像。从左到右的图像是原始图像,clahe、dcp、nst、msg net、cyclegan、enlighten gan、stillgan和fs-gan(本发明方法)。
[0138]
图5:不同方法增强图像分割结果的比较。第一行、第三行和第五行是增强的图像,第二行、第四行和第六行是分别对应于第一行、第三行和第五行的分割图像。从左到右的图像是原始图像、clahe、dcp、nst、msg net、cyclegan、enlighten gan、stillgan、fs-gan(本发明方法)和groundtruth。
[0139]
图6:ssrm和idcm的有效性分析。第一行、第三行是完整图像,第二行、第四行分别是第一行和第三行中用红色框起的区域的放大图像。从左到右的图像是原始图像、backbone(主干网络)、with ssrm、with idcm和fs-gan(本发明方法)。
[0140]
图7:模糊判别器的有效性分析。第一列和第二列是带噪声图像,第四列是将第三列中的红色框的局部图像块放大。图像自上而下为fs-gan(本发明方法),-fuzzyd(不采用模糊判别器的网络)和原始图像。
[0141]
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1