场景数据获取方法、装置、设备及存储介质与流程
本技术属于自动驾驶,尤其涉及一种场景数据获取方法、装置、设备及存储介质。
背景技术:
1、近年来,随着自动车辆的数量不断增加,导致的车辆事故也不断增加;但是,由于事故数据较难获得,自车车主或其它车主难以直观地了解到事故的原因,也无法根据已经发生的事故学习如何规避风险,并导致了大量的事故数据浪费;因此,自车或其它车主在后续的驾驶过程中仍然无法对已经导致事故的事故场景进行规避,所以,往往会因为相同的原因,继续产生多起交通事故。
技术实现思路
1、本技术旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本技术的一个目的在于提出一种场景数据获取方法、装置、设备及存储介质。
2、为了解决上述技术问题,本技术的实施例提供如下技术方案:
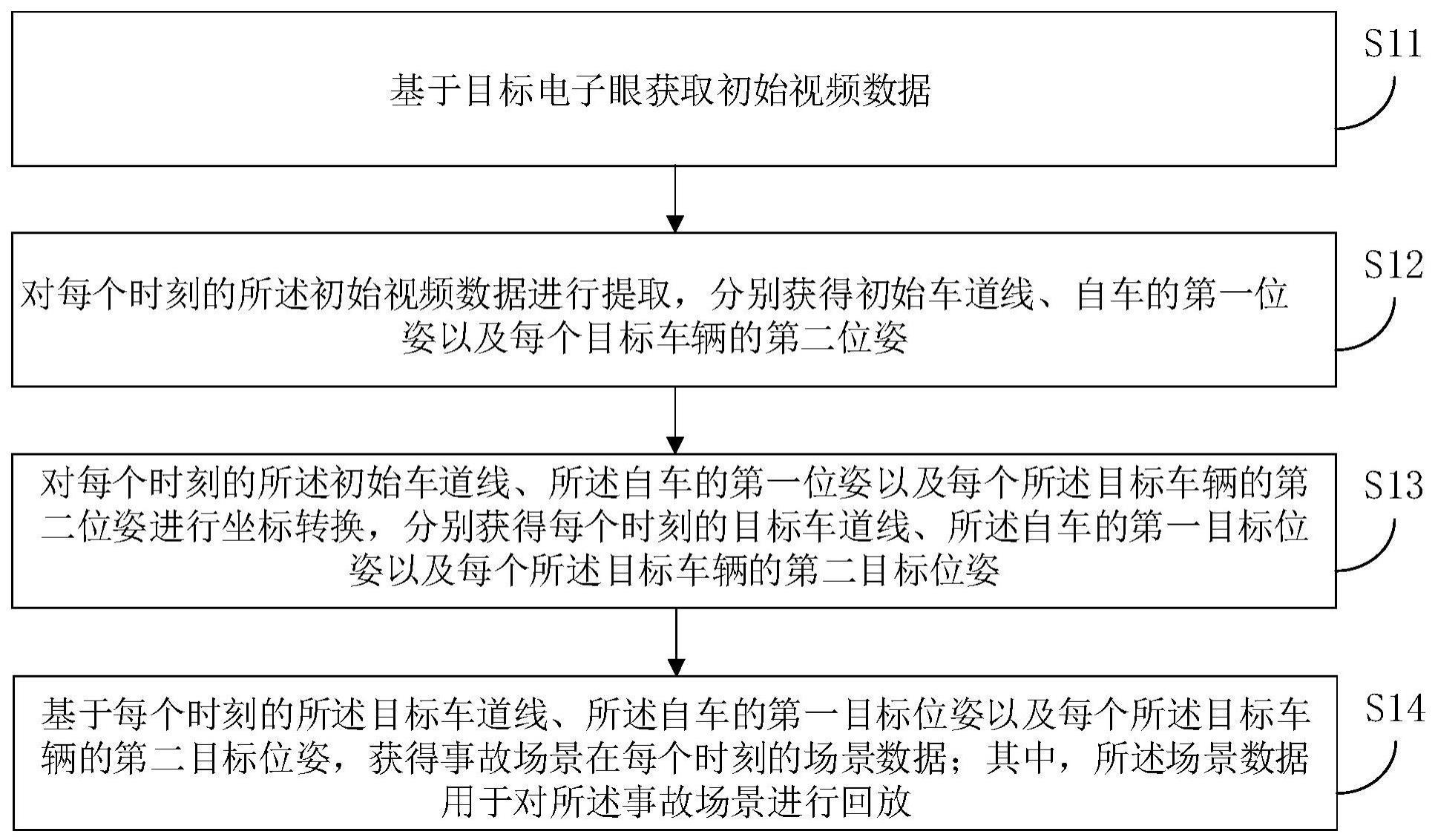
3、一种场景数据获取方法,包括:
4、基于目标电子眼获取初始视频数据;
5、对每个时刻的所述初始视频数据进行提取,分别获得初始车道线、自车的第一位姿以及每个目标车辆的第二位姿;
6、对每个时刻的所述初始车道线、所述自车的第一位姿以及每个所述目标车辆的第二位姿进行坐标转换,分别获得每个时刻的目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿;
7、基于每个时刻的所述目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿,获得事故场景在每个时刻的场景数据;其中,所述场景数据用于对所述事故场景进行回放。
8、可选的,所述对每个时刻的所述初始车道线、所述自车的第一位姿以及每个所述目标车辆的第二位姿进行坐标转换,分别获得每个时刻的目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿,包括:
9、获得坐标转换参数;
10、基于所述坐标转换参数对每个时刻的所述初始车道线进行第一坐标转换,获得每个时刻的所述目标车道线;基于所述坐标转换参数对所述自车的第一位姿进行第二坐标转换,获得所述自车在每个时刻的所述第一目标位姿;基于所述坐标转换参数对每个所述目标车辆的第二位姿进行第三坐标转换,获得所述目标车辆在每个时刻的所述第二目标位姿。
11、可选的,在所述获得每个时刻的目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿之后,还包括:
12、对第t个时刻的所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿和第t+1个时刻的所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿进行匹配,确定第t+1个时刻的所述自车的第一观测目标位姿以及每个所述目标车辆的第二观测目标位姿;其中,t≥0;
13、基于目标跟踪算法对第t个时刻的所述自车的第一目标位姿、每个所述目标车辆的第二目标位姿、第t+1个时刻的所述自车的第一观测目标位姿以及每个所述目标车辆的第二观测目标位姿,分别获得第t+1个时刻的所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿;
14、基于每个时刻的所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿,分别获得所述自车在每个时刻的第一轨迹点以及每个所述目标车辆在每个时刻的第二轨迹点。
15、可选的,在所述获得所述自车在每个时刻的第一轨迹点以及每个所述目标车辆在每个时刻的所述第二轨迹点之后,还包括:
16、基于所述自车在的多个所述第一轨迹点,计算获得所述自车在每个时刻的第一速度;并基于所述自车在每个时刻的所述第一速度,计算获得所述自车在每个时刻的第一加速度;
17、基于每个所述目标车辆的多个所述第二轨迹点,计算获得每个所述目标车辆在每个时刻的第二速度;并基于每个所述目标车辆在每个时刻的所述第二速度,计算获得每个所述目标车辆在每个时刻的第二加速度。
18、可选的,所述基于每个时刻的所述目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿,获得事故场景在每个时刻的场景数据,包括:
19、基于每个时刻的所述目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿,获得所述事故场景在每个时刻的第一子场景数据;
20、基于每个时刻的所述自车的第一速度以及第一加速度与每个所述目标车辆的第二速度以及第二加速度,获得所述事故场景在每个时刻的第二子场景数据;
21、基于每个时刻的所述第一子场景数据以及第二子场景数据,获得所述事故场景在每个时刻的所述场景数据。
22、可选的,还包括:
23、基于所述自车在每个时刻的第一速度以及第二加速度,计算获得所述自车在每个时刻的第一动作状态;基于每个所述目标车辆在每个时刻的所述第二速度以及第二加速度,计算获得每个所述目标车辆在每个时刻的第二动作状态。
24、可选的,所述基于每个时刻的所述第一子场景数据以及第二子场景数据,获得所述事故场景在每个时刻的所述场景数据,包括:
25、基于每个时刻的所述第一子场景数据、第二子场景数据、第一动作状态以及第二动作状态,获得所述事故场景在每个时刻的所述场景数据。
26、本技术的实施例还提供一种场景数据获取装置,包括:
27、获取模块,用于基于目标电子眼获取初始视频数据;
28、提取模块,用于对每个时刻的所述初始视频数据进行提取,分别获得初始车道线、自车的第一位姿以及每个目标车辆的第二位姿;
29、获得模块,用于基于每个时刻的所述初始车道线、所述自车的第一位姿以及每个所述目标车辆的第二位姿,分别获得每个时刻的目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿;
30、回放模块,用于基于每个时刻的所述目标车道线、所述自车的第一目标位姿以及每个所述目标车辆的第二目标位姿,获得事故场景在每个时刻的场景数据;其中,所述场景数据用于对所述事故场景进行回放。
31、本技术的实施例还提供一种电子设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的方法。
32、本技术的实施例还提供一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如上所述的方法。
33、本技术的实施例,具有如下技术效果:
34、本技术的上述技术方案,1)本技术的实施例,基于目标电子眼,实现了获得任意一个事故场景的初始视频数据,基于对初始视频数据的提取,获得事故场景在每个时刻对应的场景数据,进而实现了基于目标电子眼提供的初始视频数据对任意一个事故场景的场景数据的收集,并基于事故场景对应的场景数据对事故场景进行还原,解决了事故场景的数据难于获得的问题,同时提高了事故场景对应的数据的利用率;此外,也便于自动驾驶系统对事故场景的学习,并获得自动驾驶系统在相同场景下的表现,降低了自动驾驶系统发生事故的概率,提高了自动驾驶的安全性。
35、2)在获得事故场景发生时间或近事故场景发生时间的初始视频数据之后,对初始视频数据的每帧图像进行信息提取,包括每个时刻的初始车道线、自车的第一位姿以及每个目标车辆的第二位姿,并对每个时刻的初始车道线、自车的第一位姿以及每个目标车辆的第二位姿进行坐标转换,获得每个时刻的目标车道线、自车的第一目标位姿以及每个目标车辆的第二目标位姿,并最终获得事故场景在每个时刻的场景数据,然后通过每个时刻的场景数据对相关的事故场景进行回放,以便于测试或供自动驾驶系统学习,进而降低事故发生的概率。
36、本技术附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本技术的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!