一种基于纸质作业的自动批阅方法及设备与流程
1.本技术涉及图像识别领域,尤其涉及一种基于纸质作业的自动批阅方法及设备。
背景技术:
2.现阶段的作业批阅环节存在着许多问题,教师作业批改耗时长、重复性高,尤其是填空题、简答题等题型,具有耗时长,效率低的问题,对老师而言是沉重的教学负担。而学生在完成作业时,容易让他们养成缺漏、缺交、抄袭等坏习惯。
3.现有的作业中主观题的批阅,一般是教师亲自批阅并统计分数,批改效率低下,需要耗费大量的时间与精力去进行批阅统分,难以方便快捷的对成绩进行统计分析,给教师增添了教学负担。
技术实现要素:
4.本技术实施例提供了一种基于纸质作业的自动批阅方法及设备,用于解决如下技术问题:在现有的教师批阅纸质作业中,主观题的批改时间长,重复性高,难以快速进行成绩的统计分析,使主观题的批改效率低下。
5.本技术实施例采用下述技术方案:一方面,本技术实施例提供了一种基于纸质作业的自动批阅方法,所述方法包括:获取纸质作业的图像数据;提取所述图像数据中的三通道图片,并通过所述三通道图片中通道的像素值,得到红笔批阅区域;对所述红笔批阅区域进行笔迹类型的识别,得到红笔痕迹信息;将所述红笔痕迹信息与所述图像数据中的习题作答区域进行面积交集的判分处理,得到作业成绩。
6.本技术实施例通过对主观题的图像识别、智能分析、快速统计,实现了主观题的快速统计分析。通过对主观题的自动批阅统分,提升了教师的批改效率,并且在不改变教师批改习惯的前提下,大大减少了对纸质作业批改并统计分数的时间,实现了对填空题、简答题等主观题的正误统计,还能快速统计这些题目的分数以及可视化呈现统计结果,减轻了老师批阅作业的负担。并且基于采集的作业批改图片进行的图形识别和批改规则的匹配,实现了纸质作业中主观题评阅数据的快速高效的采集与统计。
7.在一种可行的实施方式中,获取纸质作业的图像数据,具体包括:通过预设扫描仪,对已批阅的纸质作业进行图像扫描,得到初步扫描图像;对所述初步扫描图像进行预览回调,得到所述初步扫描图像的图像存储路径;将所述图像存储路径进行文件流转换处理,得到转换后的图像位图;其中,所述图像数据至少包括:图像位图信息、作业二维码信息、学生信息、底图信息以及批阅区域信息。
8.在一种可行的实施方式中,在将所述图像存储路径进行文件流转换处理,得到转换后的图像位图之后,所述方法还包括:对所述图像数据中的作业二维码信息进行识别判断;若所述图像数据中纸质作业的第一面作业二维码信息识别失败,则将所述第一面作业二维码信息进行数据保存,并对所述纸质作业的第二面作业二维码信息进行识别;若所述
第二面作业二维码信息识别成功,则通过所述第二面作业二维码信息进行反向推理处理,得到反推的第一面作业二维码信息;若所述第二面作业二维码信息识别失败,则将识别失败的第一面作业二维码信息以及第二面作业二维码信息输入到后端服务器中,以完成对所述纸质作业的识别;通过识别成功的作业二维码信息,获取所述作业二维码中的作业信息;其中,所述作业信息至少包括:作业名称以及学生列表。
9.本技术实施例通过对作业两面二维码的识别,提高了识别的准确性,大大降低了对纸质作业误判的概率。
10.在一种可行的实施方式中,提取所述图像数据中的三通道图片,并通过所述三通道图片中通道的像素值,得到红笔批阅区域,具体包括:通过opencv库,提取所述图像数据中图像位图信息的三通道图像;其中,所述三通道图像包括r通道、g通道以及b通道;将所述三通道图像中r通道的像素值与所述b通道的像素值进行相减,得到第一像素值差值;将所述第一像素值差值与所述g通道的像素值进行相减,得到第二像素差值,并将所述第二像素差值进行bool值转换,得到第一bool值数组;通过所述r通道的像素值,对所述b通道的像素值以及所述g通道的像素值分别进行比例计算,并将得到的比例计算结果分别进行bool值转换,得到第二bool值数组以及第三bool值数组;其中,所述第二bool值数组与所述b通道所对应,所述第三bool值数组与所述g通道所对应;将所述第一bool值数组、所述第二bool值数组以及所述第三bool值数组进行像素区域的交集获取,得到像素交集区域;其中,所述像素交集区域不包括红色像素区域;对所述像素交集区域进行红色像素区域的反向获取,得到所述红笔批阅区域。
11.在一种可行的实施方式中,对所述像素交集区域进行红色像素区域的反向获取,得到所述红笔批阅区域,具体包括:通过 dbscan聚类算法,对所述红笔批阅区域进行坐标计算,得到所述红笔批阅区域的红色区域坐标;将所述红色区域坐标进行封装处理,并将封装处理后的红色区域坐标存储在后端数据库的列表中。
12.在一种可行的实施方式中,对所述红笔批阅区域进行笔迹类型的识别,得到红笔痕迹信息,具体包括:获取所述红笔批阅区域中红笔批阅笔迹的笔迹类型,并将所述笔迹类型整合为红笔数据集;其中,所述笔迹类型至少包括:全对笔迹、半对笔迹、全错笔迹、涂抹笔迹以及空白笔迹;通过人工智能模型中的shufflenet算法,对所述红笔数据集进行分类识别训练,得到训练后的人工智能模型;其中,所述人工智能模型的训练输入量为所述红笔数据集,训练输出量为识别后的笔迹类型;通过训练后的人工智能模型,对所述红笔批阅区域进行笔迹类型的识别,得到红笔痕迹信息。
13.本技术实施例通过教师作业痕迹处理规则,来对人工智能模型进行训练,在不改变教师批改作业的习惯下,改变人工智能模型的识别方法,大大提高了对红笔痕迹信息的正确识别,快速准确的统计学生做题的正误情况。
14.在一种可行的实施方式中,在将所述红笔痕迹信息与所述图像数据中的习题作答区域进行面积交集的判分处理之前,所述方法还包括:通过sift算法和akaze算法,将所述图像数据中的底图信息与纸质作业的原始图片信息进行特征匹配,并根据预览回调中的warpaffine函数,将特征匹配后的特征结果进行仿射变化处理,得到仿射变换矩阵;通过所述仿射变换矩阵,对所述底图信息中的图片进行纠正调整,得到纠正后底图;通过dbscan算法和numpy库,对所述纠正后底图的习题作答区域进行定位坐标计算,得到习题作答区域定
位坐标。
15.在一种可行的实施方式中,将所述红笔痕迹信息与所述图像数据中的习题作答区域进行面积交集的判分处理,得到作业成绩,具体包括:将所述红笔批阅区域的红色区域坐标与所述习题作答区域的习题作答区域定位坐标进行坐标交集处理,得到交集面积;对所述交集面积进行数值判断;若所述交集面积的面积数值大于10,则所述红笔批阅区域中的红笔痕迹信息属于所述习题作答区域,并识别判断出所述红笔痕迹信息在所述习题作答区域下所对应的题目分值;统计若干习题作答区域下的所述题目分值,得到所述纸质作业的作业成绩。
16.在一种可行的实施方式中,在统计若干习题作答区域下的所述题目分值,得到所述纸质作业的作业成绩之后,所述方法还包括:对所述图像数据中的学生信息进行识别;其中,所述学生信息至少包括:学生本人二维码、数字区域、手写学生考号以及学生姓名;对所述学生本人二维码进行识别判断若通过预览回调中的qrcodedetector,对所述学生本人二维码的识别结果为失败状态,则对所述数字区域的数字进行识别判断;若所述数字区域的数字识别结果为失败状态,则通过shufflenet算法训练的预设手写学号识别模型,对所述手写学生考号的截图信息进行识别判断;若所述截图信息的识别结果为失败状态,则通过crnn算法训练的预设手写文字的模型,对所述学生姓名进行文字内容识别判断;若所述文字内容的识别结果为失败状态,则将所述学生信息输入到人工处理数据库中;若所述学生信息的识别结果为成功状态,则将所述纸质作业的作业成绩与所述学生信息进行对应匹配,并将匹配结果输入到后端数据库中进行数据存储。
17.另一方面,本技术实施例还提供了一种基于纸质作业的自动批阅设备,包括:至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有能够被所述至少一个处理器执行的指令,以使所述至少一个处理器能够执行上述任一实施例所述的一种基于纸质作业的自动批阅方法。
18.本技术实施例提供了一种基于纸质作业的自动批阅方法及设备,通过对主观题的图像识别、智能分析、快速统计,实现了主观题的快速统计分析。通过对主观题的自动批阅统分,提升了教师的批改效率,并且在不改变教师批改习惯的前提下,大大减少了对纸质作业批改并统计分数的时间,实现了对填空题、简答题等主观题的正误统计,还能快速统计这些题目的分数以及可视化呈现统计结果,减轻了老师批阅作业的负担。并且基于采集的作业批改图片进行的图形识别和批改规则的匹配,实现了纸质作业中主观题评阅数据的快速高效的采集与统计。
附图说明
19.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。在附图中:图1为本技术实施例提供的一种基于纸质作业的自动批阅方法流程图;图2为本技术实施例提供的一种系统整体结构流程图;图3为本技术实施例提供的一种纸质作业处理流程示意图;
图4为本技术实施例提供的一种二维码信息识别示意图;图5为本技术实施例提供的一种纸质作业的图像数据示意图;图6为本技术实施例提供的一种红笔痕迹的错题不判规则示意图;图7为本技术实施例提供的一种红笔痕迹的对题不判规则示意图;图8为本技术实施例提供的一种全对判断示意图;图9为本技术实施例提供的一种全错判断示意图;图10为本技术实施例提供的一种半对错判断示意图;图11为本技术实施例提供的一种学生成绩统计分析示意图;图12为本技术实施例提供的一种重点问题讲解教学示意图;图13为本技术实施例提供的一种基于纸质作业的自动批阅设备的结构示意图。
具体实施方式
20.为了使本技术领域的人员更好地理解本技术中的技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本说明书实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都应当属于本技术保护的范围。
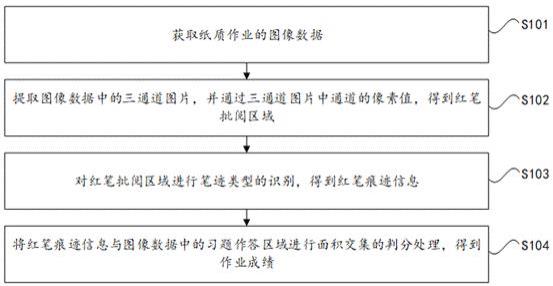
21.本技术实施例提供了一种基于纸质作业的自动批阅方法,如图1所示,基于纸质作业的自动批阅方法具体包括步骤s101-s104:s101、获取纸质作业的图像数据。
22.具体地,通过预设扫描仪,对已批阅的纸质作业进行图像扫描,得到初步扫描图像。对初步扫描图像进行预览回调,得到初步扫描图像的图像存储路径。将图像存储路径进行文件流转换处理,得到转换后的图像位图。其中,图像数据至少包括:图像位图信息、作业二维码信息、学生信息、底图信息以及批阅区域信息。
23.在一个实施例中,图2为本技术实施例提供的一种系统整体结构流程图,图3为本技术实施例提供的一种纸质作业处理流程示意图,如图2及图3所示,学生通过教师布置的纸质作业进行答题,然后再由教师用红笔对主观题进行批改,之后根据每个厂商提供的sdk开始扫描方法,驱动扫描仪,扫描批阅的纸质作业,扫描完成以后,在服务器中通过预览回调(previecallback)方法获取图片的存储路径。然后通过文件流转换将图片路径转换成图像位图(bitmap)。其中,位图为使用像素阵列(pixel-array/dot-matrix点阵)来表示的图像。
24.进一步地,对图像数据中的作业二维码信息进行识别判断。若图像数据中纸质作业的第一面作业二维码信息识别失败,则将第一面作业二维码信息进行数据保存,并对纸质作业的第二面作业二维码信息进行识别。若第二面作业二维码信息识别成功,则通过第二面作业二维码信息进行反向推理处理,得到反推的第一面作业二维码信息。
25.进一步地,若第二面作业二维码信息识别失败,则将识别失败的第一面作业二维码信息以及第二面作业二维码信息输入到后端服务器中,以完成对纸质作业的识别。
26.进一步地,通过识别成功的作业二维码信息,获取作业二维码中的作业信息。其中,作业信息至少包括:作业名称以及学生列表。
27.在一个实施例中,图4为本技术实施例提供的一种二维码信息识别示意图,如图4所示,拿到bitmap以后通过二维码识别技术获取作业中二维码的信息。
28.获取二维码信息过程中当第一面作业二维码信息识别失败,先本地保存失败信息。当第二面作业二维码信息识别成功时,通过第二面作业二维码信息就可以反推出第一面作业二维码信息。当两面二维码都识别失败,再上传到后端服务器进行识别。
29.在一个实施例中,识别成功以后,通过作业二维码信息可以获取作业信息,如作业名称、学生列表。然后将作业信息中的二维码信息拼接成一个字符串,将对应纸质作业的图像数据上传到服务端。当服务端阅卷完成以后,扫描仪通过sdk方法获取阅卷是否完成的状态,并将该状态进行外部显示。
30.s102、提取图像数据中的三通道图片,并通过三通道图片中通道的像素值,得到红笔批阅区域。
31.具体地,通过opencv库,提取图像数据中图像位图信息的三通道图像。其中,三通道图像包括r通道、g通道以及b通道。将三通道图像中r通道的像素值与b通道的像素值进行相减,得到第一像素值差值。将第一像素值差值与g通道的像素值进行相减,得到第二像素差值,并将第二像素差值进行bool值转换,得到第一bool值数组。
32.进一步地,通过r通道的像素值,对b通道的像素值以及g通道的像素值分别进行比例计算,并将得到的比例计算结果分别进行bool值转换,得到第二bool值数组以及第三bool值数组。其中,第二bool值数组与b通道所对应,第三bool值数组与g通道所对应。
33.进一步地,将第一bool值数组、第二bool值数组以及第三bool值数组进行像素区域的交集获取,得到像素交集区域。其中,像素交集区域不包括红色像素区域。对像素交集区域进行红色像素区域的反向获取,得到红笔批阅区域。
34.其中,通过 dbscan聚类算法,对红笔批阅区域进行坐标计算,得到红笔批阅区域的红色区域坐标。将红色区域坐标进行封装处理,并将封装处理后的红色区域坐标存储在后端数据库的列表中。
35.在一个实施例中,图5为本技术实施例提供的一种纸质作业的图像数据示意图,如图5所示,通过对图像数据中图像位图信息的三通道图像进行像素差值计算,得到第一bool值数组、第二bool值数组以及第三bool值数组,然后提取以上三者的交集(交集不包含红色的像素区域),然后反取红色的区域。再利用 dbscan聚类算法,将红色批阅区域的红色区域坐标封装在列表中,已确定出红笔批阅区域中红笔痕迹的具体坐标位置。
36.s103、对红笔批阅区域进行笔迹类型的识别,得到红笔痕迹信息。
37.具体地,获取红笔批阅区域中红笔批阅笔迹的笔迹类型,并将笔迹类型整合为红笔数据集。其中,笔迹类型至少包括:全对笔迹、半对笔迹、全错笔迹、涂抹笔迹以及空白笔迹。
38.进一步地,通过人工智能模型中的shufflenet算法,对红笔数据集进行分类识别训练,得到训练后的人工智能模型。其中,人工智能模型的训练输入量为红笔数据集,训练输出量为识别后的笔迹类型。通过训练后的人工智能模型,对红笔批阅区域进行笔迹类型的识别,得到红笔痕迹信息。
39.需要说明的是,通过预设的作业批改规则以及采集到的红笔数据集对人工智能模型进行识别训练之前,教师的作业批改痕迹应满足(1)上传的图片必须为彩色,(2)客观题
不需要老师判,系统自动批改,(3)填空题、简答题,老师的红笔批改必须落在学生答题区域内,(4)相邻题目的批改痕迹不能有重叠,(5)从左上到右下的斜杠会判定为全错,(6)从左下到右上的斜杠不进行判断,(7)空白区域为全对,(8)“x”为全错,(9)半对为题目分值的一半,其他分值使用分数栏。
40.在一个实施例中,图6为本技术实施例提供的一种红笔痕迹的错题不判规则示意图,如图6所示,可根据认为预设的评判规则对笔迹类型进行判断,并通过以下的预设规则对人工智能模型进行优化分类训练,以实现对红笔痕迹信息的识别,例如:未批的填空题按全错笔迹处理,填空题一道小题下有多个空的,部分已批部分未批时:已批的只有全错笔迹,未批的按全错笔迹处理;已批的只有半对笔迹,未批的按全错笔迹处理;已批的有全错笔迹和涂抹笔迹,未批的按全错笔迹处理;已批的有空白笔迹和涂抹笔迹的,未批的按空白笔迹处理;已批的有空白笔迹和全错笔迹,未批的按全错笔迹处理;已批的有空白笔迹、全错笔迹、涂抹笔迹,未批的按全错处理。对于主观题来说,主观题判分识别优先级:划分条 》 答题区;如果划分条没划分,答题区也没有判分(没打对错),按全错笔迹处理;只有对答题区内识别红笔,判分区红笔会处理成黑笔;同一道题内空白笔迹、全错笔迹、半对笔迹,出现一个以上,识别结果随机;只有涂抹按全错笔迹处理;未批按全错笔迹处理。
41.在一个实施例中,图7为本技术实施例提供的一种红笔痕迹的对题不判规则示意图,如图7所示,还可以根据对题不判的预设规则对人工智能模型进行优化分类训练,以实现对红笔痕迹信息的识别,例如:未批的填空题按空白笔迹处理;填空题一道小题下有多个空的,部分已批部分未批时:已批的只有空白笔迹,未批的按空白笔迹处理;已批的只有全错笔迹,未批的按空白笔迹处理;已批的只有半对笔迹,未批的按空白笔迹处理;已批的有全错笔迹和涂抹笔迹,未批的按空白笔迹处理;已批的有空白笔迹和涂抹笔迹的,未批的按空白笔迹处理;已批的有空白笔迹和全错笔迹,未批的按空白笔迹处理;已批的有空白笔迹、全错笔迹、涂抹笔迹,未批的按空白笔迹处理。对于主观题来说,主观题判分识别优先级:划分条 》 答题区;如果划分条没划分,答题区也没有判分(没打对错),按空白笔迹处理;只有对答题区内识别红笔,判分区红笔会处理成黑笔;同一道题内空白笔迹、全错笔迹、半对笔迹,出现一个以上,识别结果随机;只有涂抹按空白笔迹处理;未批按空白笔迹处理。
42.s104、将红笔痕迹信息与图像数据中的习题作答区域进行面积交集的判分处理,得到作业成绩。
43.具体地,通过sift算法和akaze算法,将图像数据中的底图信息与纸质作业的原始图片信息进行特征匹配,并根据预览回调中的warpaffine函数,将特征匹配后的特征结果进行仿射变化处理,得到仿射变换矩阵。通过仿射变换矩阵,对底图信息中的图片进行纠正调整,得到纠正后底图。
44.进一步地,通过dbscan算法和numpy库,对纠正后底图的习题作答区域进行定位坐标计算,得到习题作答区域定位坐标。
45.进一步地,将红笔批阅区域的红色区域坐标与习题作答区域的习题作答区域定位坐标进行坐标交集处理,得到交集面积。对交集面积进行数值判断。若交集面积的面积数值大于10,则红笔批阅区域中的红笔痕迹信息属于习题作答区域,并识别判断出红笔痕迹信息在习题作答区域下所对应的题目分值。
46.进一步地,统计若干习题作答区域下的题目分值,得到纸质作业的作业成绩。
47.在一个实施例中,图8为本技术实施例提供的一种全对判断示意图,如图8所示,当识别出红笔痕迹信息属于习题作答区域,进行题目的分值计算,如果学生答案全部正确,则老师在答题区域打对钩后,全部题目结果统计为为正确,并得到该题目的分数。图9为本技术实施例提供的一种全错判断示意图,如图9所示,如果学生答案全部错误,那么教师可以统一在答题区域打叉,统计全部题目为错误,得到该题目的分数。图10为本技术实施例提供的一种半对错判断示意图,如图10所示,如果学生答题正确,部分错误,那么会分别识别正确或错误的题目正误情况,并建立和题目的对应关系,统计出所有题的正误情况,并得到该题目的分数。最后对所有的题目分数进行统计,得到该纸质作业的作业成绩。
48.进一步地,对图像数据中的学生信息进行识别。其中,学生信息至少包括:学生本人二维码、数字区域、手写学生考号以及学生姓名。
49.进一步地,对学生本人二维码进行识别判断。若通过预览回调中的qrcodedetector,对学生本人二维码的识别结果为失败状态,则对数字区域的数字进行识别判断。
50.进一步地,若数字区域的数字识别结果为失败状态,则通过shufflenet算法训练的预设手写学号识别模型,对手写学生考号的截图信息进行识别判断。
51.进一步地,若截图信息的识别结果为失败状态,则通过crnn算法训练的预设手写文字的模型,对学生姓名进行文字内容识别判断。
52.进一步地,若文字内容的识别结果为失败状态,则将学生信息输入到人工处理数据库中。
53.若学生信息的识别结果为成功状态,则将纸质作业的作业成绩与学生信息进行对应匹配,并将匹配结果输入到后端数据库中进行数据存储。
54.作为一种可行的实施方式,根据扫描过来图像数据中的学生信息,通过预览回调(opencv)自带qrcodedetector方法来识别学生本人二维码。当识别不出学生本人二维码时,通过yolo算法检测数字区域的位置,根据数字区域的坐标截取数字区域识别数字,由于存在扫描图片倒置的情况,导致截取的数字图片颠倒,通过对数字的识别结果判断是否颠倒,如果颠倒会将图片旋转重新识别;由于扫描图片上有三个数字区域,模型会对这三个数字区域进行识别,依据识别的结果和概率值,根据规则提取最终结果。通过识别出来数字或二维码来判断是否存在学生信息,当不存在学生信息时,通过手写学生考号定位学生,截取学生手写的学号区域图片,通过shufflenet算法训练手写学号的模型,识别学号定位学生信息,当考号定位不出学生时,通过手写学生姓名定位学生,截取学生手写姓名的区域的图片,通过(该模型识别常用文字1952个)识别学生的名字,当以上都定位不出时,上传到人工处理数据库中,实现人工的处理。
55.在一个实施例中,当得到学生纸质作业的作业成绩,图11为本技术实施例提供的一种学生成绩统计分析示意图,如图11所示,教师可以基于日常作业的快速统计结果,查看全班的成绩统计,快速掌握本班学生的针对相应的内容的掌握情况。图12为本技术实施例提供的一种重点问题讲解教学示意图,如图12所示,对于课堂上重点讲学生错误率高的内容,教师可以对存在问题的学生出现的问题进行重点讲解,实现基于学生错题数据的精准教学。
56.另外,本技术实施例还提供了一种基于纸质作业的自动批阅设备,如图13所示,基
于纸质作业的自动批阅设备130具体包括:至少一个处理器131。以及,与至少一个处理器131通信连接的存储器132;其中,存储器132存储有能够被至少一个处理器131执行的指令,以使至少一个处理器131能够执行:获取纸质作业的图像数据;提取图像数据中的三通道图片,并通过三通道图片中通道的像素值,得到红笔批阅区域;对红笔批阅区域进行笔迹类型的识别,得到红笔痕迹信息;将红笔痕迹信息与图像数据中的习题作答区域进行面积交集的判分处理,得到作业成绩。
57.另一方面,本技术还提供了一种基于纸质作业的自动批阅方法,包括:步骤s101:扫描仪扫描采集并识别出具有特定排版方式的纸质作业介质上的红笔判分痕迹(红笔痕迹信息)识别出来,并转换为红笔判分痕迹识信息;步骤s102:根据红笔痕迹信息对主观题答题结果进行自动判分。
58.其中,所述步骤s101:扫描仪扫描采集并识别出具有特定排版方式的纸质作业介质上的红笔判分痕迹识别出来并转换为红笔判分痕迹识信息,包括:步骤s1011:扫描仪扫描1. 根据每个厂商提供的sdk开始扫描方法,驱动扫描仪,扫描作业。
59.2. 扫描完成以后,通过预览回调(previecallback)方法获取图像存储路径。
60.3. 然后通过文件流转换将图片路径转换成bitmap(图像位图:使用像素阵列(pixel-array/dot-matrix点阵)来表示的图像)。
61.步骤s1012:作业二维码信息识别1. 拿到bitmap以后通过二维码识别技术获取作业中二维码的信息。
62.2. 获取二维码信息过程中当第一面二维码识别失败,先本地保存失败信息。当第二面识别二维码信息成功时,通过第二面的二维码信息就可以反推出第一面的二维码信息。当两面二维码都识别失败,上传到服务器进行识别。
63.纸质作业的正反面均包含二维码信息;识别成功以后,通过二维码的信息可以获取作业信息,如作业名称、学生列表。然后将作业信息二维码信息拼接成一个字符串,将对应图片上传到服务端。
64.其中,获取阅卷结果的方式为:当阅卷完成以后,扫描仪通过sdk方法获取阅卷是否完成的状态,并将状态进行显示。
65.步骤s1013:定位学生(这一步骤是为后续识别出成绩,赋值给某个学生做准备)根据扫描过来图片,通过opencv自带qrcodedetector方法来识别二维码,当识别不出二维码时,通过yolo算法检测数字区域的位置,根据数字区域的坐标截取数字区域识别数字,由于存在扫描图片倒置的情况,导致截取的数字图片颠倒,通过对数字的识别结果判断是否颠倒,如果颠倒会将图片旋转重新识别;由于扫描图片上有三个数字区域,模型会对这三个数字区域进行识别,依据识别的结果和概率值,根据规则提取最终结果。通过识别出来数字或二维码来判断是否存在学生信息,当不存在学生信息时,通过学生手写考号定位学生,截取学生手写的学号区域图片,通过shufflenet算法训练手写学号的模型,识别学
号定位学生信息,当考号定位不出学生时,通过手写学生姓名定位学生,截取学生手写姓名的区域的图片,通过crnn算法训练手写文字的模型(该模型识别常用文字1952个)识别学生的名字,以上都定位不出时,提交给人工处理。
66.步骤s1014:提取红笔区域(为了定位到红笔区域,识别红笔做准备)利用opencv 读取三通道(bgr)图片,用r通道的像素值分别减去b通道和g通道的像素值,转换bool值数组,计算r通道的像素值与bg两通道的像数值的比例转换为bool值数组,提取以上三者(第一bool值数组、第二bool值数组以及第三bool值数组)的交集(交集不包含红色的像素区域),然后反取红色的区域,得到红笔批阅区域。利用 dbscan聚类算法,将获取独立红色区域的坐标(红色区域坐标)封装在列表中。
67.步骤s1015:使用人工智能识别上一步定位出来的红笔区域(红笔批阅区域),使用人工智能模型识别出结果;利用shufflenet算法对红笔数据集进行分类训练识别红色笔迹的对(全对笔迹),半对(半对笔迹),错(全错笔迹),涂抹(涂抹笔迹),空白(空白笔迹)。
68.步骤s1016:定位习题作答区域(找到习题的范围)根据底图(图像数据中的底图信息)和试卷通过sift和akaze算法特征匹配,阵通过opencv的warpaffine函数进行仿射变化,获取仿射变换矩,并纠正图片(纠正后底图);通过dbscan算法和numpy操作对坐标(习题作答区域定位坐标)进行调整定位。
69.所述步骤s102:根据红笔痕迹信息对主观题答题结果进行自动判分,包括:计算每个红笔区域的坐标(红色区域坐标)与答题区域的坐标(题作答区域定位坐标)的交集部分,其中,当计算交集部分的面积(交集面积)大于10,视为红色笔迹(红笔痕迹信息)属于该题,并将红色笔记的识别结果赋值(题目分数)给该题(首先获取每道习题的分数,然后通过识别结果来赋值给该题具体分数,最后得到纸质作业的作业成绩)。
70.本技术实施例提供了一种基于纸质作业的自动批阅方法及设备,应用扫描仪快速采集教师评阅主观题信息,可实现批量主观题批阅并实现快速统计。应用人工智能技术实现教师批阅信息的快速采集。将教师主观题批阅的正误数据进行快速统计。减轻教师在完成日常作业时,批阅半主观题和主观题工作时的负担,提升教师批阅效率,让老师可以快速看到全班同学的主观题答题成绩。教师可一目了然地了解全班学生及某些学生的的主观题答题情况。
71.应用高清扫描仪及配套的软件系统,通过教师批阅信息采集、批阅信息处理、分析统计、作业数据可视化呈现,实现学生日常作业中的主观题和半主观题的信息快速采集及统计,教师可以基于这些信息,对日常作业中有问题的题目进行整理,针对性地帮助学生理清学习难点,在课堂教学中基于学生的问题针对性地讲解难点内容,为学生提供高效的教学支持。
72.本技术中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于设备、非易失性计算机存储介质实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
73.上述对本技术特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行
并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
74.以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术的实施例可以有各种更改和变化。凡在本技术实施例的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1