一种青霉素发酵过程关键变量软测量方法及系统
1.本发明涉及软测量领域,特别地,涉及一种青霉素发酵过程关键变量软测量方法及系统。
背景技术:
2.青霉素作为一种重要的抗生素,有着非常广泛的应用。青霉素发酵过程具有非线性、时变性和不确定性的特点。为了实现对青霉素发酵过程的优化控制和产品质量的提高,迫切需要对青霉素发酵过程进行在线软测量。青霉素浓度是发酵过程中重要的质量指标之一,准确测量青霉素浓度对青霉素发酵过程的优化控制和产量的提高有着重要的作用和指导意义。
3.然而,目前对青霉素浓度的在线分析测量很难做到,一方面是青霉素浓度传感器测量成本很高,离线化验耗时较长,另一方面是生产环境复杂,测量到的数据存在很多污染和干扰,这些难点导致给青霉素发酵过程的优化控制和产量的提高带来了困难,成为青霉素发酵过程中急需解决的一个瓶颈问题。从而对青霉素浓度的在线软测量仪表及方法研究成为了学术界和工业界的一个研究热点。
技术实现要素:
4.发明目的:针对上述现有技术中存在的问题,本发明提供了一种青霉素发酵过程关键变量软测量方法及系统,利用增强型灰狼优化算法(agwo)对深度学习模型深度信念极限学习机软测量模型进行优化,计算速度快、准确度高。
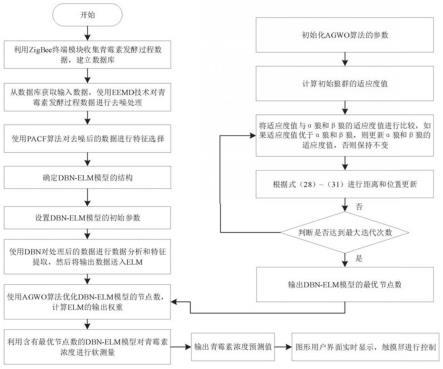
5.技术方案:本发明提供一种青霉素发酵过程关键变量软测量方法,包括如下步骤:
6.步骤1:实时收集青霉素发酵过程中产生的变量,建立数据库;
7.步骤2:从数据库中获取输入变量利用集成经验模态分解eemd进行去噪处理;
8.步骤3:对去噪处理后的变量利用pacf算法进行特征选择,构建最优输入特征集合;
9.步骤4:利用步骤3中最优输入特征集合建立软测量模型,将处理好的输入变量送入构建的软测量模型中进行训练;所述软测量模型为基于深度信念神经网络dbn和极限学习机模型elm的dbn-elm模型;
10.步骤5:引入增强型灰狼优化算法agwo对软测量模型的参数进行优化,输出最优参数,利用优化后的软测量模型进行预测,输出青霉素浓度预测结果。
11.进一步地,所述步骤2利用集成经验模态分解eemd进行去噪处理,包括如下步骤:
12.步骤2.1:在原始信号x(t)中加入均值为0、方差为常数的高斯白噪声n(t),得到新的信号如下式:
13.xm(t)=x(t)+nm(t)
ꢀꢀ
(1)
14.式中,xm(t)表示第m次加入的高斯白噪声的信号,nm(t)表示第m次加入的高斯白噪声;
15.步骤2.2:对xm(t)分别进行emd分解,得到一系列imf分量和残差分量,分别记其为k
mn
和rm(t);其中,k
mn
表示第m次加入高斯白噪声后,分解所得到的第n个imf分量;
16.步骤2.3:每次加入不同的白噪声,重复上述步骤2.1和2.2,得到下式:
[0017][0018]
步骤2..4:对上述结果进行总体平均运算,消除多次加入高斯白噪声对真实imf分量的影响,最后得到imf分量表达式如下:
[0019][0020]
进一步地,所述步骤3利用pacf算法进行特征选择的具体过程如下:
[0021]
步骤3.1:假设ym(t)为输出变量,如果第s个延时时刻的pacf值在95%置信区间之外,则y
m-s
(t)取其中一个为输入变量;如果所有延时时刻的pacf值均在95%置信区间内,则取y
m-1
(t)作为输入变量;
[0022]
步骤3.2:对于长度为n的imf子序列{y1(t),y2(t),...,yn(t)},由协方差γs得延时s协方差得估计值:
[0023][0024]
式中,表示序列得平均值,n/4为最大时延时刻;
[0025]
步骤3.3:由步骤3.2,得自相关函数(acf)估计值表示如下:
[0026][0027]
步骤3.4:基于式(4)和(5),pacf计算式如下:
[0028][0029]
根据pacf值,判断不同辅助变量与关键变量得相关性,构建最优输入特征集合。
[0030]
进一步地,所述步骤4中建立软测量模型的具体步骤如下:
[0031]
步骤4.1:建立深度信念神经网络dbn,dbn神经网络由多个受限玻尔兹曼机rbn堆叠组成,通过无监督逐层贪婪训练,将数据映射到高维空间;rbn由可见层v和隐藏层h组成,其中可见层v负责接收输入数据,隐含层h提取特征;
[0032]
步骤4.2:构建elm极限学习机模型,elm由输入层、隐藏层和输出层构成;
[0033]
步骤4.3:整合dbn神经网络与elm,建立dbn-elm模型;在所使用的dbn-elm模型中,dbn模型由四层受限玻尔兹曼机rbm组成,采用无监督的贪婪方式对数据集训练后提取特征,然后将第四层的rbm中的隐藏层输出作为elm输入层,训练dbn-elm模型。
[0034]
进一步地,所述步骤4.1中使用rbm训练过程如下:
[0035]
步骤4.1.1:采用无监督逐层贪婪方式初始化rbm层之间的连接权重和偏移量,然
后每层rbm从下到上训练,累计多个rbm形成dbn神经网络模型;
[0036]
步骤4.1.2:假设rbm的可见层v和隐藏层h的神经元均为二进制,则其能量函数定义如下:
[0037][0038]
式中,θ={w
ij
,ai,bj},为rbm的参数,由实数表示;a和b分别表示可见层v和隐藏层h的偏置,w是权重矩阵;
[0039]
步骤4.1.3:计算联合概率分布函数p(v,h)如下式:
[0040][0041]
式中,z
θ
=∑∑e-e(v,h|θ)
,表示归一化因子;
[0042]
步骤4.1.4:每个可见层v变量和隐藏层h变量被激活的条件概率如下式所示:
[0043]
p(vi=1|h)=σ(ai+∑jw
ijhj
)
ꢀꢀꢀꢀ
(9)
[0044]
p(hj=1|v)=σ(bj+∑iw
ij
vi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0045]
式中,σ为sigmoid函数,计算式如下:
[0046][0047]
步骤4.1.5:通过求解训练集的最大对数似然估计函数可以得到参数的估计,并利用对比散度(cd)算法得到rbm参数更新准则,具体计算式如下:
[0048]
δw
ij
=ε(《v
ihj
》
e-《v
ihj
》r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0049]
δai=ε(《vi》
e-《vi》r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0050]
δbj=ε(《hj》
e-《hj》r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0051]
式中,ε表示学习率,《
·
》e表示训练数据的数学期望,《
·
》r表示重构模型的数学期望。
[0052]
进一步地,所述步骤4.2中构建elm极限学习机模型具体步骤为:
[0053]
步骤4.2.1:给定t个训练集其中x
t
为输入向量,o
t
为期望输出向量,对于包含有l个隐含层激活函数为s(x)的极限学习机数学模型可以表示为:
[0054][0055]
其中,w
l
为第l个隐含层神经元和输入层的权重,b
l
表示第l个隐含节点的偏差,β
l
为连接第1隐含层神经元和输出层的权值;
[0056]
步骤4.2.2:对极限学习机数学模型进行简写,得到下式:
[0057]
hβ=o
ꢀꢀ
(16)
[0058]
其中,h为隐含层输出层矩阵,具体表达式如下:
[0059][0060]
步骤4.2.3:由输出权值的求解是保证损失函数取得最小值,则有下式:
[0061]
[0062]
其中输出权值β可由下式得到:
[0063][0064]
进一步地,所述步骤5中agwo算法具体实现步骤如下:
[0065]
步骤5.1:设置gwo算法的初始参数,包括训练次数种群大小和迭代次数,搜索空间的上下边界;
[0066]
步骤5.2:包围猎物阶段,gwo算法数学模型为:
[0067][0068][0069]
表示灰狼的位置向量,表示猎物的位置向量;和为系数向量,其计算表达式如下:
[0070][0071][0072][0073]
式中,t为当前迭代次数,t
max
为最大迭代次数;r1和r2分别表示在区间[0,1]均匀分布的随机向量;为收敛因子,随迭代次数的增加,其值从2递减到0;
[0074]
步骤5.3:狩猎阶段,灰狼个体跟踪猎物的数学模型描述如下:
[0075][0076][0077][0078]
式中,和分别表示当前种群α,β,δ的位置向量;分别表示当前种群α,β,δ的位置向量;和分别表示当前候选灰狼与最优三条狼之间的距离向量;当|a|>1时,灰狼之间尽量分散在各区域并搜寻猎物;当|a|<1时,灰狼将集中搜索某个或某些
[0079]
区域的猎物;
[0080]
步骤5.4:对收敛因子进行改进,改进后的收敛因子表达式如下:
[0081][0082]
步骤5.5:对位置更新进行改进,位置更新公式如下所示:
[0083][0084][0085][0086]
改进后的gwo算法,其搜索由α狼和β狼决定。
[0087]
进一步地,所述步骤5中利用agwo算法优化软测量模型的参数,具体实现步骤如下:
[0088]
步骤6.1:设置dbn-elm模型和agwo算法的初始参数,包括训练次数,训练样本大小,节点数,种群大小和迭代次数,搜索空间的上下边界;
[0089]
步骤6.2:将dbn-elm模型的节点数量作为agwo算法优化的对象,计算初始每只灰狼的适应度值,将该适应度值与α狼和β狼进行比较,如果适应度值优于α狼和β狼,更新α狼和β狼的适应度值和位置;否则,保留原来α狼和β狼的适应度值和位置,并利用elm极限学习机模型公式(15)至公式(18)对α狼和β狼的位置和距离进行更新;
[0090]
步骤6.3:判断是否达到最大迭代次数,如果达到,则输出dbn-elm模型的最优节点个数,否则,继续步骤6.3;
[0091]
步骤6.4:将数据送入到含有优化参数的dbn-elm软测量模型进行预测,利用公式(19)输出青霉素浓度预测结果。
[0092]
本发明还公开一种青霉素发酵过程关键变量软测量系统,包括上位机和下位机;所述上位机包括显示和监测模块、数据处理模块、特征选择模块、软测量模块、agwo优化模块,所述下位机包括zigbee终端模块;
[0093]
所述zigbee终端模块基于zigbee的嵌入式芯片设计,包括传感器模块、通信模块和主控模块,所述传感器模块为ds18b20数字传感器、t113压阻式压力传感器、rf无线传输的ph值传感器,用于收集青霉素发酵过程产生的变量并将收集的变量通过通信模块传送到上位机;所述通信模块用于联通上位机与下位机;所述主控模块用于给zigbee终端模块的硬件下达指示命令;
[0094]
所述数据处理模块,用于利用集成经验模态分解eemd对输入变量进行去噪处理;
[0095]
所述特征选择模块,用于对去噪处理后的变量利用pacf算法进行特征选择,构建最优输入特征集合;
[0096]
所述软测量模块,用于构建基于深度信念神经网络dbn和极限学习机模型elm的dbn-elm模型,并利用所述dbn-elm模型进行预测;
[0097]
所述agwo优化模块,用于对软测量模型的参数进行优化,输出最优节点个数。
[0098]
优选地,所述显示和监测模块包括图形交互界面和触摸屏,用于将预测得到的青霉素浓度值传输到上位机并在图形交互界面进行实时显示,通过触摸屏进行控制。
[0099]
与现有技术相比,本发明的有益效果:
[0100]
1、本发明针对青霉素过程数据在收集过程中存在的干扰和污染,采用eemd技术进
行去噪处理;2、针对霉素过程数据的非线性和高维性特点,使用pacf算法进行特征选择,选择合适辅助变量与青霉素浓度构建软测量模型;3、建立了青霉素浓度的软测量模型,可以在线预测青霉素浓度;4、使用agwo算法对软测量模型的节点数进行优化,计算速度快、准确度高。
附图说明
[0101]
图1是本发明所提出的方法流程图;
[0102]
图2是本发明青霉素发酵过程数据采集图;
[0103]
图3是本发明所提出的系统结构图;
[0104]
图4是基于深度信念极限学习机的青霉素发酵过程关键变量软测量模型的预测结果;
[0105]
图5是基于深度信念极限学习机的青霉素发酵过程关键变量软测量模型的预测误差曲线图。
具体实施方式
[0106]
下面结合附图和具体实施例,对本发明的实施方式作进一步详细描述。
[0107]
本发明公开一种青霉素发酵过程关键变量软测量方法及系统,所述青霉素发酵过程关键变量软测量方法包括如下步骤:
[0108]
步骤1:实时收集青霉素发酵过程中产生的变量,建立数据库。
[0109]
步骤2:从数据库中获取输入变量利用集成经验模态分解eemd进行去噪处理。
[0110]
步骤2.1:在原始信号x(t)中加入均值为0、方差为常数的高斯白噪声n(t),得到新的信号如下式:
[0111]
xm(t)=x(t)+nm(t)
ꢀꢀ
(1)
[0112]
式中,xm(t)表示第m次加入的高斯白噪声的信号,nm(t)表示第m次加入的高斯白噪声;
[0113]
步骤2.2:对xm(t)分别进行emd分解,得到一系列imf分量和残差分量,分别记其为k
mn
和rm(t);其中,k
mn
表示第m次加入高斯白噪声后,分解所得到的第n个imf分量;
[0114]
步骤2.3:每次加入不同的白噪声,重复上述步骤2.1和2.2,得到下式:
[0115][0116]
步骤2..4:对上述结果进行总体平均运算,消除多次加入高斯白噪声对真实imf分量的影响,最后得到imf分量表达式如下:
[0117][0118]
步骤3:对去噪处理后的变量利用pacf算法进行特征选择,构建最优输入特征集合。
[0119]
步骤3.1:假设ym(t)为输出变量,如果第s个延时时刻的pacf值在95%置信区间之外,则y
m-s
(t)取其中一个为输入变量;如果所有延时时刻的pacf值均在95%置信区间内,则取y
m-1
(t)作为输入变量;
[0120]
步骤3.2:对于长度为n的imf子序列{y1(t),y2(t),...,yn(t)},由协方差γs得延时s协方差得估计值:
[0121][0122]
式中,表示序列得平均值,n/4为最大时延时刻;
[0123]
步骤3.3:由步骤3.2,得自相关函数(acf)估计值表示如下:
[0124][0125]
步骤3.4:基于式(4)和(5),pacf计算式如下:
[0126][0127]
根据pacf值,判断不同辅助变量与关键变量得相关性,构建最优输入特征集合。
[0128]
步骤4:利用步骤3中最优输入特征集合建立软测量模型,将处理好的输入变量送入构建的软测量模型中进行训练;所述软测量模型为基于深度信念神经网络dbn和极限学习机模型elm的dbn-elm模型。
[0129]
步骤4.1:建立深度信念神经网络dbn,dbn神经网络由多个受限玻尔兹曼机rbn堆叠组成,通过无监督逐层贪婪训练,将数据映射到高维空间;rbn由可见层v和隐藏层h组成,其中可见层v负责接收输入数据,隐含层h提取特征。
[0130]
所述步骤4.1中使用rbm训练过程如下:
[0131]
步骤4.1.1:采用无监督逐层贪婪方式初始化rbm层之间的连接权重和偏移量,然后每层rbm从下到上训练,累计多个rbm形成dbn神经网络模型。
[0132]
步骤4.1.2:假设rbm的可见层v和隐藏层h的神经元均为二进制,则其能量函数定义如下:
[0133][0134]
式中,θ={w
ij
,ai,bj},为rbm的参数,由实数表示;a和b分别表示可见层v和隐藏层h的偏置,w是权重矩阵。
[0135]
步骤4.1.3:计算联合概率分布函数p(v,h)如下式:
[0136][0137]
式中,z
θ
=∑∑e-e(v,h|θ)
,表示归一化因子。
[0138]
步骤4.1.4:每个可见层v变量和隐藏层h变量被激活的条件概率如下式所示:
[0139]
p(vi=1|h)=σ(ai+∑jw
ijhj
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0140]
p(hj=1|v)=σ(bj+∑iw
ij
vi)(10)
[0141]
式中,σ为sigmoid函数,计算式如下:
[0142][0143]
步骤4.1.5:通过求解训练集的最大对数似然估计函数可以得到参数的估计,并利用对比散度(cd)算法得到rbm参数更新准则,具体计算式如下:
[0144]
δw
ij
=ε(《v
ihj
》
e-《v
ihj
》r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0145]
δai=ε(《vi》
e-《vi》r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0146]
δbj=ε(《hj》
e-《hj》r)
ꢀꢀꢀꢀꢀꢀ
(14)
[0147]
式中,ε表示学习率,《
·
》e表示训练数据的数学期望,《
·
》r表示重构模型的数学期望。
[0148]
步骤4.2:构建elm极限学习机模型,elm由输入层、隐藏层和输出层构成。
[0149]
步骤4.2.1:给定t个训练集其中x
t
为输入向量,o
t
为期望输出向量,对于包含有l个隐含层激活函数为s(x)的极限学习机数学模型可以表示为:
[0150][0151]
其中,w
l
为第1个隐含层神经元和输入层的权重,b
l
表示第1个隐含节点的偏差,β
l
为连接第l隐含层神经元和输出层的权值。
[0152]
步骤4.2.2:对极限学习机数学模型进行简写,得到下式:
[0153]
hβ=o
ꢀꢀ
(16)
[0154]
其中,h为隐含层输出层矩阵,具体表达式如下:
[0155][0156]
步骤4.2.3:由输出权值的求解是保证损失函数取得最小值,则有下式:
[0157][0158]
其中输出权值β可由下式得到:
[0159][0160]
步骤4.3:整合dbn神经网络与elm,建立dbn-elm模型;在所使用的dbn-elm模型中,dbn模型由四层受限玻尔兹曼机rbm组成,采用无监督的贪婪方式对数据集训练后提取特征,然后将第四层的rbm中的隐藏层输出作为elm输入层,训练dbn-elm模型。
[0161]
步骤5:引入agwo算法对软测量模型的参数进行优化,输出最优参数,利用优化后的软测量模型进行预测,输出青霉素浓度预测结果。
[0162]
步骤5.1:设置gwo算法的初始参数,包括训练次数种群大小和迭代次数,搜索空间的上下边界。
[0163]
步骤5.2:包围猎物阶段,gwo算法数学模型为:
[0164][0165][0166]
表示灰狼的位置向量,表示猎物的位置向量;和为系数向量,其
计算表达式如下:
[0167][0168][0169][0170]
式中,t为当前迭代次数,t
max
为最大迭代次数;r1和r2分别表示在区间[0,1]均匀分布的随机向量;为收敛因子,随迭代次数的增加,其值从2递减到0。
[0171]
步骤5.3:狩猎阶段,灰狼个体跟踪猎物的数学模型描述如下:
[0172][0173][0174][0175]
式中,和分别表示当前种群α,β,δ的位置向量;分别表示当前种群α,β,δ的位置向量;和分别表示当前候选灰狼与最优三条狼之间的距离向量;当|a|>1时,灰狼之间尽量分散在各区域并搜寻猎物;当|a|<1时,灰狼将集中搜索某个或某些
[0176]
区域的猎物。
[0177]
步骤5.4:对收敛因子进行改进,改进后的收敛因子表达式如下:
[0178][0179]
步骤5.5:对位置更新进行改进,位置更新公式如下所示:
[0180][0181][0182][0183]
改进后的gwo算法,其搜索由α狼和β狼决定。
[0184]
利用agwo算法优化软测量模型的参数,具体实现步骤如下:
[0185]
步骤6.1:设置dbn-elm模型和agwo算法的初始参数,包括训练次数,训练样本大小,节点数,种群大小和迭代次数,搜索空间的上下边界。
[0186]
步骤6.2:将dbn-elm模型的节点数量作为agwo算法优化的对象,计算初始每只灰狼的适应度值,将该适应度值与α狼和β狼进行比较,如果适应度值优于α狼和β狼,更新α狼和β狼的适应度值和位置;否则,保留原来α狼和β狼的适应度值和位置,并利用elm极限学习机模型公式(15)至公式(18)对α狼和β狼的位置和距离进行更新。
[0187]
步骤6.3:判断是否达到最大迭代次数,如果达到,则输出dbn-elm模型的最优节点个数,否则,继续步骤6.3。
[0188]
步骤6.4:将数据送入到含有优化参数的dbn-elm软测量模型进行预测,利用公式(19)输出青霉素浓度预测结果。
[0189]
步骤6:将软测量模型预测得到的青霉素浓度值传输到上位机并在图形交互界面进行实时显示,通过触摸屏进行控制。
[0190]
针对上述的青霉素发酵过程关键变量软测量方法,本发明还公开一种青霉素发酵过程关键变量软测量系统,包括上位机和下位机。上位机包括显示和监测模块、数据处理模块、特征选择模块、软测量模块、agwo优化模块,下位机包括zigbee终端模块。
[0191]
zigbee终端模块基于zigbee的嵌入式芯片设计,包括传感器模块、通信模块和主控模块,传感器模块为ds18b20数字传感器、t113压阻式压力传感器、rf无线传输的ph值传感器,用于收集青霉素发酵过程产生的变量并将收集的变量通过通信模块传送到数据处理模块;通信模块用于联通上位机与下位机;主控模块用于给zigbee终端模块的硬件下达指示命令,确保硬件正常工作和创造无线局域网。
[0192]
数据处理模块,用于利用集成经验模态分解eemd对输入变量进行去噪处理,得到去除干扰和污染的输入数据。
[0193]
特征选择模块,用于对去噪处理后的变量利用pacf算法进行特征选择,构建最优输入特征集合。
[0194]
软测量模块,用于构建基于深度信念神经网络dbn和极限学习机模型elm的dbn-elm模型,并利用所述dbn-elm模型进行预测。
[0195]
agwo优化模块,用于对软测量模型的参数进行优化,输出最优节点个数。
[0196]
显示和监测模块包括图形交互界面和触摸屏,用于将预测得到的青霉素浓度值传输到上位机并在图形交互界面进行实时显示,通过触摸屏进行控制。
[0197]
zigbee终端模块上电运行后搜索区域的软测量模块并加入网络,zigbee终端模块的主要功能是通过传感器收集青霉素发酵过程产生的数据,利用通信模块传输至上位机,在上位机进行软测量后,将控制信息通过通信模块传输至下位机,以维持整个发酵过程的常态运行。
[0198]
本发明拟采用pensim2.0平台进行青霉素发酵过程的仿真实验,pensim2.0平台是基于birol内核的青霉素发酵仿真平台,pensim2.0平台可以通过调整设置不通过的初始条件获得不同的发酵工况,发酵过程主要有17个变量,如表1所示。本发明选取物青霉素浓度作为输出变量,其余变量经过eemd技术进行去噪处理后,通过pacf算法进行特征选择,从中选取10个变量作为输入变量。利用pensim2.0平台设定批次1的反应时间为400h,采样间隔时间为1h,共生成10组数据,按照7∶3的比例进行划分为训练集和测试集。其实验结果如表2所示。从表2可以看出,所提出的基于深度信念极限学习机的青霉素发酵过程混合软测量模型有着优异的性能,能够实现青霉素浓度的在线实时测量。
[0199]
表1青霉素发酵数据变量名称
[0200][0201]
表2不同软测量方法精度对比
[0202][0203][0204]
注:进行实验的青霉素发酵过程数据使用过eemd技术去噪和pacf算法特征选择。
[0205]
参见图4与图5,图4是基于深度信念极限学习机的青霉素发酵过程关键变量软测量模型的预测结果,图5是基于深度信念极限学习机的青霉素发酵过程关键变量软测量模型的预测误差曲线图。从图4和图5可以看出软测量模型有着优异的性能,能够实现青霉素浓度的在线实时测量,并且误差值小,精确度更高。
[0206]
本发明并不局限于上述具体实施案例,在本领域技术人员所具备的知识范围内,任何根据本发明的技术方案及其发明构思加以等同替换或改变,均应包含在本发明保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1