一种基于对话状态指导的端到端任务型对话系统
本发明涉及自然语言处理,特别是涉及一种基于对话状态指导的端到端任务型对话系统。
背景技术:
1、流水线式任务型对话系统一般由自然语言理解、对话状态跟踪、对话决策、自然语言生成四大模块构成,分别实现意图识别、槽位填充、策略学习、回复生成等工作。每个模块需要单独训练,并且都需要大量特定格式的人工标注数据,模块的输出会作为下一模块的输入,最后由自然语言模块生成最终的回复。对话状态跟踪模块是流水线式任务型对话系统中很重要的一部分,它的任务是跟踪隐藏在对话内容中的对话状态,有效的对话状态跟踪模块可以辅助系统检索外部知识库。流水线式任务型对话方法使用多个槽-值对来表示对话状态,指导后续模块发起api进行外部知识库检索。但这种对话状态跟踪组件需要特定的数据和单独训练,难以用于端到端的系统中。基于seq2seq的端到端任务型对话方法将对话视为从对话内容到回复的映射问题,这种方法虽然结构简单但难以将外部知识融入到回复生成过程中。seq2seq模型的编码器在编码时将多轮对话拼接成一个词序列作为编码器的输入,忽略了对话的多轮结构信息。模型在解码过程中只考虑将外部知识库信息融入生成的回复中,然而对话内容通常也会包含一定的知识,这一部分信息对解码器的解码过程同样十分重要。此外,对话状态指导为解决oov问题,将对话历史和知识库中的所有词汇引入词汇表,解码时词源选择也是一个棘手的问题。
2、因此当前对话状态指导的端到端任务型对话方法主要存在以下挑战:①端到端模型无法显示检索外部知识库,所以外部知识难以有效地融入生成的回复中。②编码器忽略了对话的多轮结构信息。③对话状态指导的任务型对话系统在解码过程中没有充分利用对话内容中的知识信息。④解码器在生成过程中难以从多个词源中进行选择。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于对话状态指导的端到端任务型对话系统。
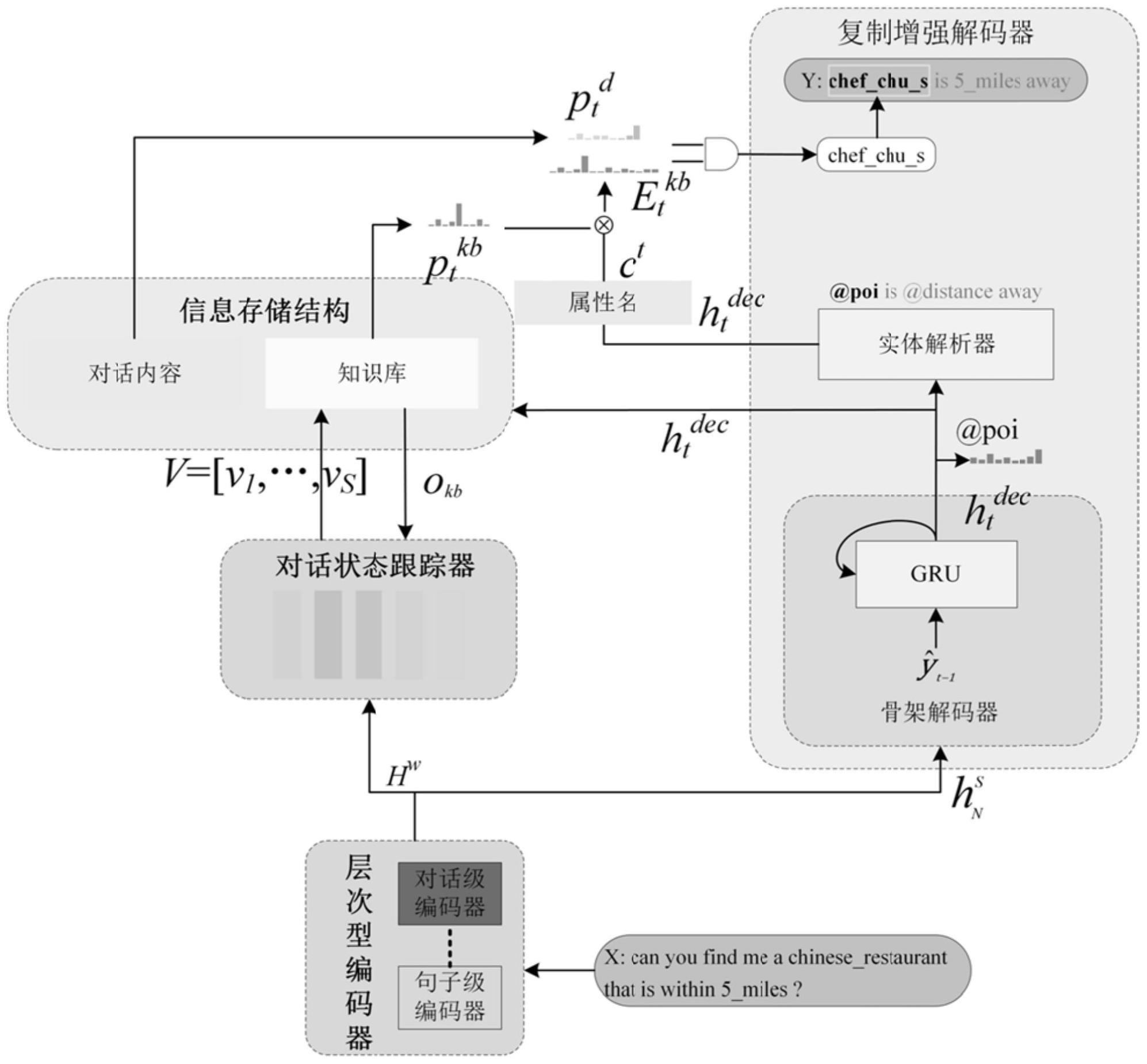
2、为了实现本发明的上述目的,本发明提供了一种基于对话状态指导的端到端任务型对话系统,包括:
3、信息存储结构:用于存储对话内容和与对话相关的知识库信息;
4、层次型编码器:对对话进行编码,获得对话内容的语义表示;
5、对话状态跟踪器:用于根据对话内容获得对话状态向量,并根据对话状态向量对信息存储结构的知识库信息进行检索;
6、复制增强解码器:用于将信息存储结构中的知识融入到生成的回复中,得到最终回复。
7、进一步地,所述信息存储结构包括:
8、知识存储模块,用于存储与对话相关的结构化知识,每一行存储着知识库中某个主题结点相关的所有属性信息;
9、对话内容存储模块,用于存储对话内容,所述对话内容包括对话中的每个词,以及该词对应的所属者、时间信息、位置信息中的之一或者任意组合。
10、进一步地,所述知识存储模块的每个单元为知识库中的每个词,可表示为:
11、
12、其中,wi,j表示存储结构中第i行j列存储的词;
13、aj表示wi,j对应的属性名即第j列的列名;
14、对话内容存储模块中每个存储单元为对话内容存储模块中的每一行,表示为:
15、
16、其中,j表示存储单元的总个数;
17、emb(·)表示使用一个嵌入矩阵进行编码。
18、进一步地,所述层次型编码器包括若干层:
19、第一层是句子级编码器,负责对单个句子进行编码并提取句子级语义:
20、
21、其中wm表示句子中的m步的某个词,通过一个嵌入函数变成嵌入向量;
22、是句子级编码器上一时刻的隐藏层状态向量;
23、φemd(·)表示嵌入函数;
24、表示通过gru模型得到句子级编码器m时刻的隐藏层状态向量;
25、句子级编码器在结束时间步m时刻的输出将作为句子sn的语义表示,将其表示为es_n:
26、
27、第二层是对话级编码器,负责对整个对话进行编码,获取整个对话过程的语义表示:
28、
29、表示对话级编码器上一时刻的隐藏状态;
30、对话级编码器在最后一个时间步n的向量输出是整个对话的语义表示。
31、进一步地,所述对话状态跟踪器的输入为层次型编码器中句子级编码器生成的隐藏向量序列其中l表示整个对话序列的长度,即对话包含的词汇数量,是由句子级编码器生成的位于对话过程中第l个词汇的向量表示;这样可以最大限度地保留对话中词汇的原始词义。
32、通过计算槽位与对话历史中每个词的注意力来获取槽值的概率分布,然后通过一个softmax层对该概率分布进行归一化:
33、
34、其中,表示第j个槽位的槽值在整个对话历史上的概率分布;
35、uj表示第j个可学习的槽位信息矩阵;
36、softmax()表示softmax函数;
37、再通过计算对应槽位下各序列的加权和来获得每个槽位对应的槽值表示:
38、
39、表示表示第j个槽位取对话历史中第l个词为槽值的概率;
40、是由句子级编码器生成的位于对话过程中第l个词汇的向量表示;
41、得到所述对话状态向量,其中向量的个数等于对话包含的槽位个数,也是知识库中每条信息的属性个数。
42、通过所述对话状态跟踪器能让外部知识有效地融入生成的回复中。
43、进一步地,所述根据对话状态向量对信息存储结构的知识库信息进行检索包括:
44、首先通过公式(8)计算知识库中各属性值被对应状态向量选中的概率,然后通过求和操作计算各知识行与当前对话相关的概率:
45、vj表示第j个对话状态;
46、然后将知识库中所有行的概率分布通过一个激活函数进行转换,转换后概率分布的值越接近1越表示该知识行与当前对话相关,否则越不相关;
47、最后,将知识存储模块中所有知识行的加权和整合成一个知识向量o:
48、
49、其中,o表示与对话相关的知识库信息;
50、表示总行数;
51、表示知识库中第i行与当前对话相关的概率;
52、|s|是对话包含的槽位数量;
53、ci,j表示第i行第j列的词的向量表示。
54、进一步地,所述复制增强解码器包括骨架解码器和实体解析器;
55、首先由一个骨架解码器从词汇表中进行预测目标,生成回复;
56、若骨架解码器在某一时刻生成了特定的实体标签,则由实体解析器从信息存储结构中复制相应的实体替代原有实体标签,得到最终回复。
57、通过将解码器与复制机制结合,在某些时刻直接从信息存储结构中复制相关词汇作为解码器的输出,即使出现未登录词oov也可通过复制机制也可使其出现在生成的回复中。复制增强解码器考虑了对话的多轮结构信息,且任务型对话系统在解码过程中能充分利用对话内容中的知识信息。
58、进一步地,基于所述系统的方法包括以下步骤:
59、首先通过层次型编码器获得对话内容的语义表示,
60、然后对话状态跟踪器根据对话内容获得一组对话状态向量,并在对话状态跟踪器中根据对话状态向量对信息存储结构的知识库信息进行检索;
61、最后通过复制增强解码器将信息存储结构中的知识融入到骨架解码器生成的回复中,得到对话系统最终的回复。
62、综上所述,由于采用了上述技术方案,本发明将对话状态跟踪模块与seq2seq模型结合,采用一组可学习的向量表示对话状态,向量组表示的对话状态不破坏系统端到端可学习的特性。
63、此外,使用层次型编码器分别提取对话的句子级和对话级的语义信息;采用一个信息存储结构存储对话内容和知识库信息,使得解码器在解码时会将对话内容与知识库中的知识信息都融入到系统回复中;以及采用一个复制增强的解码器进行词源选择,均能够有效提高端到端任务型对话系统中回复的准确性。
64、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!