基于遮挡关键区域的无监督行人重识别方法
1.本发明涉及行人重识别技术领域,具体涉及一种基于遮挡关键区域的无监督行人重识别方法。
背景技术:
2.行人重识别是近年来计算机视觉领域比较热门的研究方向之一,它是一个图像检索问题,是利用计算机视觉技术判断图像或视频中是否存在特定行人的技术,即给定一个监控行人图像检索跨设备下的该行人图片。
3.随着科技的发展,行人重识别技术已经被广泛应用到智能安防、视频监控等领域。目前,行人重识别已经在有标注的监督领域取得了比较大的突破,并且展现出了优越的性能。但是,由于标注数据集需要较高的人工成本,而无标签的数据往往是十分廉价而且规模比较大的。如何使用大型未标注的数据集对深度学习模型进行训练越来越受到人们的关注,无监督行人重识别应运而生,然而因为缺乏对图像数据的标注,这种基于无监督学习的行人重识别方法往往很难达到有监督学习方法所能够达到的检索准确率。
4.无监督行人重识别就是利用没有标记的数据集学习行人的特征表征,通过深度学习提取的行人特征可以分为两种类型:全局特征和局部特征。全局特征通常包含了行人图片中最直观的信息,如行人衣服的颜色;局部特征是图像局部的一些细节部分,如帽子、背包等。
5.目前,比较流行的完全无监督行人重识别方法大多采用聚类算法对未标记样本生成伪标签,从而以有监督的方式训练模型,而这种方式往往容易导致网络模型过于关注图像的局部特征或者全局特性,导致模型泛化性不高、性能下降等问题。
技术实现要素:
6.本发明解决的问题是如何避免网络过于关注图像的局部特征或全局特征,从而提高模型的泛化性,如何优化损失函数,从而进一步提高网络的鲁棒性。为解决上述问题,本发明提供基于遮挡关键区域的无监督行人重识别方法,包括步骤:
7.s1:获取不带标签的行人图片数据集其中n表示数据集中图片的数量,xi表示数据集中第i张行人图片,将每张图片的尺寸调整为相同高度和宽度,并进行预处理;
8.s2:构建深度学习模型,将预处理后的训练数据输入网络,提取图片样本的特征;
9.s3:对提取的特征进行聚类,得到伪标签;
10.s4:根据聚类结果更新聚类中心以及难样本集合,计算总损失,梯度回传更新网络参数,保存网络的最优参数。
11.s5:使用训练好的网络模型进行行人重识别,输入想要查询行人的图片和视频,输出行人重识别信息。
12.上述方法中,通过对卷积神经网络计算得到的特征向量进行聚类,可以有效将来
自不同相机的同一行人的样本聚集到同一类中,这样每个样本就得到了一个伪标签。无监督行人重识别中,常用到基于难样本策略的对比损失函数,而将关键区域遮挡后的图片实际上已经成为了一个难样本,将这样的难样本放入卷积神经网络中训练,一方面巧妙地利用了基于难样本的对比损失函数,促进神经网络模型的迭代更新;另一方面,可以避免模型过于关注局部特征,提高了网络模型的鲁棒性。
13.进一步地,s1中的预处理为将所有图片调整为相同的大小,对图片进行增强处理,包括水平翻转、旋转一定角度、标准化三种方式。
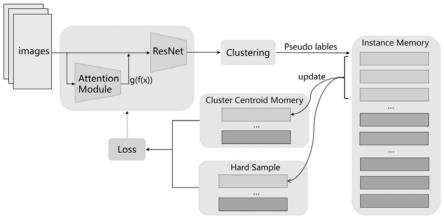
14.s2中,深度学习模型中包含两个模块:注意力模块(attention module)和resnet50模型。注意力模块(attention module)采用的是cbam模型中的空间注意力模块,输出一个与图片大小相同的矩阵,用于反映当前网络模型所关注的图像区域。遮挡函数g表示是否对当前图像进行遮挡,遮挡后的图像使用函数f(x)表示。将经过g(f(x))处理后的图像输入到下一个模块resnet50中。
15.进一步地,遮挡函数g通过设定阈值决定是否进行遮挡。函数f表示对空间注意力模块输出权值最高的区域进行遮挡。
16.通过遮挡原图关注度最高的区域,可以迫使网络模型更多地关注整体区域;通过选取一定比例的图片进行遮挡,可以使网络模型对图片的局部特征、全局特征进行综合性地学习,从而提升模型的泛化性。
17.s3中,所述步骤包括:
18.s31:对所有图片的输出特征计算两两之间的jaccard距离,得到nxn维的距离矩阵。
19.s32:结合得到的距离矩阵,采用dbscan算法进行聚类,对一个簇中的样本赋予相同的伪标签,对聚类产生的离群点,赋予其最近的簇的伪标签。
20.s4中,所述步骤包括:
21.s41:为了更好地对不同的行人进行分类,将基于难样本的损失函数和基于聚簇的损失函数进行整合,即
22.s42:使用记忆模块的方式,将难样本保存在内存中,对难样本集进行更新,方式为κ[j]=μκ[j]-(1-μ)f
hard
,即对j类所属的困难正样本进行更新,f
hard
表示当前batch中关于κ[j]的难样本,即特征向量与κ[j]余弦距离相差最大的样本。
[0023]
s43:基于难样本的损失函数:
[0024][0025]
其中,c为行人特征聚簇后的类别数量,q为当前样本的特征向量,k
+
为样本q所属类的难样本的特征向量,ki为各个难样本所属类的特征向量,τ为温度系数,用于控制相似样本的规模,《》表示计算两个向量间的余弦距离。
[0026]
s44:使用记忆模块的方式,将每个类别的聚类中心保存在内存中,聚类中心的计算方式为聚类后具有相同伪标签的所有特征向量的平均值,每一轮迭代后对聚类中心进行更新,具体方式为ci=αci+(1-α)c
i-1
,ci表示第i轮迭代计算所得的聚类中心,c
i-1
表示第i-1
轮计算所得的聚类中心。
[0027]
s45:基于聚簇的损失函数:
[0028][0029]
其中,c为行人特征聚簇后的类别数量,q为当前样本的特征向量,c
+
为样本q所属类的聚类中心,ci为各个聚类中心的特征向量,τ为温度系数,用于控制相似样本的规模,《》表示计算两个向量间的余弦距离。
[0030]
s46:将数据集图片输入到网络中进行训练,设置训练参数,包括:设置每次训练随机丢失隐含层的节点数、设置全部训练集中样本训练的次数、设置学习率、选择优化器、根据损失曲线判断损失是否收敛等和保存训练好的模型。
[0031]
s5:输入待识别行人图片和视频,提取视频中的行人构造候选行人图片集,计算候选行人图片集中每个行人与待识别行人图片的余弦距离,对图片中行人按照距离排序,根据相似程度对候选行人图片集进行排序,输出前m张最相似的图片,完成行人重识别。
[0032]
本发明的实质性特点在于:
[0033]
1.本发明通过空间注意力模块反映图片的关键区域,并对一定比例图片的关键区域进行遮挡。遮挡后的行人图片既能保持与类内图片共通的地方,又能在一定程度上减少与其他类别的区分度,从而成为了一个边界模糊的难样本。在此基础上结合基于难样本挖掘的infonce损失函数,可以有效地让神经网络的特征编码保持类内紧凑和类间分散。
[0034]
2.本发明对难样本的选取方式进行了改进,具体是使用记忆模块的方式更新难样本,在每一个batch中选取距离记忆模块中k[j]最远的特征向量f
hard
,对记忆模块中保存的特征进行更新,即κ[j]=μκ[j]-(1-μ)f
hard
。相比传统的难样本选择策略,本发明在每一轮batch中只更新了一次难样本,而并非为每一个样本重新查找它的难样本,从而在一定程度上加快了模型的训练和收敛。
附图说明
[0035]
图1是本发明的流程图;
[0036]
图2是本发明的卷积神经网络架构图。
具体实施方式
[0037]
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体说明。
[0038]
实施例1
[0039]
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。但本发明并不限于此实施例。
[0040]
本实施例提供了基于遮挡关键区域的无监督行人重识别方法,如图1和图2所示,本方法包括步骤:
[0041]
s1:获取不带标签的行人图片数据集其中n表示数据集中图片的数量,xi表示数据集中第i张行人图片,将每张图片的尺寸调整为相同高度和宽度,并进行预处理;
[0042]
s2:构建深度学习模型,将预处理后的训练数据输入网络,提取图片样本的特征;
[0043]
s3:对提取的特征进行聚类,得到伪标签;
[0044]
s4:根据聚类结果更新聚类中心以及难样本集合,计算总损失,梯度回传更新网络参数,保存网络的最优参数。
[0045]
s5:将训练好的神经网络模型投入使用。
[0046]
s1中,使用行人数据集market-1501对卷积神经网络模型进行训练,将所有图片大小调整至64x128。对图片进行增强处理,具体包括水平翻转、顺时针和逆时针旋转30度、标准化。
[0047]
s2中,将注意力模块(attention module)和残差网络模块(resnet50)进行整合。注意力模块(attention module)输出一个与图片大小相同的矩阵,用于反映当前网络模型所关注的图像区域,遮挡函数g表示是否对当前图像进行遮挡,遮挡后的图像使用函数f(x)表示。将经过g(f(x))处理后的图像输入到下一个模块resnet50中。
[0048]
进一步地,cbam模型的注意力机制包括空间注意力和通道注意力两部分,本发明只采用了空间注意力部分。为了获得在空间维度的注意力特征,基于特征图的宽度和高度进行全局最大池化和全局平均池化,将特征维度由64x128转变成1x1,接着经过卷积核为7x7的卷积和relu激活函数后降低特征图的维度,然后在经过一次卷积后提升为原来的维度。cbam空间注意力模块的输出反映了当前网络的关注区域。
[0049]
进一步地,遮挡函数g通过设定阈值决定是否进行遮挡。遮挡函数g可表示为q表示范围为[0,1]之间的随机数,阈值设定为0.3。
[0050]
进一步地,函数f表示对空间注意力模块输出权值最高的区域进行遮挡,具体是将大小为64x128的输出权值区域进行划分,划分成8x16个大小为8x8的子区域,将最高权值所在子区域的所有值设置为0,随后再把64x128的输出权值区域与原图的特征向量相乘,输入到resnet网络中。
[0051]
通过遮挡原图关注度最高的区域,产生了一个既能与原类别保持共有特征,又能减少与其他类别图片区分度的难样本,通过选取一定比例的图片进行遮挡,可以使网络模型更多地关注整体区域,对图片的局部特征、全局特征进行综合性地学习,从而提升模型的泛化性。
[0052]
s3中,所述步骤包括:
[0053]
s31:对所有图片的输出特征计算两两之间的jaccard距离,得到nxn维的距离矩阵,n表示图片的数量。
[0054]
s32:基于s31中的距离矩阵,采用dbscan算法进行聚类,对一个簇中的样本赋予相同的伪标签,对聚类产生的离群点,赋予其最近的簇的伪标签。
[0055]
s4中,所述步骤包括:
[0056]
s41:为了让属于同一个行人图片的特征编码更加紧凑,属于不同行人图片的特征编码更加远离,本发明采用infonce loss构造损失函数,形式为loss构造损失函数,形式为其中,q表示待查询的行人编码特征,k
+
表示与q为同一个类别的正样本,{k1,k2,k3,
…
,kk}分别表示k个行人类别的候选集。
[0057]
s42:clusternce loss是一种聚簇级别的infonce loss,clusternce loss具体是使用一个变量(如类内平均特征向量)表示来描述每个cluster,从而产生一个cluster级的内存字典,并在聚类级别计算对比度损失。通过这种方式,每个类别的一致性可以在整个模型的训练过程中得到有效维护,并且可以显著降低gpu内存消耗。
[0058]
s43:为了减少内存的使用,本发明采用clusternce loss对聚类结果计算损失同时提出一种更新难样本损失的clusternce loss函数本发明将这两个损失函数相结合,因此兼顾了聚类结果和个体差异,具体方式为合,因此兼顾了聚类结果和个体差异,具体方式为μ为平衡因子,设置为0.5。
[0059]
s44:使用记忆模块的方式,将难样本保存在内存中,每一轮迭代后对难样本集进行更新,方式为κ[j]=μκ[j]-(1-μ)f
hard
,即对j类所属的困难正样本进行更新,f
hard
表示当前batch中关于κ[j]的难样本,即特征向量与κ[j]余弦距离相差最大的样本,μ为动量更新系数,设置为0.5。
[0060]
s45:进一步地,基于难样本挖掘的损失函数其中,c为行人特征聚簇后的类别数量,q为当前样本的特征向量,k
+
为样本q所属类的难样本的特征向量,ki为各个难样本所属类的特征向量,τ为温度系数,设置为0.2,用于控制相似样本的规模,《》表示计算两个向量间的余弦距离。
[0061]
s46:使用记忆模块的方式,将每个类别的聚类中心保存在内存中,聚类中心的计算方式为聚类后具有相同伪标签的所有特征向量的平均值,每一轮迭代后对聚类中心进行更新,具体方式为ci=αci+(1-α)c
i-1
,ci表示第i轮迭代计算所得的聚类中心,c
i-1
表示第i-1轮计算所得的聚类中心,α为动量更新系数,设置为0.75。
[0062]
s47:进一步地,基于聚簇的损失函数其中,c为行人特征聚簇后的类别数量,q为当前样本的特征向量,c
+
为样本q所属类的聚类中心,ci为各个聚类中心的特征向量,τ为温度系数,设置为0.07,用于控制相似样本的规模,《》表示计算两个向量间的余弦距离。
[0063]
s48:将数据集图片输入到网络中进行训练,设置训练参数,包括:设置每次训练随机丢失隐含层的节点数、设置全部训练集中样本训练的次数、设置学习率、选择优化器、根据损失曲线判断损失是否收敛等。当损失函数数值变化不大时,即可判断算法收敛,保存此时的网络参数,从而得到训练好的模型。
[0064]
s5:使用训练好的网络模型进行行人重识别,输入待识别行人图片和视频,提取视频中的行人构造候选行人图片集,计算候选行人图片集中每个行人与待识别行人图片的余弦距离,对图片中行人按照距离排序,距离表征了二者之间相似程度,相似程度高的就对应视频提取的候选图的那个人,根据相似程度对候选行人图片集进行排序,输出前m张最相似的图片,完成行人重识别。
[0065]
根据上述描述的行人重识别方法的步骤,学习率设置为0.04,整个训练过程将在80轮后终止,测试上述行人重识别方法的识别性能。
[0066]
将market-1501作为训练集,dukemtmc-reid作为验证集时,本发明的方法rank-1
为0.74442,map为0.61148。当仅使用market-1501对模型进行训练及验证时,rank-1为0.80581,map为0.63435。rank-1为识别结果中第1张图的结果正确率,也称第一匹配率,map为平均精度均值,是将多分类任务中的平均精度求和再取平均。结果数据表明本发明所提出的方法具有良好的泛化能力和准确性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1