一种油浸变压器故障诊断方法与流程
1.本发明涉及主要油浸式变压器故障诊断领域,尤其涉及一种油浸变压器故障诊断方法。
背景技术:
2.油浸式变压器是电力系统的关键设备,其安全稳定运行意义重大。然而,电网运行环境给电力变压器高可靠性运行带来了严峻挑战。热应力、电应力、机械应力和环境因素的多重影响会加剧变压器绝缘材料老化,并进一步诱发多种故障,这些故障的发生将严重威胁电力正常供应。
3.经研究证明,多重应力造成的绝缘劣化或变压器故障会加快绝缘材料的化学反应,产生多种气体溶解于变压器油中,典型气体包括氢气(h2)、甲烷(ch4)、一氧化碳(co)、二氧化碳(co2)、乙炔(c2h2)、乙烯(c2h4)、乙烷(c2h6)。基于溶解气体分析目前已形成了改良三比值法、戴维三角形等一系列传统油浸式变压器故障诊断方法。但电力变压器故障产气机理复杂,油中气体含量的分布特性很难推测;油中溶解气体含量或含量比值与故障类型之间的映射关系复杂,仅靠人为经验难以归纳。于是支持向量机、人工神经网络等人工智能方法被广泛应用于电力变压器的故障诊断。
4.人工智能方法相较传统电力变压器故障诊断方法能够提高诊断准确度。其中支持向量机通过优化结构风险来构造分类器,较好解决了小样本、非线性等问题,可达到良好的诊断效果,但传统支持向量机输出为硬分类,无法给出概率输出,不便于分析问题的不确定性。此外,为提高算法故障诊断准确率,以往研究多针对单一算法中的参数采用各类优化算法进行优化,但在故障特征不明确条件下单一算法仍存在误诊断的可能。
技术实现要素:
5.本发明提供了一种油浸变压器故障诊断方法,解决了现有技术中至少一种存在的技术问题。
6.本发明采用的技术方案如下:一种油浸变压器故障诊断方法,包括:
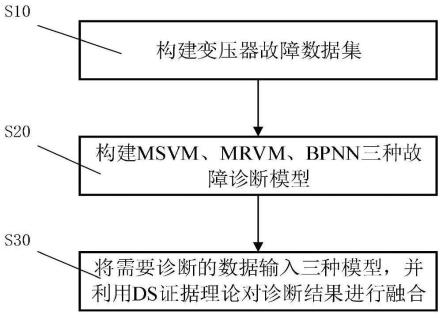
7.s10:构建变压器故障数据集,所述变压器故障数据集包括多组故障样本,所述故障样本为特征参数与故障类型的对应关系;
8.s20:根据变压器故障数据集,分别建立基于多分类相关向量机的第一变压器故障诊断模型、基于多分类支持向量机的第二变压器故障诊断模型和基于反向传播神经网络的第三变压器故障诊断模型;
9.s30:将待诊断的特征参数分别输入第一变压器故障诊断模型、第二变压器故障诊断模型和第三变压器故障诊断模型,获取三种诊断结果数据;
10.s40:将三种诊断结果数据通过ds证据理论进行证据融合,输出最终诊断结果。
11.进一步地,所述变压器故障数据集分为用于对变压器故障诊断模型进行训练的训练集和用于对训练后的变压器故障诊断模型进行验证的测试集。
12.进一步地,所述步骤s20包括:
13.根据训练集中故障样本的特征参数以及与该特征参数对应的故障类型,分别建立基于多分类相关向量机的第一变压器故障诊断模型、基于多分类支持向量机的第二变压器故障诊断模型和基于反向传播神经网络的第三变压器故障诊断模型;
14.通过测试集分别对第一变压器故障诊断模型、第二变压器故障诊断模型和第三变压器故障诊断模型进行验证。
15.进一步地,所述步骤s20还包括:
16.通过粒子群算法的对各个变压器故障诊断模型中的参数进行寻优。
17.进一步地,参数寻优通过粒子群算法的算法适应度函数进行,算法适应度函数为:
[0018][0019]
其中,n为训练样本集的总数;为第i个样本的第j个输出节点的理想输出值;y
ij
为第i个样本的第j个输出节点的实际输出值;c为输出节点的个数。
[0020]
进一步地,当粒子群算法的算法适应度函数输出值满足误差时,则将当前的参数作为寻优结果,代入各个变压器故障诊断模型。
[0021]
进一步地,所述特征参数包括h2含量,ch4含量,c2h6含量,c2h4含量和c2h2含量,所述故障类型包括温度故障、放电故障、局部放电故障和正常运行。
[0022]
进一步地,所述第一变压器故障诊断模型与第二变压器故障诊断模型采用高斯核函数,公式为:
[0023][0024]
其中,xi为第i个样本数据集;xj为第j个样本数据集;γ为平滑因子。
[0025]
进一步地,所述第三变压器故障诊断模型的输出层采用softmax激活函数构建。
[0026]
进一步地,所述的步骤s30还包括:
[0027]
根据ds证据理论所建立的决策标准,对证据融合的结果进行判定。
[0028]
本发明的有益效果:
[0029]
(1)建立了基于多分类相关向量机、多分类支持向量机和反向传播神经网络的故障诊断概率输出模型,避免了传统硬分类诊断方法无法给出概率的问题,便于分析故障类型的不确定性。
[0030]
(2)利用ds证据理论对三种算法输出结果进行融合,相较单一算法,本发明诊断精确度、连续性和可靠性进一步提升。
[0031]
(3)该方法可利用计算机程序实现,对于油浸式变压器故障在线监测系统的研制与开发具有重要意义。
附图说明
[0032]
图1为本发明方法的总体流程图。
[0033]
图2为步骤s20的具体流程图。
[0034]
图3为神经网络结构图。
[0035]
图4为步骤s30的具体流程图。
[0036]
图5为mrvm、msvm、bpnn诊断结果。
[0037]
图6为mrvm、msvm、bpnn与证据理论融合结果对比。
具体实施方式
[0038]
为了使本领域技术人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
[0039]
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
[0040]
在本发明的实施例中,图1是根据本发明一种油浸变压器故障诊断方法的具体步骤提供的流程图,如图1所示,本发明具体包括:
[0041]
s10:构建变压器故障数据集,所述变压器故障数据集包括多组故障样本,所述故障样本为特征参数与故障类型的对应关系。
[0042]
其中,故障样本的特征参数选取油中溶解的h2、ch4、c2h6、c2h4、c2h2的含量,以x1代表h2含量;x2代表ch4含量;x3代表c2h6含量;x4代表c2h4含量;x5代表c2h2含量。5类气体的含量将构成模型输入的故障样本(x,y)的特征向量x,其中,x=[x1,x2,x3,x4,x5]。y则为样本的故障类型,故障类型分为4种:温度故障f1、放电故障f2、局部放电故障f3和正常运行f4,并分别采用向量[1,0,0,0,]
t
、[0,1,0,0,]
t
、[0,0,1,0]
t
、[0,0,0,1]
t
表示。
[0043]
所述变压器故障数据集分为用于对变压器故障诊断模型进行训练的训练集和用于对训练后的变压器故障诊断模型进行验证的测试集,其中,训练集与测试集的比例可以为7:3。在将变压器故障数据集中数据导入到模型中时,需要对数据进行归一化处理,以避免数值较大的气体特征量主导较小的气体特征量,归一化公式为:
[0044]
x
*
=(x-μ)/σ
[0045]
其中,μ为样本数据均值;σ为样本数据标准差;x为样本原始数据;x
*
为归一化后数据值。
[0046]
s20:根据变压器故障数据集,分别建立基于多分类相关向量机的第一变压器故障诊断模型、基于多分类支持向量机的第二变压器故障诊断模型和基于反向传播神经网络的第三变压器故障诊断模型。
[0047]
如图2所示,所述s20具体包括:
[0048]
根据训练集中故障样本的特征参数以及与该特征参数对应的故障类型,分别建立基于多分类相关向量机mrvm的第一变压器故障诊断模型、基于多分类支持向量机msvm的第二变压器故障诊断模型和基于反向传播神经网络bpnn的第三变压器故障诊断模型。
[0049]
其中,需要对各模型参数进行初始化,规定算法最大迭代次数。msvm、mrvm核函数均采用高斯核函数,其公式为:
[0050][0051]
其中,xi为第i个样本数据集;xj为第j个样本数据集;γ为平滑因子。
[0052]
反向传播神经网络是一种按误差逆向传播算法进行网络训练的多层前馈型网络,由输入层、隐含层和输出层组成,结构如图3所示,其中,m为输入量个数;n是隐含层神经元个数;l是输出类别个数。其中,输入层数量为5,输出层数量为7,隐含层神经元个数设置为17。
[0053]
为实现第三变压器故障诊断模型的概率输出,可采用softmax激活函数构建其输出层。
[0054]
softmax函数的基本原理如下式所示,其将分类结果归一化,形成概率分布,作用类似于二分类中sigmoid函数。
[0055][0056]
其中yi为输出层的第i个概率输出,i=1,2,
…
,l;zi为神经网络softmax输出层的第i个输入。
[0057]
三个变压器故障诊断模型中的参数对精度有着重要影响,需要在运行前进行优化设置,故需要通过粒子群算法的对各个变压器故障诊断模型中的参数进行寻优。具体需要寻优的参数是平滑因子γ、正则化参数c,正则化参数c为svm基本原理中涉及到的参数,为本领域技术人员所熟知,故在此不再赘述。
[0058]
其中,系统初始化为一组随机解,称之为粒子,通过粒子在搜索空间的飞行完成寻优,粒子群算法能够通过个体间的协作和竞争实现全局搜索。粒子群算法没有遗传算法的交叉算子和变异算子,而是粒子在解空间追随最优的粒子进行搜索。相较遗传算法或蚁群算法,粒子群算法需要调整的参数更少,更易于实现。
[0059]
参数寻优通过粒子群算法的算法适应度函数进行,算法适应度函数如下。
[0060][0061]
其中,n为训练样本集的总数;为第i个样本的第j个输出节点的理想输出值;y
ij
为第i个样本的第j个输出节点的实际输出值;c为输出节点的个数。
[0062]
当算法适应度函数输出值越小时,参数越优。若算法适应度函数输出值满足误差要求,具体是适应度函数输出值≤0.1,则将当前参数作为寻优结果,将最优参数代入至各个变压器故障诊断模型。若不满足误差要求,则继续进行寻优,直到满足误差要求或达到迭代上限退出运行。
[0063]
当三个变压器故障诊断模型的参数为最优值时,通过测试集分别对第一变压器故障诊断模型、第二变压器故障诊断模型和第三变压器故障诊断模型进行验证。
[0064]
s30:将待诊断的特征参数分别输入第一变压器故障诊断模型、第二变压器故障诊断模型和第三变压器故障诊断模型,获取三种诊断结果数据,将三种诊断结果数据通过ds证据理论进行证据融合,输出最终诊断结果。
[0065]
如图4所示,所述s30具体包括:
[0066]
将所要进行诊断的数据输入mrvm、msvm和bpnn故障诊断模型,利用各模型对油浸式变压器进行故障诊断,获取三种诊断结果数据。
[0067]
用ds证据理论将三种变压器故障诊断模型获得的概率结果进行证据融合。其中,dampster-shafer理论(dampster-shafer theory,dst)是处理不确定性和多源信息推理的数学理论,常用来衡量特定事件发生的置信度。
[0068]
在ds证据理论中,设θ是一个识别框架或称假设,其包含有限个基本命题,各命题之间相互独立。针对变压器故障诊断的识别框架由四种故障类型f1、f2、f3、f4组成,如下公式所示。
[0069]
θ={f1,f2,f3,f4}
[0070]
m(a)代表命题a的基本概率分配(basic probability assignment,bpa)或证据,识别框架θ上的bpa是一个2
θ
→
[0,1]的函数m,并且满足如下所示公式,其中φ为空集。
[0071][0072]
为反映证据间的可靠性差异,可使用信度系数α对基本概率分配值进行修正,修正模型如下式所示。其中,m(a)是命题a原始的基本概率分配,而m'(a)是经信度系数修改后的概率分配,m(θ)是描述不确定性的概率分配。
[0073]
m'(a)=αm(a)
[0074]
m(θ)=1-α
[0075]
对于命题当其有两个证据源b和c时,证据融合规则如下式所示:
[0076][0077][0078]
其中是一个组合算子;k是反映证据冲突等级的归一化因子。为最大程度地减少不同证据之间的冲突,可利用基于相容系数的组合方法调整原始bpa。
[0079]
根据ds证据理论所建立的决策标准,对证据融合的结果进行判定。
[0080]
决策标准如下式所示:
[0081][0082][0083]
其中,m(a2)=max{m(ai),m(θ)为描述不确定性的基本概率分配;ε0和ε1为阈值,设定为0.3、0.1。
[0084]
以下是对本专方法的性能分析:
[0085]
采集521个溶解气体分析(digital gasanalysis,dga)数据,如表1所示。其中包含温度故障f1为214个,放电故障f2为125个,局部放电故障f3为94个,正常状态f4为88个。
[0086]
表1每种故障的样本数量
[0087][0088]
为客观评判不同算法性能优劣,还需引入相关指标加以衡量。为此引入精确度(accuracy,a)、连续性(consistency,c)和可靠性(reliability,r)三种指标对算法表现进行分析,具体计算公式如下所示。精确度是正确诊断样本数占总样本数的比值,其是衡量算法优劣的基本标准,对反映算法性能具有重要意义。但仅利用精确度并不能全面衡量算法性能,因为较高精确度的算法可能对某种故障类型的诊断准确度极高,而对其它故障类型诊断准确度极低。为此需引入连续性指标,以反映算法对不同故障类型的总体诊断性能。此外,为同时体现算法精确度和连续性,可计算二者平均值,作为可靠性指标。
[0089]
si=pi/n(i)
×
100%
[0090][0091]
a=t
sp
/t
tc
[0092]
r=(a+c)/2
[0093]
其中pi是第i类故障中正确诊断的样本数目;n(i)是第i类故障的故障样本总数;si是第i种故障类型正确诊断样本数占故障数据的比例;n是故障类型数目。t
sp
是所有故障类型成功诊断的总数;t
tc
是样本总数。
[0094]
案例1:
[0095]
利用表1中数据评估基于多分类相关向量机的第一变压器故障诊断模型、基于多分类支持向量机的第二变压器故障诊断模型和基于反向传播神经网络的第三变压器故障诊断模型的分类性能。521个样本按7:3的比例划分为训练集和测试集,其中测试集数量为156个,训练集数量为365个。
[0096]
图5呈现了三种故障诊断模型的连续性、精确性和可靠性结果。在三种概率型输出算法中,mrvm的表现最优,其连续性为83.6%,精度为87.8%,可靠性为85.7%;其次为msvm,其连续性为77.5%,精度为85.3%,可靠性为81.4%;表现最差的是bpnn,其三项指标分别为76.4%、82.6%和79.5%。通过分析可知,神经网络需大量样本训练,而本示例数据集相对较小,故其诊断表现同mrvm和msvm有明显差距。而msvm需对多个参数同时进行优化,影响了其整体表现,故其性能不如单一参数的mrvm。
[0097]
案例2:
[0098]
变压器油中气体h2、ch4、c2h2、c2h4和c2h6的含量分别为130.40、2.39、7.22、1.80、4.38(单位:ppm),故障类型为局部放电。经bpnn、msvm和mrvm诊断后,3个算法的4个输出结果形成一个3
×
4的概率值矩阵,如下式所示:
[0099][0100]
经证据理论融合后,结果如表2所示,通过表最后一行数据分析可知,其满足决策公式各项要求,故可判定该故障为f3,即局部放电故障。该诊断结果与实际工况诊断结果相
一致。
[0101]
表2证据推理结果
[0102][0103]
对156和测试集数据采用以上同样方法进行计算分析,并将其与单一算法性能进行对比,结果如图6所示。可以看出,相较单一算法,经证据理论融合后,诊断精确度、连续性和可靠性都有了一定程度提升,分别达到了88.6%、89.1%和88.85%。而单一算法最优的mrvm,其各指标分别为87.8%、83.6%和85.7%。综上,相较单一算法,利用ds证据融合多概率输出算法可在一定程度上提升诊断整体性能,避免误诊断的发生。
[0104]
最后所应说明的是,以上具体实施方式仅用以说明本发明的技术方案而非限制,尽管参照实例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1