一种基于机器学习和云模型的分类洪水随机预报方法
1.本发明属于水文预报技术领域,具体涉及一种基于机器学习和云模型的分类洪水随机预报方法。
背景技术:
2.准确及时的洪水预报有利于制定科学合理的水利工程调度方案,保证流域水安全,具有重要的经济和社会效益。近年来,机器学习因其较强非线性拟合能力、模型搭建简单,在水文预报领域备受关注。采用以人工神经网络为代表的机器学习模型作为水文预报模型,已经成为一种稳定有效的预报手段。然而,考虑到单个模型结构不确定性对预报结果影响较大,国内外学者提出了多模型组合预报的概念。主要应用类似于简单平均法、神经网络模型和贝叶斯模型平均等方法,实现多个模型预报结果的综合,以此提高整体预报精度。但是这些方法主要是从模型模拟精度来进行融合权重的计算,未考虑模型分布之间的相似性。原则上,无论水文预报技术如何提高,预报误差总是难以避免,然而目前大部分不确定性随机模拟未考虑前后预报时刻误差之间的关联性。
技术实现要素:
3.针对不同模型预报结果具有不确定性的特点,且一般考虑预报误差的洪水预报过程未考虑预报时刻前后关联性等缺陷,本发明提出一种基于机器学习和云模型的分类洪水随机预报方法,能够提高洪水预报精度。
4.本发明采用以下技术方案:
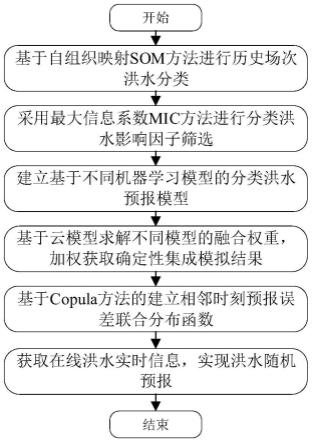
5.一种基于机器学习和云模型的分类洪水随机预报方法,包括以下步骤:
6.step 1:以历史典型场次洪水作为模型率定与检验的基础资料,选取满足条件的分类指标,基于自组织映射神经网络(som)进行历史场次洪水分类;
7.step 2:采用最大信息系数方法(mic)进行分类洪水影响因子筛选,并建立基于不同机器学习方法的分类洪水预报模型,获得不同模型对应各类洪水的最优参数;
8.step 3:针对不同类型洪水,基于云模型求解不同预报模型的融合权重,对各模型的模拟结果进行加权获取分类洪水模型集成预报结果;
9.step 4:分析计算预报相对误差,基于copula方法建立相邻时刻相对预报误差联合分布函数,确定相对预报误差累积概率分布函数;
10.step 5:获取在线洪水实时信息,实现洪水随机预报。
11.上述技术方案中,进一步地,所述step1中分类指标包含降雨总量、最大三小时降雨、降雨强度、降雨中心、前期影响雨量和洪峰中的一种或多种。
12.进一步地,所述step2中分别采用最大信息系数方法mic进行影响因子筛选,包括以下方法:针对不同类型洪水,以t时刻预报降雨p
t
以及前期降雨{p
t-n
,p
t-n+1
,p
t-n+2
,
…
,p
t-1
}作为待选预报因子集合,基于最大信息系数方法mic计算当前时刻流量q
t
与不同待选预报因子的相关性(mic值),选择mic值大于0.30的待选预报因子作为预报模型输入;
13.进一步地,所述step2建立基于不同机器学习方法的分类洪水预报模型,包括以下步骤:
14.step2-1:将洪水序列按照场次洪水划分为训练期和验证期,以step2获得的mic值大于0.30的待选预报因子作为模型输入,场次洪水作为模型输出,并将所有数据集归一化至(0,1]区间;
15.step2-2:建立基于不同机器学习方法的预报模型{m1,m2,
…
,mk}(k≥2),输出模型结果,反归一化后得到模拟径流值其中,表示第i个预报模型第t时刻的模拟值,i=1,2,
…
,k,k为预报模型的个数,t为不同场次洪水的时间长度(h);
16.step2-3:对比训练集次洪观测值其中,表示第t时刻的观测值,选择相关系数(r)、纳什系数(nse)、平均绝对误差(mae)和均方根误差(rmse)作为评价指标,采用网格法对不同机器学习模型参数进行优选;
17.step2-4:将验证集数据输入训练好的模型中获得模拟结果,反归一化后得到径流模拟值以相关系数、纳什系数、平均绝对误差和均方根误差作为评价指标,判断模型的模拟结果是否合格。
18.进一步地,所述step2-1机器学习方法包含神经网络模型、支持向量机模型、长短期记忆网络模型、门循环单元模型和极度梯度提升树中的两种或两种以上。
19.进一步地,所述step3中基于云模型求解不同预报模型的融合权重,对各模型的模拟结果进行加权获取模型集成预报结果,包括以下步骤:
20.step3-1:选取训练期内的观测值和模拟值,基于逆向正态云发生器建立相应云模型对(cq
sim,i
,cq
obs
),将序列的分布特征转化为对应的数字特征,其中,cq
sim,i
表示第i个预报模型模拟值构造的云模型期望曲线,cq
obs
表示观测值构造的云模型期望曲线;
21.step3-2:基于云模型期望曲线重叠度分别计算不同预报模型模拟值和观测值的全局相似度si(q
sim,i
,q
obs
):
22.si(q
sim,i
,q
obs
)=sim(cq
sim,i
,cq
obs
)
ꢀꢀꢀ
(1)
23.step3-3:由全局相似度si(q
sim,i
,q
obs
)求解各预报模型的融合权重wi:
[0024][0025]
step3-4:对各模型的模拟结果进行加权组合,得到模型集成预报结果:
[0026][0027]
式中,表示第i个预报模型第t时刻的模拟值,i=1,2,
…
,k,k为预报模型个数,k≥2。
[0028]
进一步地,所述step3-4的模型集成预报结果选择相关系数(r)、纳什系数(nse)、平均绝对误差(mae)和均方根误差(rmse)作为评价指标,判断集成预报结果是否合格。
[0029]
进一步地,所述step4分析计算相对预报误差,基于copula方法建立相邻时刻相对
预报误差联合分布函数,包括以下步骤:
[0030]
step4-1:假设径流预报相对误差为构建径流预报相对误差分布作为边缘分布,分别基于不同copula函数建立前后时刻的联合分布,采用最大似然估计法对联合分布中的未知参数进行求解;
[0031]
step4-2:采用赤池信息量准则aic指标对求得的联合分布函数进行评价,选取aic指标值最小的copula函数作为最终的联合分布函数;
[0032]
进一步地,所述step4-1采用的copula函数包括但不局限于gumbel、clayton和frank copula函数;
[0033]
进一步地,所述step5中获取在线洪水实时信息,实现洪水随机预报。其中包括以下步骤:
[0034]
step5-1:获取在线洪水实时信息,从实时雨水情信息中提取各分类因子数据,基于step1建立的自组织映射神经网络som进行在线洪水分类,确定该场次洪水所属类别;
[0035]
step5-2:选取由step2获取的对应该类洪水的最优模型参数,和由step3中的方法获取的融合权重进行确定性集成预报;
[0036]
step5-3:采用吉布斯gibbs抽样法对预报误差进行随机模拟,耦合确定性预报结果,实现洪水随机预报区间。
[0037]
进一步地,所述step5-3采用吉布斯gibbs抽样法进行预报时刻预报误差随机模拟,包括以下步骤:
[0038]
step5-3-1生成2个随机数α0,α1∈(0,1),α0和α1为概率值;
[0039]
step5-3-2根据条件概率分布式其中,x1表示当前时刻相对预报误差,x0表示假设场次洪水预报时刻前1h的相对预报误差,c为相邻时刻的copula相对预报误差联合分布函数,基于step4中的方法得到。将α0,α1代入条件概率分布式,求得x1,即为当前预报时刻的相对预报误差累积概率分布值;
[0040]
step5-3-3随机生成α2,α3,
…
,α
t
∈(0,1),求解以下方程组如下:
[0041][0042]
可得到第2~t时刻的相对误差累积概率分布值x2、x3......x
t
;
[0043]
step5-3-4重复step5-3-3的步骤n次,即可得n组相对预报误差累积概率分布值
[0044]
step5-3-5根据求得的相对预报误差累积概率分布函数,通过step4方法建立的相邻时刻相对预报误差联合分布函数的反函数逆推得到n组相对预报误差将相对预报误差与确定集成预报结果进行耦合,实现洪水随机预报。
[0045]
本发明与现有技术相比,具有以下有益效果:
[0046]
(1)采用多种基于机器学习方法的水文预报模型进行集合预报,能够避免单一模型预报风险,提高预报精度;
[0047]
(2)采用云模型进行不同预报模型的加权平均,能够弥补模型预报的不确定性缺陷;
[0048]
(3)基于copula多元函数的预报误差随机模拟考虑不同时段的相互性,能够提高随机预报精度。
附图说明
[0049]
图1是本发明的方法流程图;
[0050]
图2是本发明中step5的具体流程图;
[0051]
图3是实施案例中c1类洪水预报结果图;
[0052]
图4是实施案例中c2类洪水预报结果图;
[0053]
图5是实施案例中洪水随机预报结果图。
具体实施方式
[0054]
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本技术所附权利要求所限定的范围。
[0055]
如图1所示,一种基于机器学习和云模型的分类洪水随机预报方法,包括以下步骤:
[0056]
step 1:以历史典型场次洪水作为模型率定与检验的基础资料,选取满足条件的分类指标,基于自组织映射神经网络som进行历史场次洪水分类;
[0057]
step 2:采用最大信息系数方法mic进行分类洪水影响因子筛选,并建立基于不同机器学习方法的分类洪水预报模型,获得不同模型对应各类洪水的最优参数;
[0058]
step 3:针对不同类型洪水,基于云模型求解不同预报模型的融合权重,对各模型的模拟结果进行加权获取分类洪水模型集成预报结果;
[0059]
step 4:分析计算相对预报误差,基于copula方法建立相邻时刻相对预报误差联合分布函数,确定相对预报误差累积概率分布函数;
[0060]
step 5:获取在线洪水实时信息,实现洪水随机预报。
[0061]
所述step1中分类指标包含但不局限于降雨总量、最大三小时降雨、降雨强度、降雨中心、前期影响雨量和洪峰。
[0062]
所述step2中分别采用最大信息系数方法mic进行影响因子筛选为:针对不同类型洪水,以t时刻预报降雨p
t
以及前期降雨{p
t-n
,p
t-n+1
,p
t-n+2
,
…
,p
t-1
}作为待选预报因子集合,基于最大信息系数方法mic计算当前时刻流量q
t
与不同待选预报因子的相关性(mic值),选择mic值大于0.30的待选预报因子作为预报模型输入;
[0063]
所述step2建立基于不同机器学习方法的分类洪水预报模型,包括以下步骤:
[0064]
step2-1:将洪水序列按照场次洪水划分为训练期和验证期,以step2获得的mic值大于0.30的待选预报因子作为模型输入,场次洪水作为模型输出,并将所有数据集归一化至(0,1]区间;
[0065]
step2-2:建立基于不同机器学习方法的预报模型{m1,m2,
…
mi,
…
mk}(k≥2),输出模型结果,反归一化后得到模拟径流值其中,表示第i个预报模型第t时刻的模拟值,i=1,2,
…
,k,k为预报模型的个数,t为不同场次洪水的时间长度(h);
[0066]
step2-3:对比次洪观测值其中,表示第t时刻的观测值,采用网格法对不同机器学习模型参数进行优选;
[0067]
step2-4将验证集数据输入训练好的模型中获得模拟结果,反归一化后得到径流值
[0068]
所述step2-1机器学习方法包含神经网络模型、支持向量机模型、长短期记忆网络模型、门循环单元模型和极度梯度提升树中的两种或两种以上。
[0069]
所述step2-3模型参数优选,选择相关系数(r)、纳什系数(nse)、平均绝对误差(mae)和均方根误差(rmse)作为评价指标。
[0070]
所述step3中基于云模型求解不同预报模型的融合权重,对各模型的模拟结果进行加权获取模型集成预报结果,包括以下步骤:
[0071]
step3-1:选取训练期内的观测值和模拟值,基于逆向正态云发生器建立相应云模型对(cq
sim,i
,cq
obs
),将序列的分布特征转化为对应的数字特征,其中,cq
sim,i
表示第i个预报模型模拟值构造的云模型期望曲线,cq
obs
表示观测值构造的云模型期望曲线;
[0072]
step3-2:基于云模型期望曲线重叠度分别计算不同预报模型模拟值q
sim,i
和观测值q
obs
的全局相似度si(q
sim,i
,q
obs
):
[0073]
si(q
sim,i
,q
obs
)=sim(cq
sim,i
,cq
obs
)
ꢀꢀꢀ
(1)
[0074]
step3-3:由全局相似度si(q
sim,i
,q
obs
)求解各预报模型的融合权重wi:
[0075][0076]
step3-4:对各模型的模拟结果进行加权组合,得到模型集成预报结果:
[0077][0078]
式中,表示第i个预报模型第t时刻的模拟值,i=1,2,
…
,k,k为预报模型个数,k≥2。
[0079]
所述step3-4的集成预报结果选择相关系数(r)、纳什系数(nse)、平均绝对误差(mae)和均方根误差(rmse)作为评价指标,判断模型集成预报结果是否合格。
[0080]
所述step4分析计算预报误差,基于copula方法建立相邻时刻相对预报误差联合分布函数,包括以下步骤:
[0081]
step4-1:假设径流相对预报误差为构建径流相对预报误差分布作为边缘分布,分别基于不同copula函数建立前后时刻的联合分布,采用最大似然估计法对联合分布中的未知参数进行求解;
[0082]
step4-2:采用赤池信息量准则aic指标对求得的联合分布函数进行评价,选取aic指标值最小的copula函数作为最终的联合分布函数;
[0083]
所述step4-1采用的copula函数包括但不局限于gumbel、clayton和frank copula函数;
[0084]
如图2所示,所述step5获取在线洪水实时信息,实现洪水随机预报,其中包括以下步骤:
[0085]
step5-1:获取在线洪水实时信息,从实时雨水情信息中提取各分类因子数据,基于step1建立的自组织映射神经网络som在线洪水分类,确定该场次洪水所属类别;
[0086]
step5-2:选取由step2获取的对应该类洪水的最优模型参数,和由step3方法获取的融合权重进行确定性集成预报;
[0087]
step5-3:采用吉布斯gibbs抽样法对相对预报误差进行随机模拟,将模拟得到的相对预报误差与确定性集成预报结果进行耦合,实现洪水随机预报区间。
[0088]
进一步地,所述step5-3采用吉布斯gibbs抽样法进行预报时刻预报误差随机模拟,包括以下步骤:
[0089]
step5-3-1生成2个随机数α0,α1∈(0,1),α0和α1为概率值;
[0090]
step5-3-2根据条件概率分布式其中,x1表示当前时刻相对预报误差,x0表示假设场次洪水预报时刻前1h的相对预报误差,c为相邻时刻的copula相对预报误差联合分布函数,基于step4中方法获得。将α0,α1代入条件概率分布式,求得x1,即为当前预报时刻的相对预报误差累积概率分布值;
[0091]
step5-3-3随机生成α2,α3,
…
,α
t
∈(0,1),求解以下方程组如下:
[0092][0093]
可得到第2~t时刻的相对误差累积概率分布值x2、x3......x
t
;
[0094]
step5-3-4重复step5-3-3的步骤n次,即可得n组相对预报误差累积概率分布值
[0095]
step5-3-5根据求得的相对预报误差累积概率分布函数,通过step4方法建立的相邻时刻相对预报误差联合分布函数的反函数逆推得到n组相对预报误差将相对预报误差与确定集成预报结果进行耦合,实现洪水随机预报。
[0096]
现以某水库分类洪水预报为例,说明本发明方法的有效性与合理性。选取该水库历史22场典型洪水,基于自组织映射神经网络som进行分类,分类结果为两类:c1和c2。针对两类洪水,采用mic方法进行影响因子筛选;选取mic值大于0.3的影响作为模型输入,以时刻径流量作为输出,分别建立基于lstm、gru和xgboost的预报模型,对模型进行率定和验证;然后采用云模型对不同预报模型结果进行加权融合,获取模型确定性预报结果,不同模型的场次洪水模拟结果如图3和图4所示。同时采用相关系数(r)、纳什系数(nse)、平均绝对
误差(mae)和均方根误差(rmse)这4个指标对预报结果进行评价,结果如表1和表2所示。可知,通过云模型进行加权平均,虽然无法保证结果最优,但可以有效弥补模型的不确定性缺陷。
[0097]
根据确定性集成预报结果,计算分析预报误差,建立预报误差的边缘分布,同时构建预报误差前后时段的联合分布函数;进一步基于gibbs抽样对误差进行随机模拟,叠加确定性预报结果获取最终随机预报区间,整体覆盖性较好,结果如图5所示,置信区间为85%。
[0098]
表1c1类洪水下不同预报模型训练和验证期指标评价结果
[0099][0100]
表2c2类洪水下不同预报模型训练和验证期指标评价结果
[0101]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1