一种基于多生成器的环境因素引导的台风多趋势预测方法
1.本技术属于气象灾害预报技术领域,尤其涉及一种基于多生成器的环境因素引导的台风多趋势预测方法。
背景技术:
2.台风是一种强大且复杂的天气系统,也被称之为热带气旋,飓风或者热带风暴。它通常在热带,亚热带和温带地区发展,并且会带来大量的降水以及平衡全球的热量。但是强台风会给海上的船只和工作平台造成致命的危险。当其登陆时,它也会带来许多自然灾害,如: 大风,风暴潮,洪水等。这些自然灾害会造成严重的经济损失和人员伤亡。为了抵御台风带来的自然灾害,提前且准确的预测出台风轨迹和强度的未来趋势是非常必要的。由于台风的发展会受到大量因素的影响,台风的预测是一个非常困难的任务,建立一个能够捕获台风的环境信息并且能够给出合理预测趋势的台风系统是非常有必要的。
3.目前权威的气象机构通常使用数值预测的方法来预测台风的发展,该方法会模拟台风发展过程可能会受到的各种影响因素来保证自身预测的准确性。但是台风是一个非常复杂的天气系统,台风数值预测的模拟过程不仅需要超级计算机的支持也需要花费大量的时间。因此只需要数块gpu深度学习台风预测方法就受到了大家的广泛关注,目前基于多数深度学习的方法都只能给出一条确定的预测趋势,这就不符合台风的复杂性和不确定性。单给出一个确定预测的台风预测方法是不被气象学家所接受的,因为其预测结果的参考意义太小。另外,目前基于深度学习的台风预测方法并没有关注到台风的环境因素的特征提取对台风预测的重要性。
技术实现要素:
4.本技术的目的是提供一种基于多生成器的环境因素引导的台风多趋势预测方法,以克服现存的基于深度学习的台风预测方法存在的多个问题,如:无法给出可靠的多趋势台风预测结果的问题,无法较好的提取台风环境信息特征的问题等。
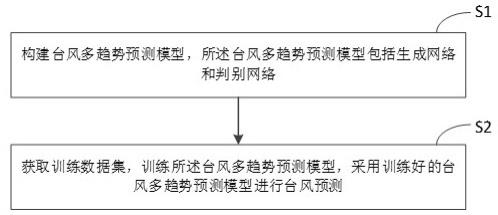
5.为了实现上述目的,本技术技术方案如下:一种基于多生成器的环境因素引导的台风多趋势预测方法,包括:构建台风多趋势预测模型,所述台风多趋势预测模型包括生成网络和判别网络,所述生成网络包括编码模块和解码模块,所述编码模块包括二维数据编码器、一维数据编码器和环境数据编码器,分别对台风二维数据、一维数据和环境数据进行特征提取,所述解码模块包括生成器选择器和若干个相同的生成器,所述生成器选择器根据编码模块所提取的特征,预测出每个生成器被选择的概率序列,根据所得到的概率序列选择生成器进行台风预测,输出预测的台风序列;所述判别网络用于判断输入台风序列的真实性的概率值;获取训练数据集,训练所述台风多趋势预测模型,采用训练好的台风多趋势预测模型进行台风预测。
6.进一步的,所述二维数据编码器包括3d u-net卷积神经网络和一个全连接层,所
述一维数据编码器包括两个全连接层和若干个lstm单元,所述环境数据编码器包括全连接层和卷积层;所述二维数据编码器用来提取二维数据的空间特征以及生成未来的预设时间点的二维数据,所述一维数据编码器用于提取一维和二维数据的时序特征,所述环境数据编码器用于提取环境数据特征;所述一维数据编码器的输入是一维数据与二维数据的空间特征的融合数据。
7.进一步的,所述一维数据包括台风经纬度和中心风速气压,所述二维数据包括预设等压面的位势高度数据。
8.进一步的,所述生成器选择器包括若干个全连接层,所述生成器包括全连接层和若干个相同的lstm单元;所述环境数据编码器的输出、一维数据编码器的输出拼接融合后输入到生成器选择器,生成器选择器输出每个生成器被选择的概率;所述环境数据编码器的输出、一维数据编码器的输出以及二维数据编码器的输出特征进行拼接,在拼接后输入到各个生成器。
9.进一步的,所述判别网络包括依次连接的两个全连接层、若干个lstm单元和另一个全连接层。
10.本技术提出的一种基于多生成器的环境因素引导的台风多趋势预测方法,预测所需要的数据包含一维数据和二维网格数据以及额外的环境数据。一维数据为台风的经纬度,风速和气压数据。二维网格数据包含了代表台风气压结构的500 hpa的位势高度数据。环境数据包含了月份,台风移动速度,过去24小时的台风移动方向,过去24小时的台风强度变化,副热带高压的范围和台风所处的位置,能够从多种异构的气象数据提取特征并给出合理的多可能的台风趋势,为气象预报提供了更多的参考。本技术从异构的气象数据中提取中台风自身的特征以及台风的环境特征,并能利用这些特征选择出多个合理的生成器进行台风预测,最终给出多个多种可能的台风未来趋势。
附图说明
11.图1是本技术台风多趋势预测方法流程图;图2是本技术台风多趋势预测模型结构示意图。
具体实施方式
12.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅用以解释本技术,并不用于限定本技术。
13.在一个实施例中,如图1所示,提供了一种基于多生成器的环境因素引导的台风多趋势预测方法,包括:步骤s1、构建台风多趋势预测模型,所述台风多趋势预测模型包括生成网络和判别网络,所述生成网络包括编码模块和解码模块,所述编码模块包括二维数据编码器、一维数据编码器和环境数据编码器,分别对台风二维数据、一维数据和环境数据进行特征提取,所述解码模块包括生成器选择器和若干个相同的生成器,所述生成器选择器根据编码模块
所提取的特征,预测出每个生成器被选择的概率序列,根据所得到的概率序列选择生成器进行台风预测,输出预测的台风序列;所述判别网络用于计算预测的台风序列真实的概率值。
14.本实施例构建的台风多趋势预测模型,为包括生成网络和判别网络的生成对抗网络框架。其中,生成网络由两个模块组成:编码模块和解码模块。
15.编码模块由三个组件组成:二维数据编码器、一维数据编码器和环境数据编码器。
16.二维数据编码器包括一个3d-unet卷积神经网络和一个全连接层,用来提取二维数据的空间特征以及生成未来的预设时间点的二维数据。预设时间点的个数取决于预测时间的长度。3d-unet的输入通道数以及输出通道数均为1,整个3d-unet卷积神经网络的权值为w_u_1, 定义为浮点型变量,无偏置。3d-unet卷积神经网络输出的二维数据特征通过一个全连接层(embeding)再次进行特征的提取,全连接层的神经元个数为32个,权值为w_2d,定义为浮点型变量,偏置为b_2d定义为浮点型变量。
17.本实施例3d-unet卷积神经网络有两个输出,图2中向上的箭头指的是3d-unet提取的二维数据的空间特征,向右的箭头输出的是生成未来的预设时间点的二维数据。关于3d-unet,是本领域比较成熟的技术,这里不再赘述。未来的预设时间点的二维数据(图2中表示为二维数据特征)经过一个全连接层后,输出二维数据编码器的输出特征。
18.一维数据编码器由两个全连接层和若干个相同的lstm单元组成。本实施例中,两个全连接层神经元个数分别设为32和64个,权值为w_1和w_2,定义为浮点型变量,偏置为b_1和b_2, 定义为浮点型变量。lstm单元的隐藏层神经元个数设置为64个,权值为w_l_1, 定义为浮点型变量,无偏置。lstm单元的数量设置为8个。
19.所述环境数据编码器由若干个全连接层和若干个卷积层。本实施例中,全连接层个数设置为12个,前9个全连接层用于不同环境信息的特征提取,其的神经元个数为16个,9个权值为w_3到w_12,定义为浮点型变量。9个偏置分别为b_3到b_12,定义为浮点型变量。卷积层个数设置为1,其卷积核大小为3,卷积核个数为1,卷积步长为1,填充宽度为1。后三个全连接层用于不同环境特征的融合,其神经元个数分别为104,104和32个,权值分别为w_13,w_14,w_15,定义为浮点型变量。偏置分别为b_13到b_15,定义为浮点型变量。
20.需要说明的是,编码模块中所有全连接层后接relu激活函数,所有卷积层后接归一化层和relu激活函数。
21.本技术所述一维数据编码器的输入是一维数据与二维数据的空间特征的融合数据,即将一维数据与二维数据的空间特征进行拼接后输入到一维数据编码器的全连接层,经过全连接层的融合处理后,lstm单元用来提取融合后的时序特征。
22.解码模块主要由一个生成器选择器和若干个相同的生成器组成。本实施例生成器个数设置成6个,生成器选择器由三个全连接层组成,第一个和第二个全连接层后接relu激活函数。三个全连接层的神经元个数分别为32,32,6,权值分别为w_16,w_17,w_18,定义为浮点型变量。偏置分别为b_16到b_18,定义为浮点型变量。生成器选择器根据编码模块所提取的特征,预测出每个生成器被选择的概率,再根据这个概率序列使用蒙的卡罗采样法选择6个生成器进行最终的台风预测。每个生成器由两个全连接层和若干个相同的lstm单元组成,两个全连接层神经元个数分别设为32和64个,权值为w_19和w_20,定义为浮点型变量,偏置为b_19和b_20, 定义为浮点型变量;lstm单元的隐藏层神经元个数设置为64个,权
值为w_l_2, 定义为浮点型变量,无偏置,lstm单元的数量设置为4。生成器的全连接层用于融合和提取编码模块所提取的特征和所预测的二维数据,lstm单元用于提取时序特征并预测台风,生成器中所有全连接层后接relu激活函数。
23.本技术环境数据编码器的输出、一维数据编码器的输出拼接融合后输入到生成器选择器,生成器选择器输出每个生成器被选择的概率。例如选择生成器g1的概率为0.25,选择生成器g2的概率是0.15,
…
,选择生成器gk的概率是0.10。
24.如图2所示,特征拼接模块,用于对环境数据编码器的输出、一维数据编码器的输出以及二维数据编码器的输出特征进行拼接,在拼接后输入到各个生成器。
25.本实施例,6个被选择的生成器,都被用来依次生成预测的台风序列。最终获得预测的6种可能的台风趋势,这对气象专家来说更有参考价值。
26.本实施例判别网络由两个全连接层和若干个lstm单元和另一个全连接层组成,用于判断输入台风序列的真实性的概率值。前两个全连接层神经元个数都设为32和个,权值为w_21和w_22,定义为浮点型变量,偏置为b_21和b_22, 定义为浮点型变量,后接relu激活函数。lstm单元的隐藏层神经元个数设置为128个,权值为w_l_3, 定义为浮点型变量,无偏置。lstm单元的数量设置为12个。第二个全连接层神经元个数设为2个,权值为w_23,定义为浮点型变量,偏置为b_24, 定义为浮点型变量。
27.步骤s2、获取训练数据集,训练所述台风多趋势预测模型,采用训练好的台风多趋势预测模型进行台风预测。
28.在构建台风多趋势预测模型之后,获取训练数据集对其进行训练。具体的,将数据集划分为训练集、验证集和测试集三部分。测试集包含了2017-2019年发生在西太平洋和中国南海海域的82个台风数据。训练集和验证集包含了1950-2016年的台风数据。按照80%和20%比例随机划分。训练集共包含1303个台风数据,验证集包含318个台风数据。将数据集中的一维数据,二维数据和环境数据进行标准化处理,使得数据更有利于模型的训练。
29.训练时,用随机权值初始化生成网络和判别网络参数,设定生成网络每迭代1次,判别网络迭代1次为一次完整的网络训练,总共进行200次完整的训练。设定判别网络和生成网络的学习率同为0.0001。训练过程如下:将包含台风一维数据(台风经纬度,中心风速气压)和台风二维数据(预设等压面的位势高度数据,例如500 hpa的位势高度数据,代表在某个区域内,每个坐标点在500hpa等压面上离地面的高度,不同的气象现象会影响500hpa等压面的高度)的序列以及台风的环境数据(环境数据包含了月份,台风移动速度,过去24小时的台风移动方向,过去24小时的台风强度变化,副热带高压的范围和台风所处的位置)输入到生成网络对应的中。
30.生成网络中的对应编码器对输入的多个模态的数据进行特征的提取。
31.解码模块对特征进行解码,选择合适的生成器进行台风预测并最终给出多种可能的台风未来的趋势。
32.将所预测的台风与台风的真实值进行误差的计算,得到l2损失,并将该误差反馈到网络中,调整网络的参数,优化预测性能。
33.将所预测的台风和真实台风序列输入到判别网络中,计算出每条台风序列真实的概率值。
34.根据计算得到的每条台风序列的概率值和对应标签,进行交叉熵损失的计算,用
adam算法最小化损失函数,训练模型至收敛,获得最佳性能模型进行台风预测。经过上述步骤的操作,完成对台风多趋势预测模型的训练,采用训练好的台风多趋势预测模型,即可实现台风的多种可能趋势的预测。
35.以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1