一种推荐系统及方法
1.本发明涉及推荐系统技术领域,特别是涉及一种推荐系统及方法。
背景技术:
2.推荐系统旨在根据用户的兴趣爱好和历史行为,预测用户是否会与某个项目(例如物品,新闻,文章,多媒体文件)发生交互,为每个用户推荐其可能喜欢或者需要的项目,从而满足用户的需求。
3.随着推荐系统的发展,人们致力于提高推荐物品的准确性,而忽略了推荐项目的多样性,即推荐的项目类型少。
4.然而,准确的推荐结果不一定是令人满意的。当用户访问网络时,找到准确的内容只是他们众多的需求之一。从用户满意的角度来看,准确性从来不是唯一的标准。在影响用户满意度的众多指标中,多样性决定了用户在推荐场景中的参与度。如果没有多样性的推荐结果,用户很可能会接触到重复的信息,从而导致信息冗余。
技术实现要素:
5.本发明实施例的目的是提供一种推荐方法及系统,在保证推荐结果准确性的同时,提高了推荐结果的多样性。
6.为实现上述目的,本发明实施例提供了如下方案:
7.一种推荐系统,包括:
8.输入层,侧重多样性预测的第一图游走模型,侧重准确性预测的第二图游走模型和门控平衡层;
9.所述输入层用于基于输入数据生成初始嵌入向量,所述输入数据包括用户和项目间的历史交互记录;所述输入数据中的项目包括预设的n个项目中的部分或全部项目;所述输入数据中的用户为全部用户;n为正整数;
10.所述第一图游走模型用于根据输入层输出的初始嵌入向量进行邻域聚合得到第一最终嵌入向量,并根据所述第一最终嵌入向量生成第一预测结果;其中,所述第一预测结果包括:所述n个项目中每一项目被推荐给所述用户的第一可能性;所述第一图游走模型的衰减因子为d=λ且λ∈[0,1],所述衰减因子d=λ用于使所述第一图游走模型侧重多样性预测;
[0011]
所述第二图游走模型用于根据输入层输出的初始嵌入向量进行邻域聚合得到第二最终嵌入向量,并根据所述第二最终嵌入向量生成第二预测结果;其中,所述第二预测结果包括:所述n个项目中每一项目被推荐给所述用户的第二可能性;所述第二图游走模型的衰减因子为d=1-λ且λ∈[0,1],所述衰减因子d=1-λ用于使所述第二图游走模型侧重准确性预测;
[0012]
所述门控平衡层用于将所述第一预测结果和所述第二预测结果进行融合,得到综合预测结果,所述综合预测结果包括:所述n个项目中每一项目被推荐给所述用户的综合可
能性。
[0013]
可选地,还包括:
[0014]
模型输出层,用于:
[0015]
根据所述综合预测结果,计算推荐概率;所述推荐概率包括:所述n个项目中每一项目被推荐给所述用户的概率;
[0016]
根据所述推荐概率对所述n个项目进行降序排序,输出排序后的前n个项目;n不大于n;n为正整数。
[0017]
可选地,在所述基于输入数据生成初始嵌入向量的方面,所述输入层具体用于:
[0018]
根据所述输入数据中用户与项目间的历史交互记录,生成用户-项目二分图;所述用户-项目二分图中每一节点包括:节点标识和节点属性;所述节点标识为用户标识或者项目标识;包含用户标识的节点为用户节点,包含项目标识的节点为项目节点;发生交互的用户节点与项目节点之间采用边相连;
[0019]
根据所述用户-项目二分图,生成初始嵌入向量。
[0020]
可选地,所述邻域聚合具体包括:
[0021]
对第u个用户进行第k+1次邻域聚合:
[0022][0023]
对第i个项目进行第k+1次邻域聚合:
[0024][0025]
其中,d为衰减因子,表示对称归一化项,|ni|表示项目i的邻居节点总个数,ni为项目i的邻居集合,|nu|表示用户u的邻居节点总个数,nu为用户u的邻居集合,为项目i的第k阶嵌入向量,为用户u的第k阶嵌入向量,为用户u的初始嵌入向量,为项目i的初始嵌入向量。
[0026]
可选地,所述融合具体包括:
[0027]
对所述第一预测结果和所述第二预测结果进行线性变换;g=σ(w1ra+w2rd);
[0028]
其中,ra表示第二预测结果,rd表示第一预测结果,w1表示第二预测结果ra的权重系数,w2表示第一预测结果rd的权重系数,σ(
·
)表示激活函数,g表示权重分配向量,g的取值范围为(0,1);
[0029]
通过矩阵点乘对所述第二预测结果ra和所述第一预测结果rd进行加权融合得到综合预测结果rating;
[0030]
rating=gθra+(1-g)θrd;
[0031]
θ表示矩阵点乘。
[0032]
本发明实施例还提供了一种推荐方法,包括:
[0033]
获取基于输入数据生成初始嵌入向量,所述输入数据包括用户和项目间的历史交互记录;所述输入数据中的项目包括预设的n个项目中的部分或全部项目;所述输入数据中
的用户为全部用户;n为正整数;
[0034]
根据输入层输出的初始嵌入向量进行邻域聚合得到第一最终嵌入向量,并根据所述第一最终嵌入向量生成第一预测结果;其中,所述第一预测结果包括:所述n个项目中每一项目被推荐给所述用户的第一可能性;所述第一预测结果对应的衰减因子为d=λ且λ∈[0,1],所述衰减因子d=λ用于使所述第一预测结果侧重多样性预测;
[0035]
根据输入层输出的初始嵌入向量进行邻域聚合得到第二最终嵌入向量,并根据所述第二最终嵌入向量生成第二预测结果;其中,所述第二预测结果包括:所述n个项目中每一项目被推荐给所述用户的第二可能性;所述第二预测结果对应的衰减因子为d=1-λ且λ∈[0,1],所述衰减因子d=1-λ用于使所述第二预测结果侧重准确性预测;
[0036]
将所述第一预测结果和所述第二预测结果进行融合,得到综合预测结果,所述综合预测结果包括:所述n个项目中每一项目被推荐给所述用户的综合可能性。
[0037]
可选地,还包括:
[0038]
根据所述综合预测结果,计算推荐概率;所述推荐概率包括:所述n个项目中每一项目被推荐给所述用户的概率;
[0039]
根据所述推荐概率对所述n个项目进行降序排序,输出排序后的前n个项目;n不大于n;n为正整数。
[0040]
可选地,所述获取基于输入数据生成初始嵌入向量具体包括:
[0041]
根据所述输入数据中用户与项目间的历史交互记录,生成用户-项目二分图;所述用户-项目二分图中每一节点包括:节点标识和节点属性;所述节点标识为用户标识或者项目标识;包含用户标识的节点为用户节点,包含项目标识的节点为项目节点;发生交互的用户节点与项目节点之间采用边相连;
[0042]
根据所述用户-项目二分图,生成初始嵌入向量。
[0043]
可选地,所述邻域聚合具体包括:
[0044]
对第u个用户进行第k+1次邻域聚合:
[0045][0046]
对第i个项目进行第k+1次邻域聚合:
[0047][0048]
其中,d为衰减因子,表示对称归一化项,|ni|表示项目i的邻居节点总个数,ni为项目i的邻居集合,|nu|表示用户u的邻居节点总个数,nu为用户u的邻居集合,为项目i的第k阶嵌入向量,为用户u的第k阶嵌入向量,为用户u的初始嵌入向量,为项目i的初始嵌入向量。
[0049]
可选地,所述融合具体包括:
[0050]
对所述第一预测结果和所述第二预测结果进行线性变换;g=σ(w1ra+w2rd);
[0051]
其中,ra表示第二预测结果,rd表示第一预测结果,w1表示第二预测结果ra的权重
系数,w2表示第一预测结果rd的权重系数,σ(
·
)表示激活函数,g表示权重分配向量,g的取值范围为(0,1);
[0052]
通过矩阵点乘对所述第二预测结果ra和所述第一预测结果rd进行加权融合得到综合预测结果rating;
[0053]
rating=gθra+(1-g)θrd;
[0054]
θ表示矩阵点乘。
[0055]
根据本发明提供的具体实施例,公开了以下技术效果:
[0056]
本发明实施例根据用户和项目间的历史交互记录生成初始嵌入向量,之后,使用侧重多样性预测的第一图游走模型基于初始嵌入向量进行预测,得到第一预测结果,同时,使用侧重准确性预测的第二图游走模型基于初始嵌入向量进行预测,得到第二预测结果。其中,第一图游走模型的衰减因子为d=λ且λ∈[0,1]使第一预测结果侧重于向用户推荐多样的项目,而第二图游走模型的衰减因子为d=1-λ且λ∈[0,1]使第二预测结果侧重向用户推荐准确的项目。之后,将第一预测结果和第二预测结果进行融合,即将预测结果的准确性和多样性进行融合,得到的综合预测结果同时兼顾了准确性和多样性。也即,在保证推荐结果准确性的同时,提高了推荐结果的多样性。
附图说明
[0057]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
[0058]
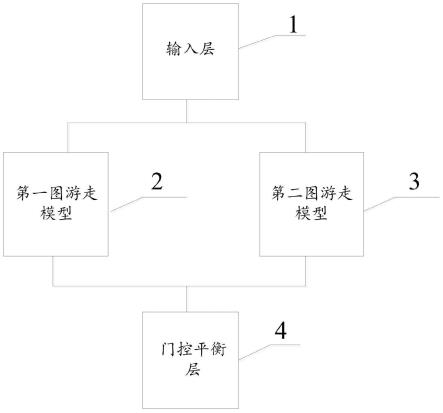
图1为本发明实施例提供的一种推荐系统的结构示意图;
[0059]
图2为本发明实施例提供的用户和项目的历史交互记录图;
[0060]
图3为本发明实施例提供的用户项目二分图;
[0061]
图4为本发明实施例提供的邻域聚合流程示意图;
[0062]
图5为本发明实施例提供的一种推荐方法的流程示意图。
[0063]
符号说明:
[0064]
输入层-1,第一图游走模型-2,第二图游走模型-3,门控平衡层-4。
具体实施方式
[0065]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0066]
本发明的目的是提供一种推荐系统及方法,解决人们致力于提高推荐物品的准确性,而忽略了推荐项目的多样性,推荐的项目类型少用户很可能会接触到重复的信息,从而导致信息冗余的问题。
[0067]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
[0068]
图1示出了上述推荐系统的一种示例性结构,包括输入层1,第一图游走模型2,第二图游走模型3和门控平衡层4。下面详细介绍各部分。
[0069]
输入层1用于基于输入数据生成初始嵌入向量,输入数据包括用户和项目间的历史交互记录;输入数据中的项目包括预设的n个项目中的部分或全部项目;输入数据中的用户为全部用户;n为正整数。
[0070]
在基于输入数据生成初始嵌入向量的方面,输入层1具体用于:
[0071]
根据输入数据中用户与项目间的历史交互记录,生成用户-项目二分图;用户-项目二分图中每一节点包括:节点标识和节点属性;节点标识为用户标识或者项目标识;包含用户标识的节点为用户节点,包含项目标识的节点为项目节点;发生交互的用户节点与项目节点之间采用边相连;
[0072]
根据用户-项目二分图,生成初始嵌入向量。
[0073]
在一个示例中,用户指自然人注册的账户,例如自然人在淘宝app上的账户id、邮箱等。项目指自然人注册的账户访问的链接,地址,产品,新闻,文章和多媒体文件等等。用户和项目间的历史交互记录请参见图2,图2中每个用户u或项目i都是一个独立的节点。项目包括预设的n个项目中的部分或全部项目,即图2中(v1,v4)或(v1,v2,v3,v4)。用户为u1,u2,u3,u4。所有用户组成集合u=(u1,...,um),所有项目组成集合i=(i1,...,in),节点集合v=(u∪i),节点为用户或项目的id属性(id编码),m表示所有用户的数量,n表示所有项目的数量。
[0074]
请参见图3,用户和项目间的历史交互记录会生成一个用户-项目二分图g=(v,e),对用户-项目二分图中的所有用户和项目进行统一编号,即统一进行id编码。某个用户和某个项目之间发生历史交互会生成一条边,所有边组成边集合e。若用户u与项目i有历史交互(用户u点击、浏览、评价项目i等等),则把用户u与项目i的历史交互看作节点u与节点i的边。若用户u与项目i没有交互,则节点u与节点i之间不存在边。遍历所有用户和项目的历史交互记录后,得到一个用户-项目二分图g。
[0075]
基于输入数据生成初始嵌入向量具体包括:输入用户和项目的id编码,根据用户-项目二分图g中的节点集合v进行初始化来生成初始嵌入向量其中表示字数矩阵;m+n表示行数;t表示列数,例如64或128。采用xavier方式初始化嵌入向量。
[0076]
一个节点集合v对应一个初始嵌入向量确定输入数据为且输入数据的数量为用户和项目的总数量(m+n)个。其中,所有用户的初始嵌入向量集合为m表示行数,t表示列数,单个用户u的初始嵌入向量为初始嵌入向量集合与输入数据之间是一一对应的映射关系。所
有项目的初始嵌入向量集合为n表示行数,t表示列数,单个项目i的初始嵌入向量为
[0077]
第一图游走模型2用于根据输入层1输出的初始嵌入向量进行邻域聚合得到第一最终嵌入向量,并根据第一最终嵌入向量生成第一预测结果;其中,第一预测结果包括:n个项目中每一项目被推荐给用户的第一可能性;第一图游走模型的衰减因子为d=λ且λ∈[0,1],衰减因子d=λ用于使第一图游走模型2侧重多样性预测。
[0078]
在一个示例中,将初始嵌入向量输入到侧重多样性预测的第一图游走模型2进行邻域聚合,以生成偏好多样性的第一预测结果。侧重多样性预测的第一图游走模型2是一个需要进行k次邻域聚合的神经网络模型。因此,对初始嵌入向量进行k次邻域聚合,并且将最后一次邻域聚合生成的嵌入向量e
(k)
作为第一最终嵌入向量。邻域聚合生成第一最终嵌入向量e
(k)
具体包括:
[0079]
令k=1,k∈[1,k];
[0080]
确定衰减因子d=λ且λ∈[0,1],将初始嵌入向量侧重多样性预测的第一图游走模型2;
[0081]
对每一个初始嵌入向量进行第k次邻域聚合;
[0082]
令k=k+1,k∈[1,k]直至k=k,得到经过k次邻域聚合的第一最终嵌入向量
[0083]
根据第一最终嵌入向量生成第一预测结果具体包括:
[0084]
第一预测结果其中rd为一个矩阵,包括m*n个元素,m与u对应,n与i对应,t表示转置。第一预测结果rd第m(u)行第n(i)列的元素表示了向用户u推荐项目i的可能性。
[0085]
第二图游走模型3用于根据输入层1输出的初始嵌入向量进行邻域聚合得到第二最终嵌入向量,并根据第二最终嵌入向量生成第二预测结果;其中,第二预测结果包括:n个项目中每一项目被推荐给用户的第二可能性;第二图游走模型3的衰减因子为d=1-λ且λ∈[0,1],衰减因子d=1-λ用于使第二图游走模型3侧重准确性预测。
[0086]
在一个示例中,将初始嵌入向量输入到侧重准确性预测的第二图游走模型3进行邻域聚合,以生成偏好准确性的第二预测结果。侧重准确性预测的第二图游走模型3是一个需要进行k次邻域聚合的神经网络模型。因此,对初始嵌入向量进行k次邻域聚合,并且将最后一次邻域聚合生成的嵌入向量e
(k)
作为第二最终嵌入向量。邻域聚合生成第二最终嵌入向量e
(k)
具体包括:
[0087]
令k=1,k∈[1,k];
[0088]
确定衰减因子d=1-λ且λ∈[0,1],将初始嵌入向量侧重准确性预测的第二图游走模型3;
[0089]
对每一个初始嵌入向量进行第k次邻域聚合;
[0090]
令k=k+1,k∈[1,k]直至k=k,得到经过k次邻域聚合的第二最终嵌入向量
[0091]
根据第二最终嵌入向量生成第二预测结果具体包括:
[0092]
第二预测结果其中ra为一个矩阵,包括m*n个元素,m与u对应,n与i对应,t表示转置。第二预测结果ra第m(u)行第n(i)列的元素表示了向用户u推荐项目i的可能性。
[0093]
在另一个示例中,第一图游走模型2和第二图游走模型3不包含传统图卷积神经网络模型特有的特征变换和非线性激活组件,只保留邻域聚合组件。
[0094]
门控平衡层4用于将第一预测结果rd和第二预测结果ra进行融合,得到综合预测结果,综合预测结果包括:n个项目中每一项目被推荐给用户的综合可能性。
[0095]
在一个示例中,在侧重多样性预测的第一图游走模型2和侧重准确性预测的第二图游走模型3的训练过程中确定平衡方法,平衡方法为门控机制,生成综合预测结果rating。综合预测结果rating为一个矩阵,包括m*n个元素,m与u对应,n与i对应。综合预测结果rating第m(u)行第n(i)列的元素表示了向用户u推荐项目i的综合可能性。
[0096]
综上所述,本发明实施例提供的一种推荐系统及方法,邻域聚合将传统的节点集合v邻域信息范围扩大,通过对第一预测结果rd和第二预测结果ra进行融合,得到综合预测结果rating,在保证推荐结果准确性的同时,提高了推荐结果的多样性。
[0097]
模型输出层用于根据综合预测结果rating,计算推荐概率;推荐概率包括:n个项目中每一项目被推荐给用户的概率。
[0098]
根据推荐概率对n个项目进行降序排序,输出排序后的前n个项目;n不大于n;n为正整数。
[0099]
在一个示例中,模型输出层采用sigmoid激活函数对综合预测结果rating归一化以计算推荐概率,其数值范围被限定在(0,1)。将推荐概率进行降序排序,输出排序后的前n个项目。
[0100]
请参见图4,k表示层数,以u0,u2,u3,i0,i2,i4为例,邻域聚合具体包括:
[0101]
对第u个用户的第k阶嵌入向量进行第k+1次邻域聚合:
[0102][0103]
对第i个项目的第k阶嵌入向量进行第k+1次邻域聚合:
[0104][0105]
其中,d为衰减因子,表示对称归一化项,|ni|表示项目i的邻居节点总个数,ni为项目i的邻居集合,|nu|表示用户u的邻居节点总个数,nu为用户u的邻居集合,
为项目i的第k阶嵌入向量,为用户u的第k阶嵌入向量,为用户u的初始嵌入向量,为项目i的初始嵌入向量。
[0106]
融合具体包括:
[0107]
对第一预测结果和所述第二预测结果进行线性变换;
[0108]
g=σ(w1ra+w2rd);
[0109]
其中,ra表示第二预测结果,rd表示第一预测结果,w1表示第二预测结果ra的权重系数,w2表示第一预测结果rd的权重系数,σ(
·
)表示激活函数,g表示权重分配向量,g的取值范围为(0,1);
[0110]
通过矩阵点乘对第二预测结果ra和第一预测结果rd进行加权融合得到综合预测结果rating;
[0111]
rating=gθra+(1-g)θrd;
[0112]
θ表示矩阵点乘。
[0113]
在本发明其他实施例中,第一图游走模型2和第二图游走模型3在训练过程中,可训练的参数只有第0层(k=0)的初始嵌入向量e
(0)
、第二预测结果ra的权重系数w1,第一预测结果rd的权重系数w2,采用xavier方式初始化上述e
(0)
,w1和w23个参数。
[0114]
请参见图5,本发明实施例还提供一种推荐方法,包括:
[0115]
步骤1:获取基于输入数据生成初始嵌入向量,输入数据包括用户和项目间的历史交互记录;输入数据中的项目包括预设的n个项目中的部分或全部项目;输入数据中的用户为全部用户;n为正整数。
[0116]
步骤1具体可由前述的输入层1执行,具体可参见前述输入层1的介绍,在此不作赘述。
[0117]
步骤2:根据输入层输出的初始嵌入向量进行邻域聚合得到第一最终嵌入向量,并根据第一最终嵌入向量生成第一预测结果;其中,第一预测结果包括:n个项目中每一项目被推荐给用户的第一可能性;第一预测结果对应的衰减因子为d=λ且λ∈[0,1],衰减因子d=λ用于使第一预测结果侧重多样性预测。
[0118]
步骤2具体可由前述的第一图游走模型2执行,具体可参见前述第一图游走模型2的介绍,在此不作赘述。
[0119]
在进行步骤2的同时,还可以进行步骤3:根据输入层输出的初始嵌入向量进行邻域聚合得到第二最终嵌入向量,并根据第二最终嵌入向量生成第二预测结果;其中,第二预测结果包括:n个项目中每一项目被推荐给用户的第二可能性;第二预测结果对应的衰减因子为d=1-λ且λ∈[0,1],衰减因子d=1-λ用于使第二预测结果侧重准确性预测。
[0120]
步骤3具体可由前述的第二图游走模型3执行,具体可参见前述第二图游走模型3的介绍,在此不作赘述。
[0121]
步骤4:将第一预测结果和第二预测结果进行融合,得到综合预测结果,综合预测结果包括:n个项目中每一项目被推荐给用户的综合可能性。
[0122]
步骤4具体可由前述的门控平衡层4执行,具体可参见前述门控平衡层4的介绍,在此不作赘述。
[0123]
在本发明其他实施例中,上述所有实施例中的推荐方法还可包括:
[0124]
步骤41:根据综合预测结果,计算推荐概率;推荐概率包括:n个项目中每一项目被
推荐给用户的概率;
[0125]
根据推荐概率对n个项目进行降序排序,输出排序后的前n个项目;n不大于n;n为正整数。
[0126]
步骤41具体可由前述的门控平衡层4执行,具体可参见前述门控平衡层4的介绍,在此不作赘述。
[0127]
在本发明其他实施例中,上述所有实施例中的推荐方法还可包括:
[0128]
步骤11:获取基于输入数据生成初始嵌入向量具体包括:
[0129]
根据输入数据中用户与项目间的历史交互记录,生成用户-项目二分图;用户-项目二分图中每一节点包括:节点标识和节点属性;节点标识为用户标识或者项目标识;包含用户标识的节点为用户节点,包含项目标识的节点为项目节点;发生交互的用户节点与项目节点之间采用边相连;
[0130]
根据用户-项目二分图,生成初始嵌入向量。
[0131]
步骤11具体可由前述的输入层1执行,具体可参见前述输入层1的介绍,在此不作赘述。
[0132]
在本发明其他实施例中,上述所有实施例中的推荐方法还可包括:
[0133]
步骤21:邻域聚合具体包括:
[0134]
对第u个用户进行第k+1次邻域聚合:
[0135][0136]
对第i个项目进行第k+1次邻域聚合:
[0137][0138]
其中,d为衰减因子,表示对称归一化项,|ni|表示项目i的邻居节点总个数,ni为项目i的邻居集合,|nu|表示用户u的邻居节点总个数,nu为用户u的邻居集合,为项目i的第k阶嵌入向量,为用户u的第k阶嵌入向量,为用户u的初始嵌入向量,为项目i的初始嵌入向量。
[0139]
步骤21具体可由前述的第一图游走模型2和第二图游走模型3执行,具体可参见前述第一图游走模型2和第二图游走模型3的介绍,在此不作赘述。
[0140]
在本发明其他实施例中,上述所有实施例中的推荐方法还可包括:
[0141]
步骤42:融合具体包括:
[0142]
对第一预测结果和第二预测结果进行线性变换;
[0143]
g=σ(w1ra+w2rd);
[0144]
其中,ra表示第二预测结果,rd表示第一预测结果,w1表示第二预测结果ra的权重系数,w2表示第一预测结果rd的权重系数,σ(
·
)表示激活函数,g表示权重分配向量,g的取值范围为(0,1);
[0145]
通过矩阵点乘对第二预测结果ra和第一预测结果rd进行加权融合得到综合预测结
果rating;
[0146]
rating=gθra+(1-g)θrd;
[0147]
θ表示矩阵点乘。
[0148]
步骤42具体可由前述的门控平衡层4执行,具体可参见前述门控平衡层4的介绍,在此不作赘述。
[0149]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
[0150]
本文中应用了具体个例对本发明实施例的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明实施例的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明实施例的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明实施例的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1