基于MogrifierLSTM+HDC的个人信用评估方法与流程
本发明涉及信用评估,具体涉及一种基于mogrifier lstm+hdc的个人信用评估方法。
背景技术:
1、随着互联网金融行业迅速发展,其数据量逐渐增大、数据更新速度加快、数据类型增多,这为金融机构的客户信用评估工作带来了挑战。个人信用风险评估本质是一个分类问题,即将客户分成“好”客户和“坏”客户两类,帮助金融机构进行审批决策。
2、现有技术中,个人信用评估方法主要分为专家模型、统计学习方法、机器学习方法、深度学习方法。其中,专家模型依赖业务规则来搭建模型内部结构,在遇到相同业务时能够快速部署,但不适应不同业务类型,通用性稍差;传统、机器学习方法预测结果的好坏通常依赖人工设计的特征,人工设计特征存在考虑特征不全面和花费大量的人工和时间成本问题。
3、相比之下,深度学习方法能够从数据中自动学习特征,节省人工和时间成本。例如王重仁,韩冬梅.基于卷积神经网络的互联网金融信用风险预测研究[j].微型机与应用,2017,36(24):4.首先将输入数据分为动态数据和静态数据,将动态数据和静态数据分别转换为矩阵和向量,然后利用cnn来自动提取特征并进行分类,最后使用roc曲线,auc值和ks值作为评价指标,实验结果表明,卷积神经网络模型对于信用风险的预测效果要优于其他机器学习算法。实际应用当中,金融机构对信用风险评估的准确性一直有更高的追求。
4、为提高信用风险评估的准确性,王重仁,王雯,佘杰,等,融合深度神经网络的个人信用评估方法[j].计算机工程,2020,46(10):7.基于互联网行业的用户行为数据,提出一种基于长短期记忆(lstm)神经网络和卷积神经网络(cnn)融合的深度神经网络个人信用评分方法,对每个用户的行为数据进行编码,形成一个包括时间维度和行为维度的矩阵,通过融合基于注意力机制的lstm模型和cnn模型2个子模型,从用户原始行为数据中提取序列特征和局部特征。实验结果表明,该方法相比单独的cnn有更好的表现。但普通的lstm输入信息和上一个状态信息之间是相互独立的,它们只在门中进行交互,在这之前缺乏交互,这可能会导致上下文信息的丢失,进而影响最后的结果。
技术实现思路
1、本发明意在提供一种基于mogrifier lstm+hdc的个人信用评估方法,以解决现有技术中lstm的输入信息和上一个状态信息之间相互独立,可能导致上下文信息丢失的问题,提高了序列特征提取的准确性。
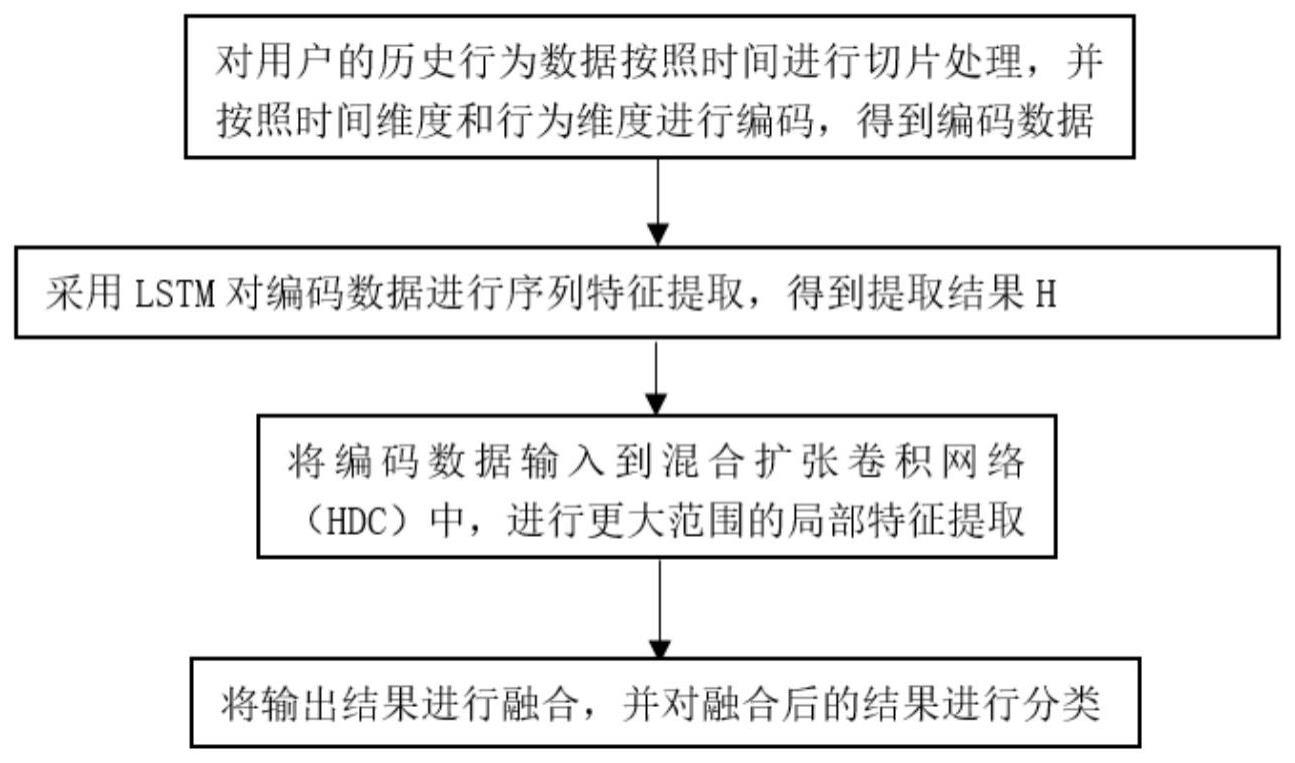
2、为达到上述目的,本发明采用如下技术方案:基于mogrifier lstm+hdc的个人信用评估方法,包括:
3、步骤1,数据预处理,对用户的历史行为数据按照时间进行切片处理,并按照时间维度和行为维度进行编码,得到编码数据;
4、步骤2,采用mogrifier lstm对编码数据进行序列特征提取,得到提取结果h;
5、步骤3,将编码数据输入到混合扩张卷积网络(hdc)中,进行更大范围的局部特征提取;
6、步骤4,将步骤2和步骤3输出结果进行融合,并对融合后的结果进行分类。
7、本方案的原理及优点是:用户的历史行为数据存在序列性,且分散杂乱,在实际个人信用风险评估时,首先需要对用户的历史行为数据进行预处理,按照时间进行切片处理,并按照时间维度和行为维度进行编码,得到便于使用的编码数据;对于存在时序性的历史行为数据,采用mogrifier lstm对编码数据进行序列特征提取,得到提取结果;mogrifierlstm是在普通lstm计算之前交替地让当前时刻输入和上一时刻状态进行交互,解决了现有技术中采用lstm的输入信息和上一个状态信息之间相互独立,且只在门中进行交互,在这之前缺乏交互,可能导致上下文信息丢失的问题,提高了序列特征提取的准确性。
8、采用mogrifier lstm对时序性的客户历史行为数据进行特征提取具有很好的效果,本技术中同时还考虑到客户历史行为数据的局部特征的提取,将编码数据输入到混合扩张卷积网络中,进行更大范围的局部特征提取。采用混合扩张卷积网络进行局部特征提取,提升了对客户历史行为数据特征提取的能力。
9、最后将分别经过mogrifier lstm和混合扩张卷积网络处理得到的结果进行融合,并对融合后的结果进行分类,即完成个人信用评估。
10、优选的,作为一种改进,所述历史行为数据包括用户浏览行为、信用卡账单记录、银行流水记录。
11、技术效果:选择用户的浏览行为、信用卡账单、银行流水等这些历史行为数据,能够更好的了解用户的行为习惯,消费能力,消费习惯以及偏好,更好的评估用户信用风险。
12、优选的,作为一种改进,采用所述mogrifier lstm交替的让当前时刻输入和上一时刻状态进行交互,具体过程如下:
13、
14、
15、其中i∈[1...r],r表示轮次,r=0时,即为普通的lstm,q和r是随机初始化矩阵,xt表示当前输入,ht-1表示之前状态,σ表示sigmod函数,⊙表示矩阵对应位置相乘。
16、技术效果:当前输入xt和之前状态ht-1是相互独立的,它们只在门中进行交互,采用mogrifier lstm进行特征提取,不改变lstm本身结构,在普通lstm计算之前交替地让当前时刻输入和上一时刻状态进行交互,避免在普通lstm计算之前缺乏交互可能导致上下文信息丢失。
17、优选的,作为一种改进,所述mogrifier lstm为双向mogrifier lstm。
18、技术效果:双向lstm只是不同方向的两层lstm,并没有增加交互也没有改变计算方式;单向的mogrifier lstm只能学习到当前位置之前的特征信息,无法学习到之后的信息,采用双向的mogrifier lstm能够学习正向和反向信息,特征提取准确性更高。
19、优选的,作为一种改进,所述步骤2还包括:
20、步骤21,将提取结果h输入注意力机制中进行处理,计算不同位置的特征权重,对不同位置特征权重进行加权处理,得到加权结果s。
21、优选的,作为一种改进,所述注意力机制为自注意力机制。
22、技术效果:自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性;而本技术主要关注的是输入信息,寻找输入序列中不同部分之间关联程度,所以采用自注意力机制。
23、优选的,作为一种改进,所述自注意力机制的计算公式为:
24、q=wq*h
25、k=wk*h
26、v=wv*h
27、
28、其中,wq,wk,wv是可训练参数矩阵,h为采用mogrifier lstm得到的特征提取结果。
29、技术效果:通过构造恰当的内积来对v进行加权,权重越大,词之间的关联程度越大,计算权重便于获得词之间的关联程度。
30、优选的,作为一种改进,所述混合扩张卷积网络采用扩张率为[1,2,5]。
31、技术效果:能够避免扩张卷积局部信息丢失问题。
32、优选的,作为一种改进,所述分类的具体公式为:
33、p=σ(w[s;h]+b)
34、其中s表示基于自注意力机制的mogrifier lstm结构的输出特征向量,h表示混合扩张卷积网络结构输出的特征向量。
35、技术效果:通过分类即能够对个人信用进行评估,得到“好”客户和“坏”客户。
- 还没有人留言评论。精彩留言会获得点赞!